Public Channels
- # boston-meetup
- # dagster-integration
- # data-council-meetup
- # dev-discuss
- # general
- # github-discussions
- # github-notifications
- # gx-integration
- # jobs
- # london-meetup
- # mark-grover
- # nyc-meetup
- # open-lineage-plus-bacalhau
- # providence-meetup
- # sf-meetup
- # spark-support-multiple-scala-versions
- # spec-compliance
- # toronto-meetup
- # user-generated-metadata
Private Channels
Direct Messages
Group Direct Messages







This is the official start of the OpenLineage initiative. Thank you all for joining. First item is to provide feedback on the doc: https://docs.google.com/document/d/1qL_mkd9lFfe_FMoLTyPIn80-fpvZUAdEIfrabn8bfLE/edit




Thanks all for joining. In addition to the google doc, I have opened a pull request with an initial openapi spec: https://github.com/OpenLineage/OpenLineage/pull/1 The goal is to specify the initial model (just plain lineage) that will be extended with various facets. It does not intend to restrict to HTTP. Those same PUT calls without output can be translated to any async protocol

For reference, the slides of the kickoff meeting: https://docs.google.com/presentation/d/1bOnm4J7y1JRJBJtSImm-3vvXzvqqkL-UsCShAuub5oU/edit?usp=sharing
Am I the only weirdo that would prefer a Google Group mailing list to Slack for communicating?
*Thread Reply:* I think that is better for keeping people engaged, since it isn't just a ton of history to go through
*Thread Reply:* And I think it is also better for having thoughtful design discussions
*Thread Reply:* I’m happy to create a google group if that would help.
*Thread Reply:* Here it is: https://groups.google.com/g/openlineage
*Thread Reply:* Slack is more of a way to nudge discussions along, we can use github issues or the mailing list to discuss specific points
*Thread Reply:* @Ryan Blue and @Wes McKinney any recommendations on automating sending github issues update to that list?
*Thread Reply:* I don't really know how to do that

*Thread Reply:* @Julien Le Dem How about using Github discussions. They are specifically meant to solve this problem. Feature is still in beta, but it be enabled from repository settings. One positive side i see is that it will really easy to follow through and one separate place to go and look for discussions and ideas which are being discussed.
*Thread Reply:* I just enabled it: https://github.com/OpenLineage/OpenLineage/discussions
*Thread Reply:* the plan is to use github issues for discussions on the spec. This is to supplement



@Victor Shafran has joined the channel
👋 Hi everyone!

@Zhamak Dehghani has joined the channel
I’ve opened a github issue to propose OpenAPI as the way to define the lineage metadata: https://github.com/OpenLineage/OpenLineage/issues/2 I have also started a thread on the OpenLineage group: https://groups.google.com/g/openlineage/c/2i7ogPl1IP4 Discussion should happen there: ^

@Evgeny Shulman has joined the channel
FYI I have updated the PR with a simple genrator: https://github.com/OpenLineage/OpenLineage/pull/1
 }
}

@Daniel Henneberger has joined the channel
Please send me your github ids if you wish to be added to the github repo

@Fabrice Etanchaud has joined the channel
As mentioned on the mailing List, the initial spec is ready for a final review. Thanks for all who gave feedback so far.
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/1
The next step will be to define individual facets
I have opened a PR to update the ReadMe: https://openlineage.slack.com/archives/C01EB6DCLHX/p1607835827000100

👋
I’m planning to merge https://github.com/OpenLineage/OpenLineage/pull/1 soon. That will be the base that we can iterate on and will enable starting the discussion on individual facets
Thank you all for the feedback. I have made an update to the initial spec adressing the final comments
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/1
The contributing guide is available here: https://github.com/OpenLineage/OpenLineage/blob/main/CONTRIBUTING.md Here is an example proposal for adding a new facet: https://github.com/OpenLineage/OpenLineage/issues/9
Welcome to the newly joined members 🙂 👋

Hello! Airflow PMC member here. Super interested in this effort
I'm joining this slack now, but I'm basically done for the year, so will investigate proposals etc next year

Hey all 👋 Super curious what people's thoughts are on the best way for data quality tools i.e. Great Expectations to integrate with OpenLineage. Probably a Dataset level facet of some sort (from the 25 minutes of deep spec knowledge I have 😆), but curious if that's something being worked on? @Abe Gong
*Thread Reply:* The initial OpenLineage spec is pretty explicit about linking metadata primarily to execution of specific tasks, which is appropriate for ValidationResults in Great Expectations
*Thread Reply:* There isn’t as strong a concept of persistent data objects (e.g. a specific table, or batches of data from a specific table)
*Thread Reply:* (In the GE ecosystem, we call these DataAssets and Batches)
*Thread Reply:* This is also an important conceptual unit, since it’s the level of analysis where Expectations and data docs would typically attach.
*Thread Reply:* @James Campbell and I have had some productive conversations with @Julien Le Dem and others about this topic
*Thread Reply:* Yep! The next step will be to open a few github issues with proposals to add to or amend the spec. We would probably start with a Descriptive Dataset facet of a dataset profile (or dataset update profile). There are other aspects to clarify as well as @Abe Gong is explaining above.
Also interesting to see where this would hook into Dagster. Because one of the many great features of Dagster IMO is it let you do stuff like this (without a formal spec albeit). An OpenLineageMaterialization could be interesting
*Thread Reply:* Totally! We had a quick discussion with Dagster. Looking forward to proposals along those lines.

Congrats @Julien Le Dem @Willy Lulciuc and team on launching OpenLineage!
*Thread Reply:* Thanks, @Harikiran Nayak! It’s amazing to see such interest in the community on defining a standard for lineage metadata collection.
*Thread Reply:* Yep! Its a validation that the problem is real!

Hey folks! Worked on a variety of lineage problems across domains. Super excited about this initiative!
*Thread Reply:* What are you current use cases for lineage?
(for review) Proposal issue template: https://github.com/OpenLineage/OpenLineage/pull/11
for people interested, <#C01EB6DCLHX|github-notifications> has the github integration that will notify of new PRs …

👋 Hello! I'm currently working on lineage systems @ Datadog. Super excited to learn more about this effort
*Thread Reply:* Would you mind sharing your main use cases for collecting lineage?

Hi! I’m also working on a similar topic for some time. Really looking forward to having these ideas standardized 🙂

I would be interested to see how to extend this to dashboards/visualizations. If that still falls with the scope of this project.
*Thread Reply:* Definitely, each dashboard should become a node in the lineage graph. That way you can understand all the dependencies of a given dashboard. SOme example of interesting metadata around this: is the dashboard updated in a timely fashion (data freshness); is the data correct (data quality)? Observing changes upstream of the dashboard will provide insights to what’s hapening when freshness or quality suffer
*Thread Reply:* 100%. On a granular scale, the difference between a visualization and dashboard can be interesting. One visualization can be connected to multiple dashboards. But of course this depends on the BI tool, Redash would be an example in this case.
*Thread Reply:* We would need to decide how to model those things. Possibly as a Job type for dashboard and visualization.
*Thread Reply:* It could be. Its interesting in Redash for example you create custom queries that run at certain intervals to produce the data you need to visualize. Pretty much equivalent to job. But you then build certain visualizations off of that “job”. Then you build dashboards off of visualizations. So you could model it as an job or it could make sense for it to be more modeled like an dataset.
Thats the hard part of this. How to you model a visualization/dashboard to all the possible ways they can be created since it differs depending on how the tool you use abstracts away creating an visualization.

👋 Hi everyone!
*Thread Reply:* Part of my role at Netflix is to oversee our data lineage story so very interested in this effort and hope to be able to participate in its success
A reference implementation of the OpenLineage initial spec is in progress in Marquez: https://github.com/MarquezProject/marquez/pull/880
 }
}
*Thread Reply:* The OpenLineage reference implementation in Marquez will be presented this morning Thursday (01/07) at 10AM PST, at the Marquez Community meeting.
When: Thursday, January 7th at 10AM PST Where: https://us02web.zoom.us/j/89344845719?pwd=Y09RZkxMZHc2U3pOTGZ6SnVMUUVoQT09
*Thread Reply:* Marquez now has a reference implementation of the initial OpenLineage spec

👋 Hi everyone! I'm one of the co-founder at data.world and looking forward to hanging out here

👋 Hi everyone! I was looking for the roadmap and don't see any. Does it exist?
*Thread Reply:* There’s no explicit roadmap so far. With the initial spec defined and the reference implementation implemented, next steps are to define more facets (for example, data shape, dataset size, etc), provide clients to facilitate integrations (java, python, …), implement more integrations (Spark in the works). Members of the community are welcome to drive their own initiatives around the core spec. One of the design goals of the facet is to enable numerous and independant parallel efforts
*Thread Reply:* Is there something you are interested about in particular?
I have opened a proposal to move the spec to JSONSchema, this will make it more focused and decouple from http: https://github.com/OpenLineage/OpenLineage/issues/15
Here is a PR with the corresponding change: https://github.com/OpenLineage/OpenLineage/pull/17

Really excited to see this project! I am curious what's the current state and the roadmap of it?
*Thread Reply:* You can find the initial spec here: https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md The process to contribute to the model is described here: https://github.com/OpenLineage/OpenLineage/blob/main/CONTRIBUTING.md In particular, now we’d want to contribute more facets and integrations. Marquez has a reference implementation: https://github.com/MarquezProject/marquez/pull/880 On the roadmap: • define more facets: data profile, etc • more integrations • java/python client You can see current discussions here: https://github.com/OpenLineage/OpenLineage/issues
For people curious about following github activity you can subscribe to: <#C01EB6DCLHX|github-notifications>
*Thread Reply:* It is not on general, as it can be a bit noisy
Random-ish question: why is producer and schemaURL nested under nominalTime facet in the spec for postRunStateUpdate? It seems like the producer of its metadata isn’t related to the time of the lineage event?
*Thread Reply:* Hi @Zachary Friedman! I replied bellow. https://openlineage.slack.com/archives/C01CK9T7HKR/p1612918909009900
 }
}
producer and schemaURL are defined in the BaseFacet type and therefore all facets (including nominalTime) have it.
• The producer is an identifier for the code that produced the metadata. The idea is that different facets in the same event can be produced by different libraries. For example In a Spark integration, Iceberg could emit it’s own facet in addition to other facets. The producer identifies what produced what.
• The _schemaURL is the identifier of the version of the schema for a given facet. Similarly an event could contain a mixture of Core facets from the spec as well as custom facets. This makes explicit what the definition for this facet is.
As discussed previously, I have separated a Json Schema spec for the OpenLineage events from the OpenAPI spec defining a HTTP endpoint: https://github.com/OpenLineage/OpenLineage/pull/17
 }
}
*Thread Reply:* Feel free to comment, this is ready to merge
*Thread Reply:* Thanks, Julien. The new spec format looks great 👍
And the corresponding code generator to start the java (and other languages) client: https://github.com/OpenLineage/OpenLineage/pull/18
those are merged, we now have a jsonschema, an openapi spec that extends it and a generated java model
Following up on a previous discussion: This proposal and the accompanying PR add the notion of InputFacets and OutputFacets: https://github.com/OpenLineage/OpenLineage/issues/20 In summary, we are collecting metadata about jobs and datasets. At the Job level, when it’s fairly static metadata (not changing every run, like the current code version of the job) it goes in a JobFacet. When it is dynamic and changes every run (like the schedule time of the run), it goes in a RunFacet. This proposal is adding the same notion at the Dataset level: when it is static and doesn’t change every run (like the dataset schema) it goes in a Dataset facet. When it is dynamic and changes every run (like the input time interval of the dataset being read, or the statistics of the dataset being written) it goes in an inputFacet or an outputFacet. This enables Job and Dataset versioning logic, to keep track of what changes in the definition of something vs runtime changes
*Thread Reply:* @Kevin Mellott and @Petr Šimeček Thanks for the confirmation on this slack message. To make your comment visible to the wider community, please chime in on the github issue as well: https://github.com/OpenLineage/OpenLineage/issues/20 Thank you.
*Thread Reply:* The PR is out for this: https://github.com/OpenLineage/OpenLineage/pull/23

Hi, I am really interested in this project and Marquez. I am a bit not clear about the differences and relationship between those two projects. As my understanding, OpenLineage provides an api specification for other tools running jobs (e.g. Spark, Airflow) to send out an event to update the run state of the job, then for example Marquez can be the destination for those events and show the data lineage from those run state updates. When you are saying there is an reference implementation of the OpenLineage spec in Marquez, do you mean there is an /lineage endpoint implemented in the Marquez api https://github.com/MarquezProject/marquez/blob/main/api/src/main/java/marquez/api/OpenLineageResource.java? Then my question is what is next step after Marquez has this api? How does Marquez use that endpoint to integrate with airflow for example? I did not find the usage of that endpoint in Marquez project. The library marquez-airflow which integrates Airflow with Marquez seems like only use the other marquez apis to build the data lineage. Or did I misunderstand something? Thank you very much!
*Thread Reply:* Okay, I found the spark integration in Marquez calls the /lineage endpoint. But I am still curious about the future plan to integrate with other tools, like airflow?
*Thread Reply:* Just restating some of my answers from teh marquez slack for the benefits of folks here.
• OpenLineage defines the schema to collect metadata • Marquez has a /lineage endpoint implementing the OpenLineage spec to receive this metadata, implemented by the OpenLineageResource you pointed out • In the future other projects will also have OpenLineage endpoints to receive this metadata • The Marquez Spark integration produces OpenLineage events: https://github.com/MarquezProject/marquez/tree/main/integrations/spark • The Marquez airflow integration still uses the original marquez api but will be migrated to open lineage. • All new integrations will use OpenLineage metadata

Hi Everyone. Just got started with the Marquez REST API and a little bit into the Open Lineage aspects. Very easy to use. Great work on the curl examples for getting started. I'm working with Postman and am happy to share a collection I have once I finish testing. A question about tags --- are there plans for a "post new tag" call in the API? ...or maybe I missed it. Thx. --ernie
*Thread Reply:* I forgot to reply in thread 🙂 https://openlineage.slack.com/archives/C01CK9T7HKR/p1614725462008300
OpenLineage doesn’t have a Tag facet yet (but tags are defined in the Marquez api). Feel free to open a proposal on the github repo. https://github.com/OpenLineage/OpenLineage/issues/new/choose

Hey everyone. What's the story for stream processing (like Flink jobs) for OpenLineage?
It does not fit cleanly with runEvent model, which
It is required to issue 1 START event and 1 of [ COMPLETE, ABORT, FAIL ] event per run.
as unbounded stream jobs usually do not complete.
I'd imagine few "workarounds" that work for some cases - for example, imagine a job calculating hourly aggregations of transactions and dumpling them into parquet files for further analysis. The job could issue OTHER event type adding additional output dataset every hour. Another option would be to create new "run" every hour, just indicating the added data.

*Thread Reply:* Ha, I signed up just to ask this precise question!
*Thread Reply:* I’m still looking into the spec myself. Are we required to have 1 or more runs per Job? Or can a Job exist without a run event?
*Thread Reply:* Run event can be emitted when it starts. and it can stay in RUNNING state unless something happens to the job. Additionally, you could send event periodically as state RUNNING to inform the system that job is healthy.
Similar to @Maciej Obuchowski question about Flink / Streaming jobs - what about Streaming sources (eg: a Kafka topic)? It does fit into the dataset model, more or less. But, has anyone used this yet for a set of streaming sources? Particularly with schema changes over time?
Hi @Maciej Obuchowski and @Adam Bellemare, streaming jobs are meant to be covered by the spec but I agree there are a few details to iron out.
In particular, streaming job still have runs. If they run continuously they do not run forever and you want to track that a job has been started at a point in time with a given version of the code, then stopped and started again after being upgraded for example.
I agree with @Maciej Obuchowski that we would also send OTHER events to keep track of progress.
For example one could track checkpointing this way.
For a Kafka topic you could have streaming dataset specific facets or even Kafka specific facets (ex: list of offsets we stopped reading at, schema id, etc )
*Thread Reply:* That's good idea.
Now I'm wondering - let's say we want to track on which offset checkpoint ended processing. That would mean we want to expose checkpoint id, time, and offset. I suppose we don't want to overwrite previous checkpoint info, so we want to have some collection of data in this facet.
Something like appendable facets would be nice, to just add new checkpoint info to the collection, instead of having to push all the checkpoint infos all the time we just want to add new data point.
*Thread Reply:* Thanks Julien! I will try to wrap my head around some use-cases and see how it maps to the current spec. From there, I can see if I can figure out any proposals
*Thread Reply:* You can use the proposal issue template to propose a new facet for example: https://github.com/OpenLineage/OpenLineage/issues/new/choose

Hi everyone, I just hear about OpenLineage and would like to learn more about it. The talks in the repo explain nicely the purpose and general ideas but I have a couple of questions. Are there any working implementations to produce/consume the spec? Also, are there any discussions/guides standard information, naming conventions, etc. in the facets?
• The Spark integration using OpenLineage: https://github.com/MarquezProject/marquez/tree/main/integrations/spark • in particular: ◦ A simple OpenLineage client (we’re working on adding this to the OpenLineage repo): https://github.com/MarquezProject/marquez/tree/b758751b6c0ba6d2f0da1ba7ec636b73317[…]450/integrations/spark/src/main/java/marquez/spark/agent/client ◦ emitting events: ▪︎ https://github.com/MarquezProject/marquez/blob/b758751b6c0ba6d2f0da1ba7ec636b73317[…]ava/marquez/spark/agent/lifecycle/SparkSQLExecutionContext.java ▪︎ https://github.com/MarquezProject/marquez/blob/b758751b6c0ba6d2f0da1ba7ec636b73317[…]ava/marquez/spark/agent/lifecycle/SparkSQLExecutionContext.java • The Marquez OpenLineage endpoint: https://github.com/MarquezProject/marquez/blob/893beddcb7dbc4d4b7b994f003ce461a478[…]bf466/api/src/main/java/marquez/service/OpenLineageService.java
Marquez has a reference implementation of an OpenLineage endpoint. The Spark integration emits OpenLineage events.
Thank you @Julien Le Dem!!! Will take a close look
Q related to People/Teams/Stakeholders/Owners with regards to Jobs and Datasets (didn’t find anything in search):
Let’s say I have a dataset , and there are a number of other downstream jobs that ingest from it. In the case that the dataset is mutated in some way (or deleted, archived, etc), how would I go about notifying the stakeholders of that set about the changes?
Just to be clear, I’m not concerned about the mechanics of doing this, just that there is someone that needs to be notified, who has self-registered on this set.
Similarly, I want to manage the datasets I am concerned about , where I can grab a list of all the datasets I tagged myself on.
This seems to suggest that we could do with additional entities outside of Dataset, Run, Job. However, at the same time, I can see how this can lead to an explosion of other entities. Any thoughts on this particular domain? I think I could achieve something similar with aspects, but this would require that I update the aspect on each entity if I want to wholesale update the user contact, say their email address.
Has anyone else run into something like this? Have you any advice? Or is this something that may be upcoming in the spec?
*Thread Reply:* One thing we were considering is just adding these in as Facets ( Tags as per Marquez), and then plugging into some external people managing system. However, I think the question can be generalized to “should there be some sort of generic entity that can enable relationships between itself and Datasets, Jobs, Runs) as part of an integration element?
*Thread Reply:* That’s a great topic of discussion. I would definitely use the OpenLineage facets to capture what you describe as aspect above. The current Marquez model has a simple notion of ownership at the namespace model but this need to be extended to enable use cases you are describing (owning a dataset or a job) . Right now the owner is just a generic identifier as a string (a user id or a group id for example). Once things are tagged (in some way), you can use the lineage API to find all the downstream or upstream jobs and datasets. In OpenLineage I would start by being able to capture the owner identifier in a facet with contact info optional if it’s available at runtime. It will have the advantage of keeping track of how that changed over time. This definitely deserves its own discussion.
*Thread Reply:* And also to make sure I understand your use case, you want to be able to notify the consumers of a dataset that it is being discontinued/replaced/… ? What else are you thinking about?
*Thread Reply:* Let me pull in my colleagues

*Thread Reply:* 👋 Hi Julien. I’m Olessia, I’m working on the metadata collection implementation with Adam. Some thought on this:
*Thread Reply:* To start off, we’re thinking that there often isn’t a single owner, but rather a set of Stakeholders that evolve over time. So we’d like to be able to attach multiple entries, possibly of different types, to a Dataset. We’re also thinking that a dataset should have at least one owner. So a few things I’d like to confirm/discuss options:
- If I were to stay true to the spec as it’s defined atm I wouldn’t be able to add a required facet. True/false?
- According to the readme, “...emiting a new facet with the same name for the same entity replaces the previous facet instance for that entity entirely”. If we were to store multiple stakeholders, we’d have a field “stakeholders” and its value would be a list? This would make queries involving stakeholders not very straightforward. If the facet is overwritten every time, how do I a) add individuals to the list b) track changes to the list over time. Let me know what I’m missing, because based on what you said above tracking facet changes over time is possible.
- Run events are issued by a scheduler. Why should it be in the domain of the scheduler to know the entire list of Stakeholders?
- I noticed that Marquez has separate endpoints to capture information about Datasets, and some additional information beyond what’s described in the spec is required. In this context, we could add a required Stakeholder facets on a Dataset, and potentially even additional end points to add and remove Stakeholders. Is that a valid way to go about this, in your opinion?
Curious to hear your thoughts on all of this!
*Thread Reply:* > To start off, we’re thinking that there often isn’t a single owner, but rather a set of Stakeholders that evolve over time. So we’d like to be able to attach multiple entries, possibly of different types, to a Dataset. We’re also thinking > that a dataset should have at least one owner. So a few things I’d like to confirm/discuss options: > -> If I were to stay true to the spec as it’s defined atm I wouldn’t be able to add a required facet. True/false? Correct, The spec defines what facets looks like (and how you can make your own custom facets) but it does not make statements about whether facets are required. However, you can have your own validation and make certain things required if you wish to on the client side? > - According to the readme, “...emiting a new facet with the same name for the same entity replaces the previous facet instance for that entity entirely”. If we were to store multiple stakeholders, we’d have a field “stakeholders” and its value would be a list? Yes, I would indeed consider such a facet on the dataset with the stakeholder.
> This would make queries involving stakeholders not very straightforward. If the facet is overwritten every time, how do I > a) add individuals to the list You would provide the new list of stake holders. OpenLineage standardizes lineage collection and defines a format for expressing metadata. Marquez will keep track of how metadata has evolved over time.
> b) track changes to the list over time. Let me know what I’m missing, because based on what you said above tracking facet changes over time is possible. Each event is an observation at a point in time. In a sense they are each immutable. There’s a “current” version but also all the previous ones stored in Marquez. Marquez stores each version of a dataset it received through OpenLineage and exposes an API to see how that evolved over time.
> - Run events are issued by a scheduler. Why should it be in the domain of the scheduler to know the entire list of Stakeholders? The scheduler emits the information that it knows about. For example: “I started this job and it’s reading from this dataset and is writing to this other dataset.” It may or may not be in the domain of the scheduler to know the list of stakeholders. If not then you could emit different types of events to add a stakeholder facet to a dataset. We may want to refine the spec for that. Actually I would be curious to hear what you think should be the source of truth for stakeholders. It is not the intent to force everything coming from the scheduler.
- example 1: stakeholders are people on call for the job, they are defined as part of the job and that also enables alerting
- example 2: stakeholders are consumers of the jobs: they may be defined somewhere else
> - I noticed that Marquez has separate endpoints to capture information about Datasets, and some additional information beyond what’s described in the spec is required. In this context, we could add a required Stakeholder facets on a Dataset, and potentially even additional end points to add and remove Stakeholders. Is that a valid way to go about this, in your opinion?
*Thread Reply:* Marquez existed before OpenLineage. In particular the /run end-point to create and update runs will be deprecated as the OpenLineage /lineage endpoint replaces it. At the moment we are mapping OpenLineage metadata to Marquez. Soon Marquez will have all the facets exposed in the Marquez API. (See: https://github.com/MarquezProject/marquez/pull/894/files) We could make Marquez Configurable or Pluggable for validation purposes. There is already a notion of LineageListener for example. Although Marquez collects the metadata. I feel like this validation would be better upstream or with some some other mechanism. The question is when do you create a dataset vs when do you become a stakeholder? What are the various stakeholder and what is the responsibility of the minimum one stakeholder? I would probably make it required to deploy the job that the stakeholder is defined. This would apply to the output dataset and would be collected in Marquez.
In general, you are very welcome to make suggestion on additional endpoints for Marquez and I’m happy to discuss this further as those ideas are progressing.
> Curious to hear your thoughts on all of this! Thanks for taking the time!
*Thread Reply:* https://openlineage.slack.com/archives/C01CK9T7HKR/p1621887895004200
Thanks for the Python client submission @Maciej Obuchowski https://github.com/OpenLineage/OpenLineage/pull/34
 }
}
I also have added a spec to define a standard naming policy. Please review: https://github.com/OpenLineage/OpenLineage/pull/31/files
We now have a python client! Thanks @Maciej Obuchowski
Question, what do you folks see as the canonical mechanism for receiving OpenLineage events? Do you see an agent like statsd? Or do you see this as purely an API spec that services could implement? Do you see producers of lineage data writing code to send formatted OpenLineage payloads to arbitrary servers that implement receipt of these events? Curious what the long-term vision is here related to how an ecosystem of producers and consumers of payloads would interact?
*Thread Reply:* Marquez is the reference implementation for receiving events and tracking changes. But the definition of the API let’s other receive them (and also enables using openlineage events to sync between systems)
*Thread Reply:* In particular, Egeria is involved in enabling receiving and emitting openlineage
*Thread Reply:* Thanks @Julien Le Dem. So to get specific, if dbt were to emit OpenLineage events, how would this work? Would dbt Cloud hypothetically allow users to configure an endpoint to send OpenLineage events to, similar in UI implementation to configuring a Stripe webhook perhaps? And then whatever server the user would input here would point to somewhere that implements receipt of OpenLineage payloads? This is all a very hypothetical example, but trying to ground it in something I have a solid mental model for.

*Thread Reply:* hypothetically speaking, that all sounds right. so a user, who, e.g., has a dbt pipeline and an AWS glue pipeline could configure both of those projects to point to the same open lineage service and get their entire lineage graph even if the two pipelines aren't connected.
*Thread Reply:* Yeah, OpenLineage events need to be published to a backend (can be Kafka, can be a graphDB, etc). Your Stripe webhook analogy is aligned with how events can be received. For example, in Marquez, we expose a /lineage endpoint that consumes OpenLineage events. We then map an OpenLineage event to the Marquez model (sources, datasets, jobs, runs) that’s persisted in postgres.
*Thread Reply:* sorry, I was away last week. Yes that sounds right.

Hi everyone, I just started discovering OpenLineage and Marquez, it looks great and the quick-start tutorial is very helpful! One question though, I pushed some metadata to Marquez using the Lineage POST endpoint, and when I try to confirm that everything was created using Marquez REST API, everything is there ... but I don't see these new objects in the Marquez UI... what is the best way how to investigate where the issue is?
*Thread Reply:* Welcome, @Jakub Moravec (IBM/Manta) 👋 . Given that you're able to retrieve metadata using the marquezAPI, you should be able to also view dataset and job metadata in the UI. Mind using the search bar in the top right-hand corner in the UI to see if your metadata is searchable? The UI only renders jobs and datasets that are connected in the lineage graph. We're working towards a more general metadata exploration experience, but currently the lineage graph is the main experience.

Hi friends, we're exploring OpenLineage and while building out integration for existing systems we realized there is no obvious way for an input to specify what "version" of that dataset is being consumed. For example, we have a job that rolls up a variable number of what OpenLineage calls dataset versions. By specifying only that dataset, we can't represent the specific instances of it that are actually rolled up. We think that would be a very important part of the lineage graph.
Are there any thoughts on how to address specific dataset versions? Is this where custom input facets would come to play?
Furthermore, based on the spec, it appears that events can provide dataset facets for both inputs and outputs and this seems to open the door to race conditions in which two runs concurrently create dataset versions of a dataset. Is this where the eventTime field is supposed to be used?
*Thread Reply:* Your intuition is right here. I think we should define an input facet that specifies which dataset version is being read. Similarly you would have an output facet that specifies what version is being produced. This would apply to storage layers like Deltalake and Iceberg as well.
*Thread Reply:* Regarding the race condition, input and output facets are attached to the run. The version of the dataset that was read is an attribute of a run and should not modify the dataset itself.
*Thread Reply:* See the Dataset description here: https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md#core-lineage-model

Hi everyone! I’m exploring what existing, open-source integrations are available, specifically for Spark, Airflow, and Trino (PrestoSQL). My team is looking both to use and contribute to these integrations. I’m aware of the integration in the Marquez repo: • Spark: https://github.com/MarquezProject/marquez/tree/main/integrations/spark • Airflow: https://github.com/MarquezProject/marquez/tree/main/integrations/airflow Are there other efforts I should be aware of, whether for these two or for Trino? Thanks for any information!
*Thread Reply:* I think for Trino integration you'd be looking at writing a Trino extractor if I'm not mistaken, yes?
*Thread Reply:* But extractor would obviously be at the Marquez layer not OpenLineage
*Thread Reply:* And hopefully the metadata you'd be looking to extract from Trino wouldn't have any connector-specific syntax restrictions.

Hey all! Right now I am working on getting OpenLineage integrated with some microservices here at Northwestern Mutual and was looking for some advice. The current service I am trying to integrate it with moves files from one AWS S3 bucket to another so i was hoping to track that movement with OpenLineage. However by my understanding the inputs that would be passed along in a runEvent are meant to be datasets that have schema and other properties. But I wanted to have that input represent the file being moved. Is this a proper usage of Open Lineage? Or is this a use case that is still being developed? Any and all help is appreciated!
*Thread Reply:* This is a proper usage. That schema is optional if it’s not available.
*Thread Reply:* You would model it as a job reading from a folder (the input dataset) in the input bucket and writing to a folder (the output dataset) in the output bucket
*Thread Reply:* This is similar to how this is modeled in the spark integration (spark job reading and writing to s3 buckets)
*Thread Reply:* for reference: getting the urls for the inputs: https://github.com/MarquezProject/marquez/blob/c5e5d7b8345e347164aa5aa173e8cf35062[…]marquez/spark/agent/lifecycle/plan/HadoopFsRelationVisitor.java
 <a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* getting the output URL: https://github.com/MarquezProject/marquez/blob/c5e5d7b8345e347164aa5aa173e8cf35062[…]ark/agent/lifecycle/plan/InsertIntoHadoopFsRelationVisitor.java
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* See the spec (comments welcome) for the naming of S3 datasets: https://github.com/OpenLineage/OpenLineage/pull/31/files#diff-e3a8184544e9bc70d8a12e76b58b109051c182a914f0b28529680e6ced0e2a1cR87
*Thread Reply:* Hey Julien, thank you so much for getting back to me. I'll take a look at the documentation/implementations you've sent me and will reach out if I have anymore questions. Thanks again!
*Thread Reply:* @Julien Le Dem I left a quick comment on that spec PR you mentioned. Just wanted to let you know.

Hello all. I was reading through the OpenLineage documentation on GitHub and noticed a very minor typo (an instance where and should have been an). I was just about to create a PR for it but wanted to check with someone to see if that would be something that the team is interested in.
Thanks for the tool, I'm looking forward to learning more about it.
*Thread Reply:* Thank you! Please do fix typos, I’ll approve your PR.
*Thread Reply:* No problem. Here's the PR. https://github.com/OpenLineage/OpenLineage/pull/47
*Thread Reply:* Once I fixed the ones I saw I figured "Why not just run it through a spell checker just in case... " and found a few additional ones.

For your enjoyment, @Julien Le Dem was on the Data Engineering Podcast talking about OpenLineage!
https://www.dataengineeringpodcast.com/openlineage-data-lineage-specification-episode-187/
Also happened yesterday: OpenLineage being accepted by the LFAI&Data.
I have created a channel to discuss <#C022MMLU31B|user-generated-metadata> since this came up in a few discussions.

hey guys, does anyone have any sample openlineage schemas for S3 please? potentially including facets for attributes in a parquet file? that would help heaps thanks. i am trying to slowly bring in a common metadata interface and this will help shape some of the conversations 🙂 with a move to marquez/datahub et al over time
*Thread Reply:* We currently don’t have S3 (or distributed filesystem specific facets) at the moment, but such support would be a great addition! @Julien Le Dem would be best to answer if any work has been done in this area 🙂
*Thread Reply:* Also, happy to answer any Marquez specific questions, @Jonathon Mitchal when you’re thinking of making the move. Marquez supports OpenLineage out of the box 🙌
*Thread Reply:* @Jonathon Mitchal You can follow the naming strategy here for referring to a S3 dataset: https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md#s3
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* There is no facet yet for the attributes of a Parquet file. I can give you feedback if you want to start defining one. https://github.com/OpenLineage/OpenLineage/blob/main/CONTRIBUTING.md#proposing-changes
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Adding Parquet metadata as a facet would make a lot of sense. It is mainly a matter of specifying what the json would look like
*Thread Reply:* for reference the parquet metadata is defined here: https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift
<a href="https://github.com/apache/parquet-format">apache/parquet-format</a>
*Thread Reply:* Thats awesome, thanks for the guidance Willy and Julien ... will report back on how we get on

hi all! just wanted to introduce myself, I'm the Head of Data at Hightouch.io, we build reverse etl pipelines from the warehouse into various destinations. I've been following OpenLineage for a while now and thought it would be nice to build and expose our runs via the standard and potentially save that back to the warehouse for analysis/alerting. Really interesting concept, looking forward to playing around with it
*Thread Reply:* Welcome! Let use know if you have any questions

Hi all! I have a noob question. As I understand it, one of the main purposes of OpenLineage is to avoid runaway proliferation of bespoke connectors for each data lineage/cataloging/provenance tool to each data source/job scheduler/query engine etc. as illustrated in the problem diagram from the main repo below.
My understanding is that instead, things push to OpenLineage which provides pollable endpoints for metadata tools.
I’m looking at Amundsen, and it seems to have bespoke connectors, but these are pull-based - I don’t need to instrument my data resources to push to Amundsen, I just need to configure Amundsen to poll my data resources (e.g. the Postgres metadata extractor here).
Can OpenLineage do something similar where I can just point it at something to extract metadata from it, rather than instrumenting that thing to push metadata to OpenLineage? If not, I’m wondering why?
Is it the case that Open Lineage defines the general framework but doesn’t actually enforce push or pull-based implementations, it just so happens that the reference implementation (Marquez) uses push?
*Thread Reply:* > Is it the case that Open Lineage defines the general framework but doesn’t actually enforce push or pull-based implementations, it just so happens that the reference implementation (Marquez) uses push? Yes, at core OpenLineage just enforces format of the event. We also aim to provide clients - REST, later Kafka, etc. and some reference implementations - which are now in Marquez repo. https://raw.githubusercontent.com/OpenLineage/OpenLineage/main/doc/Scope.png
There are several differences between push and poll models. Most important one is that with push model, latency between your job and emitting OpenLineage events is very low. With some systems, with internal, push based model you have more runtime metadata available than when looking from outside. Another one would be that naive poll implementation would need to "rebuild the world" on each change. There are also disadvantages, such as that usually, it's easier to write plugin that extracts data from outside the system than hooking up to the internals.
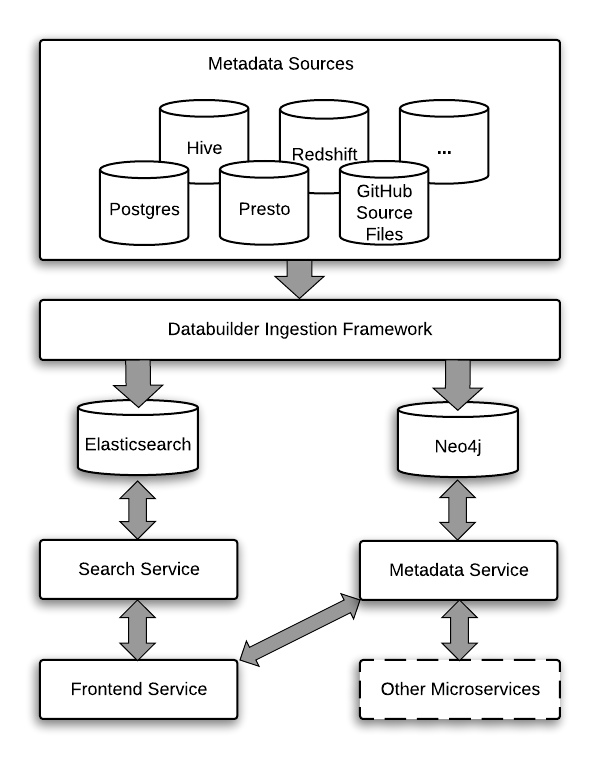
Integration with Amundsen specifically is planned. Although, right now it seems to me that way to do it is to bypass the databuilder framework and push directly to underlying database, such as Neo4j, or make Marquez backend for Metadata Service: https://raw.githubusercontent.com/amundsen-io/amundsen/master/docs/img/Amundsen_Architecture.png
*Thread Reply:* This is really helpful, thank you @Maciej Obuchowski!
*Thread Reply:* Similar to what you say about push vs pull, I found DataHub’s comment to be interesting yesterday: > Push is better than pull: While pulling metadata directly from the source seems like the most straightforward way to gather metadata, developing and maintaining a centralized fleet of domain-specific crawlers quickly becomes a nightmare. It is more scalable to have individual metadata providers push the information to the central repository via APIs or messages. This push-based approach also ensures a more timely reflection of new and updated metadata.
*Thread Reply:* yes. You can also “pull-to-push” for things that don’t push.

*Thread Reply:* @Maciej Obuchowski any particular reason for bypassing databuilder and go directly to neo4j? By design databuilder is supposed to be very abstract so any kind of backend can be used with Amundsen. Currently there are at least 4 and neo4j is just one of them.
*Thread Reply:* Databuilder's pull model is very different than OpenLineage's push model, where the events are generated while the dataset itself is generated.
So, how would you see using it? Just to proxy the events to concrete search and metadata backend?
I'm definitely not an Amundsen expert, so feel free to correct me if I'm getting it wrong.
*Thread Reply:* @Mariusz Górski my slide that Maciej is referring to might be a bit misleading. The Amundsen integration does not exist yet. Please add your input in the ticket: https://github.com/OpenLineage/OpenLineage/issues/86
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* thanks Julien! will take a look

@here Hello, My name is Kedar Rajwade. I happened to come across the OpenLineage project and it looks quite interesting. Is there some kind of getting start guide that I can follow. Also are there any weekly/bi-weekly calls that I can attend to know the current/future plans ?
*Thread Reply:* Welcome! You can look here: https://github.com/OpenLineage/OpenLineage/blob/main/CONTRIBUTING.md
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* We’re starting a monthly call, I will publish more details here
*Thread Reply:* Do you have a specific use case in mind?
The first instance of the OpenLineage Monthly meeting is tomorrow June 9 at 9am PT: https://calendar.google.com/event?action=TEMPLATE&tmeid=MDRubzk0cXAwZzA4bXRmY24yZjBkdTZzbDNfMjAyMTA2MDlUMTYwMDAwWiBqdWxpZW5AZGF0YWtpbi5jb20&tmsrc=julien%40datakin.com&scp=ALL|https://calendar.google.com/event?action=TEMPLATE&tmeid=MDRubzk0cXAwZzA4bXRmY24yZjBkdT[…]qdWxpZW5AZGF0YWtpbi5jb20&tmsrc=julien%40datakin.com&scp=ALL
*Thread Reply:* Hey @Julien Le Dem, I can’t add a link to my calendar… Can you send an invite?
*Thread Reply:* Will do. Also if you send your email in dm you can get added to the invite
*Thread Reply:* You can find the invitation on the tsc mailing list: https://lists.lfaidata.foundation/g/openlineage-tsc/topic/invitation_openlineage/83423919?p=,,,20,0,0,0::recentpostdate%2Fsticky,,,20,2,0,83423919
*Thread Reply:* @Julien Le Dem Can't access the calendar.
*Thread Reply:* Can you please share the meeting details
*Thread Reply:* The calendar invite says 9am PDT, not 10am. Which is right?
*Thread Reply:* I have posted the notes on the wiki (includes link to recording) https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+meeting+archive
Hi! Are there some 'close-to-real' sample events available to build off and compare to? I'd like to make sure what I'm outputting makes sense but it's hard when only comparing to very synthetic data.
*Thread Reply:* We’ve recently worked on a getting started guide for OpenLineage that we’d like to publish on the OpenLineage website. That should help with making things a bit more clear on usage. @Ross Turk / @Julien Le Dem might know of when that might become available. Otherwise, happy to answer any immediate questions you might have about posting/collecting OpenLineage events
*Thread Reply:* Here's a sample of what I'm producing, would appreciate any feedback if it's on the right track. One of our challenges is that 'dataset' is a little loosely defined for us as outputs since we take data from a warehouse/database and output to things like Salesforce, Airtable, Hubspot and even Slack.
{
eventType: 'START',
eventTime: '2021-06-09T08:45:00.395+00:00',
run: { runId: '2821819' },
job: {
namespace: '<hightouch://my-workspace>',
name: '<hightouch://my-workspace/sync/123>'
},
inputs: [
{
namespace: '<snowflake://abc1234>',
name: '<snowflake://abc1234/my_source_table>'
}
],
outputs: [
{
namespace: '<salesforce://mysf_instance.salesforce.com>',
name: 'accounts'
}
],
producer: 'hightouch-event-producer-v.0.0.1'
}
{
eventType: 'COMPLETE',
eventTime: '2021-06-09T08:45:30.519+00:00',
run: { runId: '2821819' },
job: {
namespace: '<hightouch://my-workspace>',
name: '<hightouch://my-workspace/sync/123>'
},
inputs: [
{
namespace: '<snowflake://abc1234>',
name: '<snowflake://abc1234/my_source_table>'
}
],
outputs: [
{
namespace: '<salesforce://mysf_instance.salesforce.com>',
name: 'accounts'
}
],
producer: 'hightouch-event-producer-v.0.0.1'
}
*Thread Reply:* One other question I have is really around how customers might take the metadata we emit at Hightouch and integrate that with OpenLineage metadata emitted from other tools like dbt, Airflow, and other integrations to create a true lineage of their data.
For example, if the data goes from S3 -> Snowflake via Airflow and then from Snowflake -> Salesforce via Hightouch, this would mean both Airflow/Hightouch would need to define the Snowflake dataset in exactly the same way to get the benefits of lineage?
*Thread Reply:* Hey, @Dejan Peretin! Sorry for the late replay here! Your OL events look solid and only have a few of suggestions:
- I would use a valid UUID for the run ID as the spec will standardize on that type, see https://github.com/OpenLineage/OpenLineage/pull/65
- You don’t need to provide the input dataset again on the
COMPLETEevent as the input datasets have already been associated with the run ID - For the producer, I’d recommend using a link to the producer source code version to link the producer version with the OL event that was emitted.
*Thread Reply:* You can now reference our OL getting started guide for a close-to-real example 🙂 , see http://openlineage.io/getting-started
*Thread Reply:* > … this would mean both Airflow/Hightouch would need to define the Snowflake dataset in exactly the same way to get the benefits of lineage? Yes, the dataset and the namespace that it was registered under would have to be the same to properly build the lineage graph. We’re working on defining unique dataset names and have made some good progress in this area. I’d suggest reviewing the OL naming conventions if you haven’t already: https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md
*Thread Reply:* Thanks! I'm really excited to see what the future holds, I think there are so many great possibilities here. Will be keeping a watchful eye. 🙂
Hey everyone! I've been running into a minor OpenLineage issue and I was curious if anyone had any advice. So according to OpenLineage specs its suggested that for a dataset coming from S3 that its namespace be in the form of s3://<bucket>. We have implemented our code to do so and RunEvents are published without issue but when trying to retrieve the information of this RunEvent (like the job) I am unable to retrieve it based on namespace from both /api/v1/namespaces/s3%3A%2F%2F<bucket name> (encoding since : and / are special characters in URL) and the beta endpoint of /api/v1-beta/lineage?nodeId=<dataset>:<namespace>:<name> and instead get a 400 error with a "Ambiguous Segment in URI" message.
Any and all advice would be super helpful! Thank you so much!
*Thread Reply:* Sounds like problem is with Marquez - might be worth to open issue here: https://github.com/MarquezProject/marquez/issues
*Thread Reply:* Thank you! Will do.
I have opened a proposal for versioning and publishing the spec: https://github.com/OpenLineage/OpenLineage/issues/63
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
We have a nice OpenLineage website now. https://openlineage.io/ Thank you to contributors: @Ross Turk @Willy Lulciuc @Michael Collado!

Hi everyone! Im trying to run a spark job with openlineage and marquez...But Im getting some errors
*Thread Reply:* Here is the error...
21/06/20 11:02:56 WARN ArgumentParser: missing jobs in [, api, v1, namespaces, spark_integration] at 5
21/06/20 11:02:56 WARN ArgumentParser: missing runs in [, api, v1, namespaces, spark_integration] at 7
21/06/20 11:03:01 ERROR AsyncEventQueue: Listener SparkListener threw an exception
java.lang.NullPointerException
at marquez.spark.agent.SparkListener.onJobEnd(SparkListener.java:165)
at org.apache.spark.scheduler.SparkListenerBus$class.doPostEvent(SparkListenerBus.scala:39)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus$class.postToAll(ListenerBus.scala:91)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$super$postToAll(AsyncEventQueue.scala:92)
at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply$mcJ$sp(AsyncEventQueue.scala:92)
at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87)
at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:87)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:83)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1302)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:82)
*Thread Reply:* Here is my code ...
```from pyspark.sql import SparkSession from pyspark.sql.functions import lit
spark = SparkSession.builder \ .master('local[1]') \ .config('spark.jars.packages', 'io.github.marquezproject:marquezspark:0.15.2') \ .config('spark.extraListeners', 'marquez.spark.agent.SparkListener') \ .config('openlineage.url', 'http://localhost:5000/api/v1/namespaces/spark_integration/') \ .config('openlineage.namespace', 'sparkintegration') \ .getOrCreate()
Supress success
spark.sparkContext.jsc.hadoopConfiguration().set('mapreduce.fileoutputcommitter.marksuccessfuljobs', 'false') spark.sparkContext.jsc.hadoopConfiguration().set('parquet.summary.metadata.level', 'NONE')
dfsourcetrip = spark.read \ .option('inferSchema', True) \ .option('header', True) \ .option('delimiter', '|') \ .csv('/Users/bcanal/Workspace/poc-marquez/pocspark/resources/data/source/trip.csv') \ .createOrReplaceTempView('sourcetrip')
dfdrivers = spark.table('sourcetrip') \ .select('driver') \ .distinct() \ .withColumn('drivername', lit('Bruno')) \ .withColumnRenamed('driver', 'driverid') \ .createOrReplaceTempView('source_driver')
df = spark.sql( """ SELECT d., t. FROM sourcetrip t, sourcedriver d WHERE t.driver = d.driver_id """ )
df.coalesce(1) \ .drop('driverid') \ .write.mode('overwrite') \ .option('path', '/Users/bcanal/Workspace/poc-marquez/pocspark/resources/data/target') \ .saveAsTable('trip')```
*Thread Reply:* After this execution, I can see just the source from first dataframe called dfsourcetrip...
*Thread Reply:* I was expecting to see all source dataframes, target dataframes and the job
*Thread Reply:* I`m running spark local on my laptop and I followed marquez getting start to up it
*Thread Reply:* I think there's a race condition that causes the context to be missing when the job finishes too quickly. If I just add
spark.sparkContext.setLogLevel('info')
to the setup code, everything works reliably. Also works if you remove the master('local[1]') - at least when running in a notebook

i need to implement export functionality for my data lineage project.
as part of this i need to convert the information fetched from graph db (neo4j) to CSV format and send in response.
can someone please direct me to the CSV format of open lineage data
*Thread Reply:* Hey, @anup agrawal. This is a great question! The OpenLineage spec is defined using the Json Schema format, and it’s mainly for the transport layer of OL events. In terms of how OL events are eventually stored, that’s determined by the backend consumer of the events. For example, Marquez stores the raw event in a lineage_events table, but that’s mainly for convenience and replayability of events . As for importing / exporting OL events from storage, as long as you can translate the CSV to an OL event, then HTTP backends like Marquez that support OL can consume them
*Thread Reply:* > as part of this i need to convert the information fetched from graph db (neo4j) to CSV format and send in response. Depending on the exported CSV, I would translate the CSV to an OL event, see https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.json
*Thread Reply:* When you say “send in response”, who would be the consumer of the lineage metadata exported for the graph db?
*Thread Reply:* so far what i understood about my requirement is that. 1. my service will receive OL events
*Thread Reply:* 2. store it in graph db (neo4j)
*Thread Reply:* 3. this lineage information will be displayed on ui, based on the request.
- now my part in that is to implement an Export functionality, so that someone can download it from UI. in UI there will be option to download the report.
- so i need to fetch data from storage and convert it into CSV format, send to UI
- they can download the report from UI.
SO my question here is that i have never seen how that CSV report look like and how do i achieve that ? when i had asked my team how should CSV look like they directed me to your website.
*Thread Reply:* I see. @Julien Le Dem might have some thoughts on how an OL event would be represented in different formats like CSV (but, of course, there’s also avro, parquet, etc). The Json Schema is the recommended format for importing / exporting lineage metadata. And, for a file, each line would be an OL event. But, given that CSV is a requirement, I’m not sure how that would be structured. Or at least, it’s something we haven’t previously discussed
i am very new to this .. sorry for any silly questions
*Thread Reply:* There are no silly questions! 😉

Hello, I have read every topic and listened to 4 talks and the podcast episode about OpenLineage and Marquez due to my basic understanding for the data engineering field, I have a couple of questions which I did not understand: 1- What are events and facets and what are their purpose? 2- Can I implement the OpenLineage API to any software? or does the software needs to be integrated with the OpenLineage API? 3- Can I say that OpenLineage is about observability and Marquez is about collecting and storing the metadata? Thank you all for being cooperative.
*Thread Reply:* Welcome, @Abdulmalik AN 👋 Hopefully the talks / podcasts have been informative! And, sure, happy to clarify a few things:
> What are events and facets and what are their purpose? An OpenLineage event is used to capture the lineage metadata at a point in time for a given run in execution. That is, the runs state transition, the inputs and outputs consumed/produced and the job associated with the run are part of the event. The metadata defined in the event can then be consumed by an HTTP backend (as well as other transport layers). Marquez is an HTTP backend implementation that consumes OL events via a REST API call. The OL core model only defines the metadata that should be captured in the context of a run, while the processing of the event is up to the backend implementation consuming the event (think consumer / producer model here). For Marquez, the end-to-end lineage metadata is stored for pipelines (composed of multiple jobs) with built-in metadata versioning support. Now, for the second part of your question: the OL core model is highly extensible via facets. A facet is user-defined metadata and enables entity enrichment. I’d recommend checking out the getting started guide for OL 🙂
> Can I implement the OpenLineage API to any software? or does the software needs to be integrated with the OpenLineage API? Do you mean HTTP vs other protocols? Currently, OL defines an API spec for HTTP backends, that Marquez has adopted to ingest OL events. But there are also plans to support Kafka and many others.
> Can I say that OpenLineage is about observability and Marquez is about collecting and storing the metadata? > Thank you all for being cooperative. Yep! OL defines the metadata to collect for running jobs / pipelines that can later be used for root cause analysis / troubleshooting failing jobs, while Marquez is a metadata service that implements the OL standard to both consume and store lineage metadata while also exposing a REST API to query dataset, job and run metadata.
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi OpenLineage team! Has anyone got this working on databricks yet? I’ve been working on this for a few days and can’t get it to register lineage. I’ve attached my notebook in this thread.
silly question - does the jar file need be on the cluster? Which versions of spark does OpenLineage support?
*Thread Reply:* I based my code on this previous post https://openlineage.slack.com/archives/C01CK9T7HKR/p1624198123045800
 }
}
*Thread Reply:* In your first cell, you have
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
spark.sparkContext.setLogLevel('info')
unfortunately, the reference to sparkContext in the third line forces the initialization of the SparkContext so that in the next cell, your new configuration is ignored. In pyspark, you must initialize your SparkSession before any references to the SparkContext. It works if you remove the setLogInfo call from the first cell and make your 2nd cell
spark = SparkSession.builder \
.config('spark.jars.packages', 'io.github.marquezproject:marquez_spark:0.15.2') \
.config('spark.extraListeners', 'marquez.spark.agent.SparkListener') \
.config('openlineage.url', '<https://domain.com>') \
.config('openlineage.namespace', 'my-namespace') \
.getOrCreate()
spark.sparkContext.setLogLevel('info')

How would one capture lineage for job that's processing streaming data? Is that in scope for OpenLineage?
*Thread Reply:* It’s absolutely in scope! We’ve primarily focused on the batch use case (ETL jobs, etc), but the OpenLineage standard supports both batch and streaming jobs. You can check out our roadmap here, where you’ll find Flink and Beam on our list of future integrations.
*Thread Reply:* Is there a streaming framework you’d like to see added to our roadmap?

*Thread Reply:* Welcome, @mohamed chorfa 👋 . Let’s us know if you have any questions!
*Thread Reply:* Really looking follow the evolution of the specification from RawData to the ML-Model
Hello OpenLineage community, We have been working on fleshing out the OpenLineage roadmap. See on github on the currently prioritized effort: https://github.com/OpenLineage/OpenLineage/projects Please add your feedback to the roadmap by either commenting on the github issues or opening new issues.
In particular, I have opened an issue to finalize our mission statement: https://github.com/OpenLineage/OpenLineage/issues/84
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Based on community feedback, The new proposed mission statement: “to enable the industry at-large to collect real-time lineage metadata consistently across complex ecosystems, creating a deeper understanding of how data is produced and used”
I have updated the proposal for the spec versioning: https://github.com/OpenLineage/OpenLineage/issues/63
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi all. I'm trying to get my bearings on openlineage. Love the concept. In our data transformation pipelines, output datasets are explicitly versioned (we have an incrementing snapshot id). Our storage layer (deltalake) allows us to also ingest 'older' versions of the same dataset, etc. If I understand it correctly I would have to add some inputFacets and outputFacets to run to store the actual version being referenced. Is that something that is currently available, or on the roadmap, or is it something I could extend myself?
*Thread Reply:* It is on the roadmap and there’s a ticket open but nobody is working on it at the moment. You are very welcome to contribute a spec and implementation
*Thread Reply:* Please comment here and feel free to make a proposal: https://github.com/OpenLineage/OpenLineage/issues/35
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
TL;DR: our database supports time-travel, and runs can be set up to use a specific point-in-time of an input. How do we make sure to keep that information within openlineage
Hi, on a subject of spark integrations - I know that there is spark-marquez but was curious did you also consider https://github.com/AbsaOSS/spline-spark-agent ? It seems like this and spark-marquez are doing similar thing and maybe it would make sense to add openlineage support to spline spark agent?
*Thread Reply:* cc @Julien Le Dem @Maciej Obuchowski
*Thread Reply:* @Michael Collado
The OpenLineage Technical Steering Committee meetings are Monthly on the Second Wednesday 9:00am to 10:00am US Pacific and the link to join the meeting is https://us02web.zoom.us/j/81831865546?pwd=RTladlNpc0FTTDlFcWRkM2JyazM4Zz09 The next meeting is this Wednesday All are welcome. • Agenda: ◦ Finalize the OpenLineage Mission Statement ◦ Review OpenLineage 0.1 scope ◦ Roadmap ◦ Open discussion ◦ Slides: https://docs.google.com/presentation/d/1fD_TBUykuAbOqm51Idn7GeGqDnuhSd7f/edit#slide=id.ge4b57c6942_0_46 notes are posted here: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting.,.,_
*Thread Reply:* Feel free to share your email with me if you want to be added to the gcal invite

Hello, is it possible to track lineage on column level? For example for SQL like this:
CREATE TABLE T2 AS SELECT c1,c2 FROM T1;
I would like to record this lineage:
T1.C1 -- job1 --> T2.C1
T1.C2 -- job1 --> T2.C2
Would that be possible to record in OL format?
(the important thing for me is to be able to tell that T1.C1 has no effect on T2.C2)
I have updated the notes and added the link to the recording of the meeting this morning: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
*Thread Reply:* In particular, please review the versioning proposal: https://github.com/OpenLineage/OpenLineage/issues/63
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* and the mission statement: https://github.com/OpenLineage/OpenLineage/issues/84
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* for this one, please give explicit approval in the ticket
*Thread Reply:* @Zhamak Dehghani @Daniel Henneberger @Drew Banin @James Campbell @Ryan Blue @Maciej Obuchowski @Willy Lulciuc ^
*Thread Reply:* Per the votes in the github ticket, I have finalized the charter here: https://docs.google.com/document/d/11xo2cPtuYHmqRLnR-vt9ln4GToe0y60H/edit

Hi Everyone. I am PMC member and committer of Apache Airflow. Watched the talk at the summit https://airflowsummit.org/sessions/2021/data-lineage-with-apache-airflow-using-openlineage/ and thought I might help (after the Summit is gone 🙂 with making OpenLineage/Marquez more seemlesly integrated in Airflow

*Thread Reply:* The demo in this does not really use the openlineage spec does it?
Did I miss something - the API that was should for lineage was that of Marquez, how does Marquest use the open lineage spec?
*Thread Reply:* I have a question about the SQLJobFacet in the job schema - isn't it better to call it the TransformationJob Facet or the ProjecessJobFacet such that any logic in the appropriate language and be described? Am I misinterpreting the intention of SQLJobFacet is to capture the logic that runs for a job?
*Thread Reply:* > The demo in this does not really use the openlineage spec does it?
@Samia Rahman In our Airflow talk, the demo used the marquez-airflow lib that sends OpenLineage events to Marquez’s
*Thread Reply:* > Did I miss something - the API that was should for lineage was that of Marquez, how does Marquest use the open lineage spec?
Yes, Marquez ingests OpenLineage events that confirm to the spec via the

Hi all, does OpenLineage intend on creating lineage off of query logs?
From what I have read, there are a number of supported integrations but none that cater to regular SQL based ETL. Is this on the OpenLineage roadmap?
*Thread Reply:* I would say this is more of an ingestion pattern, then something the OpenLineage spec would support directly. Though I completely agree, query logs are a great source of lineage metadata with minimal effort. On our roadmap, we have Kafka as a supported backend which would enable streaming lineage metadata from query logs into a topic. That said, confluent has some great blog posts on Change Data Capture: • https://www.confluent.io/blog/no-more-silos-how-to-integrate-your-databases-with-apache-kafka-and-cdc/ • https://www.confluent.io/blog/simplest-useful-kafka-connect-data-pipeline-world-thereabouts-part-1/
*Thread Reply:* Q: @Kenton (swiple.io) Are you planning on using Kafka connect? If so, I see 2 reasonable options:
- Stream query logs to a topic using the JDBC source connector, then have a consumer read the query logs off the topic, parse the logs, then stream the result of the query parsing to another topic as an OpenLineage event
- Add direct support for OpenLineage to the JDBC connector or any other application you planned to use to read the query logs.
*Thread Reply:* Either way, I think this is a great question and a common ingestion pattern we should document or have best practices for. Also, more details on how you plan to ingestion the query logs would be help drive the discussion.
*Thread Reply:* Using something like sqlflow could be a good starting point? Demo https://sqlflow.gudusoft.com/?utm_source=gspsite&utm_medium=blog&utm_campaign=support_article#/
*Thread Reply:* @Kenton (swiple.io) I haven’t heard of sqlflow but it does look promising. It’s not on our current roadmap, but I think there is a need to have support for parsing query logs as OpenLineage events. Do you mind opening an issue and outlining you thoughts? It’d be great to start the discussion if you’d like to drive this feature and help prioritize this 💯
The openlineage implementation for airflow and spark code integration currently lives in Marquez repo, my understanding from the open lineage scope is that the the integration implementation is the scope of open lineage, are the spark code migrations going to be moved to open lineage?
@Samia Rahman Yes, that is the plan. For details you can see https://github.com/OpenLineage/OpenLineage/issues/73
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
I have a question about the SQLJobFacet in the job schema - isn't it better to call it the TransformationJob Facet or the ProjecessJobFacet such that any logic in the appropriate language and be described, can be scala or python code that runs in the job facet and processing streaming or batch data? Am I misinterpreting the intention of SQLJobFacet is to capture the logic that runs for a job?
*Thread Reply:* Hey, @Samia Rahman 👋. Yeah, great question! The SQLJobFacet is used only for SQL-based jobs. That is, it’s not intended to capture the code being executed, but rather the just the SQL if it’s present. The SQL fact can be used later for display purposes. For example, in Marquez, we use the SQLJobFacet to display the SQL executed by a given job to the user via the UI.
*Thread Reply:* To capture the logic of the job (meaning, the code being executed), the OpenLineage spec defines the SourceCodeLocationJobFacet that builds the link to source in version control
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
The process started a few months back when the LF AI & Data voted to accept OpenLineage as part of the foundation. It is now official, OpenLineage joined the LFAI & data Foundation. https://lfaidata.foundation/blog/2021/07/22/openlineage-joins-lf-ai-data-as-new-sandbox-project/


Hi, I am trying to create lineage between two datasets. Following the Spec, I can see the syntax for declaring the input and output datasets, and for all creating the associated Job (which I take to be the process in the middle joining the two datasets together). What I can't see is where in the specification to relate the job to the inputs and outputs. Do you have an example of this?
*Thread Reply:* The run event is always tied to exactly one job. It's up to the backend to store the relationship between the job and its inputs/outputs. E.g., in marquez, this is where we associate the input datasets with the job- https://github.com/MarquezProject/marquez/blob/main/api/src/main/java/marquez/db/OpenLineageDao.java#L132-L143
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
the OuputStatistics facet PR is updated based on your comments @Michael Collado https://github.com/OpenLineage/OpenLineage/pull/114
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* /|~~~
///|
/////|
///////|
/////////|
\==========|===/
~~~~~~~~~~~~~~~~~~~~~
I have updated the DataQuality metrics proposal and the corresponding PR: https://github.com/OpenLineage/OpenLineage/issues/101 https://github.com/OpenLineage/OpenLineage/pull/115
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Guys, I've merged circleCI publish snapshot PR
Snapshots can be found bellow: https://datakin.jfrog.io/artifactory/maven-public-libs-snapshot-local/io/openlineage/openlineage-java/0.0.1-SNAPSHOT/ openlineage-java-0.0.1-20210804.142910-6.jar https://datakin.jfrog.io/artifactory/maven-public-libs-snapshot-local/io/openlineage/openlineage-spark/0.1.0-SNAPSHOT/ openlineage-spark-0.1.0-20210804.143452-5.jar
Build on main passed (edited)
I added a mechanism to enforce spec versioning per: https://github.com/OpenLineage/OpenLineage/issues/63 https://github.com/OpenLineage/OpenLineage/pull/140
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi all, at Booking.com we’re using Spline to extract granular lineage information from spark jobs to be able to trace lineage on column-level and the operations in between. We wrote a custom python parser to create graph-like structure that is sent into arangodb. But tbh, the process is far from stable and is not able to quickly answer questions like ‘which root input columns are used to construct column x’.
My impression with openlineage thus far is it’s focusing on less granular, table input-output information. Is anyone here trying to accomplish something similar on a column-level?

*Thread Reply:* Also interested in use case / implementation differences between Spline and OL. Watching this thread.
*Thread Reply:* It would be great to have the option to produce the spline lineage info as OpenLineage. To capture the column level lineage, you would want to add a ColumnLineage facet to the Output dataset facets. Which is something that is needed in the spec. Here is a proposal, please chime in: https://github.com/OpenLineage/OpenLineage/issues/148 Is this something you would be interested to do?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* regarding the difference of implementation, the OpenLineage spark integration focuses on extracting metadata and exposing it as a standard representation. (The OpenLineage LineageEvents described in the JSON-Schema spec). The goal is really to have a common language to express lineage and related metadata across everything. We’d be happy if Spline can produce or consume OpenLineage as well and be part of that ecosystem.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Does anyone know if the Spline developers are in this slack group?
*Thread Reply:* @Luke Smith how have things progressed on your side the past year?
I have opened an issue to track the facet versioning discussion: https://github.com/OpenLineage/OpenLineage/issues/153
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
I have updated the agenda to the OpenLineage monthly TSC meeting: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting (meeting information bellow for reference, you can also DM me your email to get added to a google calendar invite)
The OpenLineage Technical Steering Committee meetings are Monthly on the Second Wednesday 9:00am to 10:00am US Pacific and the link to join the meeting is https://us02web.zoom.us/j/81831865546?pwd=RTladlNpc0FTTDlFcWRkM2JyazM4Zz09 All are welcome.
Aug 11th 2021
• Agenda:
◦ Coming in OpenLineage 0.1
▪︎ OpenLineage spec versioning
▪︎ Clients
◦ Marquez integrations imported in OpenLineage
▪︎ Apache Airflow:
• BigQuery
• Postgres
• Snowflake
• Redshift
• Great Expectations
▪︎ Apache Spark
▪︎ dbt
◦ OpenLineage 0.2 scope discussion
▪︎ Facet versioning mechanism
▪︎ OpenLineage Proxy Backend (
*Thread Reply:* Just a reminder that this is in 2 hours
*Thread Reply:* I have added the notes to the meeting page: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
*Thread Reply:* The recording of the meeting is linked there: https://us02web.zoom.us/rec/share/2k4O-Rjmmd5TYXzT-pEQsbYXt6o4V6SnS6Vi7a27BPve9aoMmjm-bP8UzBBzsFzg.uY1je-PyT4qTgYLZ?startTime=1628697944000 • Passcode: =RBUj01C

Hi guys, great discussion today. Something we are particularly interested on is the integration with Airflow 2. I've been searching into Marquez and Openlineage repos and I couldn't find a clear answer on the status of that. I did some work locally to update the marquez-airflow package but I would like to know if someone else is working on this and maybe we could give it some help too.
*Thread Reply:* @Daniel Avancini I'm working on it. Some changes in airflow made current approach unfeasible, so slight change in a way how we capture events is needed. You can take a look at progress here: https://github.com/OpenLineage/OpenLineage/tree/airflow/2
*Thread Reply:* Thank you Maciej. I'll take a look
I have migrated the Marquez issues related to OpenLineage integrations to the OpenLineage repo
And OpenLineage 0.1.0 is out ! https://github.com/OpenLineage/OpenLineage/releases/tag/0.1.0
PR ready for review
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Anyone have experience parsing spark's logical plan to generate column-level lineage and DAGs with more human readable operations? I assume I could recreate a graph like the one below using the spark.logicalPlan facet. The analysts writing the SQL / spark queries aren't familiar with ShuffledRowRDD , MapPartitionsRDD, etc... It'd be better if I could convert this plan into spark SQL (or capture spark SQL as a facet at runtime).
*Thread Reply:* The logicalPlan facet currently returns the Logical Plan, not the physical plan. This means you end up with expressions like Aggregate and Join rather than WholeStageCodegen and Exchange. I don't know if it's possible to reverse engineer the SQL- it's worth looking into the API and trying to find a way to generate that

Nice to e-meet you 🙂 I want to use OpenLineage integration for spark in my Azure Databricks clusters, but I am having problems with the configuration of the listener in the cluster, I was wondering if you could help me, if you know any tutorial for the integration of spark with Azure Databricks that can help me, or some more specific guide for this scenario, I would really appreciate it.
*Thread Reply:* Hey, @Erick Navarro 👋 . Are you using the openlineage-spark lib? (Note, the marquez-spark lib has been deprecated)
*Thread Reply:* My team had this issue as well. Our read of the error is that Databricks attempts to register the listener before installing packages defined with either spark.jars or spark.jars.packages. Since the listener lib is not yet installed, the listener cannot be found. To solve the issue, we
- copy the OL JAR to a staging directory on DBFS (we use
/dbfs/databricks/init/lineage) - using an init script, copy the JAR from the staging directory to the default JAR location for the Databricks driver --
/mnt/driver-daemon/jars - Within the same init script, write the spark config parameters to a
.conffile in/databricks/driver/conf(we useopen-lineage.conf) The.conffile will be read by the driver on initialization. It should follow this format (lineagehosturl should point to your API):[driver] { "spark.jars" = "/mnt/driver-daemon/jars/openlineage-spark-0.1-SNAPSHOT.jar" "spark.extraListeners" = "com.databricks.backend.daemon.driver.DBCEventLoggingListener,openlineage.spark.agent.OpenLineageSparkListener" "spark.openlineage.url" = "$lineage_host_url" }Your cluster must be configured to call the init script (enabling lineage for entire cluster). OL is not friendly to notebook-level init as far as we can tell.
@Willy Lulciuc -- I have some utils and init script templates that simplify this process. May be worth adding them to the OL repo along with a readme.
*Thread Reply:* Absolutely, thanks for elaborating on your spark + OL deployment process and I think that’d be great to document. @Michael Collado what are your thoughts?
*Thread Reply:* I haven't tried with Databricks specifically, but there should be no issue registering the OL listener in the Spark config as long as it's done before the Spark session is created- e.g., this example from the README works fine in a vanilla Jupyter notebook- https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#openlineagesparklistener-as-a-plain-spark-listener
*Thread Reply:* Looks like Databricks' notebooks come with a Spark instance pre-configured- configuring lineage within the SparkSession configuration doesn't seem possible- https://docs.databricks.com/notebooks/notebooks-manage.html#attach-a-notebook-to-a-cluster 😞
*Thread Reply:* Right, Databricks provides preconfigured spark context / session objects. With Spline, you can set some cluster level config (e.g. spark.spline.lineageDispatcher.http.producer.url ) and install the library on the cluster, but then enable tracking at a notebook level with:
%scala
import za.co.absa.spline.harvester.SparkLineageInitializer._
sparkSession.enableLineageTracking()
In OL, it would be nice to install and config OL at a cluster level, but to enable it at a notebook level. This way, users could control whether all notebooks run on a cluster emit lineage or just those with lineage explicitly enabled.
*Thread Reply:* Seems, at the very least, we need to provide a way to specify the job name at the notebook level
*Thread Reply:* Agreed. I'd like a default that uses the notebook name that can also be overridden in the notebook.
*Thread Reply:* if you have some insight into the available options, it would be great if you can open an issue on the OL project. I'll have to carve out some time to play with a databricks cluster and learn what options we have
*Thread Reply:* Is this error thrown during init or job execution?
*Thread Reply:* this is likely a race condition- I've seen it happen for jobs that start and complete very quickly- things like defining temp views or similar
*Thread Reply:* During the execution of the job @Luke Smith, thank you @Michael Collado, that was exactly the scenario, the job that I executed was empty, now the cluster is running ok, I don't have errors, I have run some jobs successfully, but I don't see any information in my datakin explorer
*Thread Reply:* Awesome! Great to hear you’re up and running. For datakin specific questions, mind if we move the discussion to the datakin user slack channel?
*Thread Reply:* I found the solution here: https://docs.microsoft.com/en-us/answers/questions/170730/handshake-fails-trying-to-connect-from-azure-datab.html
*Thread Reply:* It works now! 😄
*Thread Reply:* @Erick Navarro This might be a helpful to add to our openlineage spark docs for others trying out openlineage-spark with Databricks. Let me know if that’s something you’d like to contribute 🙂
*Thread Reply:* Yes of course @Willy Lulciuc, I will prepare a small tutorial for my colleagues and I will share it with you 🙂

Hello everyone! I am currently evaluating OpenLineage and am finding it very interesting as Prefect is in the list of integrations. However, I am not seeing any documentation or code for this. How far are you from supporting Prefect?
*Thread Reply:* Hey! If you mean this picture, it provides concept of how OpenLineage works, not current state of integration. We don't have Prefect support yet; hovewer, it's on our roadmap.
 <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Thomas Fredriksen Feel free to chime in the github issue Maciej linked if you want.
What's the timeline to support spark 3.0 within OL? One breaking change we've found is within DatasetSourceVisitor.java -- the DataSourceV2 is deprecated in spark 3.0. There may be other issues we haven't found yet. Is there a good feel for the scope of work required to make OL spark 3.0 compatible?
*Thread Reply:* It is being worked on right now. @Oleksandr Dvornik is adding an integration test in the build so that we run test for both spark 2.4 and spark 3. Please open an issue with the stack trace if you can. From our perspective, it should be mostly compatible with a few exceptions like this one that we’d want to add test cases for.
*Thread Reply:* The goal is to be able to make a release in the next few weeks. The integration is being used with Spark 3 already.
*Thread Reply:* Great, I'll take some time to open an issue for this particular issue and a few others.
*Thread Reply:* are you actually using the DatasetSource interface in any capacity? Or are you just scanning the source code to find incompatibilities?
*Thread Reply:* Turns out this has more to do with a how Databricks handles the delta format. It's related to https://github.com/AbsaOSS/spline-spark-agent/issues/96.
<a href="https://github.com/AbsaOSS/spline-spark-agent">AbsaOSS/spline-spark-agent</a>
*Thread Reply:* I haven't been chasing this issue down on my team -- turns out some things were lost in communication. There are really two problems here:
- When attempting to do delta I/O with Spark 3 on Databricks, e.g.
insert into . . . values . . .We get an error related to DataSourceV2:java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation.source()Lorg/apache/spark/sql/sources/v2/DataSourceV2; - Using Spline, which is Spark 3 compatible, we have issues with the way Databricks handles delta table io. This is related: https://github.com/AbsaOSS/spline-spark-agent/issues/96
So there are two stacked issues related to spark 3 on Databricks with delta IO, not just one. Hope this clears things up.
<a href="https://github.com/AbsaOSS/spline-spark-agent">AbsaOSS/spline-spark-agent</a>
*Thread Reply:* So, the first issue is OpenLineage related directly, and the second issue applies to both OpenLineage and Spline?
*Thread Reply:* Yes, that's my read of what I'm getting from others on the team.
*Thread Reply:* For the first issue- can you give some details about the target of the INSERT INTO... ? Is it a data source defined in Databricks? a Hive table? a view on GCS?
*Thread Reply:* oh, it's a Delta table?
*Thread Reply:* Yes, it's created via
CREATE TABLE . . . using DELTA location "/dbfs/mnt/ . . . "
I have opened a PR to fix some outdated language in the spec: https://github.com/OpenLineage/OpenLineage/pull/241 Thank you @Mandy Chessell for the feedback
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
The next OpenLineage monthly meeting is next week. Please chime in this thread if you’d like something added to the agenda

*Thread Reply:* Apache Beam integration? I have a very crude integration at the moment. Maybe it’s better to integrate on the orchestration level (airflow, luigi). Thoughts?
*Thread Reply:* I think it makes a lot of sense to have a Beam level integration similar to the spark one. Feel free to post a draft PR if you want to share.
*Thread Reply:* I have added Beam as a topic for the roadmap discussion slide: https://docs.google.com/presentation/d/1fI0u8aE0iX9vG4GGrnQYAEcsJM9z7Rlv/edit#slide=id.ge7d4b64ef4_0_0
I have prepared slides for the OpenLineage meeting tomorrow morning: https://docs.google.com/presentation/d/1fI0u8aE0iX9vG4GGrnQYAEcsJM9z7Rlv/edit#slide=id.ge7d4b64ef4_0_0
*Thread Reply:* There will be a quick demo of the dbt integration (thanks @Willy Lulciuc!)
*Thread Reply:* Information to join and archive of previous meetings: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
*Thread Reply:* The recording and notes are now available: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting

*Thread Reply:* Good meeting today. @Julien Le Dem. Thanks

Hello, was looking to get some lineage out for BQ in my Airflow DAGs and saw that the BQ extractor here - https://github.com/OpenLineage/OpenLineage/blob/main/integration/airflow/openlineage/airflow/extractors/bigquery_extractor.py#L47 is using an operator that has been deprecated by Airflow - https://github.com/apache/airflow/blob/main/airflow/contrib/operators/bigquery_operator.py#L44 and most of my DAGs are using the operator BigQueryExecuteQueryOperator mentioned there. I presume with this lineage extraction wouldn’t work and some work is needed to support both these operators with the same ( or differnt) extractor. Is that correct or am I missing something ?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* We're working on updating our integration to airflow 2. Some changes in airflow made current approach unfeasible, so slight change in a way how we capture events is needed. You can take a look at progress here: https://github.com/OpenLineage/OpenLineage/tree/airflow/2
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* Thanks @Maciej Obuchowski When is this expected to land in a release ?

*Thread Reply:* hi @Maciej Obuchowski I wanted to follow up on this to understand when the more recent BQ Operators will be supported, specifically BigQueryInsertJobOperator
The PR to separate facets in their own file (and allowing versioning them independently) is now available: https://github.com/OpenLineage/OpenLineage/pull/118
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi, new to the channel but I think OL is a great initiative. Currently we are focused on beam/spark/delta but are moving to beam/flink/iceberg and I’m happy to help where I can.
Per the discussion last week, Ryan updated the metadata that would be available in Iceberg: https://github.com/OpenLineage/OpenLineage/issues/167#issuecomment-917237320
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
I have also created tickets for follow up discussions: (#269 and #270): https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting

Hello. I find OpenLineage an interesting tool however can someone help me with integration?
I am trying to capture lineage from spark 3.1.1 but when executing i constantly get: java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.v2.WriteToDataSourceV2.writer()Lorg/apache/spark/sql/sources/v2/writer/DataSourceWriter;
at openlineage.spark.agent.lifecycle.plan.DatasetSourceVisitor.findDatasetSource(DatasetSourceVisitor.java:57) as if i would be using openlineage on wrong spark version (2.4) I have tried also spark jar from branch feature/itspark3. Is there any branch or release that works or can be tried with spark 3+?
*Thread Reply:* Hello Tomas. We are currently working on support for spark v3. Can you please raise an issue with stack trace, that would help us to track and solve it. We are currently adding integration tests. Next step would be fix changes in method signatures for v3 (that's what you have)
*Thread Reply:* Hi @Oleksandr Dvornik i raised https://github.com/OpenLineage/OpenLineage/issues/272
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
I also tried to downgrade spark to 2.4.0 and retry with 0.2.2 but i also faced issue.. so my preferred way would be to push for spark 3.1.1 but depends a bit on when you plan to release version supporting it. As backup plan i would try spark 2.4.0 but this is blocking me also: https://github.com/OpenLineage/OpenLineage/issues/274
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think this might be actually spark issue: https://stackoverflow.com/questions/53787624/spark-throwing-arrayindexoutofboundsexception-when-parallelizing-list/53787847

*Thread Reply:* Can you try newer version in 2.4.** line, like 2.4.7?
*Thread Reply:* This might be also spark 2.4 with scala 2.12 issue - I'd recomment 2.11 versions.
*Thread Reply:* @Maciej Obuchowski with 2.4.7 i get following exc:
*Thread Reply:* 21/09/14 15:03:25 WARN RddExecutionContext: Unable to access job conf from RDD java.lang.NoSuchFieldException: config$1 at java.base/java.lang.Class.getDeclaredField(Class.java:2411)
*Thread Reply:* i can also try to switch to 2.11 scala
*Thread Reply:* or do you have some recommended setup that works for sure?
*Thread Reply:* One more check - you're using Java 8 with this, right?
*Thread Reply:* This is what works for me:
-> % cat tools/spark-2.4/RELEASE
Spark 2.4.8 (git revision 4be4064) built for Hadoop 2.7.3
Build flags: -B -Pmesos -Pyarn -Pkubernetes -Pflume -Psparkr -Pkafka-0-8 -Phadoop-2.7 -Phive -Phive-thriftserver -DzincPort=3036
*Thread Reply:* spark-shell:
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_292)
*Thread Reply:* data has been sent to marquez. coolio. however i noticed nullpointer being thrown: 21/09/14 15:23:53 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
java.lang.NullPointerException
at io.openlineage.spark.agent.OpenLineageSparkListener.onJobEnd(OpenLineageSparkListener.java:164)
at org.apache.spark.scheduler.SparkListenerBus$class.doPostEvent(SparkListenerBus.scala:39)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus$class.postToAll(ListenerBus.scala:91)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$super$postToAll(AsyncEventQueue.scala:92)
at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply$mcJ$sp(AsyncEventQueue.scala:92)
at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87)
at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:87)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:83)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1302)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:82)
does openlineage capture streaming in spark? as this example is not showing me anything unless i replace readStream() with batch read() and writeStream() with write() ```SparkSession.Builder builder = SparkSession.builder(); SparkSession session = builder .appName("quantweave") .master("local[**]") .config("spark.jars.packages", "io.openlineage:openlineage_spark:0.2.2") .config("spark.extraListeners", "io.openlineage.spark.agent.OpenLineageSparkListener") .config("spark.openlineage.url", "http://localhost:5000/api/v1/namespaces/spark_integration/") .getOrCreate();
Dataset<Row> df = session
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "topic1")
.option("startingOffsets", "earliest")
.load();
Dataset<Row> dff = df
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as("data");
dff
.writeStream()
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("topic", "topic2")
.option("checkpointLocation", "/tmp/checkpoint")
.start();```
*Thread Reply:* Not at the moment, but it is in scope. You are welcome to open an issue with your example to track this or even propose an implementation if you have the time.
*Thread Reply:* @Tomas Satka it would be great, if you can add an containerized integration test for kafka with your test case. You can take this as an example here
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Oleksandr Dvornik i wrote a test for simple read/write from kafka topic using kafka testcontainer. However i discovered a bug. When writing to kafka topic getting java.lang.IllegalArgumentException: One of the following options must be specified for Kafka source: subscribe, subscribepattern, assign. See the docs for more details.
• How would you like me to add the test? Fork openlineage and create PR
*Thread Reply:* • Shall i raise bug for writing to kafka that should have only "topic" instead of "subscribe"
*Thread Reply:* • Since i dont know expected payload to openlineage mock server can somebody help me to create it?
*Thread Reply:* Hi @Tomas Satka, yes you should create a fork and raise a PR from that. For more details, please take a look at. Not sure about kafka, cause we don't have that integration yet. About expected payload, as a first step, I would suggest to leave that test without assertion for now. Second step would be investigation (what we can get from that plan node). Third step - implementation and asserting a payload. Basically we parse spark optimized plan, and get as much information as we can for specific implementation. You can take a look at recent PR for HIVE. We visit root node and leaves to get output datasets and input datasets accordingly.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Oleksandr Dvornik PR for step one : https://github.com/OpenLineage/OpenLineage/pull/279
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
There may not be an answer to these questions yet, but I'm curious about the plan for Tableau lineage.
• How will this integration be packaged and attached to Tableau instances? ◦ via Extensions API, REST API? • What is the architecture? https://github.com/OpenLineage/OpenLineage/issues/78
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hi everyone - Following up on my previous post on prefect. The technical integration does not seem very difficult, but I am wondering about how to structure the lineage logic. Is it the case that each prefect task should be mapped to a lineage job? If so, how do we connect the jobs together? Does there have to be a dataset between each job? I am OpenLineage with Marquez by the way
*Thread Reply:* Hey Thomas!
Following what we do with Airflow, yes, I think that each task should be mapped to job.
You don't need datasets between each tasks. It's necessary only where you consume and produce datasets - and it does not matter where in uour job graph you've produced them.
To map tasks togther In Airflow, we use ParentRunFacet , and the same approach could be used here. In Prefect, I think using flow_run_id would work.
*Thread Reply:* this is very helpful, thank you
*Thread Reply:* what would be the namespace used in the Job -definition of each task?
*Thread Reply:* In contrast to dataset namespaces - which we try to standardize, job namespaces should be provided by user, or operator of particular scheduler.
For example, it would be good if it helped you identify Prefect instance where the job was run.
*Thread Reply:* If you use openlineage-python client, you can provide namespace either in client constuctor, or via OPENLINEAGE_NAMESPACE env variable.

*Thread Reply:* Hey @Thomas Fredriksen - just chiming in, I’m also keen for a prefect integration. Let me know if I can help out at all
*Thread Reply:* Please chime in on https://github.com/OpenLineage/OpenLineage/issues/81
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* For now I'm prototyping in a separate repo https://github.com/limx0/caching_flow_runner/tree/open_lineage
*Thread Reply:* I really like your PR, @Brad. I think that using FlowRunner and TaskRunner may be a more "proper" way of doing this, as opposed as adding a state-handler to each task the way I do it.
How are you dealing with Prefect-library tasks such as the included BigQuery-tasks and such? Is it necessary to create DatasetTask for them to show up in the lineage graph?
*Thread Reply:* Hey @Thomas Fredriksen! At the moment I'm not dealing with any task-specific things. The plan (in my head, and after speaking with another prefect user @davzucky) would be that we add a LineageTask subclass where you could define custom facets on a per task basis
*Thread Reply:* or some sort of other hook where basically you would define some lineage attribute or put something in the prefect.context that the TaskRunner would find and attach
*Thread Reply:* Sorry I misread your question - any tasks should be automatically tracked (I believe but have not tested yet!)
*Thread Reply:* @Brad Could you elaborate a bit on your ideas around adding custom context attributes?
*Thread Reply:* yeah so basically we just need some hooks that you can easily access from the task decorator or somewhere else that we can pass through to the open lineage adapter to do things like custom facets
*Thread Reply:* like for your bigquery example - you might want to record some facets like in https://github.com/OpenLineage/OpenLineage/blob/main/integration/common/openlineage/common/provider/bigquery.py and we need a way to do that with the Prefect bigquery task
*Thread Reply:* I see. Is this supported by the airflow-integration?
*Thread Reply:* The airflow code is here https://github.com/OpenLineage/OpenLineage/blob/main/integration/airflow/openlineage/airflow/extractors/bigquery_extractor.py
*Thread Reply:* (I don't actually use airflow or bigquery - but for my own use case I can see wanting to do thing like this)
*Thread Reply:* Interesting, I like how dynamic this is

HI all, I have a clarification question about dataset namespaces. What's the difference between a dataset namespace (in the input/output) and a dataSource name (in the dataSource facet)?
The dbt integration appears to set those to the same value (e.g. <snowflake://myprofile>), however it seems that Marquez assumes the dataset namespace to be a more generic concept (similar to a nice user provided name like the job namespace).
*Thread Reply:* Hey.
Generally, dataSource name should be namespace of particular dataset.
In some cases, like Postgres, dataSource facet is used to provide additionally connection strings, with info like particular host and port that we're connected to.
In case of Snowflake - or Bigquery, or S3, or multiple systems where we have only "global" instance, so the dataSource facet does not carry any other additional information.
*Thread Reply:* Thanks. So then perhaps marquez could differentiate a bit more between job & dataset namespaces. Right now it doesn't quite feel right to have a single global list of namespaces for jobs & datasets, especially as they also have a separate concept of sources (which are not in a namespace).
*Thread Reply:* @Willy Lulciuc what do you think?
*Thread Reply:* As an example, in marquez I have this list of namespaces (from some sample data): dbt-sales, default, <snowflake://my-account1>, <snowflake://my-account2>.
I think the new marquez UI with the nice namespace dropdown and job/dataset search is awesome, and I'd expect to be able to filter by job namespace everywhere, but how about being able to filter datasets by source (which would be populated by the OL dataset namespace) and not persist dataset namespaces in the global namespace table?
The dbt integration (https://github.com/OpenLineage/OpenLineage/tree/main/integration/dbt) is pretty awesome but there are still a few improvements we could make.
Here are a few thoughts.
• In dbt-ol if the configuration is wrong or missing we will fail silently. This one seems like a good first thing to fix by logging the error to stdout
• We need to wait until the end to know if it worked at all. It would be nice if we checked the config at the beginning and display an error right away. Possibly by adding a parent job/run with a start event at the beginning and an end event at the end when all is done.
• While we are sending events at the end the console will hang until it’s done. It’s not clear that progress is made. We could have a simple progress bar by printing a dot for every event sent. (ex: sending 10 OpenLineage events: .........)
• We could also write at the beginning that the OL events will be sent at the end so that the user knows what to expect.
What do you think? (@Maciej Obuchowski in particular, but anyone using dbt in general)
*Thread Reply:* Last point is that we should persist the configuration and not just have it in environment variables. What is the best way to do this in dbt?
*Thread Reply:* We could have something similar to https://docs.getdbt.com/dbt-cli/configure-your-profile - or even put our config in there
*Thread Reply:* I think we should assume that variables/config should be set and valid - and fail the run if they aren't. After all, if someone wouldn't need lineage events, they wouldn't use our wrapper.
*Thread Reply:* 3rd point would be easy to address if we could send events async/in parallel. But there could be dataset version dependencies, and we don't want to get into needless complexity of recognizing that, building a dag etc.
We could batch events if the network roundtrips are responsible for majority of the slowdown. However, we can't assume any particular environment.
Maybe just notifying about the progress is the best thing we can do right now.
*Thread Reply:* About second point, I want to add recognizing if we already have a parent run - for example, if running via airflow. If not, creating run for this purpose is a good idea.
*Thread Reply:* @Maciej Obuchowski can you open github issues to propose those changes?
*Thread Reply:* FWIW, I have been putting my config in ~/.openlineage/config so it can be mapped into a container
*Thread Reply:* Makes sense, also, all clients could use that config

*Thread Reply:* if dbt could actually stream the events, that would be great.
*Thread Reply:* Unfortunately, this seems very unlikely for now, due to the fact that we rely on metadata files that dbt only produces after end of execution.
The split of facets in their own schemas is ready to be merged: https://github.com/OpenLineage/OpenLineage/pull/118
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hey @Julien Le Dem I'm going to start a thread here for any issues I run into trying to build a prefect integration
*Thread Reply:* This might be useful to others https://github.com/OpenLineage/OpenLineage/pull/284
*Thread Reply:* So I'm trying to push a simple event to marquez, but getting the following response:
'{"code":400,"message":"Unable to process JSON"}'
The JSON I'm pushing:
{
"eventTime": "2021-09-16T04:00:28.343702",
"eventType": "START",
"inputs": {},
"job": {
"facets": {},
"name": "prefect.core.parameter.p",
"namespace": "default"
},
"producer": "<https://github.com/OpenLineage/OpenLineage/tree/0.0.0/integration/prefect>",
"run": {
"facets": {},
"runId": "3bce33cb-9495-4c58-b326-6aac71634ace"
}
}
Does anything look obviously wrong here?
*Thread Reply:* What I did previously when debugging something like this was to remove half of the payload until I found the culprit. Binary search essentially. I was running Marquez locally, so probably could’ve enabled better logging as well. Aren’t inputs and facets arrays?
*Thread Reply:* Thanks for the response @marko - this is a greatly reduced payload already (but I'll keep going). Yep they are supposed to be arrays (I've since fixed that)
*Thread Reply:* Okay - I've got a simply working example now https://github.com/limx0/caching_flow_runner/blob/open_lineage/caching_flow_runner/task_runner.py
<a href="https://github.com/limx0/caching_flow_runner">limx0/caching_flow_runner</a>
*Thread Reply:* I might move this into a proper PR @Julien Le Dem
A question about DatasetType - is there a representation for a file-like type? For files stored in S3/FTP/NFS etc (assuming a fully resolvable url)
*Thread Reply:* I think there was some talk somewhere to actually drop the DatasetType concept; can't find where though.
*Thread Reply:* I've taken a look at your repo. Looks great so far!
One thing I've noticed I don't think you need to use any stuff from Marquez to emit events. It's lineage ingestion API is deprecated - you can just use openlineage-python client. If there's something you think it's missing from it, feel free to write that here or open issue.
*Thread Reply:* And would that be replaced by just some Input/Output notion @Maciej Obuchowski?
*Thread Reply:* Oh yeah I got a little confused by the single lineage endpoint - but I’ve realised how it all works now. I’m still using the marquez backend to view things but I’ll use the openlineage-client to talk to it
When trying to fix failing checks, i see integration-test-integration-airflow to fail ```#!/bin/bash -eo pipefail if [[ GCLOUDSERVICEKEY,GOOGLEPROJECTID == "" ]]; then echo "No required environment variables to check; moving on" else IFS="," read -ra PARAMS <<< "GCLOUDSERVICEKEY,GOOGLEPROJECTID"
for i in "${PARAMS[@]}"; do if [[ -z "${!i}" ]]; then echo "ERROR: Missing environment variable {i}" >&2
if [[ -n "" ]]; then
echo "" >&2
fi
exit 1
else
echo "Yes, ${i} is defined!"
fi
done fi
ERROR: Missing environment variable {i}
Exited with code exit status 1 CircleCI received exit code 1``` However i havent touch airflow at all.. can somebody help please?
*Thread Reply:* Hey, Airflow integration tests do not pass env variables to PRs from forks due to security reasons - everyone could create malicious PR and dump secrets
*Thread Reply:* So, they will fail and there's nothing to do from your side 🙂
*Thread Reply:* We probably should split those into ones that don't touch external systems, and run those for all PRs
*Thread Reply:* ah okie. good to know. and in build-integration-spark Could not resolve all artifacts. Is that also known issue? Or something from my side that i could fix?
*Thread Reply:* Looks like gradle server problem?
> Could not get resource '<https://plugins.gradle.org/m2/com/diffplug/spotless/spotless-lib/2.13.2/spotless-lib-2.13.2.module>'.
> Could not GET '<https://plugins.gradle.org/m2/com/diffplug/spotless/spotless-lib/2.13.2/spotless-lib-2.13.2.module>'. Received status code 500 from server: Internal Server Error
*Thread Reply:* After retry, there's spotless error:
+········.orElse(Collections.emptyList()).stream()
*Thread Reply:* I think this is due to mismatch between behavior of spotless in Java 8 and Java 11+ - which you probably used 🙂
*Thread Reply:* ah.. i used java11. so shall i rerun something with java8 setup as sdk?
*Thread Reply:* For spotless, you can just fix this one line 🙂 Though I don't guarantee that tests that run later will pass, so you might need Java 8 for later testing
*Thread Reply:* will somebody please review my PR? had to already adjust due to updates on same test class 🙂
Hey team - I've opened https://github.com/OpenLineage/OpenLineage/pull/293 for a very WIP prefect integration
*Thread Reply:* @Thomas Fredriksen would love any feedback
*Thread Reply:* nicely done! As we discussed in another thread - the way you have implemented lineage using FlowRunner and TaskRunner is likely the best way to do this. Let me know if you need any help, I would love to see this PR get merged!
*Thread Reply:* Hey @Brad, it looks great!
I've seen you're using task_qualified_name to name datasets and I don't think it's the right way.
I'd take a look at naming conventions here: https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md
Getting that right is key to making sure that lineage is properly tracked between systems - for example, if you use Prefect to schedule dbt runs or pyspark jobs, the unified naming makes sure that all those integrations properly refer to the same dataset.
*Thread Reply:* Hey @Maciej Obuchowski thanks for the feedback. Yep the naming was a bit of a placeholder. Open to any recommendations.. I think things like dbt or pyspark are straight forward (we could add special handling for tasks like that) but what about regular transformation type tasks that run in a scheduler? Do you have any naming preference? Say I just had some pandas transform task in prefect for example
*Thread Reply:* First of all, not all tasks are producing and consuming datasets. For example, I wouldn't expect any of the Github tasks to have any datasets.
Second, in Airflow we have a concept of Extractor where you can write specialized code to expose datasets. For example, for BigQuery we extract datasets from query plan. Now, I'm not sure if this concept would translate well to Prefect - but if yes, then we have some helpers inside openlineage common library that could be reused. Also, this way allows to emit additional facets, some of which are really useful - like query statistics for BigQuery, and data quality tests for dbt.
Third, if we're talking about generalized tasks like FunctionTask or ShellTask, then I think the right way is to expose functionality to user to expose lineage themselves. I'm not sure how exactly that would look in Prefect.
*Thread Reply:* You've raised some good points @Maciej Obuchowski - I might have been thinking about this integration in slightly the wrong way. I think based on your comments I'll refactor some of the code to hook into the Results object in prefect (The Result object is the way in which data is serialized and persisted).
> Now, I'm not sure if this concept would translate well to Prefect - but if yes, then we have some helpers inside openlineage common library that could be reused This definitely applies to prefect and the similar tasks exist in prefect and we should definitely leverage the common library in this case.
> Third, if we're talking about generalized tasks like FunctionTask or ShellTask, then I think the right way is to expose functionality to user to expose lineage themselves. I'm not sure how exactly that would look in Prefect. Yeah I agree with this. I'd like to make it as easy a possible to opt-in, but I think you're right that there needs to be some hooks for user defined lineage. I'll think about this a little more.
> First of all, not all tasks are producing and consuming datasets. For example, I wouldn't expect any of the Github tasks to have any datasets. My initial thoughts here were that it would still be good to have lineage as these tasks do have side effects, and downstream consumers of the lineage data might want to know about these tasks. However I don't have a good feeling yet how best to do this, so I'm going to park those thoughts for now.
*Thread Reply:* > Yeah I agree with this. I'd like to make it as easy a possible to opt-in, but I think you're right that there needs to be some hooks for user defined lineage. I'll think about this a little more. First version of an integration doesn't have to be perfect. in particular, not handling this use case would be okay, since it does not lock us into some particular way of doing it later.
> My initial thoughts here were that it would still be good to have lineage as these tasks do have side effects, and downstream consumers of the lineage data might want to know about these tasks. However I don't have a good feeling yet how best to do this, so I'm going to park those thoughts for now. I'd think of two options first, before modeling it as a dataset: Won't existence of a event be enough? After all, we'll still have it despite it not having any input and output datasets. If not, then wouldn't custom run or job facet be a better fit?
*Thread Reply:* > Won’t existence of a event be enough? After all, we’ll still have it despite it not having any input and output datasets. Duh, yep you’re right @Maciej Obuchowski, I’m over thinking this. I’m going to clean this up based on your comments
*Thread Reply:* Hi @Brad. How will this integration work for Prefect flows running in Prefect Cloud or on Prefect Server?
*Thread Reply:* Hi @Thomas Fredriksen - it'll relate to the agent actually - you'll need to pass the flow runner class to the agent when running
*Thread Reply:* Unfortunately I've been a little busy the past week, and I will be for the rest of this week
*Thread Reply:* but I do plan to pick this up next week
*Thread Reply:* (the additional changes I mention above)
*Thread Reply:* looking forward to it 🙂 let me know if you need any help!
*Thread Reply:* yeah when I get this next lot of stuff in - I'd love for people to test it out

Is there a preferred academic citation for OpenLineage? I’m writing a paper on the provenance system in our machine learning library, and I’d like to cite OpenLineage as an example of future work on data lineage to integrate with.
*Thread Reply:* I think you can reffer to https://openlineage.io/
We’re starting to see the beginning of larger contributions (Spark streaming, prefect, …) and I think we need to define a way to accept those contributions incrementally. If we take the example of Streaming (Spark streaming, Flink or Beam) support (but really this applies in general, sorry to pick on you Tomas, this is great!): The first Spark streaming PR ( https://github.com/OpenLineage/OpenLineage/pull/279 ) lays the ground work for testing spark streaming but there’s more work to have a full feature. I’m in favor of merging Spark streaming support into main once it’s working end to end (possibly with partial input/output coverage). So I see 2 options:
- start a branch for spark streaming support. Have PRs like this one go into it until it’s completed (smaller reviews). Then merge the whole thing as a PR in main when it’s finished
- Keep working on that PR until it’s fully implemented, but it will get big, and make reviews difficult. I have seen the model 1) work well. It’s easier to do multiple smaller reviews for larger projects.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Thank you @Ross Turk for this really useful article: https://openlineage.io/blog/dbt-with-marquez/?s=03 Is anyone aware of additional environment being supported by the dbt<->OpenLineage<->Marquez integration ? I think only Snowflake and BigQuery are supported now. I am really interested by SQLServer or even Dremio (which could be great because capable of read from multiples DB).
Thank you
*Thread Reply:* It should be really easy to add additional databases. Basically, we'd need to know how to get namespace for that database: https://github.com/OpenLineage/OpenLineage/blob/main/integration/common/openlineage/common/provider/dbt.py#L467
The first step should be to add SQLServer or Dremio to the dataset naming schema here https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you @Maciej Obuchowski, I tried to give it a try but without success yet. Not sure where I am suppose to add the sqlserver naming schema... If you have any documentation that I could read I would be glad =) Many thanks
*Thread Reply:* This would be adding a paragraph similar to this one: https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md#snowflake
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Snowflake See: Object Identifiers — Snowflake Documentation Datasource hierarchy: • account name Naming hierarchy: • Database: {database name} => unique across the account • Schema: {schema name} => unique within the database • Table: {table name} => unique within the schema Identifier: • Namespace: snowflake://{account name} ◦ Scheme = snowflake ◦ Authority = {account name} • Name: {database}.{schema}.{table} ◦ URI = snowflake://{account name}/{database}.{schema}.{table}

Hi all. I'm the Founder / CTO of a data discovery & transformation platform that captures very rich lineage information. We're interested in exposing / making our lineage data consumable via open standards, which is what lead me to this project. A couple of questions:
A) Am I right in considering that's the goal of this project? B) Are you also considering provedance as well as lineage? C) What's a good starting point to understand the models we should be exposing our data in, to make it consumable?
*Thread Reply:* For clarity on the provedance vs lineage point (in case I'm using those terms incorrectly...)
Our platform performs automated enrichment and processing of data. In doing so, we often make calls to functions or out to other data services (such as APIs, or SELECTs against databases). We capture the inputs that pass to these, along with the outputs. (And, if the input is derived from other outputs, we capture the full chain, right back to the root).
That's the kinda stuff our customers are really interested in, and we feel like there's value in making is consumable.
*Thread Reply:* Not sure I understand you right, but are you interested in tracking individual API calls, and for example, values of some parameters passed for one call?
*Thread Reply:* I guess that's not in OpenLineage scope, as we're interested more in tracking metadata for whole datasets. But I might be wrong, some other people might chime in.
We could of course model this situation, but that would capture for example schema of those parameters. Not their values.
*Thread Reply:* I think this might be better suited for https://opentelemetry.io/
*Thread Reply:* Kinda, but not really. Telemetery data is metadata about the API calls. We have that, but it's not interesting to our customers. It's the metadata about the data that Vyne provides that we want to expose.
Our customers use Vyne to fetch data from lots of different sources. Eg:
> "Whenever a trade is booked, calculate it's compliance against these regulations, to report to the regulators". or
> "Whenever a customer buys a $thing, capture the transaction data, client data, and account data, and store it in this table." Providing answers to those questions involves fetching and transforming data, before storing it, or outputting it. We capture all that data, on a per-attribute basis, so we can answer the question "how did we get this value?" That's the lineage information we want to publish.
*Thread Reply:* The core OpenLineage model is documented at https://github.com/OpenLineage/OpenLineage/#core-model . The model is really focused on Jobs and Datasets. Jobs have Runs which have start and end times (typically scheduled start/end times as well) and read from and/or write to the target datasets. If your transformation chain fits within that model, then I think you can definitely record and share the lineage information with your customers. The existing implementations are all focused on batch data access, though streaming should be possible to capture as well

Hello. I am trying the openlineage-airflow integration with Marquez as the backend and have 3 questions.
- Does it only work for PostgresOperators?
- Which is the recommended integration: marquez-airflow or openlineage-airflow
- How do you enable more detailed logging? I tried OPENLINEAGELOGLEVEL and MARQUEZLOGLEVEL and neither seemed to affect logging. I assume this is logged to the airflow worker

*Thread Reply:* Hello @Drew Bittenbender!
For your two first questions:
• Yes right now only the PostgresOperator is integrated. I learnt it the hard way ^_^. Spent hours trying with MySQL. There were attempts to integrate with MySQL actually. If engineers do not integrate it I will allocate myself some time to try to implement other airflow db operators.
• Use the openlineage one. It is the recommended approach now.
*Thread Reply:* Thank you @Faouzi. Is there any documentation/best practices to write your own extractor, or is it "read the code"? We use the Python, Docker and SSH operators a lot. Maybe those don't fit into the lineage paradigm well, but want to give it a shot
*Thread Reply:* To the best of my knowledge there is no documentation to guide through the design of your own extractor. So yes we need to read the code. Here a link where you can see how they did for postgre extractor and others. https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow/openlineage/airflow/extractors
*Thread Reply:* I think in case of "bring your own code" operators like Python or Docker ones, it might be better to use lineage_run_id macro and use openlineage-python library inside, instead of implementing extractor.
*Thread Reply:* I think @Maciej Obuchowski is right here. The airflow integration will create the parent jobs, but to get the dataset input/output links, it's best to do that directly from the python/docker scripts. If you report the parent run id, Marquez will link the jobs together correctly
*Thread Reply:* To clarify on what airflow operators are supported out of the box: • postgres • bigquery • snowflake • Great expectations (with extra config) See: https://github.com/OpenLineage/OpenLineage/blob/3a1ccbd854bbf202bbe6437bf81786cb01[…]ntegration/airflow/openlineage/airflow/extractors/extractors.py Mysql is not at the moment. We should track it as an issue
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi there! I’m trying to enhance the lineage functionality of a data infrastructure I’m working on. All of the tools I found only visualize the relationships between tables before and after the transformation, but the DataHub RFC discusses Field Level Lineage, which I thought was close to the functionality I was looking for. Does OpenLineage support the same functionality? https://datahubproject.io/docs/rfc/active/1841-lineage/field_level_lineage/
*Thread Reply:* OpenLineage doesn’t have field level lineage yet. Here is the proposal for adding it: https://github.com/OpenLineage/OpenLineage/issues/148
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Those two specs look compatible, so Datahub should be able to consume this lineage metadata in the future

Hello, everyone. I'm trying to work with OL and Airflow 2.1.4 and it doesn't work. I found that OL is supported for Airflow 1.10.12++. Does it support Airflow 2.X.Y?
*Thread Reply:* Hi! Airflow 2.x is currently in development - you can follow along with the progress here: https://github.com/OpenLineage/OpenLineage/issues/205
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* There should be a first version of Airflow 2.X support soon: https://github.com/OpenLineage/OpenLineage/pull/305 We’re labelling it experimental because the config step might change as discussion in the airflow github evolve. It will track succesful jobs in its current state.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi All, I’m working on openlineage-dbt integration with Marquez as backend. I want to integrate OL with DBT cloud, would you please help to provide steps that I need to follow?
*Thread Reply:* Take a look at this: https://docs.getdbt.com/docs/dbt-cloud/dbt-cloud-api/metadata/metadata-overview
*Thread Reply:* @SAM Let us know of your progress.

Hey folks 😊
I’m trying to run dbt-ol with Redshift target, but I get the following error message
Traceback (most recent call last):
File "/usr/local/bin/dbt-ol", line 61, in <module>
main()
File "/usr/local/bin/dbt-ol", line 54, in main
events = processor.parse().events()
File "/usr/local/lib/python3.8/site-packages/openlineage/common/provider/dbt.py", line 97, in parse
self.extract_dataset_namespace(profile)
File "/usr/local/lib/python3.8/site-packages/openlineage/common/provider/dbt.py", line 368, in extract_dataset_namespace
self.dataset_namespace = self.extract_namespace(profile)
File "/usr/local/lib/python3.8/site-packages/openlineage/common/provider/dbt.py", line 382, in extract_namespace
raise NotImplementedError(
NotImplementedError: Only 'snowflake' and 'bigquery' adapters are supported right now. Passed redshift
I know that Redshift is not the best cloud DWH we can use… 😅
But, still….do you have any plan to support it?
Thanks!
*Thread Reply:* Hey, can you create ticket in OpenLineage repository? FWIW Redshift is very similar to postgres, so supporting it won't be hard.
*Thread Reply:* Hey @Maciej Obuchowski 😊 Yep, will do now! Thanks!
*Thread Reply:* Well...will do tomorrow morning 😅
*Thread Reply:* Here’s the issue: https://github.com/OpenLineage/OpenLineage/issues/318
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks a lot. I pulled it in the current project.
*Thread Reply:* @Julien Le Dem @Maciej Obuchowski I’m not familiar with dbt-ol codebase, but I’m willing to help on this if you guys can give me a bit of guidance 😅
*Thread Reply:* @ale can you help us define naming schema for redshift, as we have for other databases? https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md
*Thread Reply:* will work on this today and I’ll try to submit a PR by EOD
*Thread Reply:* There you go https://github.com/OpenLineage/OpenLineage/pull/324
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Host would be something like
examplecluster.<XXXXXXXXXXXX>.<a href="http://us-west-2.redshift.amazonaws.com">us-west-2.redshift.amazonaws.com</a>
right?
*Thread Reply:* If you want to look at dbt integration itself, there are two things:
We need to determine how Redshift adapter reports metrics https://github.com/OpenLineage/OpenLineage/blob/610a687bf69df2b52ec4ac4da80b4a05580e8d32/integration/common/openlineage/common/provider/dbt.py#L412
And how we can create namespace and job name based on the job naming schema that you created: https://github.com/OpenLineage/OpenLineage/blob/610a687bf69df2b52ec4ac4da80b4a05580e8d32/integration/common/openlineage/common/provider/dbt.py#L512
One thing how to get this info is to run the dbt yourself and look at resulting metadata files - in target dir of the dbt directory
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I figured out how to generate the namespace.
But I can’t understand which of the JSON files is inspected for metrics. Is it run_results.json ?
*Thread Reply:* yes, run_results.json - it's different in bigquery and snowflake, so I presume it's different in redshift too
*Thread Reply:* Regarding namespace: if env_var is used in profiles.yml , how is this handled now?
*Thread Reply:* Well, it isn't. This is relevant only if you passed cluster hostname this way, right?
*Thread Reply:* If you think it make sense, I can submit a PR to handle dbt profile with env_var
*Thread Reply:* Do you want to run jinja on the dbt profile?
*Thread Reply:* Theoretically, we'd need to run it also on dbt_project.yml , but we only take target path and profile name from it.
*Thread Reply:* The env_var syntax in the profile is quite simple, I was thinking of extracting the env var name using re and then retrieving the value from os
*Thread Reply:* It would work, but we can actually use jinja - if you're using dbt, it's already included. The method is pretty simple: ``` @contextmember @staticmethod def envvar(var: str, default: Optional[str] = None) -> str: """The envvar() function. Return the environment variable named 'var'. If there is no such environment variable set, return the default.
If the default is None, raise an exception for an undefined variable.
"""
if var in os.environ:
return os.environ[var]
elif default is not None:
return default
else:
msg = f"Env var required but not provided: '{var}'"
undefined_error(msg)```
*Thread Reply:* Oh cool! I will definitely use this one!
*Thread Reply:* We'd be sure that our implementation matches dbt's one, right? Also, you'd support default method for free
*Thread Reply:* So this env_varmethod is defined in dbt and not in OpenLineage codebase, right?
*Thread Reply:* dbt is on Apache license 🙂
*Thread Reply:* Should we import dbt package and use the method or should we just copy/paste the method inside OpenLineage codebase?
*Thread Reply:* I think we should just do basic jinja template rendering in our code like in the quick example: https://realpython.com/primer-on-jinja-templating/#quick-examples
just with the env_var method passed to the render method 🙂
*Thread Reply:* basically, here in the code we should read the file, do the jinja render, and load yaml from string instead of straight from file https://github.com/OpenLineage/OpenLineage/blob/610a687bf69df2b52ec4ac4da80b4a05580e8d32/integration/common/openlineage/common/provider/dbt.py#L176
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* ok, got it. Will try to implement following your suggestions. Thanks @Maciej Obuchowski 🙌
*Thread Reply:* We need to:
- load the template profile from the
profile.yml - replace any env vars we found
For the first step, we can use
jinja2.TemplateHowever, to replace the env vars we find, we have to actually search for those env vars… 🤔
*Thread Reply:* The dbt method implements that: ``` @contextmember @staticmethod def envvar(var: str, default: Optional[str] = None) -> str: """The envvar() function. Return the environment variable named 'var'. If there is no such environment variable set, return the default.
If the default is None, raise an exception for an undefined variable.
"""
if var in os.environ:
return os.environ[var]
elif default is not None:
return default
else:
msg = f"Env var required but not provided: '{var}'"
undefined_error(msg)```
*Thread Reply:* Ok, but I need to pass var to the env_var method.
And to pass the var value, I need to look into the loaded Template and search for env var names…
*Thread Reply:* that's what jinja does - you're passing function to jinja render, and it's calling it itself
*Thread Reply:* you can try the quick example from here, but just pass the env_var method (slightly adjusted - as a standalone function and without undefined error) and call it inside the template: https://realpython.com/primer-on-jinja-templating/#quick-examples
*Thread Reply:* I’m trying to run
pip install -e ".[dev]"
so that I can test my changes, but I get
ERROR: Could not find a version that satisfies the requirement openlineage-integration-common[dbt]==0.2.3 (from openlineage-dbt[dev]) (from versions: 0.0.1rc7, 0.0.1rc8, 0.0.1, 0.1.0rc5, 0.1.0, 0.2.0, 0.2.1, 0.2.2)
ERROR: No matching distribution found for openlineage-integration-common[dbt]==0.2.3
I don’t understand what I’m doing wrong…
*Thread Reply:* can you try installing it manually?
pip install openlineage-integration-common[dbt]==0.2.3
*Thread Reply:* I mean, it exists in pypi: https://pypi.org/project/openlineage-integration-common/#files

*Thread Reply:* Yep, maybe it’s our internal Pypi repo which is not synced. Installing from the public pypi resolved the issue
*Thread Reply:* Can;’t seem to make env_var working as the render method of a Template 😅
*Thread Reply:* ```import os from typing import Optional from jinja2 import Template
def envvar(var: str, default: Optional[str] = None) -> str: """The envvar() function. Return the environment variable named 'var'. If there is no such environment variable set, return the default.
If the default is None, raise an exception for an undefined variable.
"""
if var in os.environ:
return os.environ[var]
elif default is not None:
return default
else:
msg = f"Env var required but not provided: '{var}'"
raise Exception("")
if name == 'main': t = Template("Hello {{ envvar('ENVVAR') }}!") print(t.render(envvar=envvar))```
*Thread Reply:* works for me:
mobuchowski@thinkpad [18:57:14] [~]
-> % ENV_VAR=world python jinja_example.py
Hello world!
*Thread Reply:* Finally 😅 https://github.com/OpenLineage/OpenLineage/pull/328
There are minimal tests for Redshift and env vars. Feedbacks and suggestions are welcome!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Maciej Obuchowski 😊 Regarding this comment https://github.com/OpenLineage/OpenLineage/pull/328#discussion_r726586564
How can we distinguish between snowflake, bigquery and redshift in this method?
A simple, but not very clean solution, would be to split this
bytes = get_from_multiple_chains(
node.catalog_node,
[
['stats', 'num_bytes', 'value'], # bigquery
['stats', 'bytes', 'value'], # snowflake
['stats', 'size', 'value'] # redshift (Note: size = count of 1MB blocks)
]
)
into two pieces, one checking for snowflake and bigquery and the other checking for redshift.
A better solution would be to have the profile type inside method node_to_output_dataset , but I’m struggling understanding how to do that
*Thread Reply:* Well, why not do something like
```bytes = getfrommultiple_chains(... rest of stuff)
if adapter == 'redshift': bytes = 10241024```
*Thread Reply:* we can store adapter type in the class
*Thread Reply:* well, I've looked at last commit and that's exactly what you did 👍
*Thread Reply:* Now, have you tested your branch on real redshift cluster? I don't think we 100% need automated tests for that now, but would be nice to have confirmation that it works.
*Thread Reply:* Not yet, but I'll try to do that this afternoon. Need to figure out how to build the lib locally, then I can use it to test with Redshift
*Thread Reply:* I think pip install -e .[dbt] in common directory should be enough
*Thread Reply:* namespace: well, if it matches what you put into your profile, there's not much we can do. I don't understand why you connect to redshift via host, maybe this is related to IAM?
*Thread Reply:* I think the marquez error is because we don't send SourceCodeLocationJobFacet
*Thread Reply:* Regarding the namespace, I will check it and figure it out 😊 Regarding the error: in the context of this PR, is it something I should worry about or not?
*Thread Reply:* I think not in the context of the PR. It certainly deserves separate issue in Marquez repository.
*Thread Reply:* Is there anything else I can do to improve the PR?
*Thread Reply:* did you figure out the namespace stuff? I think it's ready to be merged outside of that
*Thread Reply:* Ok i figured it out.
When running dbt locally, we connect to Redshift using an SSH tunnel.
dbt runs on Docker, hence it can access the tunnel using host.docker.internal
*Thread Reply:* Makes sense. So, let's merge it, after DCO bot gets up again.
*Thread Reply:* merged your PR 🙌
*Thread Reply:* I think I'm going to change it up a bit. The problem is that we can try to render jinja everywhere, including comments. I tried to make it skip unknown methods and values here, but I think the right solution is to load the yaml, and then try to render jinja for values.
*Thread Reply:* Does it work with simply dbt run?
*Thread Reply:* also, do you have dbt-snowflake installed?
*Thread Reply:* it works with dbt run
*Thread Reply:* what the dbt says - the snowflake profile with dev target - is that what you ment to run or was it something else?
*Thread Reply:* it feels very weird to me, since the dbt-ol script just runs dbt run underneath
*Thread Reply:* this is my profiles.yml file: ```snowflake: target: dev outputs: dev: type: snowflake account: xxxxxxx
# User/password auth
user: xxxxxx
password: xxxxx
role: poc_db_temp_fullaccess
database: POC_DB
warehouse: poc_wh
schema: temp
threads: 2
client_session_keep_alive: False
query_tag: dbt_ol```
*Thread Reply:* Yes, it looks that everything is okay on your side...
*Thread Reply:* may be I’ll restart my machine and try again
*Thread Reply:* can you try
OPENLINEAGE_URL=<http://localhost:5000> dbt-ol debug
*Thread Reply:* Good that you fixed that one 🙂 Regarding last one, I've found it independently yesterday and PR fixing it is already waiting for review: https://github.com/OpenLineage/OpenLineage/pull/322
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* There will be a release soon: https://openlineage.slack.com/archives/C01CK9T7HKR/p1633631825147900
 }
}

Hi, I just started playing around with Marquez. When submitting some lineage data, after some experimenting, the visualisation becomes a bit cluttered with all the naive attempts of building a meaningful graph. Can I clear this up somehow? Or is there a tip, how to hide certain information?
*Thread Reply:* So, as a quick fix, shutting down and re-starting the docker container resets everything.
./docker/up.sh
*Thread Reply:* I guess that it's the easiest way now. There should be API for that.
*Thread Reply:* @Alex P Yeah, we're realizing that being able to delete metadata is becoming very important. And, as @Maciej Obuchowski mentioned, dropping your entire database is the only way currently (not ideal!). We do have an issue in the Marquez backlog to expose delete APIs: https://github.com/MarquezProject/marquez/issues/754
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* A bit more discussion is needed though. Like what if a dataset is deleted, but you still want to keep track that it existed at some point? (i.e. soft vs hard deletes). But, for the case that you just want to clear metadata because you were testing things out, then yeah, that's more obvious and requires little discussion of the API upfront.
*Thread Reply:* @Alex P I moved the delete APIs to the Marquez 0.20.0 release
*Thread Reply:* I have also updated a corresponding issue to track this in OpenLineage: https://github.com/OpenLineage/OpenLineage/issues/323
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
The next OpenLineage monthly meeting is on the 13th. https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting please chime in here if you’d like a topic to be added to the agenda
*Thread Reply:* Reminder that the meeting is today. See you soon
*Thread Reply:* The recording and notes of the meeting are now available: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting#MonthlyTSCmeeting-Oct13th2021
@channel: We’ve recently become aware that our integration with dbt no longer works with the latest dbt manifest version (v3), see original discussion. The manifest version change was introduced in dbt 0.21 , see diff. That said, we do have a fix: PR #322 contributed by @Maciej Obuchowski! Here’s our plan to rollout the openlineage-dbt hotfix for those using the latest version of dbt (NOTE: for those using an older dbt version, you will NOT not be affected by this bug):
Releasing OpenLineage 0.2.3 with dbt v3 manifest support:
- Branch off
0.2.2tagged commit, and create aopenlineage-0.2.xbranch - Cherry pick the commit with the dbt manifest
v3fix - Release
0.2.3batch release We will be releasing0.2.3today. Please reach out to us with any questions!
 }
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
}
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* For people following along, dbt changed the schema of its metadata which broke the openlineage integration. However we were a bit too stringent on validating the schema version (they increment it every time event if it’s backwards compatible, which it is in this case). We will fix that so that future compatible changes don’t prevent the ol integration to work.
*Thread Reply:* As one of the main integrations, would be good to connect more within the dbt community for the next releases, by testing the release candidates 👍
Thanks for the PR
*Thread Reply:* Yeah, I totally agree with you. We also should be more proactive and also be more aware in what’s coming in future dbt releases. Sorry if you were effected by this bug :ladybug:
*Thread Reply:* We’ve release OpenLineage 0.2.3 with the hotfix for adding dbt v3 manifest support, see https://github.com/OpenLineage/OpenLineage/releases/tag/0.2.3
You can download and install openlineage-dbt 0.2.3 with the fix using:
$ pip3 install openlineage-dbt==0.2.3
Hello. I have a question about dbt-ol. I run dbt in a docker container and alias the dbt command to execute in that docker container. dbt-ol doesn't seem to use that alias. Do you know of a way to force it to use the alias?...or is there an alternative to getting the linage into Marquez?
*Thread Reply:* @Drew Bittenbender dbt-ol always calls dbt command now, without spawning shell - so it does not have access to bash aliases.
Can you elaborate about your use case? Do you mean that dbt in your path does docker run or something like this? It still might be a problem if we won't have access to artifacts generated by dbt in target directory.
*Thread Reply:* I am running on a mac and I have aliased (.zshrc) dbt to execute docker run against the fishtownanalytics docker image rather than installing dbt natively (homebrew, etc). I am doing this so that the dbt configuration is portable and reusable by others.
It seems that by installing openlineage-dbt in a virtual environment, it pulls down it's own version of dbt which it calls inline rather than shelling out and executing the dbt setup resident in the host system. I understand that opening a shell is a security risk so that is understandable.
*Thread Reply:* It does not pull down, it just assumes that it's in the system. It would fail if it isn't.
For now I think you could build your own image based on official one, and install openlineage-dbt inside, something like:
FROM fishtownanalytics/dbt:0.21.0
RUN pip install openlineage-dbt
ENTRYPOINT ["dbt-ol"]
*Thread Reply:* and then pass OPENLINEAGE_URL in env while doing docker run
*Thread Reply:* Also, to make sure that using shell would help in your case: do you bind mount your dbt directory to home? dbt-ol can't run without access to dbt's target directory, so if it's not visible in host, the only option is to have dbt-ol in container.
*Thread Reply:* Regarding 2), the data is only visible after next dbt-ol run - dbt docs generate does not emit events itself, but generates data that run take into account.
*Thread Reply:* Do they have it in dbt docs?
Hey folks 😊 DCO checks on this PR https://github.com/OpenLineage/OpenLineage/pull/328 seem to be stuck. Any suggestions on how to unblock it?
Thanks!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I don't think anything is wrong with your branch. It's also not working on my one. Maybe it's globally stuck?

We are working on the hackathon and have a couple of questions about generating lineage information. @Willy Lulciuc would you have time to help answer a couple of questions?
• Is there a way to generate OpenLineage output that contains a mapping between input and output fields? • In Azure Databricks sources often map to ADB mount points. We are looking for a way to translate this into source metadata in the OL output. Is there some configuration that would make this possible, or any other suggestions?
*Thread Reply:* > Is there a way to generate OpenLineage output that contains a mapping between input and output fields? OpenLineage defines discrete classes for both OpenLineage.InputDataset and OpenLineage.OutputDataset datasets. But, for clarification, are you asking:
- If a job reads / writes to the same dataset, how can OpenLineage track which fields were used in job’s logic as input and which fields were used to write back to the resulting output?
- Or, if a job reads / writes from two different dataset, how can OpenLineage track which input fields were used in the job’s logic for the resulting output dataset? (i.e. column-level lineage)
*Thread Reply:* > In Azure Databricks sources often map to ADB mount points. We are looking for a way to translate this into source metadata in the OL output. Is there some configuration that would make this possible, or any other suggestions?
I would look into our OutputDatasetVisitors class (as a starting point) that extracts metadata from the spark logical plan to construct a mapping between a logic plan to one or more OpenLineage.Dataset for the spark job. But, I think @Michael Collado will have a more detailed suggestion / approach to what you’re asking
*Thread Reply:* are the sources mounted like local filesystem mounts? are you ending up with datasources that point to the local filesystem rather than some dbfs url? (sorry, I'm not familiar with databricks or azure at this point)
*Thread Reply:* I think under the covers they are an os level fs mount, but it is using an ADB specific api, dbutils.fs.mount. It is using the ADB filesystem.
*Thread Reply:* Do you use the dbfs scheme to access the files from Spark as in the example on that page?
df = spark.read.text("dbfs:/mymount/my_file.txt")
*Thread Reply:* @Willy Lulciuc In our project, @Will Johnson had generated some sample OL output from just reading in and writing out a dataset to blob storage. In the resulting output, I see the columns represented as fields under the schema element with a set represented for output and another for input. I would need the mapping of in and out columns to generate column level lineage so wondering if it is possible to get or am I just missing it somewhere? Thanks for your help!
*Thread Reply:* Ahh, well currently, no, but it has been discussed and on the OpenLineage roadmap. Here’s a proposal opened by @Julien Le Dem, column level lineage facet, that starts the discussion to add the columnLineage face to the datasets model in order to support column-level lineage. Would be great to get your thoughts!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

*Thread Reply:* @Michael Collado - Databricks allows you to reference a file called /mnt/someMount/some/file/path The way you have referenced it would let you hit the file with local file system stuff like pandas / local python.
*Thread Reply:* For column level lineage, you can add your own custom facets: Here’s an example in the Spark integration: (LogicalPlanFacet) https://github.com/OpenLineage/OpenLineage/blob/5f189a94990dad715745506c0282e16fd8[…]openlineage/spark/agent/lifecycle/SparkSQLExecutionContext.java Here is the paragraph about this in the spec: https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md#custom-facet-naming
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* This example adds facets to the run, but you can also add them to the job
*Thread Reply:* unfortunately, there's not yet a way to add your own custom facets to the spark integration- there's some work on extensibility to be done
*Thread Reply:* for the hackathon's sake, you can check out the package and just add in whatever you want
Question on the Spark Integration and its SPARKCONFURL_KEY configuration variable.
It looks like I can pass in any url but I'm not sure if I can pass in query parameters along with that URL. For example, if I had https://localhost/myendpoint?secret_code=123 I THINK that is used for the endpoint and it does not append /lineage to the end of the url. Is that a fair assessment of what happens when the url is provided?
Thank you for any guidance!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* You can also pass the settings independently if you want something more flexible: https://github.com/OpenLineage/OpenLineage/blob/8afc4ff88b8dd8090cd9c45061a9f669fe[…]n/java/io/openlineage/spark/agent/OpenLineageSparkListener.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* SparkSession.builder()
.config("spark.jars.packages", "io.openlineage:openlineage_spark:0.2.+")
.config("spark.extraListeners", "io.openlineage.spark.agent.OpenLineageSparkListener")
.config("spark.openlineage.host", "<https://localhost>")
.config("spark.openlineage.apiKey", "your api key")
.config("spark.openlineage.namespace", "<NAMESPACE_NAME>") // Replace with the name of your Spark cluster.
.getOrCreate()
*Thread Reply:* It is going to add /lineage in the end: https://github.com/OpenLineage/OpenLineage/blob/8afc4ff88b8dd8090cd9c45061a9f669fe[…]rc/main/java/io/openlineage/spark/agent/OpenLineageContext.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* the apiKey setting is sent in an “Authorization” header
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you @Julien Le Dem it seems in both cases (defining the url endpoint with spark.openlineage.url and with the components: spark.openlineage.host / openlineage.version / openlineage.namespace / etc.) OpenLineage will strip out url parameters and rebuild the url endpoint with /lineage.
I think we might need to add in a url parameter configuration for our hackathon. We're using a bit of serverless code to shuttle open lineage events to a queue so that another job and/or serverless application can read that queue at its leisure.
Using the apiKey that feeds into the Authorization header as a Bearer token is great and would suffice but for our services we use OAuth tokens that would expire after two hours AND most of our customers wouldn't want to generate an access token themselves and feed it to Spark. ☹️
Would you guys entertain a proposal to support a spark.openlineage.urlParams configuration variable that lets you add url parameters to the derived lineage url?
Thank you for the detailed replies and deep links!
*Thread Reply:* Yes, please open an issue detailing the use case.
Quick question, is it expected, when using Spark SQL and the Spark Integration for Spark3 that we receive and INPUT but no OUTPUTS when doing a CREATE TABLE ... AS SELECT ... .
I'm reading from a Spark SQL table (underlying CSV) and then writing it to a DELTA lake table.
I get a COMPLETE event type with an INPUT but no OUTPUT and then I get an exception for the AsyncEvent Queue but I'm guessing it's unrelated 😅
21/10/13 15:38:15 INFO OpenLineageContext: Lineage completed successfully: ResponseMessage(responseCode=200, body=null, error=null) {"eventType":"COMPLETE","eventTime":"2021-10-13T15:38:15.878Z","run":{"runId":"2cfe52b3-e08f-4888-8813-ffcdd2b27c89","facets":{"spark_unknown":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.2.3-SNAPSHOT/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","output":{"description":{"@class":"org.apache.spark.sql.catalyst.plans.logical.Project","traceEnabled":false,"streaming":false,"cacheId":null,"canonicalizedPlan":false},"inputAttributes":[{"name":"id","type":"long","metadata":{}}],"outputAttributes":[{"name":"id","type":"long","metadata":{}},{"name":"action_date","type":"date","metadata":{}}]},"inputs":[{"description":{"@class":"org.apache.spark.sql.catalyst.plans.logical.Range","streaming":false,"traceEnabled":false,"cacheId":null,"canonicalizedPlan":false},"inputAttributes":[],"outputAttributes":[{"name":"id","type":"long","metadata":{}}]}]},"spark.logicalPlan":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.2.3-SNAPSHOT/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.Project","num-children":1,"projectList":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"id","dataType":"long","nullable":false,"metadata":{},"exprId":{"product_class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":111,"jvmId":"4bdfd808-97d5-455f-ad6a-a3b29855e85b"},"qualifier":[]}],[{"class":"org.apache.spark.sql.catalyst.expressions.Alias","num-children":1,"child":0,"name":"action_date","exprId":{"product-class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":113,"jvmId":"4bdfd808_97d5_455f_ad6a_a3b29855e85b"},"qualifier":[],"explicitMetadata":{},"nonInheritableMetadataKeys":"[__dataset_id, __col_position]"},{"class":"org.apache.spark.sql.catalyst.expressions.CurrentDate","num_children":0,"timeZoneId":"Etc/UTC"}]],"child":0},{"class":"org.apache.spark.sql.catalyst.plans.logical.Range","num-children":0,"start":0,"end":5,"step":1,"numSlices":8,"output":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"id","dataType":"long","nullable":false,"metadata":{},"exprId":{"product_class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":111,"jvmId":"4bdfd808-97d5-455f-ad6a-a3b29855e85b"},"qualifier":[]}]],"isStreaming":false}]}}},"job":{"namespace":"sparknamespace","name":"databricks_shell.project"},"inputs":[],"outputs":[],"producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.2.3-SNAPSHOT/integration/spark>","schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunEvent>"}
21/10/13 15:38:16 INFO FileSizeAutoTuner: File size tuning result: {"tuningType":"autoTuned","tunedConfs":{"spark.databricks.delta.optimize.minFileSize":"268435456","spark.databricks.delta.optimize.maxFileSize":"268435456"}}
21/10/13 15:38:16 INFO FileFormatWriter: Write Job e062f36c-8b9d-4252-8db9-73b58bd67b15 committed.
21/10/13 15:38:16 INFO FileFormatWriter: Finished processing stats for write job e062f36c-8b9d-4252-8db9-73b58bd67b15.
21/10/13 15:38:18 INFO CodeGenerator: Code generated in 253.294028 ms
21/10/13 15:38:18 INFO SparkContext: Starting job: collect at DataSkippingReader.scala:430
21/10/13 15:38:18 INFO DAGScheduler: Job 1 finished: collect at DataSkippingReader.scala:430, took 0.000333 s
21/10/13 15:38:18 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
java.lang.NullPointerException
at io.openlineage.spark.agent.OpenLineageSparkListener.onJobEnd(OpenLineageSparkListener.java:167)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:39)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:119)
at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:103)
at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1547)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
*Thread Reply:* This is because this specific action is not covered yet. You can see the “spark_unknown” facet is describing things that are not understood yet
run": {
...
"facets": {
"spark_unknown": {
...
"output": {
"description": {
"@class": "org.apache.spark.sql.catalyst.plans.logical.Project",
"traceEnabled": false,
"streaming": false,
"cacheId": null,
"canonicalizedPlan": false
},
*Thread Reply:* I think this is part of the Spark 3 gap
*Thread Reply:* an unknown output will cause missing output lineage
*Thread Reply:* Output handling is here: https://github.com/OpenLineage/OpenLineage/blob/e0f1852422f325dc019b0eab0e466dc905[…]io/openlineage/spark/agent/lifecycle/OutputDatasetVisitors.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Ah! Thank you so much, Julien! This is very helpful to understand where that is set. This is a big gap that we want to help address after our hackathon. Thank you!
Following up on the meeting this morning, I have created an issue to formalize a design doc review process: https://github.com/OpenLineage/OpenLineage/issues/336 If that sounds good I’ll create the first doc to describe this as a PR. (how meta!)
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* the github wiki is backed by a git repo but it does not allow PRs. (people do hacks but I’d rather avoid those)
We're discussing creating Transport abstraction for OpenLineage clients, that would allow us creating better experience for people that expect to be able to emit their events using something else than http interface. Please tell us what you think of proposed mechanism - encouraging emojis are helpful too 😉
https://github.com/OpenLineage/OpenLineage/pull/344
OpenLineage release 0.3 is coming. Please chiming if there’s anything blocker that should go in the release: https://github.com/OpenLineage/OpenLineage/projects/4

👋 Hi everyone!
openlineage with DBT and Trino, is there any forecast?
*Thread Reply:* Maybe you want to contribute it? It's not that hard, mostly testing, and figuring out what would be the naming of openlineage namespace for Trino, and how some additional statistics work.
For example, recently we had added support for Redshift by community member @ale
https://github.com/OpenLineage/OpenLineage/pull/328
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Done. PASS=5 WARN=0 ERROR=0 SKIP=0 TOTAL=5 Traceback (most recent call last): File "/home/labuser/.local/bin/dbt-ol", line 61, in <module> main() File "/home/labuser/.local/bin/dbt-ol", line 54, in main events = processor.parse().events() File "/home/labuser/.local/lib/python3.8/site-packages/openlineage/common/provider/dbt.py", line 98, in parse self.extractdatasetnamespace(profile) File "/home/labuser/.local/lib/python3.8/site-packages/openlineage/common/provider/dbt.py", line 377, in extractdatasetnamespace self.datasetnamespace = self.extractnamespace(profile) File "/home/labuser/.local/lib/python3.8/site-packages/openlineage/common/provider/dbt.py", line 391, in extract_namespace raise NotImplementedError( NotImplementedError: Only 'snowflake' and 'bigquery' adapters are supported right now. Passed trino
Hey folks, we've released OpenLineage 0.3.1. There are quite a few changes, including doc improvements, Redshift support in dbt, bugfixes, a new server-side client code base, but the real highlights are
- Official Spark 3 support- this is still a work in progress (the whole Spark integration is), but the big deal is we've split the source tree to support both Spark 2 and Spark 3 specific plan visitors. This will enable us to work with the Spark 3 API explicitly and to add support for those interfaces and classes that didn't exist in Spark 2. We're also running all integration tests against both Spark 2.4.7 and Spark 3.1.0
- Airflow 2 support- also a work in progress, but we have a new
LineageBackendimplementation that allows us to begin tracking lineage for successful Airflow 2 DAGs. We're working to support failure notifications so we can also trace failed jobs. TheLineageBackendcan also be enabled in Airflow 1.10.X to improve the reporting of task completion times. Check the READMEs for more details and to get started with the new features. Thanks to @Maciej Obuchowski , @Oleksandr Dvornik, @ale, and @Willy Lulciuc for their contributions. See the full changelog

Hello community. I am starting using marquez. I try to connect dbt with Marquez, but the spark adapter is not yet available.
Are you planning to implement this spark dbt adapter in next openlineage versions?
NotImplementedError: Only 'snowflake', 'bigquery', and 'redshift' adapters are supported right now. Passed spark In my company we are starting to use as well the athena dbt adapter. Are you planning to implement this integration? Thanks a lot community
*Thread Reply:* That would make sense. I think you are the first person to request this. Is this something you would want to contribute to the project?
*Thread Reply:* I would like to Julien, but not sure how can I do it. Could you guide me how can i start? or show me other integration.

*Thread Reply:* @David Virgil look at the pull request for the addition of Redshift as a starting guide. https://github.com/OpenLineage/OpenLineage/pull/328
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks @Matthew Mullins I ll try to add dbt spark integration
Hey folks, quick question, are we able to run dbt-ol without providing OPENLINEAGE_URL? I find it quite limiting that I need to have a service set up in order to emit/generate OL events/messages. Is there a way to just output them to the console?
*Thread Reply:* OK, was changed here: https://github.com/OpenLineage/OpenLineage/pull/286
Did you think about this?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* In Marquez there was a mechanism to do that. Something like OPENLINEAGE_BACKEND=HTTP|LOG
*Thread Reply:* @Mario Measic We're going to add Transport mechanism, that will address use cases like yours. Please comment on this PR what would you expect: https://github.com/OpenLineage/OpenLineage/pull/344
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Nice, thanks @Julien Le Dem and @Maciej Obuchowski.
*Thread Reply:* Also, dbt build is not working which is kind of the biggest feature of the version 0.21.0, I will try testing the code with modifications to the https://github.com/OpenLineage/OpenLineage/blob/c3aa70e161244091969951d0da4f37619bcbe36f/integration/dbt/scripts/dbt-ol#L141
I guess there's a reason for it that I didn't see since you support v3 of the manifest.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Also, is it normal not to see the column descriptions for the model/table even though these are provided in the YAML file, persisted in Redshift and also dbt docs generate has been run before dbt-ol run?
*Thread Reply:* Tried with dbt versions 0.20.2 and 0.21.0, openlineage-dbt==0.3.1
*Thread Reply:* I'll take a look at that. Supporting descriptions might be simple, but dbt build might be a little larger task.
*Thread Reply:* I opened a ticket to track this: https://github.com/OpenLineage/OpenLineage/issues/376
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* The column description issue should be fixed here: https://github.com/OpenLineage/OpenLineage/pull/383
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
I’m looking for feedback on my proposal to improve the proposal process ! https://github.com/OpenLineage/OpenLineage/issues/336
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hey guys - just an update on my prefect PR (https://github.com/OpenLineage/OpenLineage/pull/293) - there a little spiel on the ticket but I've closed that PR in favour of opening a new one. Prefect have just release a 2.0a technical preview, which they would like to make stable near the start of next year. I think it makes sense to target this release, and I've had one of the prefect team reach out and is keen to get some sort of lineage implemented in prefect.
*Thread Reply:* If anyone has any questions or comments - happy to discuss here
*Thread Reply:* Thanks for updating the community, Brad!

*Thread Reply:* Than you Brad. Looking forward to see how to integrated that with v2

Hello, joining here from Prefect. Because of community requests from users like Brad above, we are looking to implement lineage for Prefect this quarter. Good to meet you all!
*Thread Reply:* Welcome, @Kevin Kho 👋. Really excited to see this integration kick off! 💯🚀
Hello,
i am integratng openLineage with Airflow 2.2.0
Do you consider in the future airflow manual inlets and outlets?
Seeing the documentation I can see that is not possible.
OpenLineageBackend does not take into account manually configured inlets and outlets.
Thanks

*Thread Reply:* While it’s not something we’re supporting at the moment, it’s definitely something that we’re considering!
If you can give me a little more detail on what your system infrastructure is like, it’ll help us set priority and design
*Thread Reply:* So basic architecture of a datalake. We are using airflow to trigger jobs. Every job is a pipeline that runs a spark job (in our case it spin up an EMR). So the idea of lineage would be defining in the dags inlets and outlets based on the airflow lineage:
https://airflow.apache.org/docs/apache-airflow/stable/lineage.html
I think you need to be able to include these inlets and outlets in the picture of openlineage
*Thread Reply:* Why not use spark integration? https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark
*Thread Reply:* because there are some other jobs that are not spark, some jobs they run in dbt, other jobs they run in redshift @Maciej Obuchowski
*Thread Reply:* So, combo of https://github.com/OpenLineage/OpenLineage/tree/main/integration/dbt and PostgresExtractor from airflow integration should cover Redshift if you're using it from PostgresOperator 🙂
It's definitely interesting use case - you'd be using most of the existing integrations we have.
*Thread Reply:* @Maciej Obuchowski Do i need to define any extractor in the airflow startup?

*Thread Reply:* I am using Redshift with PostgresOperator and it is returning…
[2021-11-06 03:43:06,541] {{__init__.py:92}} ERROR - Failed to extract metadata 'NoneType' object has no attribute 'host' task_type=PostgresOperator airflow_dag_id=counter task_id=inc airflow_run_id=scheduled__2021-11-06T03:42:00+00:00
Traceback (most recent call last):
File "/usr/local/airflow/.local/lib/python3.7/site-packages/openlineage/lineage_backend/__init__.py", line 83, in _extract_metadata
task_metadata = self._extract(extractor, task_instance)
File "/usr/local/airflow/.local/lib/python3.7/site-packages/openlineage/lineage_backend/__init__.py", line 104, in _extract
task_metadata = extractor.extract_on_complete(task_instance)
File "/usr/local/airflow/.local/lib/python3.7/site-packages/openlineage/airflow/extractors/base.py", line 61, in extract_on_complete
return self.extract()
File "/usr/local/airflow/.local/lib/python3.7/site-packages/openlineage/airflow/extractors/postgres_extractor.py", line 65, in extract
authority=self._get_authority(),
File "/usr/local/airflow/.local/lib/python3.7/site-packages/openlineage/airflow/extractors/postgres_extractor.py", line 120, in _get_authority
if self.conn.host and self.conn.port:
AttributeError: 'NoneType' object has no attribute 'host'
I can’t see this raised as an issue.
Hello, I am trying to integrate Airflow with openlineage.
It is not working for me.
What I tried:
- Adding
openlineage-airflowto requirements.txt - Adding ```- AIRFLOWLINEAGEBACKEND=openlineage.airflow.backend.OpenLineageBackend
- OPENLINEAGE_URL="https://marquez-internal-eks.eu-west-1.dev.hbi.systems"
- OPENLINEAGENAMESPACE="dnsairflow"
During handling of the above exception, another exception occurred:
Traceback (most recent call last): File "/home/airflow/.local/bin/airflow", line 8, in <module> sys.exit(main()) File "/home/airflow/.local/lib/python3.8/site-packages/airflow/main.py", line 40, in main args.func(args) File "/home/airflow/.local/lib/python3.8/site-packages/airflow/cli/cliparser.py", line 47, in command func = importstring(importpath) File "/home/airflow/.local/lib/python3.8/site-packages/airflow/utils/moduleloading.py", line 32, in importstring module = importmodule(modulepath) File "/usr/local/lib/python3.8/importlib/init.py", line 127, in importmodule return bootstrap.gcdimport(name[level:], package, level) File "<frozen importlib.bootstrap>", line 1014, in gcdimport File "<frozen importlib.bootstrap>", line 991, in _findandload File "<frozen importlib.bootstrap>", line 975, in findandloadunlocked File "<frozen importlib.bootstrap>", line 671, in _loadunlocked File "<frozen importlib.bootstrapexternal>", line 843, in execmodule File "<frozen importlib.bootstrap>", line 219, in callwithframesremoved File "/home/airflow/.local/lib/python3.8/site-packages/airflow/cli/commands/dbcommand.py", line 24, in <module> from airflow.utils import cli as cliutils, db File "/home/airflow/.local/lib/python3.8/site-packages/airflow/utils/db.py", line 26, in <module> from airflow.jobs.basejob import BaseJob # noqa: F401 File "/home/airflow/.local/lib/python3.8/site-packages/airflow/jobs/init.py", line 19, in <module> import airflow.jobs.backfilljob File "/home/airflow/.local/lib/python3.8/site-packages/airflow/jobs/backfilljob.py", line 29, in <module> from airflow import models File "/home/airflow/.local/lib/python3.8/site-packages/airflow/models/init.py", line 20, in <module> from airflow.models.baseoperator import BaseOperator, BaseOperatorLink File "/home/airflow/.local/lib/python3.8/site-packages/airflow/models/baseoperator.py", line 196, in <module> class BaseOperator(Operator, LoggingMixin, TaskMixin, metaclass=BaseOperatorMeta): File "/home/airflow/.local/lib/python3.8/site-packages/airflow/models/baseoperator.py", line 941, in BaseOperator def postexecute(self, context: Any, result: Any = None): File "/home/airflow/.local/lib/python3.8/site-packages/airflow/lineage/init.py", line 103, in applylineage _backend = getbackend() File "/home/airflow/.local/lib/python3.8/site-packages/airflow/lineage/init.py", line 52, in get_backend clazz = conf.getimport("lineage", "backend", fallback=None) File "/home/airflow/.local/lib/python3.8/site-packages/airflow/configuration.py", line 469, in getimport raise AirflowConfigException( airflow.exceptions.AirflowConfigException: The object could not be loaded. Please check "backend" key in "lineage" section. Current value: "openlineage.airflow.backend.OpenLineageBackend".```
*Thread Reply:* 1. Please use openlineage.lineage_backend.OpenLineageBackend as AIRFLOW__LINEAGE__BACKEND
- Please tell us where you've seen
openlineage.airflow.backend.OpenLineageBackend, so we can fix the documentation 🙂
*Thread Reply:* https://pypi.org/project/openlineage-airflow/
*Thread Reply:* (I googled it and found that page that seems to have an outdated doc)
*Thread Reply:* @Maciej Obuchowski @Julien Le Dem that's the page i followed. Please guys revise the documentation, as it is very important
*Thread Reply:* PyPi is using the README at the time of the release 0.3.1, rather than the current README, which is 0.4.0. If we send the new release to PyPi it should also update the README
Related the Airflow integration. Is it required to install openlineage-airflow and setup the environment variables in both scheduler and webserver, or just in the scheduler?
*Thread Reply:* I set i up in the scheduler and it starts to log data to marquez. But it fails with this error:
Traceback (most recent call last):
File "/home/airflow/.local/lib/python3.8/site-packages/openlineage/client/client.py", line 49, in __init__
raise ValueError(f"Need valid url for OpenLineageClient, passed {url}")
ValueError: Need valid url for OpenLineageClient, passed "<http://marquez-internal-eks.eu-west-1.dev.hbi.systems>"
*Thread Reply:* why is it not a valid URL?
*Thread Reply:* Which version of the OpenLineage client are you using? On first check it should be fine
*Thread Reply:* @John Thomas I was appending double quotes as part of the url. Forget about this error
Hello, I am receiving this error today when I deployed openlineage in development environment (not using docker-compose locally).
I am running with KubernetesExecutor
airflow.exceptions.AirflowConfigException: The object could not be loaded. Please check "backend" key in "lineage" section. Current value: "openlineage.lineage_backend.OpenLineageBackend".
*Thread Reply:* Are you sure that openlineage-airflow is present in the container?
So in this case in my template I am adding:
```env:
ADDITIONALPYTHONDEPS: "openpyxl==3.0.3 smartopen==2.0.0 apache-airflow-providers-http apache-airflow-providers-cncf-kubernetes apache-airflow-providers-amazon openlineage-airflow"
OPENLINEAGEURL: https://marquez-internal-eks.eu-west-1.dev.hbi.systems
OPENLINEAGENAMESPACE: dnsairflow
AIRFLOWKUBERNETESENVIRONMENTVARIABLESOPENLINEAGEURL: https://marquez-internal-eks.eu-west-1.dev.hbi.systems
AIRFLOWKUBERNETESENVIRONMENTVARIABLESOPENLINEAGENAMESPACE: dns_airflow
configmap: mountPath: /var/airflow/config # mount path of the configmap data: airflow.cfg: | [lineage] backend = openlineage.lineage_backend.OpenLineageBackend
pod_template_file.yaml: |
containers:
- args: []
command: []
env:
- name: AIRFLOW__KUBERNETES_ENVIRONMENT_VARIABLES__OPENLINEAGE_URL
value: <https://marquez-internal-eks.eu-west-1.dev.hbi.systems>
- name: AIRFLOW__KUBERNETES_ENVIRONMENT_VARIABLES__OPENLINEAGE_NAMESPACE
value: dns_airflow
- name: AIRFLOW__LINEAGE__BACKEND
value: openlineage.lineage_backend.OpenLineageBackend```
I am installing openlineage in the ADDITIONAL_PYTHON_DEPS
*Thread Reply:* Maybe ADDITIONAL_PYTHON_DEPS are dependencies needed by the tasks, and are installed after Airflow tries to initialize LineageBackend?
*Thread Reply:* I am checking this accessing the Kubernetes pod
I see that every task is displayed as a different job. I was expecting to see one job per dag.
Is this the expected behaviour??
*Thread Reply:* Probably what you want is job hierarchy: https://github.com/MarquezProject/marquez/issues/1737
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* I do not see any benefit of just having some airflow task metadata. I do not see relationship between tasks. Every task is a job. When I was thinking about lineage when i started working on my company integration with openlineage i though that openlineage would give me relationship between task or datasets and the only thing i see is some metadata of the history of airflow runs that is already provided by airflow
*Thread Reply:* i was expecting to see a nice graph. I think it is missing some features
*Thread Reply:* at this early stage
*Thread Reply:* It probably depends on whether those tasks are covered by the extractors: https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow/openlineage/airflow/extractors
*Thread Reply:* We are not using any of those operators: bigquery, postsgress or snowflake.
And what is it doing GreatExpectactions extractor?
It would be good if there is one extractor that relies in the inlets and outlets that you can define in any Airflow task, and that that can be the general way to make relationships between datasets
*Thread Reply:* And that the same dag graph can be seen in marquez, and not one job per task.
*Thread Reply:* > It would be good if there is one extractor that relies in the inlets and outlets that you can define in any Airflow task I think this is good idea. Overall, OpenLineage strongly focuses on automatic metadata collection. However, using them would be a nice fallback for not-covered-yet cases.
> And that the same dag graph can be seen in marquez, and not one job per task. This currently depends on dataset hierarchy. If you're not using any of the covered extractors, then Marquez can't build dataset graph like in the demo: https://raw.githubusercontent.com/MarquezProject/marquez/main/web/docs/demo.gif
With the job hierarchy ticket, probably some graph could be generated using just the job data though.
*Thread Reply:* Created issue for the manual fallback: https://github.com/OpenLineage/OpenLineage/issues/384
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Maciej Obuchowski how many people are working full time in this library? I really would like to adopt it in my company, as we use airflow and spark, but i see that yet it does not have the features we would like to.
At the moment the same info we have in marquez related the tasks, is available in airflow UI or using airflow API.
The game changer for us would be that it could give us features/metadata that we cannot query directly from airflow. That's why if the airflow inlets/outlets could be used, then it really would make much more sense for us to adopt it.
*Thread Reply:* > how many people are working full time in this library? On Airflow integration or on OpenLineage overall? 🙂
> The game changer for us would be that it could give us features/metadata that we cannot query directly from airflow. I think there are three options there:
- Contribute relevant extractors for Airflow operators that you use
- Use those extractors as custom extractors: https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow#custom-extractors
- Create that manual fallback mechanism with Airflow inlets/outlets: https://github.com/OpenLineage/OpenLineage/issues/384
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* But first, before implementing last option, I'd like to get consensus about it - so feel free to comment there about your use case
@Maciej Obuchowski even i can contribute or help with my ideas (from what i consider that should be lineage from a client side)
@Maciej Obuchowski I was able to put to work Airflow in Kubernetes pointing to Marquez using the openlineage library. I have a few problems I found that would be good to comment.
I see a warning
[2021-11-03 11:47:04,309] {great_expectations_extractor.py:27} WARNING - Did not find great_expectations_provider library or failed to import it
I couldnt find any information about GreatExpectationsExtractor. Could you tell me what is this extractor about?
*Thread Reply:* It should only affect you if you're using https://greatexpectations.io/
*Thread Reply:* I have a similar message after installing openlineage into Amazon MWAA from the scheduler logs:
WARNING:/usr/local/airflow/.local/lib/python3.7/site-packages/openlineage/airflow/extractors/great_expectations_extractor.py:Did not find great_expectations_provider library or failed to import it
I am not using great expectations in the DAG.
I see a few priorities for Airflow integration:
- Direct relationship 1-1 between Dag && Job. At the moment every task is a different job in marquez. What i consider wrong.
- Airflow Inlets/outlets integration with marquez When do you think you guys can have this? If you need any help I can happily contribute, but I would need some help
*Thread Reply:* I don't think 1) is a good idea. You can have multiple tasks in one dag, processing different datasets and producing different datasets. If you want visual linking of jobs that produce disjoint datasets, then I think you want this: https://github.com/MarquezProject/marquez/issues/1737 which wuill affect visual layer.
Regarding 2), I think we need to get along with Airflow maintainers regarding long term mechanism on which OL will work: https://github.com/apache/airflow/issues/17984
I think using inlets/outlets as a fallback mechanism when we're not doing automatic metadata extraction is a good idea, but we don't know if hypothetical future mechanism will have access to these. It's hard to commit to mechanism which might disappear soon.
Another option is that I build my own extractor, do you have any example of how to create a custom extractor? How I can apply that customExtractor to specific operators? Is there a way to link an extractor with an operator, so at runtime airflow knows which extractor to run?
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow#custom-extractors
I think you can base your code on any existing extractor, like PostgresExtractor: https://github.com/OpenLineage/OpenLineage/blob/main/integration/airflow/openlineage/airflow/extractors/postgres_extractor.py#L53
Custom extractors work just like buildin ones, just that you need to add bit of mapping between operator and extractor, like OPENLINEAGE_EXTRACTOR_PostgresOperator=openlineage.airflow.extractors.postgres_extractor.PostgresExtractor
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you very much @Maciej Obuchowski
Last question of the morning. Running one task that failed i could see that no information appeared in Marquez. Is this something that is expected to happen? I would like to see in Marquez all the history of runs, successful and unsucessful them.
*Thread Reply:* It worked like that in Airflow 1.10.
This is an unfortunate limitation of LineageBackend API that we're using for Airflow 2. We're trying to work out solution for this with Airflow maintainers: https://github.com/apache/airflow/issues/17984
<a href="https://github.com/apache/airflow">apache/airflow</a>
Hello openlineage community.
Yesterday I tried the integration with spark.
The result was not satisfactory. This is what I did:
- Add openlineage-spark dependency
- Add these lines:
.config("spark.jars.packages", "io.openlineage:openlineage_spark:0.3.1") .config("spark.extraListeners", "io.openlineage.spark.agent.OpenLineageSparkListener") .config("spark.openlineage.url", "<https://marquez-internal-eks.eu-west-1.dev.hbi.systems/api/v1/namespaces/spark_integration/>"This job was doing spark.read from 2 different json location. It is doing spark write to 5 different parquet location in s3. The job finished succesfully and the result in marquez is:
If I enter in the bucket namespaces I see nowthing inside
*Thread Reply:* This job with no output is a symptom of the output not being understood. you should be able to see the facets for that job. There will be a spark_unknown facet with more information about the problem. If you put that into an issue with some more details about this job we should be able to help.
*Thread Reply:* I ll try to put all the info in a ticket, as it is not working as i would expect
The page froze and no link from the menu works. Apart from that I see that there are no messages in the logs
*Thread Reply:* Is there an error in the browser javascript console? (example on chrome: View -> Developer -> Javascript console)

Hi #general, I'm a data engineer for a UK-based insuretech (part of one of the biggest UK retail insurers). We run a series of tech meetups and we'd love to have someone from the OpenLineage project to give us a demo of the tool. Would anyone be interested (DM if so 🙂 ) ?

Hi! Is there an example of tracking lineage when using Pandas to read/write and transform data?
*Thread Reply:* Hi Taleb - I don’t know of a generalized example of lineage tracking with Pandas, but you should be able to accomplish this by sending the runEvents manually to the OpenLineage API in your code: https://openlineage.io/docs/openapi/
*Thread Reply:* Is this a work in progress, that we can investigate? Because I see it in this image https://github.com/OpenLineage/OpenLineage/blob/main/doc/Scope.png
 <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* To my knowledge, while there are a few proposals around adding a wrapper on some Pandas methods to output runEvents, it’s not something that’s had work started on it yet
*Thread Reply:* I sent some feelers out to get a little more context from folks who are more informed about this than I am, so I’ll get you more info about potential future plans and the considerations around them when I know more
*Thread Reply:* So, Pandas is tricky because unlike Airflow, DBT, or Spark, Pandas doesn’t own the whole flow, and you might dip in and out of it to use other Python Packages (at least I did when I was doing more Data Science).
We have this issue open in OpenLineage that you should go +1 to help with our planning 🙂
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* interesting... what if it were instead on all the read_** to_** functions?

Hi! I am working alongside David at integrating OpenLineage into our Data Pipelines. I have a questions around Marquez and OpenLineage's divergent APIs:
That is to say, these 2 APIs differ:
https://openlineage.io/docs/openapi/
https://marquezproject.github.io/marquez/openapi.html
This makes sense since they are at different layers of abstraction, but Marquez requires a few things that are absent from OpenLineage's API, for example the type in a data source, the distinctions between physicalName and sourceName in Datasets. Is that intentional? And can these be set using the OpenLineage API as some additional facets or keys? I noticed that the DatasourceDatasetFacet has a map of additionalProperties .
*Thread Reply:* The Marquez write APIs are artifacts from before OpenLineage existed, and they’re already slated for deprecation soon.
If you POST an OpenLineage runEvent to the /lineage endpoint in Marquez, it’ll create any missing jobs or datasets that are relevant.
*Thread Reply:* Thanks for the response. That sounds good. Does this include the query interface e.g.
http://localhost:5000/api/v1/namespaces/testing_java/datasets/incremental_data
as that currently returns the Marquez version of a dataset including default set fields for type and the above mentioned properties.
*Thread Reply:* I believe the intention for type is to support a new facet- TBH, it hasn't been the most pressing concern for most users, as most people are only recording tables, not streams. However, there's been some recent work to support Kafka in Spark- maybe it's time to address that deficiency.
I don't actually know what happened to the datasource type field- maybe @Julien Le Dem can comment on whether that field was dropped intentionally or whether it was an oversight.
*Thread Reply:* It looks like an oversight, currently Marquez hard codes it to POSGRESQL: https://github.com/MarquezProject/marquez/blob/734bfd691636cb00212d7d22b1a489bd4870fb04/api/src/main/java/marquez/db/OpenLineageDao.java#L438
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* The source has a name though: https://github.com/OpenLineage/OpenLineage/blob/8afc4ff88b8dd8090cd9c45061a9f669fea2151e/spec/facets/DatasourceDatasetFacet.json#L12
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
The next OpenLineage monthly meeting is this coming Wednesday at 9am PT The tentative agenda is: • OL Client use cases for Apache Iceberg [Ryan] • OpenLineage and Azure Purview [Shrikanth] • Proxy Backend and Egeria integration progress update (Issue #152) [Mandy] • OpenLineage last release overview (0.3.1) ◦ Facet versioning ◦ Airflow 2 / Spark 3 support, dbt improvements • OpenLineage 0.4 scope review ◦ Proxy Backend (Issue #152) ◦ Spark, Airflow, dbt improvements (documentation, coverage, ...) ◦ improvements to the OpenLineage model • Open discussion
 <a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* If you want to add something please chime in this thread
*Thread Reply:* The monthly meeting is happening tomorrow. The purview team will present at the December meeting instead See full agenda here: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting You are welcome to contribute
*Thread Reply:* The slides for the meeting later today: https://docs.google.com/presentation/d/1z2NTkkL8hg_2typHRYhcFPyD5az-5-tl/edit#slide=id.ge7d4b64ef4_0_0
*Thread Reply:* I have posted the notes and the recording from the last instance of our monthly meeting: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting#MonthlyTSCmeeting-Nov10th2021(9amPT) I have a few TODOs to follow up on tickets
The next release of OpenLineage is being scoped: https://github.com/OpenLineage/OpenLineage/projects/6 Please chime in if you want to raise the priority of something or are planning to contribute

Hi, I have been looking at open lineage for some time. And I really like it. It is very simple specification that covers a lot of use-cases. You can create any provider or consumer in a very simple way. So that’s pretty powerful. I have some questions about things that are not clear to me. I am not sure if this is the best place to ask. Please refer me to other place if this is not appropriate.
*Thread Reply:* How do you model continuous process (not batch processes). For example a flume or spark job that does some real time processing on data.
Maybe it’s simply a “Job” But than what is run ?
*Thread Reply:* How do you model consumers at the end - they can be reports? Data applications, ML model deployments, APIs, GUI consumed by end users ?
Have you considered having some examples of different use cases like those?
*Thread Reply:* By definition, Job is a process definition that consumes and produces datasets. It is many to many relations? I’ve been wondering about that.Shouldn’t be more restrictive? For example important use-case for lineage is troubleshooting or error notifications (e.g mark report or job as temporarily in bad state if upstream data integration is broken). In order to be able to that you need to be able to traverse the graph to find the original error. So having multiple inputs produce single output make sense (e.g insert into output_1 select ** from x,y group by a,b) . But what are the cases where you’d want to see multiple outputs ? You can have single process produce multiple tables (in above example) but they’d alway be separate queries. The actual inputs for each output would be different.
But having multiple outputs create ambiguity as now If x or y is broken but have multiple outputs I do not know which is really impacted?
*Thread Reply:* > How do you model continuous process (not batch processes). For example a flume or spark job that does some real time processing on data. > > Maybe it’s simply a “Job” But than what is run ? Every continuous process eventually has end - for example, you can deploy new version of your Flink pipeline. The new version would be the next Run for the same Job.
Moreover, OTHER event type is useful to update metadata like amount of processed records. In this Flink example, it could be emitted per checkpoint.
I think more attention for streaming use cases will be given soon.
*Thread Reply:* > How do you model consumers at the end - they can be reports? Data applications, ML model deployments, APIs, GUI consumed by end users ? Our reference implementation is an web application https://marquezproject.github.io/marquez/
We definitely do not exclude any of the things you're talking about - and it would make a lot of sense to talk more about potential usages.
*Thread Reply:* > By definition, Job is a process definition that consumes and produces datasets. It is many to many relations? I’ve been wondering about that.Shouldn’t be more restrictive? I think this is too SQL-centric view 🙂
Not everything is a query. For example, those Flink streaming jobs can produce side outputs, or even push data to multiple sinks. We need to model those types of jobs too.
If your application does not do multiple outputs, then I don't see how specification allowing those would impact you.
*Thread Reply:* > We definitely do not exclude any of the things you’re talking about - and it would make a lot of sense to talk more about potential usages. Yes I think that would be great if we expand on potential usages. if Open Lineage documentation (perhaps) has all kind of examples for different use-cases or case studies. Financal or healthcase industry case study and how would someone doing integration with OpenLineage. It would be easier to understand the concepts and make sure things are modeled consistently.
*Thread Reply:* > I think this is too SQL-centric view 🙂 > > Not everything is a query. For example, those Flink streaming jobs can produce side outputs, or even push data to multiple sinks. We need to model those types of jobs too. Thanks for answering @Maciej Obuchowski
Even in SQL you can have multiple outputs if you look thing at transaction level. I was simply using it as an example.
Maybe it would be clear what I mean in another example . Let’s say we have those phases
- Ingest from sources
- Process/transform
- export to somewhere (image/diagram) https://mermaid.ink/img/eyJjb2RlIjoiXG5ncmFwaCBMUlxuICAgIHN1YmdyYXBoIFNvdXJjZXNcbi[…]yIjpmYWxzZSwiYXV0b1N5bmMiOnRydWUsInVwZGF0ZURpYWdyYW0iOmZhbHNlfQ
Let’s look at those two cases:
- Within a single flink job and even task: Inventory & UI are both written to both S3, DB
- Within a single flink job and even task: Inventory is written only to S3, UI is written only to DB
In 1. open lineage run event could look like {inputs: [ui, inventory], outputs: [s3, db] }
In 2. user can either do same as 1. (because data changes or copy-paste) which would be an error since both do not go to both
Likely accurate one would be
{inputs: [ui], outputs: [s3] } {inputs: [ui], outputs: [db] }
If the specification standard required single output then
- would be modelled like run event
{inputs: [ui, inventory], outputs: [s3] };{inputs: [ui, inventory], outputs: [db] }which is still correct if more verbose. - could only be modelled this way:
{inputs: [ui], outputs: [s3] };{inputs: [ui], outputs: [db] }
The more restrictive specification seems to lower the chance for an error doesn’t it?
Also if tools know spec guarantees single output , they’d be able to write tracing capabilities which are more precise because the structure would allow for less ambiguity. Storage backends that implement the spec could be also written in more optimal ways perhaps I have not looked into those accuracy of those hypothesis though.
Those were the thoughts I was thinking when asking about that. I’d be curious if there’s document on the research of pros/cons and alternatives for the design of the current specifications
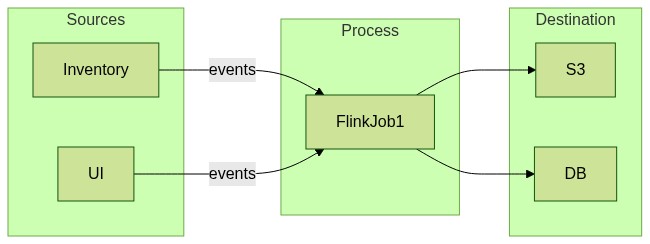
*Thread Reply:* @Anthony Ivanov I see what you're trying to model. I think this could be solved by column level lineage though - when we'll have it. OL consumer could look at particular columns and derive which table contained particular error.
> 2. Within a single flink job and even task: Inventory is written only to S3, UI is written only to DB Does that actually happen? I understand this in case of job, but having single operator write to two different systems seems like bad design. Wouldn't that leave the possibility of breaking exactly-once unless you're going full into two phase commit?
*Thread Reply:* > Does that actually happen? I understand this in case of job, but having single operator write to two different systems seems like bad design In a Spark or flink job it is less likely now that you mention it. But in a batch job (airflow python or kubernetes operator for example) users could do anything and then they’d need lineage to figure out what is wrong if even if what they did is suboptimal 🙂
> I see what you’re trying to model. I am not trying to model something specific. I am trying to understand how would openlineage be used in different organisations/companies and use-cases.
> I think this could be solved by column level lineage though There’s something specific planned ? I could not find a ticket in github. I thought you can use Dataset Facets - Schema for example could be subset of columns for a table …
*Thread Reply:* @Anthony Ivanov take a look at this: https://github.com/OpenLineage/OpenLineage/issues/148
How do you deleting jobs/runs from Marquez/OpenLineage?
*Thread Reply:* We’re adding APIs to delete metadata in Marquez 0.20.0. Here’s the related issue, https://github.com/MarquezProject/marquez/issues/1736
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Until then, you can connected to the DB directly and drop the rows from both the datasets and jobs tables (I know, not dieal)
*Thread Reply:* Thanks! I assume deleting information will remain a Marquez only feature rather than becoming part of OpenLineage itself?
*Thread Reply:* Yes! Delete operations will be an action supported by consumers of OpenLineage events
Am I understanding namespaces correctly? A job namespace is different to a Dataset namespace. And that job namespaces define a job environment, like Airflow, Spark or some other system that executes jobs. But Dataset namespace define data locations, like an S3 bucket, local file system or schema in a Database?
*Thread Reply:* I've been skimming this page: https://github.com/OpenLineage/OpenLineage/blob/main/spec/Naming.md
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Excellent, I think I had mistakenly conflated the two originally. This document makes it a little clearer. As an additional question: When viewing a Dataset in Marquez will it cross the job namespace bounds? As in, will I see jobs from different job namespaces?
*Thread Reply:* The above document seems to have implied a namespace could be like a connection string for a database
*Thread Reply:* Wait, it does work? Marquez was being temperamental
*Thread Reply:* Yes, marquez is unable to fetch lineage for either dataset
*Thread Reply:* I think you might have hit this issue: https://github.com/MarquezProject/marquez/issues/1744
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* or, maybe not? It was released already.
Can you create issue on github with those helpful gifs? @Lyndon Armitage
*Thread Reply:* I think you are right Maciej
*Thread Reply:* Was that patched in 0,19.1?
*Thread Reply:* As far as I see yes: https://github.com/MarquezProject/marquez/releases/tag/0.19.1
Haven't tested this myself unfortunately.
*Thread Reply:* Perhaps not. It is urlencoding them:
<http://localhost:3000/lineage/dataset/jdbc%3Ah2%3Amem%3Asql_tests_like/HBMOFA.ORDDETP>
But the error seems to be in marquez getting them.
*Thread Reply:* This is an example Lineage event JSON I am sending.
*Thread Reply:* I did run into another issue with really long names not being supported due to Marquez's DB using a fixed size string for a column, but that is understandable and probably a non-issue (my test code was generating temporary folders with long names).
*Thread Reply:* A 404 is returned for: http://localhost:3000/api/v1/lineage/?nodeId=dataset:jdbc%3Ah2%3Amem%3Asql_tests_like:HBMOFA.ORDDETP
*Thread Reply:* @Lyndon Armitage can you create issue on the Marquez repo? https://github.com/MarquezProject/marquez/issues
*Thread Reply:* https://github.com/MarquezProject/marquez/issues/1761 Is this sufficient?
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Yup, thanks!
I am looking at an AWS Glue Crawler lineage event. The glue crawler creates or updates a table schema, and I have a few questions on aligning to best practice.
- Is this a dataset create/update or…
- … a job with no dataset inputs and only dataset outputs or
- … is the path in S3 the input and the Glue table the output?
- Is there an example of the lineage even here I can clone or work from? Thanks.
*Thread Reply:* Hi Francis, for the event is it creating a new table with new data in glue / adding new data to an existing one or is it simply reformatting an existing table or making an empty one?
*Thread Reply:* The table does not exist in the Glue catalog until …
A Glue crawler connects to one or more data stores (in this case S3), determines the data structures, and writes tables into the Data Catalog.
The data/objects are in S3, the Glue catalog is a metadata representation (HIVE) as as table.
*Thread Reply:* Hmm, interesting, so the lineage of interest here would be of the metadata flow not of the data itself?
In that case I’d say that the glue Crawler is a job that outputs a dataset.
*Thread Reply:* The crawler is a job that discovers a dataset. It doesn't create it. If you're posting lineage yourself, I'd post it as an input event, not an output. The thing that actually wrote the data - generated the records and stored them in S3 - is the thing that would be outputting the dataset
*Thread Reply:* @Michael Collado I agree the crawler discovers the S3 dataset. It also creates an event which creates/updates the HIVE/Glue table.
If the Glue table isn’t a distinct dataset from the S3 data, how does this compare to a view in a database on top of a table. Are they 2 datasets or just one?
Glue can discover data in remote databases too, in those cases does it make sense to have only the source dataset?
*Thread Reply:* @John Thomas yes, its the metadata flow.
*Thread Reply:* that's how the Spark integration currently treats Hive datasets- I'd like to add a facet to attach that indicates that it is being read as a Hive table, and include all the appropriate metadata, but it uses the dataset's location in S3 as the canonical dataset identifier
*Thread Reply:* @Francis McGregor-Macdonald I think the way to represent this is predicated on what you’re looking to accomplish by sending a runEvent for the Glue crawler. What are your broader objectives in adding this?
*Thread Reply:* I am working through AWS native services seeing how they could, can, or do best integrate with openlineage (I’m an AWS SA). Hence the questions on best practice.
Aligning with the Spark integration sounds like it might make sense then. Is there an example I could build from?
*Thread Reply:* an example of reporting lineage? you can look at the Spark integration here - https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/
*Thread Reply:* Ahh, in that case I would have to agree with Michael’s approach to things!
*Thread Reply:* @Michael Collado I am following the Spark integration you recommended (for a Glue job) and while everything appears to be set up correct, I am getting no lineage appear in marquez (a request.get from the pyspark script can reach the endpoint). Is there a way to enable a debug log so I can look to identify where the issue is? Is there a specific place to look in the regular logs?
*Thread Reply:* listener output should be present in the driver logs. you can turn on debug logging in your log4j config (or whatever logging tool you use) for the package io.openlineage.spark.agent
Woo hoo! Initial Spark <-> Kafka support has been merged 🙂 https://github.com/OpenLineage/OpenLineage/pull/387
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
I am “successfully” exporting lineage to openlineage from AWS Glue using the listener. Only the source load is showing, not the transforms, or the sink
*Thread Reply:* Output event:
2021-11-22 08:12:15,513 INFO [spark-listener-group-shared] agent.OpenLineageContext (OpenLineageContext.java:emit(50)): Lineage completed successfully: ResponseMessage(responseCode=201, body=, error=null) {
“eventType”: “COMPLETE”,
“eventTime”: “2021-11-22T08:12:15.478Z”,
“run”: {
“runId”: “03bfc770-2151-499e-9265-8457a38ceec3”,
“facets”: {
“sparkversion”: {
“producer”: “https://github.com/OpenLineage/OpenLineage/tree/0.3.1/integration/spark”,
“schemaURL”: “https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet”,
“spark-version”: “3.1.1-amzn-0”,
“openlineage-spark-version”: “0.3.1”
}
}
},
“job”: {
“namespace”: “sparkintegration”,
“name”: “nyctaxirawstage.mappartitionsunionmappartitionsnew_hadoop”
},
“inputs”: [
{
“namespace”: “s3.cdkdl-dev-foundationstoragef3787fa8-raw1d6fb60a-171gwxf2sixt9”,
“name”: “
*Thread Reply:* This sink record is missing details …
2021-11-22 08:12:15,481 INFO [Thread-7] sinks.HadoopDataSink (HadoopDataSink.scala:$anonfun$writeDynamicFrame$1(275)): nameSpace: , table:
*Thread Reply:* I can also see multiple history events (presumably for each transform, each as above) emitted for the same Glue Job, with different RunId, with the same inputs and the same (null) output.
*Thread Reply:* Are you using the existing spark integration for the spark lineage?
*Thread Reply:* I followed: https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark
In the Glue context I was not clear on the correct settings for “spark.openlineage.parentJobName” and “spark.openlineage.parentRunId”, I put in static values (which may be incorrect)?
I injected these via: "--conf": "spark.openlineage.parentJobName=nyc-taxi-raw-stage",
*Thread Reply:* Happy to share what is working when I am done, I can’t seem to find an AWS Glue specific example to walk me through.
*Thread Reply:* yeah, We haven’t spent any significant time with AWS Glue, but we just released the Databricks integration, which might help guide the way you’re working a little bit more
*Thread Reply:* from what I can see in the DBX integration (https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/databricks) all of what is being done here I am doing in Glue (upload the jar, embed the settings into the Glue spark job). It is emitting the above for each transform in the Glue job, but does not seem to capture the output …
*Thread Reply:* Is there a standard Spark test script in use with openlineage I could put into Glue to test without using any Glue specific functionality (without for example the GlueContext, or Glue dynamic frames)?
*Thread Reply:* The initialisation does appear to be working if I compare it to the DBX README
Mine from AWS Glue…
21/11/22 18:48:48 INFO SparkContext: Registered listener io.openlineage.spark.agent.OpenLineageSparkListener
21/11/22 18:48:49 INFO OpenLineageContext: Init OpenLineageContext: Args: ArgumentParser(host=<http://ec2>-….<a href="http://compute-1.amazonaws.com:5000">compute-1.amazonaws.com:5000</a>, version=v1, namespace=spark_integration, jobName=default, parentRunId=null, apiKey=Optional.empty) URI: <http://ec2>-….<a href="http://compute-1.amazonaws.com:5000/api/v1/lineage">compute-1.amazonaws.com:5000/api/v1/lineage</a>
21/11/22 18:48:49 INFO AsyncEventQueue: Process of event SparkListenerApplicationStart(nyc-taxi-raw-stage,Some(spark-application-1637606927106),1637606926281,spark,None,None,None) by listener OpenLineageSparkListener took 1.092252643s.
*Thread Reply:* We don’t have a test run, unfortunately, but you could follow this blog post’s processes in each and see what the differences are? https://openlineage.io/blog/openlineage-spark/
*Thread Reply:* Thanks, I have been looking at that. I will create a Glue job aligned with that. What is the best way to pass feedback? Keep it here?
*Thread Reply:* yeah, this thread will work great 🙂

*Thread Reply:* @Francis McGregor-Macdonald are you managed to enable it?
*Thread Reply:* Just DM you the code I used a while back (app.py + CDK code). I haven’t used it in a while, and there is some duplication in it. I had openlineage enabled, but dynamic frames not working yet with lineage. Let me know how you go. I haven’t had the space to look at it in a while, but happy to support if you are looking at it.

how to use the Open lineage with amundsen ?
*Thread Reply:* You can use this: https://github.com/amundsen-io/amundsen/pull/1444
<a href="https://github.com/amundsen-io/amundsen">amundsen-io/amundsen</a>
*Thread Reply:* you can also check out this section from the Amundsen Community Meeting in october: https://www.youtube.com/watch?v=7WgECcmLSRk

*Thread Reply:* No, I believe the databuilder OpenLineage extractor for Amundsen will continue to store lineage metadata in Atlas
*Thread Reply:* We've spoken to the Amundsen team, and though using Marquez to store lineage metadata isn't an option, it's an integration that makes sense but hasn't yet been prioritized
*Thread Reply:* Thanks , Right now amundsen has no support for lineage extraction from spark or airflow , if this case do we need to use marquez for open lineage implementation to capture the lineage from airflow & spark
*Thread Reply:* Maybe, that would mean running the full Amundsen stack as well as the Marquez stack along side each other (not ideal). The OpenLineage integration for Amundsen is very recent, so haven't had a chance to look deeply into the implementation. But, briefly looking over the config for Openlineagetablelineageextractor, you can only send metadata to Atlas
*Thread Reply:* @Willy Lulciuc thats our real concern , running the two stacks will make a mess environment , let me explain our amundsen setup , we are having neo4j as backend , (front end , search service , metadata service,elastic search & neo4j) . our requirement to capture lineage from spark and airflow , imported into amundsen

*Thread Reply:* We are running into a similar issue. @Dinakar Sundar were you able to get the Amundsen OpenLineage integration to work with a neo4j backend?

Hi all - i just watched the presentation on this and Marquez from the Airflow 21 summit. I was pretty impressed with this. My question is what other open source players are in this space or are pretty much people consolidating around this? (which would be great). Was looking at the available datasource extractors for the airflow side and would hope to see more here, looking at the code doesn't seem like too huge of a deal. Is there a roadmap available?
*Thread Reply:* You can take a look at https://github.com/OpenLineage/OpenLineage/projects

Hi all, I was wondering what is the status of native support of openlineage for DataHub or Amundzen. re https://openlineage.slack.com/archives/C01CK9T7HKR/p1633633476151000?thread_ts=1633008095.115900&cid=C01CK9T7HKR Many thanks!
our amundsen setup , we are having neo4j as backend , (front end , search service , metadata service,elastic search & neo4j) . our requirement to capture lineage from spark and airflow , imported into amundsen ?
Hello, OpenLineage folks - I'm curious if anyone here has ran into an issue like we're running into as we look to extend OpenLineage's Spark integration into Databricks.
Has anyone ran into an issue where a scala class should exist (based on a decompiled jar, I see that it's a public class) but you keep getting an error like object SqlDWRelation in package sqldw cannot be accessed in package com.databricks.spark.sqldw?
Databricks has a Synapse SQL DW connector: https://docs.databricks.com/data/data-sources/azure/synapse-analytics.html
I want to extract the database URL, table, and schema from the logical plan but
I execute something like the below command that runs a SELECT ** on the given tableName ("borrower" in this case) in the Azure Synapse database.
val df = spark.read.format("com.databricks.spark.sqldw")
.option("url", sqlDwUrl)
.option("tempDir", tempDir)
.option("forwardSparkAzureStorageCredentials", "true")
.option("dbTable", tableName)
.load()
val logicalPlan = df.queryExecution.logical
val logicalRelation = logicalPlan.asInstanceOf[LogicalRelation]
val sqlBaseRelation = logicalRelation.relation
I end up with something like this, all good so far:
```logicalPlan: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Relation[memberId#97,residentialState#98,yearsEmployment#99,homeOwnership#100,annualIncome#101,incomeVerified#102,dtiRatio#103,lengthCreditHistory#104,numTotalCreditLines#105,numOpenCreditLines#106,numOpenCreditLines1Year#107,revolvingBalance#108,revolvingUtilizationRate#109,numDerogatoryRec#110,numDelinquency2Years#111,numChargeoff1year#112,numInquiries6Mon#113] SqlDWRelation("borrower")
logicalRelation: org.apache.spark.sql.execution.datasources.LogicalRelation = Relation[memberId#97,residentialState#98,yearsEmployment#99,homeOwnership#100,annualIncome#101,incomeVerified#102,dtiRatio#103,lengthCreditHistory#104,numTotalCreditLines#105,numOpenCreditLines#106,numOpenCreditLines1Year#107,revolvingBalance#108,revolvingUtilizationRate#109,numDerogatoryRec#110,numDelinquency2Years#111,numChargeoff1year#112,numInquiries6Mon#113] SqlDWRelation("borrower")
sqlBaseRelation: org.apache.spark.sql.sources.BaseRelation = SqlDWRelation("borrower")``
Schema, I can easily get withsqlBaseRelation.schema` but I cannot figure out:
- How I can get the database name from the logical relation
- How I can get the table name from the logical relation ("borrower" is the table name so I can always parse the string if necessary"
I know that Databricks has the SqlDWRelation class which I think I need to cast the BaseRelation to BUT it appears to be in a jar / package that is inaccessible during the execution of a notebook. Specifically
import com.databricks.spark.sqldw.SqlDWRelationis the relation and it appears to have a few accessors that would help me answer some of these questions:paramsandJDBCWrapper
Of course this is undocumented on the Databricks side 😰
If I could cast the BaseRelation into this SqlDWRelation, I'd be able to get this info. However, whenever I attempt to use the imported SqlDWRelation, I get an error object SqlDWRelation in package sqldw cannot be accessed in package com.databricks.spark.sqldw I'm hoping someone has run into something similar in the past on the Spark / Databricks / Scala side and might share some advice. Thank you for any guidance!
*Thread Reply:* Have you tried reflection? https://commons.apache.org/proper/commons-lang/apidocs/org/apache/commons/lang3/reflect/FieldUtils.html#getDeclaredField-jav[…].lang.String-boolean-
*Thread Reply:* I have not! Will give it a try, Maciej! Thank you for the reply!
*Thread Reply:* 🙏 @Maciej Obuchowski we're not worthy! That was the magic we needed. Seems like a hack since we're snooping in on private classes but if it works...
Thank you so much for pointing to those utilities!
*Thread Reply:* Glad I could help!
A colleague pointed me at https://open-metadata.org/, is there anywhere a view or comparison of this and openlineage?
*Thread Reply:* Different concepts. OL is focused on describing the lineage and metadata of the running jobs. So it keeps track of all the metadata (schema, ...) of inputs and outputs at the time transformation occurs + transformation metadata (code version, cost, etc.)
OM I am not an expert but it's a metadata model with clients and API around it.

Hey! OpenLineage is a beautiful initiative, to be honest! We also try to accommodate it. One question, maybe it's already described somewhere then many apologies :) if we need to propagate run id from Airflow to a child task (AWS Batch job, for instance) what will be the best way to do it in the current realization (as we get run id only at post execute phase)?.. We use Airflow 2+ integration.
*Thread Reply:* Hey. For technical reasons, we can't automatically register macro that does this job, as we could in Airflow 1 integration. You could put it yourself:
*Thread Reply:* ```def lineageparentid(run_id, task): """ Macro function which returns the generated job and run id for a given task. This can be used to forward the ids from a task to a child run so the job hierarchy is preserved. Child run can create ParentRunFacet from those ids. Invoke as a jinja template, e.g.
PythonOperator(
task_id='render_template',
python_callable=my_task_function,
op_args=['{{ lineage_parent_id(run_id, task) }}'], # lineage_run_id macro invoked
provide_context=False,
dag=dag
)
:param run_id:
:param task:
:return:
"""
with create_session() as session:
job_name = openlineage_job_name(task.dag_id, task.task_id)
ids = JobIdMapping.get(job_name, run_id, session)
if ids is None:
return ""
elif isinstance(ids, list):
run_id = "" if len(ids) == 0 else ids[0]
else:
run_id = str(ids)
return f"{_DAG_NAMESPACE}/{job_name}/{run_id}"
def openlineagejobname(dagid: str, taskid: str) -> str: return f'{dagid}.{taskid}'```
*Thread Reply:* from here: https://github.com/OpenLineage/OpenLineage/blob/main/integration/airflow/openlineage/airflow/dag.py#L77
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* the quickest response ever! And that works like a charm 🙌
*Thread Reply:* Glad I could help!
@Maciej Obuchowski and @Michael Collado given your work on the Spark Integration, what's the right way to explore the Write operations' logical plans? When doing a read, it's easy! In scala df.queryExecution.logical gives you exactly what you need but how do you guys interactively explore what sort of commands are being used during a write? We are exploring some of the DataSourceV2 data sources and are hoping to learn from you guys a bit more, please 😃
*Thread Reply:* For SQL, EXPLAIN EXTENDED and show() in scala-shell is helpful:
spark.sql("EXPLAIN EXTENDED CREATE TABLE tbl USING delta LOCATION '/tmp/delta' AS SELECT ** FROM tmp").show(false)
```|== Parsed Logical Plan ==
'CreateTableAsSelectStatement [tbl], delta, /tmp/delta, false, false
+- 'Project [**]
+- 'UnresolvedRelation [tmp], [], false
== Analyzed Logical Plan ==
CreateTableAsSelect org.apache.spark.sql.delta.catalog.DeltaCatalog@63c5b63a, default.tbl, [provider=delta, location=/tmp/delta], false +- Project [x#12, y#13] +- SubqueryAlias tmp +- LocalRelation [x#12, y#13]
== Optimized Logical Plan == CreateTableAsSelect org.apache.spark.sql.delta.catalog.DeltaCatalog@63c5b63a, default.tbl, [provider=delta, location=/tmp/delta], false +- LocalRelation [x#12, y#13]
== Physical Plan == AtomicCreateTableAsSelect org.apache.spark.sql.delta.catalog.DeltaCatalog@63c5b63a, default.tbl, LocalRelation [x#12, y#13], [provider=delta, location=/tmp/delta, owner=mobuchowski], [], false +- LocalTableScan [x#12, y#13] |```
*Thread Reply:* For dataframe api, I'm usually just either logging plan to console from OpenLineage listener, or looking at sparklogicalPlan or sparkunknown facets send by listener - even when the particular write operation isn't supported by integration, those facets should have some relevant info.
*Thread Reply:* For example, for the query I've send at comment above, the spark_logicalPlan facet looks like this:
"spark.logicalPlan": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/0.4.0-SNAPSHOT/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>",
"plan": [
{
"allowExisting": false,
"child": [
{
"class": "org.apache.spark.sql.catalyst.plans.logical.LocalRelation",
"data": null,
"isStreaming": false,
"num-children": 0,
"output": [
[
{
"class": "org.apache.spark.sql.catalyst.expressions.AttributeReference",
"dataType": "integer",
"exprId": {
"id": 2,
"jvmId": "e03e2860-a24b-41f5-addb-c35226173f7c",
"product-class": "org.apache.spark.sql.catalyst.expressions.ExprId"
},
"metadata": {},
"name": "x",
"nullable": false,
"num-children": 0,
"qualifier": []
}
],
[
{
"class": "org.apache.spark.sql.catalyst.expressions.AttributeReference",
"dataType": "integer",
"exprId": {
"id": 3,
"jvmId": "e03e2860-a24b-41f5-addb-c35226173f7c",
"product-class": "org.apache.spark.sql.catalyst.expressions.ExprId"
},
"metadata": {},
"name": "y",
"nullable": false,
"num-children": 0,
"qualifier": []
}
]
]
}
],
"class": "org.apache.spark.sql.execution.command.CreateViewCommand",
"name": {
"product-class": "org.apache.spark.sql.catalyst.TableIdentifier",
"table": "tmp"
},
"num-children": 0,
"properties": null,
"replace": true,
"userSpecifiedColumns": [],
"viewType": {
"object": "org.apache.spark.sql.catalyst.analysis.LocalTempView$"
}
}
]
},
*Thread Reply:* Okay! That is very helpful! I wasn't sure if there was a fancier trick but I can definitely do logging 🙂 Our challenge was that our proprietary packages were resulting in Null Pointer Exceptions when it tried to push to OpenLineage 😞
*Thread Reply:* You can always add test cases and add breakpoints to debug in your IDE. That doesn't work for the container tests, but it does work for the other ones
*Thread Reply:* Ah! That's a great point! I definitely would appreciate being able to poke at the objects interactively in a debug mode. Thank you for the guidance as well!

hi everyone! 👋 Very noob question here: I’ve been wanting to play with Marquez and open lineage for my company’s projects. I use mostly scala & spark, but also Airflow. I’ve been reading and watching talks about OpenLineage and Marquez. So far i didn’t quite discover if Marquez or OpenLineage does field-level lineage (with Spark), like spline tries to.
Any idea?
Other sources about this topic • https://medium.com/cdapio/data-integration-with-field-level-lineage-5d9986524316 • https://medium.com/cdapio/field-level-lineage-part-1-3cc5c9e1d8c6 • https://medium.com/cdapio/designing-field-level-lineage-part-2-b6c7e6af5bf4 • https://www.youtube.com/playlist?list=PL897MHVe_nHeEQC8UnCfXecmZdF0vka_T • https://www.youtube.com/watch?v=gKYGKXIBcZ0 • https://www.youtube.com/watch?v=eBep6rRh7ic



*Thread Reply:* Hi Ricardo - OpenLineage doesn’t currently have support for field-level lineage, but it’s definitely something we’ve been looking into. This is a great collection of resources 🙂
We’ve to-date been working on our integrations library, making it as easy to set up as possible.
*Thread Reply:* Thanks John! I was checking the issues on github and other posts here. Just wanted to clarify that. I’ll keep an eye on it
The next OpenLineage monthly meeting is this Wednesday at 9am PT. (everybody is welcome to join) The slides are here: https://docs.google.com/presentation/d/1q2Be7WTKlIhjLPgvH-eXAnf5p4w7To9v/edit#slide=id.ge4b57c6942_0_75 tentative agenda: • SPDX headers [Mandy Chessel] • Azure Purview + OpenLineage [Will Johnson, Mark Taylor] • Logging backend (OpenTelemetry, ...) [Julien Le Dem] • Open discussion Please chime in in this thread if you’d want to add something
*Thread Reply:* The link to join the meeting is on the wiki: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
*Thread Reply:* Please reach out to me if you’d like to be added to a gcal invite
@John Thomas we in Condenast currently exploring the features of open lineage to integrate to databricks , https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/databricks , spark configuration not working ,
*Thread Reply:* Hi Dinakar. Can you give some specifics regarding what kind of problem you're running into?
*Thread Reply:* Hi @Michael Collado, were able to set the spark configuration for spark extra listener & placed jars as well , wen i ran the sapark job , Lineage is not get tracked into the marquez
*Thread Reply:* {"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.3.1/integration/spark","schemaURL":"https://github.com/OpenLineage/OpenLineage/tree/0.3.1/integration/spark/facets/spark/v1/output-statistics-facet.json","rowCount":0,"size":-1,"status":"DEPRECATED"}},"outputFacets":{"outputStatistics":{"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.3.1/integration/spark","schemaURL":"https://openlineage.io/spec/facets/1-0-0/OutputStatisticsOutputDatasetFacet.json#/$defs/OutputStatisticsOutputDatasetFacet","rowCount":0,"size":-1}}}],"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.3.1/integration/spark","schemaURL":"https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunEvent"}
OpenLineageHttpException(code=0, message=java.lang.IllegalArgumentException: Cannot construct instance of io.openlineage.spark.agent.client.HttpError (although at least one Creator exists): no String-argument constructor/factory method to deserialize from String value ('{"code":404,"message":"HTTP 404 Not Found"}')
at [Source: UNKNOWN; line: -1, column: -1], details=java.util.concurrent.CompletionException: java.lang.IllegalArgumentException: Cannot construct instance of io.openlineage.spark.agent.client.HttpError (although at least one Creator exists): no String-argument constructor/factory method to deserialize from String value ('{"code":404,"message":"HTTP 404 Not Found"}')
at [Source: UNKNOWN; line: -1, column: -1])
at io.openlineage.spark.agent.OpenLineageContext.emit(OpenLineageContext.java:48)
at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:122)
at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$onJobStart$3(OpenLineageSparkListener.java:159)
at java.util.Optional.ifPresent(Optional.java:159)
at io.openlineage.spark.agent.OpenLineageSparkListener.onJobStart(OpenLineageSparkListener.java:148)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:37)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:119)
at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:103)
at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1585)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
*Thread Reply:* Issue solved , mentioned the version wrongly as 1 instead v1

👋 Hi everyone!

Hello Everyone.. we are exploring Openlineage for capturing Spark lineage.. but form the GitHub(https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark) ..I see that the output send to API (Marquez).. how can I send it to Kafka topic.. can some body please guide me on this.

*Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/400/files
there’s ongoing PR for proxy backend, which opens http API and redirects events to Kafka.
*Thread Reply:* Hi Kavuri, as minkyu said, there's currently work going on to simplify this process.
For now, you'll need to make something to capture the HTTP api events and send them to the Kafka topic. Changing the spark.openlineage.url parameter will send the runEvents wherever you like, but obviously you can't directly produce HTTP events to a topic
*Thread Reply:* Many Thanks for the Reply.. As I understand, currently pushing lineage to kafka topic is not yet there. it is under implementation. If you can help me out in understanding in which version it is going to be present, that will help me a lot. Thanks in advance.
*Thread Reply:* Not sure about the release plan, but the http endpoint is just regular RESTful API, and you will be able to write a super simple proxy for your own use case if you want.
Hi, Open Lineage team - For the Spark Integration, I'm looking to extract information from a DataSourceV2 data source.
I'm working on the WRITE side of the data source and right now I'm touching the AppendData logical plan (I can't find the Java Doc): https://github.com/rdblue/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala#L446
I was able to extract out the table name (from the named relation) but I'm struggling getting out the schema next.
I noticed that the AppendData offers inputSet, schema, and outputSet. • inputSet gives me an AttributeSet which does contain the names of my columns (https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/AttributeSet.scala#L69) • schema returns an empty StructType • outputSet is an empty AttributeSet I thought I read in the Spark Internals book that outputSet would only be populated if there was some sort of change to the DataFrame columns but I cannot find that page and searching for spark outputSet turns up few relevant results.
Has anyone else worked with the AppendData plan and gotten the schema out of it? Am I going down the wrong path with this snippet of code below? Thank you for any guidance!
if (logical instanceof AppendData) {
AppendData appendOp = (AppendData) logical;
NamedRelation namedRel = appendOp.table();
<a href="http://log.info">log.info</a>(namedRel.name()); // Works great!
<a href="http://log.info">log.info</a>(appendOp.inputSet().toString());// This will get you a rough schema
StructType schema = appendOp.schema(); // This is an empty StructType
<a href="http://log.info">log.info</a>(schema.json()); // Nothing useful here
}
<a href="https://github.com/rdblue/spark">rdblue/spark</a>
<a href="https://github.com/apache/spark">apache/spark</a>
*Thread Reply:* One thing, you're looking at Ryan's fork of Spark, which is few thousand commits behind head 🙂
This one should be good: https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/v2Commands.scala#L72
About schema: looking at AppendData's query schema should work, if there's no change to columns, because to pass analysis, data being inserted have to match table's schema. I would test that though 🙂
On the other hand, current AppendDataVisitor just looks at AppendData's table and tries to extract dataset from it using list of common output visitors:
In this case, the DataSourceV2RelationVisitor would look at it, provided we're using Spark 3:
*Thread Reply:* In this case, we basically need more info about nature of this DataSourceV2Relation, because this is provider-dependent. We have Iceberg in main branch and Delta here: https://github.com/OpenLineage/OpenLineage/pull/393/files#diff-7b66a9bd5905f4ba42914b73a87d834c1321ebcf75137c1e2a2413c0d85d9db6
*Thread Reply:* Ah! Maciej! As always, thank you! Looking through the DataSourceV2RelationVisitor you provided, it looks like the connector (Azure Cosmos Db) doesn't provide that Provider property 😞 😞 😞
Is there any other method for determining the type of DataSourceV2Relation?
*Thread Reply:* And, to make sure I close out on my original question, it was as simple as the code that Maciej was using:
I merely needed to use DataSourceV2Realtion rather than NamedRelation!
DataSourceV2Relation relation = (DataSourceV2Relation)appendOp.table();
<a href="http://log.info">log.info</a>(relation.schema().toString());
<a href="http://log.info">log.info</a>(relation.name());
*Thread Reply:* Are we talking about this connector? https://github.com/Azure/azure-sdk-for-java/blob/934200f63dc5bc7d5502a95f8daeb8142[…]/src/main/scala/com/azure/cosmos/spark/ItemsReadOnlyTable.scala
<a href="https://github.com/Azure/azure-sdk-for-java">Azure/azure-sdk-for-java</a>
*Thread Reply:* I guess you can use object.getClass.getCanonicalName() to find if the passed class matches the one that Cosmos provider uses.
*Thread Reply:* Yes! That's the one, Maciej! I will give getCanonicalName a try but also make a PR into that repo to get the provider property set up correctly 🙂
*Thread Reply:* Glad to help 😄
*Thread Reply:* @Will Johnson could you tell on which commands from https://github.com/OpenLineage/OpenLineage/issues/368#issue-1038510649 you'll be working?
*Thread Reply:* If any, of course 🙂
*Thread Reply:* From all of our tests on that Cosmos connector, it looks like it strictly uses athe AppendData operation. However @Harish Sune is looking at more of these commands from a Delta data source.
*Thread Reply:* Just to close the loop on this one - I submitted a PR for the work we've been doing. Looking forward to any feedback! https://github.com/OpenLineage/OpenLineage/pull/450
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks @Will Johnson! I added one question about dataset naming.
Finally got this doc posted - https://github.com/OpenLineage/OpenLineage/pull/437 (see the readable version here ) Looking for feedback, @Willy Lulciuc @Maciej Obuchowski @Will Johnson
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Yes! This is awesome!! How might this work for an existing command like the DataSourceV2Visitor.
Right now, OpenLineage checks based on the provider property if it's an Iceberg or Delta provider.
Ideally, we'd be able to extend the list of providers or have a custom "CosmosDbDataSourceV2Visitor" that knew how to work with a custom DataSourceV2.
Would that cause any conflicts if the base class is already accounted for in OpenLineage?
*Thread Reply:* Resolving this would be nice addition to the doc (and, to the implementation) - currently, we're just returning result of first function for which isDefinedAt is satisfied.
This means, that we can depend on the order of the visitors...
*Thread Reply:* great question. For posterity, I'd like to move this to the PR discussion. I'll address the question there.
Oh, and I forgot to post yesterday OpenLineage 0.4.0 was released 🥳
This was a big one. • Split tests for Spark 2 and Spark 3 • Spark output metrics • Databricks support with init scripts • Initial Iceberg support for Spark • Initial Kafka support for Spark • dbt build support • forward compatibility for dbt versions • lots of bug fixes 🙂 Check the full changelog for details
Hi @Michael Collado is there any documentation on using great expectations with open lineage
*Thread Reply:* hmm, actually the only documentation we have right now is on the demo.datakin.com site https://demo.datakin.com/onboarding . The great expectations tab should be enough to get you started
*Thread Reply:* I'll open a ticket to copy that documentation to the OpenLineage site repo

Hello ! I am new on OpenLineage , awesome project !! ; anybody knows about integration with Deequ ? Or a way to capture dataset stats with openlineage ? Thanks ! Appreciate the help !
*Thread Reply:* Hi! We don't have any integration with deequ yet. We have a structure for recording data quality assertions and statistics, though - see https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/DataQualityAssertionsDatasetFacet.json and https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/DataQualityMetricsInputDatasetFacet.json for the specs.
Check the great expectations integration to see how those facets are being used

*Thread Reply:* This is great. Thanks @Michael Collado!

Hi,
I am testing Open Lineage/Marquez 0.4.0 with dbt 1.0.0 using dbt-ol build
It seems 12 events were generated but UI shows only history of runs with "Nothing to show here" in detail section about datasets/tests failures in dbt namespace.
The warehouse namespace shows lineage but no details about dataset/test failures .
Please advice.
02:57:54 Done. PASS=4 WARN=0 ERROR=3 SKIP=2 TOTAL=9 02:57:54 Error sending message, disabling tracking Emitting OpenLineage events: 100%|██████████████████████████████████████████████████████| 12/12 [00:00<00:00, 12.50it/s]
*Thread Reply:* This is nothing to show here when you click on test node, right? What about run node?
*Thread Reply:* There is no details about failure.
```dbt-ol build -t DEV --profile cdp --profiles-dir /c/Work/dbt/cdp100/profiles --project-dir /c/Work/dbt/cdp100 --select +riskrawmastersharedshareclass Running OpenLineage dbt wrapper version 0.4.0 This wrapper will send OpenLineage events at the end of dbt execution. 02:57:21 Running with dbt=1.0.0 02:57:23 [WARNING]: Configuration paths exist in your dbtproject.yml file which do not apply to any resources. There are 1 unused configuration paths:
- models.cdp.risk.raw.liquidity.shared
02:57:23 Found 158 models, 181 tests, 0 snapshots, 0 analyses, 574 macros, 0 operations, 2 seed files, 56 sources, 1 exposure, 0 metrics 02:57:23 02:57:35 Concurrency: 10 threads (target='DEV') 02:57:35 02:57:35 1 of 9 START test dbtexpectationssourceexpectcompoundcolumnstobeuniquebsesharedpbshareclassEDMPORTFOLIOIDSHARECLASSCODEanyvalueismissingDELETEDFLAGFalse [RUN] 02:57:37 1 of 9 PASS dbtexpectationssourceexpectcompoundcolumnstobeuniquebsesharedpbshareclassEDMPORTFOLIOIDSHARECLASSCODEanyvalueismissingDELETEDFLAGFalse [PASS in 2.67s] 02:57:37 2 of 9 START view model REPL.SHARECLASSDIM.................................... [RUN] 02:57:39 2 of 9 OK created view model REPL.SHARECLASSDIM............................... [SUCCESS 1 in 2.12s] 02:57:39 3 of 9 START test dbtexpectationsexpectcompoundcolumnstobeuniquerawreplpbsharedshareclassRISKPORTFOLIOIDSHARECLASSCODEanyvalueismissingDELETEDFLAGFalse [RUN] 02:57:43 3 of 9 PASS dbtexpectationsexpectcompoundcolumnstobeuniquerawreplpbsharedshareclassRISKPORTFOLIOIDSHARECLASSCODEanyvalueismissingDELETEDFLAGFalse [PASS in 3.42s] 02:57:43 4 of 9 START view model RAWRISKDEV.STG.SHARECLASSDIM........................ [RUN] 02:57:46 4 of 9 OK created view model RAWRISKDEV.STG.SHARECLASSDIM................... [SUCCESS 1 in 3.44s] 02:57:46 5 of 9 START view model RAWRISKDEV.MASTER.SHARECLASSDIM..................... [RUN] 02:57:46 6 of 9 START test relationshipsriskrawstgsharedshareclassRISKINSTRUMENTIDRISKINSTRUMENTIDrefriskrawstgsharedsecurity_ [RUN] 02:57:46 7 of 9 START test relationshipsriskrawstgsharedshareclassRISKPORTFOLIOIDRISKPORTFOLIOIDrefriskrawstgsharedportfolio_ [RUN] 02:57:51 5 of 9 ERROR creating view model RAWRISKDEV.MASTER.SHARECLASSDIM............ [ERROR in 4.31s] 02:57:51 8 of 9 SKIP test relationshipsriskrawmastersharedshareclassRISKINSTRUMENTIDRISKINSTRUMENTIDrefriskrawmastersharedsecurity_ [SKIP] 02:57:51 9 of 9 SKIP test relationshipsriskrawmastersharedshareclassRISKPORTFOLIOIDRISKPORTFOLIOIDrefriskrawmastersharedportfolio_ [SKIP] 02:57:52 7 of 9 FAIL 7282 relationshipsriskrawstgsharedshareclassRISKPORTFOLIOIDRISKPORTFOLIOIDrefriskrawstgsharedportfolio_ [FAIL 7282 in 5.41s] 02:57:54 6 of 9 FAIL 6520 relationshipsriskrawstgsharedshareclassRISKINSTRUMENTIDRISKINSTRUMENTIDrefriskrawstgsharedsecurity_ [FAIL 6520 in 7.23s] 02:57:54 02:57:54 Finished running 6 tests, 3 view models in 30.71s. 02:57:54 02:57:54 Completed with 3 errors and 0 warnings: 02:57:54 02:57:54 Database Error in model riskrawmastersharedshareclass (models/risk/raw/master/shared/riskrawmastersharedshareclass.sql) 02:57:54 002003 (42S02): SQL compilation error: 02:57:54 Object 'RAWRISKDEV.AUDIT.STGSHARECLASSDIMRELATIONSHIPRISKINSTRUMENTID' does not exist or not authorized. 02:57:54 compiled SQL at target/run/cdp/models/risk/raw/master/shared/riskrawmastersharedshareclass.sql 02:57:54 02:57:54 Failure in test relationshipsriskrawstgsharedshareclassRISKPORTFOLIOIDRISKPORTFOLIOIDrefriskrawstgsharedportfolio (models/risk/raw/stg/shared/riskrawstgsharedschema.yml) 02:57:54 Got 7282 results, configured to fail if != 0 02:57:54 02:57:54 compiled SQL at target/compiled/cdp/models/risk/raw/stg/shared/riskrawstgsharedschema.yml/relationshipsriskrawstgsha19e10fb324f7d0cccf2aab512683f693.sql 02:57:54 02:57:54 Failure in test relationshipsriskrawstgsharedshareclassRISKINSTRUMENTIDRISKINSTRUMENTID_refriskrawstgsharedsecurity_ (models/risk/raw/stg/shared/riskrawstgsharedschema.yml) 02:57:54 Got 6520 results, configured to fail if != 0 02:57:54 02:57:54 compiled SQL at target/compiled/cdp/models/risk/raw/stg/shared/riskrawstgsharedschema.yml/relationshipsriskrawstgsha_e3148a1627817f17f7f5a9eb841ef16f.sql 02:57:54 02:57:54 See test failures:
select ** from RAWRISKDEV.AUDIT.STGSHARECLASSDIMrelationship_RISKINSTRUMENT_ID
02:57:54 02:57:54 Done. PASS=4 WARN=0 ERROR=3 SKIP=2 TOTAL=9 02:57:54 Error sending message, disabling tracking Emitting OpenLineage events: 100%|██████████████████████████████████████████████████████| 12/12 [00:00<00:00, 12.50it/s]Emitted 14 openlineage events (dbt) linux@dblnbk152371:/c/Work/dbt/cdp$```
*Thread Reply:* I'm talking on clicking on non-test node in Marquez UI - the screenshots shared show you clicked on the one ending in test
*Thread Reply:* There are two types of failures: tests failed on stage model (relationships) and physical error in master model (no table with such name). The stage test node in Marquez does not show any indication of failures and dataset node indicates failure but without number of failed records or table name for persistent test storage. The failed master model shows in red but no details of failure. Master model tests were skipped because of model failure but UI reports "Complete".
*Thread Reply:* If I understood correctly, for model you would like OpenLineage to capture message error, like this one
22:52:07 Database Error in model customers (models/customers.sql)
22:52:07 Syntax error: Expected "(" or keyword SELECT or keyword WITH but got identifier "PLEASE_REMOVE" at [56:12]
22:52:07 compiled SQL at target/run/jaffle_shop/models/customers.sql
And for dbt test failures, to visualize better that error is happening, for example like that:
*Thread Reply:* We actually do the first one for Airflow and Spark, I've missed it for dbt 😞
Created issue to add it to spec in a generic way: https://github.com/OpenLineage/OpenLineage/issues/446
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Sounds great. Failed/Skipped Tests/Models could be color-coded as well. Thanks.

*Thread Reply:* Hey. If you're using Airflow 2, you should use LineageBackend method described here: https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow#airflow-21-experimental
*Thread Reply:* You don't need to do anything with DAG import then.
*Thread Reply:* Thanks!!!!! i'll try
The PR at https://github.com/OpenLineage/OpenLineage/pull/451 should be everything needed to complete the implementation for https://github.com/OpenLineage/OpenLineage/pull/437 . The PR is in draft mode, as I still need ~1 day to update the integration test expectations to match the refactoring (there are some new events, but from my cursory look, the old events still match expected contents). But I think it's in a state that can be reviewed before the tests are updated.
There are two other PRs that this one is based on - broken up for easier reviewing • https://github.com/OpenLineage/OpenLineage/pull/447 • https://github.com/OpenLineage/OpenLineage/pull/448
*Thread Reply:* @Will Johnson @Maciej Obuchowski FYI 👆

The next OpenLineage Technical Steering Committee meeting is Wednesday, January 12! Meetings are on the second Wednesday of each month from 9:00 to 10:00am PT. Join us on Zoom: https://us02web.zoom.us/j/81831865546?pwd=RTladlNpc0FTTDlFcWRkM2JyazM4Zz09 All are welcome. Agenda: • OpenLineage 0.4 and 0.5 releases • Egeria version 3.4 support for OpenLineage • Airflow TaskListener to simplify OpenLineage integration [Maciej] • Open Discussion Notes: https://tinyurl.com/openlineagetsc
Hello community,
We are able to post this datasource in marquez. But then the information about the facet with the datasource is not displayed in the UI.
We want to display the S3 location (URI) where this datasource is pointing to.
{
id: {
namespace: "<s3://hbi-dns-staging>",
name: "PCHG"
},
type: "DB_TABLE",
name: "PCHG",
physicalName: "PCHG",
createdAt: "2022-01-11T16:15:54.887Z",
updatedAt: "2022-01-11T16:56:04.093153Z",
namespace: "<s3://hbi-dns-staging>",
sourceName: "<s3://hbi-dns-staging>",
fields: [],
tags: [],
lastModifiedAt: null,
description: null,
currentVersion: "c565864d-1a66-4cff-a5d9-2e43175cbf88",
facets: {
dataSource: {
uri: "<s3://hbi-dns-staging/sql-runner/2022-01-11/PCHG.avro>",
name: "<s3://hbi-dns-staging>",
_producer: "<a href="http://ip-172-25-23-163.dir.prod.aws.hollandandbarrett.comeu-west-1.com/172.25.23.163">ip-172-25-23-163.dir.prod.aws.hollandandbarrett.comeu-west-1.com/172.25.23.163</a>",
_schemaURL: "<https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet>"
}
}
}
As you see there is no much info in openlineage UI
The OpenLineage TSC meeting is tomorrow! https://openlineage.slack.com/archives/C01CK9T7HKR/p1641587111000700
 }
}
any idea guys about the previous question?
*Thread Reply:* Just to be clear, were you able to get a datasource information from API but just now showing up in the UI? Or you weren’t able to get it from API too?
Hi everyone !! I am doing POC of OpenLineage with Airflow version 2.1, before that would like to know, if this version is supported by OpenLineage?

*Thread Reply:* It does generally work, but, there's a known limitation in that only successful task runs are reported to the lineage backend. This is planned to be fixed in Airflow 2.3.
Hello there, I’m using docker Airflow version 2.1.0 , below were the steps I performed but I encountered error, pls help:
- Inside
requirements.txtfile i addedopenlineage-airflow. Then ranpip install -r requirements.txt. - Added environmental variable using this command
export AIRFLOW__LINEAGE__BACKEND = openlineage.lineage_backend.OpenLineageBackend - Then configured HTTP Backend environment variables inside “airflow” folder:
export OPENLINEAGE_URL=<http://marquez:5000> - Ran Marquez using
./docker/up.sh& open web frontend UI and saw below error msg:
*Thread Reply:* hey, I'm aware of one small bug ( which will be fixed in the upcoming OpenLineage 0.5.0 ) which means you would also have to include google-cloud-bigquery in your requirements.txt. This is the bug: https://github.com/OpenLineage/OpenLineage/issues/438
*Thread Reply:* The other thing I think you should check is, did you def define the AIRFLOW__LINEAGE__BACKEND variable correctly? What you pasted above looks a little odd with the 2 = signs
*Thread Reply:* I'm looking a task log inside my own Airflow and I see msgs like:
INFO - Constructing openlineage client to send events to
*Thread Reply:* ^ i.e. I think checking the task logs you can see if it's at least attempting to send data
Just published OpenLineage 0.5.0 . Big items here are
• dbt-spark support
• New proxy message broker for forwarding OpenLineage messages to Kafka
• New extensibility API for Spark integration
Accompanying tweet thread on the latter two items here: https://twitter.com/PeladoCollado/status/1483607050953232385
*Thread Reply:* BTW, this was actually the 0.5.1 release. Because, pypi... 🤷♂️:skintone4:
*Thread Reply:* nice on the dbt-spark support 👍

HELLO everyone . I’ve been reading and watching talks about OpenLineage and Marquez . this solution is exactly what we been looking to lineage our etls . GREAT WORK . our etls based on postgres redshift and airflow. SO
I tried to implement the example respecting all the steps required. everything runs successfully (the two dags on airflow ) on host http://localhost:3000/ but nothing appeared on marquez ui . am i missing something ? .
I’am thinking about create a simple etl pandas to a pandas with some transformation . Like to have a poc to show it to my team . I REALLY NEED SOME HELP
*Thread Reply:* Are you using docker on mac with "Use Docker Compose V2" enabled?
We've just found yesterday that it somehow breaks our example...
*Thread Reply:* yes i just installed docker on mac
*Thread Reply:* and docker compose version 1.29.2
*Thread Reply:* What you can do is to uncheck this, do docker system prune -a and try again.
*Thread Reply:* done but i get this : Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
*Thread Reply:* Try to restart docker for mac
*Thread Reply:* yeah done . I will try to implement the example again and see thank you very much
*Thread Reply:* i dont why i getting this when i $ docker-compose up :
WARNING: The TAG variable is not set. Defaulting to a blank string. WARNING: The APIPORT variable is not set. Defaulting to a blank string. WARNING: The APIADMINPORT variable is not set. Defaulting to a blank string. WARNING: The WEBPORT variable is not set. Defaulting to a blank string. ERROR: The Compose file ‘./../docker-compose.yml’ is invalid because: services.api.ports contains an invalid type, it should be a number, or an object services.api.ports contains an invalid type, it should be a number, or an object services.web.ports contains an invalid type, it should be a number, or an object services.api.ports value [‘:’, ‘:’] has non-unique elements
*Thread Reply:* are you running it exactly like here, with respect to directories, etc?
https://github.com/MarquezProject/marquez/tree/main/examples/airflow
*Thread Reply:* yeah yeah my bad . every things work fine know . I see the graph in the ui
*Thread Reply:* one more question plz . As i said our etls based on postgres redshift and airflow . any advice you have for us to integrate OL to our pipeline ?

I’m upgrading our OL Java client from an older version (0.2.3) and noticed that the ol.newCustomFacetBuilder() method to create custom facets no longer exists. I can see in this code diff that it might be replaced by simply adding to the additional properties of the standard element you are extending.
Can you please let me know if I’m understanding this change correctly? In other words, is the code in the diff functionally equivalent or is there a large change I should be understanding better?
*Thread Reply:* Hi Kevin - to my understanding that's correct. Do you guys have a custom extractor using this?
*Thread Reply:* Thanks John! We have custom code emitting OL events within our ingestion pipeline and it includes a custom facet. I’ll refactor the code to the new format and should be good to go.
*Thread Reply:* Just to follow up, this code update worked as expected and we are all good on the upgrade.
I’m not sure what went wrong, with Airflow docker, version 2.1.0 , below were the steps I performed but Marquez UI is showing no jobs, pls help:
requirements.txti addedopenlineage-airflow==0.5.1. Then ranpip install -r requirements.txt.- Added environmental variable inside my airflow docker folder using this command:
export AIRFLOW__LINEAGE__BACKEND = openlineage.lineage_backend.OpenLineageBackend - Then configured HTTP Backend environment variables inside same airflow docker folder:
export OPENLINEAGE_URL=<http://localhost:5000> - Ran Marquez using
./docker/up.shwhich is in another folder, Front end UI is not showing any job, its empty: - Attached in the airflow DAG log.
*Thread Reply:* Hm, that is odd. Usually there are a few lines in the DAG log from the OpenLineage bits. I’d expect to see something about not having an extractor for the operator you are using.
*Thread Reply:* If you open a shell in your Airflow Scheduler container and check for the presence of AIRFLOW__LINEAGE__BACKEND is it properly set? Possible the env isn’t making it all the way there.

Hi All,
I am working on a POC of OpenLineage-Airflow integration and was attempting to get it configured with Amundsen (also working on a POC). Reading through the tutorial here https://openlineage.io/integration/apache-airflow/, under the Prerequisites section it says:
To use the OpenLineage Airflow integration, you'll need a running Airflow instance. You'll also need an OpenLineage compatible HTTP backend.
The example uses Marquez, but I was trying to figure out how to get it to send metadata to the Amundsen graph db backend. Does the Airflow integration only support configuration with an HTTP compatible backend?
*Thread Reply:* Hi Lena! That’s correct, Openlineage is designed to send events to an HTTP backend. There’s a ticket on the future section of the roadmap to support pushing to Amundsen, but it’s not yet been worked on (Ref: Roadmap Issue #86)
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

hi , i am completely new to openlineage and marquez, i have to integrate openlineage to my existing java project but i am completely confused on where to start, i have gone through documentation and all but i am not able to understand how to integrate openlineage using marquez http backend in my existing project. please someone help me. I may sound naive here but i am in dire need of help.
*Thread Reply:* what do you mean by “Integrate Openlineage”?
Can you give a little more information on what you’re trying to accomplish and what the existing project is?
*Thread Reply:* I work in a datalake team and we are trying to implement data lineage property in our project using openlineage. our project basically keeps track of datasets coming from different sources(hive, redshift, elasticsearch etc.) and jobs.
*Thread Reply:* Gotcha!
Broadly speaking, all an integration needs to do is to send runEvents to Marquez.
I'd start by understanding the OpenLineage data model, and then looking at your system to identify when / where runEvents should be sent from, and what information needs to be included.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

*Thread Reply:* I suppose OpenLineage itself only defines the standard/protocol to design your data model. To be able to visualize/trace the lineage, you either have to implement your self with the standard data models or including Marquez in your project. You would need to use HTTP API to send lineage events from your Java project to Marquez in this case.
*Thread Reply:* Exactly! This project also includes connectors for more common data tools (Airflow, dbt, spark, etc), but at it's core OpenLineage is a standard and protocol
The next OpenLineage Technical Steering Committee meeting is Wednesday, February 9. Meetings are on the second Wednesday of each month from 9:00 to 10:00am PT. Join us on Zoom: https://us02web.zoom.us/j/81831865546?pwd=RTladlNpc0FTTDlFcWRkM2JyazM4Zz09 All are welcome. Agenda items are always welcome, as well. Reply in thread with yours. Current agenda: • OpenLineage 0.5.1 release • Apache Flink effort • Dagster integration • Open Discussion Notes: https://tinyurl.com/openlineagetsc


Hi everybody! Very cool initiative, thank you! Is there any traction on Apache Atlas integration? Is there some way to help you there?
*Thread Reply:* Hey Albert! There aren't yet any issues or proposals around Apache Atlas yet, but that's definitely something you can help with!
I'm not super familiar with Atlas, were you thinking in terms of enabling Atlas to receive runEvents from OpenLineage connectors?
*Thread Reply:* Hi John! Yes, exactly, it’d be nice to see Atlas as a receiver side of the OpenLineage events. Is there some guidelines on how to implement it? I guess we need OpenLineage-compatible server implementation so we could receive events and send them to Atlas, right?
*Thread Reply:* exactly - This would be a change on the Atlas side. I’d start by opening an issue in the atlas repo about making an API endpoint that can receive OpenLineage events. Marquez is our reference implementation of OpenLineage, so I’d look around in that repo to see how it’s been implemented :)
*Thread Reply:* Got it, thanks! Did that: https://issues.apache.org/jira/browse/ATLAS-4550 If it’d not get any traction we at New Work might contribute as well
*Thread Reply:* awesome! if you guys have any questions, reach out and I can get you in touch with some of the engineers on our end
*Thread Reply:* @Albert Bikeev one minor thing that could be helpful: java OpenLineage library contains server model classes: https://github.com/OpenLineage/OpenLineage/pull/300#issuecomment-923489097
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

*Thread Reply:* This is a quite old discussion, but isn't possible to use openlineage proxy to send json to kafka topic and let Atlas read that json without any modification? It would be needed to create a new model for spark, other than https://github.com/apache/atlas/blob/release-2.1.0-rc3/addons/models/1000-Hadoop/1100-spark_model.json and upload it to atlas (what could be done with a call to the atlas Api) Does it makes sense?
<a href="https://github.com/apache/atlas">apache/atlas</a>
*Thread Reply:* @Juan Carlos Fernández Rodríguez - You still need to build a bridge between the OpenLineage Spec and the Apache Atlas entity JSON. So far, no one has contributed something like that to the open source community... yet!
*Thread Reply:* sorry for the ignorance, But what is the purpose of the bridge?the comunicación with atlas should be done throw kafka, and that messages can be sent by the proxy. What are I missing?
*Thread Reply:* "bridge" in this case refers to a service of some sort that converts from OpenLineage run event to Atlas entity JSON, since there's currently nothing that will do that

*Thread Reply:* If OpenLineage send an event to kafka, I think we can use kafka stream or kafka connect to rebuild message to atlas event.
*Thread Reply:* @John Thomas Our company used to use atlas as a metadata service. I just came into know this project. After I learned how openlineage works, I think I can create an issue to describe my design first.
*Thread Reply:* @Juan Carlos Fernández Rodríguez If you already have some experience and design, can you directly create an issue so that we can discuss it in more detail ?
*Thread Reply:* Hi @xiang chen we are discussing internally in my company if rewrite to atlas or another alternative. If we do this, we will share and could involve you in some way.
Who here is working with OpenLineage at Dagster or Flink? We would love to hear about your work at the next

Hi everyone, OpenLineage is wonderful, we really needed something like this! Has anyone else used it with Databricks, Delta tables or Spark? If someone is interested into these technologies we can work together to get a POC and share some thoughts. Thanks and have a nice weekend! :)

*Thread Reply:* Hi Luca, I agree this looks really promising. I’m working on getting it to run on Databricks, but I’m only just starting out 🙂
Friendly reminder: this month’s OpenLineage TSC meeting is tomorrow! https://openlineage.slack.com/archives/C01CK9T7HKR/p1643849713216459
 }
}
Hi people, One question regarding error reporting - what is the mechanism for that? E.g. if I send duplicated job to Openlineage, is there a way to notify me about that?
*Thread Reply:* By duplicated, you mean with the same runId?
*Thread Reply:* It’s only one example, could be also duplicated job name or anything else. The question is if there is mechanism to report that
Reducing the Logging of Spark Integration
Hey, OpenLineage community! I'm curious if there are any quick tricks / fixes to reduce the amount of logging happening in the OpenLineage Spark Integration. Each job seems to print out the Logical Plan with INFO level logging. The default behavior of Databricks is to print out INFO level logs and so it gets pretty cluttered and noisy.
I'm hoping there's a feature flag that would help me shut off those kind of logs in OpenLineage's Spark integration 🤞
*Thread Reply:* I think this log should be dropped to debug: https://github.com/OpenLineage/OpenLineage/blob/d66c41872f3cc7f7cd5c99664d401e070e[…]c/main/common/java/io/openlineage/spark/agent/EventEmitter.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Maciej Obuchowski that is a good one! It would be nice to still have SOME logging in info to know that the event complete successfully but that response and event is very verbose.
I was also thinking about here: https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/src/main/common/java/io/openlineage/spark/agent/lifecycle/OpenLineageRunEventBuilder.java#L337-L340
These spots are where it's printing out the full logical plan for some reason.
Can I just open up a PR and switch these to log.debug instead?
*Thread Reply:* Yes, that would be good solution for now. Later would be nice to have some option to raise the log level - OL logs are absolutely drowning in logs from rest of Spark cluster when set to debug.
[SPARK][INTEGRATION] Need Brainstorming Ideas - How to Persist / Access Spark Configs in JobEnd
Hey, OL community! I'm working on PR#490 and I finally have all tests passing but now my desired behavior - display environment properties during COMPLETE / JobEnd events - is not happening 😭
The previous approach stored the spark properties in the OpenLineageContext with a properties attribute but that was part of all of the test failures I believe.
What are some other ways to store the jobStart's properties and make them accessible to the corresponding jobEnd? Hopefully it's okay to tag @Maciej Obuchowski, @Michael Collado, and @Paweł Leszczyński who have been extremely helpful in the past and brought great ideas to the table.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hey, I responded on the issue, but just to make it clear for everyone, the OL events for a run are not expected to be an accumulation of all past events. Events should be treated as additive by the backend - each event can post what information it has about the run and the backend is responsible for constructing a holistic picture of the run
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* e.g., here is the marquez code that fetches the facets for a run. Note that all of the facets are included from all events with the requested run_uuid. If the env facet is present on any event, it will be returned by the API
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Ah! Thanks for that @Michael Collado it's good to understand the OpenLineage perspective.
So, we do need to maintain some state. That makes total sense, Mike.
How does Marquez handle failed jobs currently? Based on this issue (https://github.com/OpenLineage/OpenLineage/issues/436) I think Marquez would show a START but no COMPLETE event, right?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* If I were building the backend, I would store events, then calculate the end state later, rather than trying to "maintain some state" (maybe we mean the same thing, but using different words here 😀).
Re: the failure events, I think job failures will currently result in one FAIL event and one COMPLETE event. The SparkListenerJobEnd event will trigger a FAIL event but the SparkListenerSQLExecutionEnd event will trigger the COMPLETE event.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Oooh! I did not know we already could get a FAIL event! That is super helpful to know, Mike! Thank you so much!
[SPARK] Connecting SparkListenerSQLExecutionStart to the various SparkListenerJobStarts
TL;DR: How can I connect the SparkListenerSQLExecutionStart to the SparkListenerJobStart events coming out of OpenLineage? The events appear to have two separate run ids and no link to indicate that the ExecutionStart event owns the subsequent JobStart events.
More Context:
Recently, I implemented a connector for Azure Synapse (data warehouse on the Microsoft cloud) for the Spark integration and now with https://github.com/OpenLineage/OpenLineage/pull/490, I realize now that the SparkListenerSQLExecutionStart events carries with it the necessary inputs and outputs to tell the "real" lineage. The way the Synapse in Databricks works is:
• SparkListenerSQLExecutionStart fires off an event with the end to end input and output (e.g. S3 as input and SQL table as output) • SparkListenerJobStart events fire off that move content from one S3 location to a "staging" location controlled by Azure Synapse. OpenLineage records this event with INPUT S3 and output is a WASB "tempfolder" (which is a temporary locatio and not really useful for lineage since it will be destroyed at the end of the job) • The final operation actually happens ALL in Synapse and OpenLineage does not fire off an event it seems. The Synapse database has a "COPY" command which moves the data from "tempfolder" in to the database. • Finally a SparkListenerSQLExecutionEnd event happens and the query is complete. Ideally, I could connect the SQLExecutionStart of SQLExecutionEnd with the SparkListenerJobStart so that I can get the JobStart properties. I see that ExecutionStart has an execution id and JobStart should have the same Execution Id BUT I think by the time I reach the ExecutionEND, all the JobStart events would have been removed from the HashMap that contains all of the events in OpenLineage.
Any guidance on how to reach a JobStart properties from an ExecutionStart or ExecutionEnd would be greatly appreciated!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think this scenario only happens when spark job spawns another "sub-job", right?
I think that maybe you can check sparkContext.getLocalProperty("spark.sql.execution.id")
> I see that ExecutionStart has an execution id and JobStart should have the same Execution Id BUT I think by the time I reach the ExecutionEND, all the JobStart events would have been removed from the HashMap that contains all of the events in OpenLineage. But pairwise, those starts and ends should at least have the same runId as they were created with same OpenLineageContext, right?
Anyway, what @Michael Collado wrote on the issue is true: https://github.com/OpenLineage/OpenLineage/pull/490#issuecomment-1042011803 - you should not assume that we hold all the metadata somewhere in memory during whole execution of the run. The backend should be able to take care of it.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Maciej Obuchowski - I was hoping they'd have the same run id as well but they do not 😞
But that is the expectation? A SparkSQLExecutionStart and JobStart SHOULD have the same execution ID, right?
I will take a look at sparkContext.getLocalProperty. Thank you so much for the reply Maciej!
*Thread Reply:* SparkSQLExecutionStart and SparkSQLExecutionEnd should have the same runId, as well as JobStart and JobEnd events. Beyond those it can get wild. For example, some jobs don't emit JobStart/JobEnd events. Some jobs, like Delta emit multiple, that aren't easily tied to SQL event.
*Thread Reply:* Okay, I dug into the Databricks Synapse Connector and it does the following:
- SparkSQLExecutionStart with execution id of 8 happens (so gets runid of abc123). It contains the real inputs and outputs that we want.
- The Synapse connector starts executing JDBC commands. These commands prepare the synapse database to connect with data that Spark will land in a staging area in the cloud. (I don't know how it' executing arbitrary commands before the official job start begins 😞 )
- SparkJobStart beings with execution id of 9 happens (so it gets runid of jkl456). This contains the inputs and an output to a temp folder (NOT the real output we want but a staging location) a. There are four JobIds 0 - 3, all of which point back to execution id 9 with the same physical plan. b. After job1, it runs more JDBC commands. c. I think at Job2, it runs the actual Spark code to query and join my raw input data and land it in a cloud storage account "tempfolder"/ d. After job3, it runs the final JDBC commands to actually move the data from "tempfolder/" to Synapse Db.
- Finally, the SparkSQLListenerEnd event occurs. I can see this in the Spark UI as well.
Because the Databricks Synapse connector somehow adds these additional JobStarts WITHOUT referencing the original SparkSQLExeuctionStart execution ID, we have to rely on heuristics to connect the /tempfolder to the real downstream table that was already provided in the ExecutionStart event 😞
I've attached the logs and a screenshot of what I'm seeing the Spark UI. If you had a chance to take a look, it's a bit verbose but I'd appreciate a second pair of eyes on my analysis. Hopefully I got something wrong 😅
*Thread Reply:* I think we've encountered the same stuff in Delta before 🙂
https://github.com/OpenLineage/OpenLineage/issues/388#issuecomment-964401860
*Thread Reply:* @Will Johnson , am I reading your report correctly that the SparkListenerJobStart event is reported with a spark.sql.execution.id that differs from the execution id of the SparkSQLExecutionStart?
*Thread Reply:* WILLJ: We're deep inside this thing and have an executionid |9|
😂
*Thread Reply:* Hah @Michael Collado I see you found my method of debugging in Databricks 😅
But you're exactly right, there's a SparkSQLExecutionStart event with execution id 8 and then a set of JobStart events all with execution id 9!
I don't know enough about Spark internals on how you can just run arbitrary Scala code while making it look like a Spark Job but that's what it looks like. As if the SqlDwWriter somehow submits a new job without a ExecutionStart... maybe it's an RDD operation instead? This has given me another idea to add some more log.info statements to my jar 😅😬
One of our own will be talking OpenLineage, Airflow and Spark at the Subsurface Conference this week. Register to attend @Michael Collado’s session on March 3rd at 11:45. You can register and learn more here: https://www.dremio.com/subsurface/live/winter2022/

*Thread Reply:* You won’t want to miss this talk!
I have a question about DataHub integration through OpenLineage standard. Is anyone working on it, or was it rather just an icon used in previous materials? We have build a openlineage API endpoint in our product and we were hoping OL will gain enough traction so it will be a native way to connect to variaty of data discovery/observability tools, such as datahub, amundzen, etc.
Many thanks!
*Thread Reply:* hi Martin - when you talk about a DataHub integration, did you mean a method to collect information from DataHub? I don't see a current issue open for that, but I recommend you make one and to kick off the discussion around it.
If you mean sending information to DataHub, that should already be possible if users pass a datahub api endpoint to the OPENLINEAGE_ENDPOINT variable
*Thread Reply:* Hi, thanks for a reply! I meant to emit Openlineage JSON structure to datahub.
Could you be please more specific, possibly link an article how to find the endpoint on the datahub side? Many thanks!
*Thread Reply:* ooooh, sorry I misread - I thought you meant that datahub had built an endpoint. Your integration should emit openlineage events to an endpoint, but datahub would have to build that support into their product likely? I'm not sure how to go about it
*Thread Reply:* I'd reach out to datahub, potentially?
*Thread Reply:* It has been discussed in the past but I don’t think there is something yet. The Kafka transport PR that is in flight should facilitate this
*Thread Reply:* Thanks for the response! though dragging Kafka in just for data delivery bit is too much. I think the clearest way would be to push Datahub to make an API endpoint and parser for OL /lineage data structure.
I see this is more political think that would require join effort of DataHub team and OpenLineage with a common goal.
The next OpenLineage Technical Steering Committee meeting is Wednesday, March 9! Meetings are on the second Wednesday of each month from 9:00 to 10:00am PT. Join us on Zoom: https://us02web.zoom.us/j/81831865546?pwd=RTladlNpc0FTTDlFcWRkM2JyazM4Zz09 All are welcome. Agenda: • New committers • Release overview (0.6.0) • New process for blog posts • Retrospective: Spark integration Notes: https://tinyurl.com/openlineagetsc
FYI, there's a talk on OpenLineage at Subsurface live tomorrow - https://www.dremio.com/subsurface/live/winter2022/session/cross-platform-data-lineage-with-openlineage/

@channel The latest release (0.6.0) of OpenLineage is now available, featuring a new Dagster integration, updates to the Airflow and Java integrations, a generic facet for env properties, bug fixes, and more. For more info, visit https://github.com/OpenLineage/OpenLineage/releases/tag/0.6.0

Hello Guys,
Where do I find an example of building a custom extractor? We have several custom airflow operators that I need to integrate
*Thread Reply:* Hi marco - we don't have documentation on that yet, but the Postgres extractor is a pretty good example of how they're implemented.
all the included extractors are here: https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow/openlineage/airflow/extractors
*Thread Reply:* Thanks. I can follow that to build my own. Also I am installing this environment right now in Airflow 2. It seems I need Marquez and openlinegae-aiflow library. It seems that by this example I can put my extractors in any path as long as it is referenced in the environment variable. Is that correct?
OPENLINEAGE_EXTRACTOR_<operator>=full.path.to.ExtractorClass
Also do I need anything else other than Marquez and openlineage_airflow?
*Thread Reply:* Yes, as long as the extractors are in the python path.
*Thread Reply:* I built one a little while ago for a custom operator, I'd be happy to share what I did. I put it in the same file as the operator class for convenience.
*Thread Reply:* to make it work, I set this environment variable:
OPENLINEAGE_EXTRACTOR_HttpToBigQueryOperator=http_to_bigquery.HttpToBigQueryExtractor
*Thread Reply:* the extractor starts at line 183, and the really important bits start at line 218
@channel At the next OpenLineage TSC meeting, we’ll be reminiscing about the Spark integration. If you’ve had a hand in OL support for Spark, please join and share! The meeting will start at 9 am PT on Wednesday this week. @Maciej Obuchowski @Oleksandr Dvornik @Willy Lulciuc @Michael Collado https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
Would Marquez create some lineage for operators that don't have a custom extractor built yet?
*Thread Reply:* You would see that job was run - but we couldn't extract dataset lineage from it.
*Thread Reply:* The good news is that we're working to solve this problem in general.
*Thread Reply:* I see, so i definitively will need the custom extractor built. I just need to understand where to set the path to the extractor. I can build one by following the postgress extractor you have built.
*Thread Reply:* That depends how you deploy Airflow. Our tests use environment in docker-compose: https://github.com/OpenLineage/OpenLineage/blob/main/integration/airflow/tests/integration/tests/docker-compose-2.yml#L34
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks for the example. I can show this to my infra support person for his reference.
This month’s OpenLineage TSC community meeting is tomorrow at 9am PT! It’s not too late to add an item to the agenda. Reply here or msg me with yours. https://openlineage.slack.com/archives/C01CK9T7HKR/p1646234698326859
I am running the last command to install marquez in AWS
helm upgrade --install marquez .
--set marquez.db.host <AWS-RDS-HOST>
--set marquez.db.user <AWS-RDS-USERNAME>
--set marquez.db.password <AWS-RDS-PASSWORD>
--namespace marquez
--atomic
--wait
And I am receiving this error
Error: query: failed to query with labels: secrets is forbidden: User "xxx@xxx.xx" cannot list resource "secrets" in API group "" in the namespace "default"
*Thread Reply:* Do you need to specify a namespace that is not « default »?
Can anyone let me know what is happening? My DI guy said it is a chart issue
*Thread Reply:* @Kevin Mellott aren't you the chart wizard? Maybe you could help 🙂
*Thread Reply:* Ok so I had to update a chart dependency
*Thread Reply:* Now I installed the service in amazon using this
helm install marquez . --dependency-update --set marquez.db.host=myhost --set marquez.db.user=myuser --set marquez.db.password=mypassword --namespace marquez --atomic --wait
*Thread Reply:* i can see marquez-web running and marquez as well as the database i set up manually
*Thread Reply:* 👋 @Marco Diaz happy to hear that the Helm install is completing without error! To help troubleshoot the error above, can you please let me know if this endpoint is available and working?
*Thread Reply:* i got this
{"namespaces":[{"name":"default","createdAt":"2022_03_10T18:05:55.780593Z","updatedAt":"2022-03-10T19:03:31.309713Z","ownerName":"anonymous","description":"The default global namespace for dataset, job, and run metadata not belonging to a user-specified namespace."}]}
*Thread Reply:* i have to use the namespace marquez to redirect there
kubectl port-forward svc/marquez 5000:80 -n marquez
*Thread Reply:* is there something i need to change in a config file?
*Thread Reply:* also how would i change the "localhost" address to something that is accessible in amazon without the need to redirect?
*Thread Reply:* Sorry for all the questions. I am not an infra guy and have had to do all this by myself
*Thread Reply:* No problem at all, I think there are a couple of things at play here. With the local setup, it appears that the web is attempting to access the API on the wrong port number (3000 instead of 5000). I’ll create an issue for that one so that we can fix it.
As to the EKS installation (or any non-local install), this is where you would need to use what’s called an ingress controller to expose the services outside of the Kubernetes cluster. There are different flavors of these (NGINX is popular), and I believe that AWS EKS has some built-in capabilities that might help as well.
https://www.eksworkshop.com/beginner/130_exposing-service/ingress/

*Thread Reply:* If your goal is to deploy to AWS, then you would need to get the EKS ingress configured. It’s not a trivial task, but they do have a bit of a walkthrough at https://www.eksworkshop.com/beginner/130_exposing-service/.
However, if you are just seeking to explore Marquez and try things out, then I would highly recommend the “Open in Gitpod” functionality at https://github.com/MarquezProject/marquez#try-it. That will perform a full deployment for you in a temporary environment very quickly.
*Thread Reply:* Is there a better guide on how to install and setup Marquez in AWS? This guide is omitting many steps https://marquezproject.github.io/marquez/running-on-aws.html
We're trying to find best way to track upstream releases of projects we have integrations for, to support newer versions faster and with less bugs. If you have any opinions on this topic, please chime in here
@Kevin Mellott Hello Kevin I followed the tutorial you sent me and I have exposed my services. However I am still seeing the same errors (this comes from the api/namescape call)
{"namespaces":[{"name":"default","createdAt":"2022_03_10T18:05:55.780593Z","updatedAt":"2022-03-10T19:03:31.309713Z","ownerName":"anonymous","description":"The default global namespace for dataset, job, and run metadata not belonging to a user-specified namespace."}]}
Is there something i need to change in the chart? I do not have access to the default namespace in kubernetes only marquez namescpace
@Marco Diaz that is actually a good response! This is the JSON returned back by the API to show some of the default Marquez data created by the install. Is there another error you are experiencing?
*Thread Reply:* I still see this https://files.slack.com/files-pri/T01CWUYP5AR-F036JKN77EW/image.png
*Thread Reply:* I created my own database and changed the values for host, user and password inside the chart.yml
*Thread Reply:* Does it show that within the AWS deployment? It looks to show localhost in your screenshot.
*Thread Reply:* Or are you working through the local deploy right now?
*Thread Reply:* It shows the same using the exposed service
*Thread Reply:* i just didnt do another screenshot
*Thread Reply:* Could it be communication with the DB?
*Thread Reply:* What do you see if you view the network traffic within your web browser (right click -> Inspect -> Network). Specifically, wondering what the response code from the Marquez API URL looks like.
*Thread Reply:* i see this error
Error occured while trying to proxy to: <a href="http://xxxxxxxxxxxxxxxxxxxxxxxxx.us-east-1.elb.amazonaws.com/api/v1/namespaces">xxxxxxxxxxxxxxxxxxxxxxxxx.us-east-1.elb.amazonaws.com/api/v1/namespaces</a>
*Thread Reply:* it seems to be trying to use the same address to access the api endpoint
*Thread Reply:* however the api service is in a different endpoint
*Thread Reply:* The API resides here
<a href="http://Xxxxxxxxxxxxxxxxxxxxxx-2064419849.us-east-1.elb.amazonaws.com">Xxxxxxxxxxxxxxxxxxxxxx-2064419849.us-east-1.elb.amazonaws.com</a>
*Thread Reply:* The web service resides here
<a href="http://xxxxxxxxxxxxxxxxxxxxxxxxxxx-335729662.us-east-1.elb.amazonaws.com">xxxxxxxxxxxxxxxxxxxxxxxxxxx-335729662.us-east-1.elb.amazonaws.com</a>
*Thread Reply:* do they both need to be under the same LB?
*Thread Reply:* How would i do that is they install as separate services?
*Thread Reply:* You are correct, both the website and API are expecting to be exposed on the same ALB. This will give you a single URL that can reach your Kubernetes cluster, and then the ALB will allow you to configure Ingress rules to route the traffic based on the request.
Here is an example from one of the AWS repos - in the ingress resource you can see the single rule setup to point traffic to a given service.
<a href="https://github.com/kubernetes-sigs/aws-load-balancer-controller">kubernetes-sigs/aws-load-balancer-controller</a>
*Thread Reply:* Thanks for the help. Now I know what the issue is

👋 Hi everyone! Our company is looking to adopt data lineage tool, so i have few queries on open lineage, so 1. Is this completey free.
- What are tha database it supports?
*Thread Reply:* Hi! Yes, OpenLineage is free. It is an open source standard for collection, and it provides the agents that integrate with pipeline tools to capture lineage metadata. You also need a metadata server, and there is an open source one called Marquez that you can use.
*Thread Reply:* It supports the databases listed here: https://openlineage.io/integration
and when i run the ./docker/up.sh --seed i got the result from java code(sample example) But how to get the same thing in python example?
*Thread Reply:* Not sure I understand - are you looking for example code in Python that shows how to make OpenLineage calls?
*Thread Reply:* this is a good post for getting started with Marquez: https://openlineage.io/blog/explore-lineage-api/
*Thread Reply:* once you have run ./docker/up.sh, you should be able to run through that and see how the system runs
*Thread Reply:* There is a python client you can find here: https://github.com/OpenLineage/OpenLineage/tree/main/client/python

*Thread Reply:* Hey @Ross Turk, (and potentially @Maciej Obuchowski) - what are the plans for OL Python client? I'd like to use it, but without a pip package it's not really project-friendly.
Is there any work in that direction, is the current client code considered mature and just needs re-packaging, or is it just a thought sketch and some serious work is needed?
I'm trying to avoid re-inventing the wheel, so if there's already something in motion, I'd rather support than start (badly) from scratch?
*Thread Reply:* What do you mean without pip-package?
*Thread Reply:* https://pypi.org/project/openlineage-python/
*Thread Reply:* It's still developed, for example next release will have pluggable backends - like Kafka https://github.com/OpenLineage/OpenLineage/pull/530
*Thread Reply:* My apologies Maciej! In my defense - looking for "open lineage" on pypi doesn't show this in the first 20 results. Still, should have checked setup.py. My bad, and thank you for the pointer!
*Thread Reply:* We might need to add some keywords to setup.py - right now we have only "openlineage" there 😉
*Thread Reply:* My mistake was that I was expecting a separate repo for the clients. But now I'm playing around with the package and trying to figure out the OL concepts. Thank you for your contribution, it's much nicer to experiment from ipynb than curl 🙂
@Julien Le Dem and @Willy Lulciuc will be at Data Council Austin next week talking OpenLineage and Airflow https://www.datacouncil.ai/talks/data-lineage-with-apache-airflow-using-openlineage?hsLang=en
I couldn't figure out for the sample lineage flow (etldelivery7_days) when we ran the seed command after from which file its fetching data
*Thread Reply:* the seed data is being inserted by this command here: https://github.com/MarquezProject/marquez/blob/main/api/src/main/java/marquez/cli/SeedCommand.java
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Got it, but if i changed the code in this java file lets say i added another job here satisfying the syntax its not appearing in the lineage flow
I created the database and host manually and passed the parameters using helm --set
Do the database services need to be exposed too through the ALB?
*Thread Reply:* I’m not too familiar with the 504 error in ALB, but found a guide with troubleshooting steps. If this is an issue with connectivity to the Postgres database, then you should be able to see errors within the marquez pod in EKS (kubectl logs <marquez pod name>) to confirm.
I know that EKS needs to have connectivity established to the Postgres database, even in the case of RDS, so that could be the culprit.
*Thread Reply:* @Kevin Mellott This is the error I am seeing in the logs
[HPM] Proxy created: /api/v1 -> <http://localhost:5000/>
App listening on port 3000!
[HPM] Error occurred while trying to proxy request /api/v1/namespaces from <a href="http://marquez-interface-test.di.rbx.com">marquez-interface-test.di.rbx.com</a> to <http://localhost:5000/> (ECONNREFUSED) (<https://nodejs.org/api/errors.html#errors_common_system_errors>)
*Thread Reply:* It looks like the website is attempting to find the API on localhost. I believe this can be resolved by setting the following Helm chart value within your deployment.
marquez.hostname=marquez-interface-test.di.rbx.com
*Thread Reply:* assuming that is the DNS used by the website
*Thread Reply:* thanks, that did it. I have a question regarding the database
*Thread Reply:* I made my own database manually. Do the marquez tables should be created automatically when install marquez?
*Thread Reply:* Also could you put both the API and interface on the same port (3000)
*Thread Reply:* Seems I am still having the forwarding issue
[HPM] Proxy created: /api/v1 -> <http://marquez-interface-test.di.rbx.com:5000/>
App listening on port 3000!
[HPM] Error occurred while trying to proxy request /api/v1/namespaces from <a href="http://marquez-interface-test.di.rbx.com">marquez-interface-test.di.rbx.com</a> to <http://marquez-interface-test.di.rbx.com:5000/> (ECONNRESET) (<https://nodejs.org/api/errors.html#errors_common_system_errors>)
Guidance on How / When a Spark SQL Execution event Controls JobStart Events?
@Maciej Obuchowski and @Paweł Leszczyński and @Michael Collado I'd really appreciate your thoughts on how / when JobStart events are triggered for a given execution. I've ran into two situations now where a SQLExecutionStart event fires with execution id X and then JobStart events fire with execution id Y.
• Spark 2 Delta SaveIntoDataSourceCommand on Databricks - I see it has a SparkSQLExecutionStart event but only on Spark 3 does it have JobStart events with the SaveIntoDataSourceCommand and the same execution id. • Databricks Synapse Connector - A SparkSQLExecutionStart event occurs but then the job starts are different execution ids. Is there any guidance / books / videos that dive deeper into how these events are triggered?
We need the JobStart event with the same execution id so that we can get some environment properties stored in the job start event.
Thanks you so much for any guidance!
*Thread Reply:* It's always Delta, isn't it?
When I originally worked on Delta support I tried to find answer on Delta slack and got an answer:
Hi Maciej, the main reason is that Delta will run queries on metadata to figure out what files should be read for a particular version of a Delta table and that's why you might see multiple jobs. In general Delta treats metadata as data and leverages Spark to handle them to make it scalable.
*Thread Reply:* I haven't touched how it works in Spark 2 - wanted to make it work with Spark 3's new catalogs, so can't help you there.
*Thread Reply:* Argh!! It's always Databricks doing something 🙄
Thanks, Maciej!
*Thread Reply:* One last question for you, @Maciej Obuchowski, any thoughts on how I could identify WHY a particular JobStart event fired? Is it just stepping through every event? Was that your approach to getting Spark3 Delta working? Thank you so much for the insights!
*Thread Reply:* Before that, we were using just JobStart/JobEnd events and I couldn't find events that correspond to logical plan that has anything to do with what job was actually doing. I just found out that SQLExecution events have what I want, so I just started using them and stopped worrying about Projection or Aggregate, or other events that don't really matter here - and that's how filtering idea was born: https://github.com/OpenLineage/OpenLineage/issues/423
*Thread Reply:* Are you trying to get environment info from those events, or do you actually get Job event with proper logical plans like SaveIntoDataSourceCommand?
Might be worth to just post here all the events + logical plans that are generated for particular job, as I've done in that issue
*Thread Reply:* scala> spark.sql("CREATE TABLE tbl USING delta AS SELECT ** FROM tmp")
21/11/09 19:01:46 WARN SparkSQLExecutionContext: SparkListenerSQLExecutionStart - executionId: 3
21/11/09 19:01:46 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.CreateTableAsSelect
21/11/09 19:01:46 WARN SparkSQLExecutionContext: SparkListenerSQLExecutionStart - executionId: 4
21/11/09 19:01:46 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.LocalRelation
21/11/09 19:01:46 WARN SparkSQLExecutionContext: SparkListenerJobStart - executionId: 4
21/11/09 19:01:46 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.LocalRelation
21/11/09 19:01:47 WARN SparkSQLExecutionContext: SparkListenerJobEnd - executionId: 4
21/11/09 19:01:47 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.LocalRelation
21/11/09 19:01:47 WARN SparkSQLExecutionContext: SparkListenerSQLExecutionEnd - executionId: 4
21/11/09 19:01:47 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.LocalRelation
21/11/09 19:01:48 WARN SparkSQLExecutionContext: SparkListenerSQLExecutionStart - executionId: 5
21/11/09 19:01:48 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.Aggregate
21/11/09 19:01:48 WARN SparkSQLExecutionContext: SparkListenerJobStart - executionId: 5
21/11/09 19:01:48 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.Aggregate
21/11/09 19:01:49 WARN SparkSQLExecutionContext: SparkListenerJobEnd - executionId: 5
21/11/09 19:01:49 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.Aggregate
21/11/09 19:01:49 WARN SparkSQLExecutionContext: SparkListenerSQLExecutionEnd - executionId: 5
21/11/09 19:01:49 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.Aggregate
21/11/09 19:01:49 WARN SparkSQLExecutionContext: SparkListenerSQLExecutionEnd - executionId: 3
21/11/09 19:01:49 WARN SparkSQLExecutionContext: org.apache.spark.sql.catalyst.plans.logical.CreateTableAsSelect
*Thread Reply:* The JobStart event contains a Properties field and that contains a bunch of fields we want to extract to get more precise lineage information within Databricks.
As far as we know, the SQLExecutionStart event does not have any way to get these properties :(
As a result, I do have to care about the subsequent JobStart events coming from a given ExecutionStart 😢
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I started down this path with the Project statement but I agree with @Michael Collado that a ProjectVisitor isn't a great idea.
https://github.com/OpenLineage/OpenLineage/issues/617
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hey. I'm working on replacing current SQL parser - on which we rely for Postgres, Snowflake, Great Expectations - and I'd appreciate your opinion.
*Thread Reply:* Marquez and OpenLineage are job-focused lineage tools, so once you run a job in an OL-integrated instance of Airflow (or any other supported integration), you should see the jobs and DBs appear in the marquez ui
*Thread Reply:* If you want to seed it with some data, just to try it out, you can run docker/up.sh -s and it will run a seeding job as it starts.
Would datasets be created when I send data from airflow?
*Thread Reply:* Yep! Marquez will register all in/out datasets present in the OL event as well as link them to the run
*Thread Reply:* FYI, @Peter Hicks is working on displaying the dataset version to run relationship in the web UI, see https://github.com/MarquezProject/marquez/pull/1929
 <a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
How is Datakin used in conjunction with Openlineage and Marquez?
*Thread Reply:* Hi Marco,
Datakin is a reporting tool built on the Marquez API, and therefore designed to take in Lineage using the OpenLineage specification.
Did you have a more specific question?
*Thread Reply:* No, that is it. Got it. So, i can install Datakin and still use openlineage and marquez?
*Thread Reply:* if you set up a datakin account, you'll have to change the environment variables used by your OpenLineage integrations, and the runEvents will be sent to Datakin rather than Marquez. You shouldn't have any loss of functionality, and you also won't have to keep manually hosting Marquez
*Thread Reply:* Will I still be able to use facets for backfills?
*Thread Reply:* yeah it works in the same way - Datakin actually submodules the Marquez API
If I have marquez access via alb ingress what would i use the marquezurl variable or openlineageurl?
So, i don't need to modify my dags in Airflow 2 to use the library? Would this just allow me to start collecting data?
openlineage.lineage_backend.OpenLineageBackend
*Thread Reply:* Yes, you don't need to modify dags in Airflow 2.1+
*Thread Reply:* Also would a new namespace be created if i add the variable?

Hello! Are there any plans for openlineage to support dbt on trino?
*Thread Reply:* Hi Datafool - I'm not familiar with how trino works, but the DBT-OL integration works by wrapping the dbt run command with dtb-ol run , and capturing lineage data from the runresult file
These things don't necessarily preclude you from using OpenLineage on trino, so it may work already.
*Thread Reply:* hey @John Thomas yep, tried to use dbt-ol run command but it seems trino is not supported, only bigquery, redshift and few others.
*Thread Reply:* aaah I misunderstood what Trino is - yeah we don't currently support jobs that are running outside of those environments.
We don't currently have plans for this, but a great first step would be opening an issue in the OpenLineage repo.
If you're interested in implementing the support yourself I'm also happy to connect you to people that can help you get started.
*Thread Reply:* oh okay, got it, yes I can contribute, I'll see if I can get some time in the next few weeks. Thanks @John Thomas
I can see 2 articles using Spline with BMW and Capital One. Could OpenLineage be doing the same job as Spline here? What would the differences be? Are there any similar references for OpenLineage? I can see Northwestern Mutual but that article does not contain a lot of detail.


Could anyone help me wit this custom extractor. I am not sure what I am doing wrong. I added the variable to airflow2, but I still see this in the logs
[2022-03-31, 16:43:39 UTC] {__init__.py:97} WARNING - Unable to find an extractor. task_type=QueryOperator
Here is the code
```import logging from typing import Optional, List from openlineage.airflow.extractors.base import BaseExtractor,TaskMetadata from openlineage.client.facet import SqlJobFacet, ExternalQueryRunFacet from openlineage.common.sql import SqlMeta, SqlParser
logger = logging.getLogger(name)
class QueryOperatorExtractor(BaseExtractor):
def __init__(self, operator):
super().__init__(operator)
@classmethod
def get_operator_classnames(cls) -> List[str]:
return ['QueryOperator']
def extract(self) -> Optional[TaskMetadata]:
# (1) Parse sql statement to obtain input / output tables.
sql_meta: SqlMeta = SqlParser.parse(self.operator.hql)
inputs = sql_meta.in_tables
outputs = sql_meta.out_tables
task_name = f"{self.operator.dag_id}.{self.operator.task_id}"
run_facets = {}
job_facets = {
'hql': SqlJobFacet(self.operator.hql)
}
return TaskMetadata(
name=task_name,
inputs=[inputs.to_openlineage_dataset()],
outputs=[outputs.to_openlineage_dataset()],
run_facets=run_facets,
job_facets=job_facets
)```


@Ross Turk Could you please take a look if you have a minute☝️? I know you have built one extractor before
*Thread Reply:* Hmmmm. Are you running in Docker? Is it possible for you to shell into your scheduler container and make sure the ENV is properly set?
*Thread Reply:* looks to me like the value you posted is correct, and return ['QueryOperator'] seems right to me
*Thread Reply:* It is in an EKS cluster
I checked and the variable is there
OPENLINEAGE_EXTRACTOR_QUERYOPERATOR=shared.plugins.ol_custom_extractors.QueryOperatorExtractor
*Thread Reply:* I am wondering if it is an issue with my extractor code. Something not rendering well
*Thread Reply:* I don’t think it’s even executing your extractor code. The error message traces back to here: https://github.com/OpenLineage/OpenLineage/blob/249868fa9b97d218ee35c4a198bcdf231a9b874b/integration/airflow/openlineage/lineage_backend/__init__.py#L77
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I am currently digging into _get_extractor to see where it might be missing yours 🤔
*Thread Reply:* silly idea, but you could add a log message to __init__ in your extractor.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* the openlineage client actually tries to import the value of that env variable from pos 22. if that happens, but for some reason it fails to register the extractor, we can at least know that it’s importing
*Thread Reply:* if you add a log line, you can verify that your PYTHONPATH and env are correct
*Thread Reply:* @Marco Diaz can you try env variable OPENLINEAGE_EXTRACTOR_QueryOperator instead of full caps?
*Thread Reply:* @Maciej Obuchowski My setup does not allow me to submit environment variables with lowercases. Is the name of the variable used to register the extractor?
*Thread Reply:* yes, it's case sensitive...
*Thread Reply:* So it is definitively the name of the variable. I changed the name of the operator to capitals and now is being registered
*Thread Reply:* Could there be a way not to make this case sensitive?
*Thread Reply:* yes - could you create issue on OpenLineage repository?
I have another question. I have this query
INSERT OVERWRITE TABLE schema.daily_play_sessions_v2
PARTITION (ds = '2022-03-30')
SELECT
platform_id,
universe_id,
pii_userid,
NULL as session_id,
NULL as session_start_ts,
COUNT(1) AS session_cnt,
SUM(
UNIX_TIMESTAMP(stopped) - UNIX_TIMESTAMP(joined)
) AS time_spent_sec
FROM schema.fct_play_sessions_merged
WHERE ds = '2022-03-30'
AND UNIX_TIMESTAMP(stopped) - UNIX_TIMESTAMP(joined) BETWEEN 0 AND 28800
GROUP BY
platform_id,
universe_id,
pii_userid
And I am seeing the following inputs
[DbTableName(None,'schema','fct_play_sessions_merged','schema.fct_play_sessions_merged')]
But the outputs are empty
Shouldn't this be an output table
schema.daily_play_sessions_v2
*Thread Reply:* Yes, it should. This line is the likely culprit: https://github.com/OpenLineage/OpenLineage/blob/431251d25f03302991905df2dc24357823d9c9c3/integration/common/openlineage/common/sql/parser.py#L30
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I bet if that said ['INTO','OVERWRITE'] it would work
*Thread Reply:* @Maciej Obuchowski do you agree? should OVERWRITE be a token we look for? if so, I can submit a short PR.
*Thread Reply:* we have a better solution
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/644
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* ah! I heard there was a new SQL parser, but did not know it was imminent!
*Thread Reply:* I've added this case as a test and it works: https://github.com/OpenLineage/OpenLineage/blob/764dfdb885112cd0840ebc7384ff958bf20d4a70/integration/sql/tests/tests_insert.rs
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Do i have to download a new version of the opelineage-airflow python library
*Thread Reply:* this PR isn’t merged yet 😞 so if you wanted to try this you’d have to build the python client from the sql/rust-parser-impl branch
*Thread Reply:* ok, np. I am not in a hurry yet. Do you have an ETA for the merge?
*Thread Reply:* Hard to say, it’s currently in-review. Let me pull some strings, see if I can get eyes on it.
*Thread Reply:* I will check again next week don't worry. I still need to make some things in my extractor work
*Thread Reply:* after it’s merged, we’ll have to do an OpenLineage release as well - perhaps next week?

Hi everyone, I just started using openlineage to connect with DBT for my company. I work as data engineering. After the connection and run test on dbt-ol run, it gives me this error. I have looked up online to find the answer but couldn't see the answer anywhere. Can somebody please help me with? The error tells me that the correct version is DBT Schemajson version 2 instead of 3. I don't know where to change the schemajson version. Thank you everyone @channel
*Thread Reply:* Hm - what version of dbt are you using?
*Thread Reply:* @Tien Nguyen The dbt schema version changes with different versions of dbt. If you have recently updated, you may have to make some changes: https://docs.getdbt.com/docs/guides/migration-guide/upgrading-to-v1.0
*Thread Reply:* also make sure you are on the latest version of openlineage-dbt - I believe we have made it a bit more tolerant of dbt schema changes.
*Thread Reply:* @Ross Turk Thank you very much for your answer. I will update those and see if I can resolve the issues.
*Thread Reply:* @Ross Turk Thank you very much for your help. The latest version of dbt couldn't work. But version 0.20.0 works for this problem.
*Thread Reply:* Hmm. Interesting, I remember when dbt 1.0 came out we fixed a very similar issue: https://github.com/OpenLineage/OpenLineage/pull/397
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* if you run pip3 list | grep openlineage-dbt, what version does it show?
*Thread Reply:* I wonder if you have somehow ended up with an older version of the integration
*Thread Reply:* is it 0.1.0 the older version of openlineage ?
*Thread Reply:* ❯ pip3 list | grep openlineage-dbt
openlineage-dbt 0.6.2
*Thread Reply:* the latest is 0.6.2 - that might be your issue
*Thread Reply:* How are you going about installing it?
*Thread Reply:* @Ross Turk. I follow instruction from open lineage "pip3 install openlineage-dbt"
*Thread Reply:* Hm! Interesting. I did the same thing to get 0.6.2.
*Thread Reply:* @Ross Turk Yes. I have tried to reinstall and clear cache but it still install 0.1.0
*Thread Reply:* But thanks for the version. I reinstall 0.6.2 version by specify the version
@Ross Turk @Maciej Obuchowski FYI the sql parser also seems not to return any inputs or outpus for queries that have subqueries
Example
INSERT OVERWRITE TABLE mytable
PARTITION (ds = '2022-03-31')
SELECT
**
FROM
(SELECT ** FROM table2) a
INSERT OVERWRITE TABLE mytable
PARTITION (ds = '2022-03-31')
SELECT
**
FROM
(SELECT ** FROM table2
UNION
SELECT ** FROM table3
UNION ALL
SELECT ** FROM table4) a
*Thread Reply:* they'll work with new parser - added test for those
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* btw, thank you very much for notifying us about multiple bugs @Marco Diaz!
*Thread Reply:* @Maciej Obuchowski thank you for making sure these cases are taken into account. I am getting more familiar with the Open lineage code as i build my extractors. If I see anything else I will let you know. Any ETA on the new parser release date?
*Thread Reply:* it should be week-two, unless anything comes up
*Thread Reply:* I see. Keeping my fingers crossed this is the only thing delaying me right now.
Also what would happen if someone uses a CTE in the SQL? Is the parser taken those cases in consideration?
Agenda items are requested for the next OpenLineage Technical Steering Committee meeting on Wednesday, April 13. Please reply here or ping me with your items!
*Thread Reply:* I've mentioned it before but I want to talk a bit about new SQL parser
*Thread Reply:* Will the parser be released after the 13?
*Thread Reply:* @Michael Robinson added additional item to Agenda - client transports feature that we'll have in next release
*Thread Reply:* Thanks, Maciej

Hi Everyone,
I have come across OpenLineage at Data Council Austin, 2022 and am curious to try it out. I have reviewed the Getting Started section (https://openlineage.io/getting-started/) of OpenLineage docs but couldn't find clear reference documentation for using the API • Are there any swagger API docs or equivalent dedicated for OpenLineage API? There is some reference docs of Marquez API: https://marquezproject.github.io/marquez/openapi.html#tag/Lineage Secondly are there any means to use Open Lineage independent of Marquez? Any pointers would be appreciated.

*Thread Reply:* I had kind of the same question. I found https://marquezproject.github.io/marquez/openapi.html#tag/Lineage With some of the entries marked Deprecated, I am not sure how to proceed.
*Thread Reply:* Hey folks, are you looking for the OpenAPI specification found here?
*Thread Reply:* @Patrick Mol, Marquez's deprecated endpoints were the old methods for creating lineage (making jobs, dataset, and runs independently), they were deprecated because we moved over to using the OpenLineage spec for all lineage collection purposes.
The GET methods for jobs/datasets/etc are still functional

*Thread Reply:* Hey John,
Thanks for sharing the OpenAPI docs. Was wondering if there are any means to setup OpenLineage API that will receive events without a consumer like Marquez or is it essential to always pair with a consumer to receive the events?
*Thread Reply:* the OpenLineage integrations don’t have any way to recieve events, since they’re designed to send events to other apps - what were you expecting OpenLinege to do?
Marquez is our reference implementation of an OpenLineage consumer, but egeria also has a functional endpoint
*Thread Reply:* Hi @John Thomas, Would creation of Sources and Datasets have an equivalent in the OpenLineage specification ? Sofar I only see the Inputs and Outputs in the Run Event spec.
*Thread Reply:* Inputs and outputs in the OL spec are Datasets in the old MZ spec, so they're equivalent
Hey Guys,
The BaseExtractor is working fine with operators that are derived from Airflow BaseOperator. However for operators derived from LivyOperator the BaseExtractor does not seem to work. Is there a fix for this? We use livyoperator to run sparkjobs
*Thread Reply:* Hi Marco - it looks like LivyOperator itself does derive from BaseOperator, have you seen any other errors around this problem?
@Maciej Obuchowski might be more help here
*Thread Reply:* It is the operators that inherit from LivyOperator. It doesn't find the parameters like sql, connection etc
*Thread Reply:* My guess is that operators that inherit from other operators (not baseoperator) will have the same problem
*Thread Reply:* interesting! I'm not sure about that. I can look into it if I have time, but Maciej is definitely the person who would know the most.
*Thread Reply:* @Marco Diaz I wonder - perhaps it would be better to instrument spark with OpenLineage. It doesn’t seem that Airflow will know much about what’s happening underneath here. Have you looked into openlineage-spark?
*Thread Reply:* I have not tried that library yet. I need to see how it implement because we have several spark custom operators that use livy
*Thread Reply:* there is a good blog post from @Michael Collado: https://openlineage.io/blog/openlineage-spark/
*Thread Reply:* and the doc page here has a good overview: https://openlineage.io/integration/apache-spark/
*Thread Reply:* is this all we need to pass?
spark-submit --conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener" \
--packages "io.openlineage:openlineage_spark:0.2.+" \
--conf "spark.openlineage.host=http://<your_ol_endpoint>" \
--conf "spark.openlineage.namespace=my_job_namespace" \
--class com.mycompany.MySparkApp my_application.jar
*Thread Reply:* If so, yes our operators have a way to pass configurations to spark and we may be able to implement it.
*Thread Reply:* Do we have to install the library on the spark side or the airflow side?
*Thread Reply:* The —packages argument tells spark where to get the jar (you'll want to upgrade to 0.6.1)

Hi, I saw there was some work done for integrating OpenLineage with Azure Purview
*Thread Reply:* @Will Johnson
*Thread Reply:* Hey @Varun Singh! We are building a github repository that deploys a few resources that will support a limited number of Azure data sources being pushed into Azure Purview. You can expect a public release near the end of the month! Feel free to direct message me if you'd like more details!
The next OpenLineage Technical Steering Committee meeting is Wednesday, April 13! Meetings are on the second Wednesday of each month from 9:00 to 10:00am PT. Join us on Zoom: https://astronomer.zoom.us/j/87156607114?pwd=a3B0K210dnRaQmdkaFdGMytBREZEQT09 All are welcome. Agenda: • OpenLineage 0.6.2 release overview • Airflow integration update • Dagster integration retrospective • Open discussion Notes: https://tinyurl.com/openlineagetsc

*Thread Reply:* Are both airflow2 and Marquez installed locally on your computer?
*Thread Reply:* yes Marco
*Thread Reply:* can you open marquez on
<http://localhost:3000>
*Thread Reply:* and get a response from
<http://localhost:5000/api/v1/namespaces>
*Thread Reply:* yes , i used this guide https://openlineage.io/getting-started and execute un post to marquez correctly
*Thread Reply:* In theory you should receive events in jobs under airflow namespace
*Thread Reply:* It looks like you need to add a payment method to your DBT account

Hello. Does Airflow's TaskFlow API work with OpenLineage?
*Thread Reply:* It does, but admittedly not very well. It can't recognize what you're doing inside your tasks. The good news is that we're working on it and long term everything should work well.
*Thread Reply:* Thanks for the quick reply Maciej.

Hi all, watched few of your demos with airflow(astronomer) recently, really liked them. Thanks for doing those
Questions:
- Are there plans to have a hive listener similar to the open-lineage spark integration ?
- If not will the sql parser work with the HiveQL ?
- Maybe one for presto too ?
- Will the run version and dataset version come out of the box or do we need to define some facets ?
- I read the blog on facets, is there a tutorial on how to create a sample facet ? Background: We have hive, spark jobs and big query tasks running from airflow in GCP Dataproc
*Thread Reply:* Hi Sandeep,
1&3: We don't currently have Hive or Presto on the roadmap! The best way to start the conversation around them would be to create a proposal in the OpenLineage repo, outlining your thoughts on implementation and benefits.
2: I'm not familiar enough with HiveQL, but you can read about the new SQL parser we're implementing here
you can see the Standard Facets here - Dataset Version is included out of the box, but Run Version would have to be defined.
the best place to start looking into making facets is the Spec doc here. We don't have a dedicated tutorial, but if you have more specific questions please feel free to reach out again on slack
*Thread Reply:* Thank you John The standard facets links to the github issues currently
*Thread Reply:* ah here -https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md#standard-facets
Reminder: this month’s OpenLineage TSC meeting is tomorrow, 4/13, at 9 am PT! https://openlineage.slack.com/archives/C01CK9T7HKR/p1649271939878419
I setup the open-lineage spark integration for spark(dataproc) tasks from airflow. It’s able to post data to the marquez end point and I see the job information in Marquez UI.
I don’t see any dataset information in it, I see just the jobs ? Is there some setup I need to do or something else I need to configure ?
*Thread Reply:* is there anything in your marquez-api logs that might indicate issues?
What guide did you follow to setup the spark integration?
*Thread Reply:* Followed this guide https://openlineage.io/integration/apache-spark/ and used the spark-defaults.conf approach
*Thread Reply:* The logs from dataproc side show no errors, let me check from the marquez api side To confirm, we should be able to see the datasets from the marquez UI with the spark integration right ?
*Thread Reply:* I'm not super familiar with the spark integration, since I work more with airflow - I'd start with looking through the readme for the spark integration here
*Thread Reply:* Hmm, the readme says it aims to generate the input and output datasets
*Thread Reply:* Are you looking at the same namespace?
*Thread Reply:* Yes, the same one where I can see the job
*Thread Reply:* Tailing the API logs and rerunning the spark job now to hopefully catch errors if any, will ping back here
*Thread Reply:* Don’t see any failures in the logs, any suggestions on how to debug this ?
*Thread Reply:* I'd next set up a basic spark notebook and see if you can't get it to send dataset information on something simple in order to check if it's a setup issue or a problem with your spark job specifically
*Thread Reply:* ok, that sounds good, will try that
*Thread Reply:* before that, I see that spark-lineage integration posts lineage to the api https://marquezproject.github.io/marquez/openapi.html#tag/Lineage/paths/~1lineage/post We don’t seem to add a DataSet in this, does marquez internally create this “dataset” based on Output and fields ?
*Thread Reply:* yeah, you should be seeing "input" and "output" in the runEvents - that's where datasets come from
*Thread Reply:* I'm not sure if it's a problem with your specific spark job or with the integration itself, however
*Thread Reply:* By runEvents, do you mean a job Object or lineage Object ? The integration seems to be only POSTing lineage objects
*Thread Reply:* yep, a runEvent is body that gets POSTed to the /lineage endpoint:
https://openlineage.io/docs/openapi/
*Thread Reply:* > Yes, the same one where I can see the job I think you should look at other namespace, which name depends on what systems you're actually using
*Thread Reply:* Shouldn’t the dataset would be created in the same namespace we define in the spark properties?
*Thread Reply:* I found few datasets in the table location, I ran it in a similar (hive metastore, gcs, sparksql and scala spark jobs) setup to the one mentioned in this post https://openlineage.slack.com/archives/C01CK9T7HKR/p1649967405659519
 }
}
Is this the correct place for this Q or should I reach out to Marquez slack ? I followed this post https://openlineage.io/integration/apache-spark/
Before I create an issue around it, maybe I'm just not seeing it in Databricks. In the Spark Integration, does OpenLineage report Hive Metastore tables or it ONLY reports the file path?
For example, if I have a Hive table called default.myTable stored at LOCATION /usr/hive/warehouse/default/mytable.
For a query that reads a CSV file and inserts into default.myTable, would I see an output of default.myTable or /usr/hive/warehoues/default/mytable?
We want to include a link between the physical path and the hive metastore table but it seems that OpenLineage (at least on Databricks) only reports the physical path with the table name showing up in the catalog but not as a facet.
*Thread Reply:* This was my experience as well, I was under the impression we would see the table as a dataset. Looking forward to understanding the expected behavior
*Thread Reply:* relevant: https://github.com/OpenLineage/OpenLineage/issues/435
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Ah! Thank you both for confirming this! And it's great to see the proposal, Maciej!

*Thread Reply:* Is there a timeline around when we can expect this fix ?
*Thread Reply:* Not a simple fix, but I guess we'll start working on this relatively soon.
*Thread Reply:* I see, thanks for the update ! We are very much interested in this feature.
@channel A significant number of us have a conflict with the current TSC meeting day/time, so, unfortunately, we need to reschedule the meeting. When you have a moment, please share your availability here: https://doodle.com/meeting/participate/id/ejRnMlPe. Thanks in advance for your input!

*Thread Reply:* You probably need to change dataset from default
*Thread Reply:* I click it on everything 😕 I manually (joining to the pod and send curl to the marquez local endpoint) created a namespaces to check if there is a network issue I was ok, I created a namespaces called: data-dev . The airflow is mounted over k8s using helm chart.
``` config:
AIRFLOWWEBSERVERBASEURL: "http://airflow.dev.test.io"
PYTHONPATH: "/opt/airflow/dags/repo/config"
AIRFLOWAPIAUTHBACKEND: "airflow.api.auth.backend.basicauth"
AIRFLOWCOREPLUGINSFOLDER: "/opt/airflow/dags/repo/plugins"
AIRFLOWLINEAGEBACKEND: "openlineage.lineage_backend.OpenLineageBackend"
. . . .
extraEnv: - name: OPENLINEAGEURL value: http://marquez-dev.data-dev.svc.cluster.local - name: OPENLINEAGENAMESPACE value: data-dev```
*Thread Reply:* I think answer is somewhere in airflow logs 🙂 For some reason, OpenLineage events aren't send to Marquez.
One really novice question - there doesn't seem to be a way of deleting lineage elements (any of them)? While I can imagine that in production system we want to keep history, it's not practical while testing/developing. I'm using throw-away namespaces to step around the issue. Is there a better way, or alternatively - did I miss an API somewhere?
*Thread Reply:* That's more of a Marquez question 🙂 We have a long-standing issue to add that API https://github.com/MarquezProject/marquez/issues/1736
*Thread Reply:* I see it already got skipped for 2 releases, and my only conclusion is that people using Marquez don't make mistakes - ergo, API not needed 🙂 Lets see if I can stick around the project long enough to offer a bit of help, now I just need to showcase it and get interest in my org.

Good day all. I’m trying out the openlineage-dagster plugin
• I’ve got dagit, dagster-daemon and marquez running locally
• The openlineagesensor is recognized in dagit and the daemon.
But, when I run a job, I see the following message in the daemon’s shell:
Sensor openlineage_sensor skipped: Last cursor: {"last_storage_id": 9, "running_pipelines": {"97e2efdf-9499-4ffd-8528-d7fea5b9362c": {"running_steps": {}, "repository_name": "hello_cereal_repository"}}}
I’ve attached my repos.py and serialjob.py.
Any thoughts?

Hi All, I am walking through the curl examples on this page and have a question on the first curl example: https://openlineage.io/getting-started/ The curl command completes, and I can see the input file and job in the namespace, but the lineage graph does not show the input file connected as an input to the job. This only seems to happen after the job is marked complete.
Is there a way to have a running job show connections to its input files in the lineage? Thanks!

Hi Team, we are using spark as a service, and we are planning to integrate open lineage spark listener and looking at the below params that we need to pass, we don't know the name of the spark cluster, is the spark.openlineage.namespace conf param mandatory?
spark-submit --conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener" \
--packages "io.openlineage:openlineage_spark:0.2.+" \
--conf "spark.openlineage.host=http://<your_ol_endpoint>" \
--conf "spark.openlineage.namespace=my_job_namespace" \
--class com.mycompany.MySparkApp my_application.jar
*Thread Reply:* Namespace is defined by you, it does not have to be name of the spark cluster.
*Thread Reply:* And I definitely recommend to use newer version than 0.2.+ 🙂
*Thread Reply:* oh i see that someone mentioned that it has to be replaced with name of the spark clsuter
*Thread Reply:* https://openlineage.slack.com/archives/C01CK9T7HKR/p1634089656188400?thread_ts=1634085740.187700&cid=C01CK9T7HKR
*Thread Reply:* @Maciej Obuchowski may i know if i can add the --packages "io.openlineage:openlineage_spark:0.2.+" as part of the spark jar file, that meant as part of the pom.xml
*Thread Reply:* I think it needs to run on the driver
Hello,
when looking through Marquez API it seems that most individual-element creation APIs are marked as deprecated and are going to be removed by 0.25, with a point of switching to open lineage. That makes POST to /api/v1/lineage the only creation point of elements, but OpenLineage API is very limited in attributes that can be passed.
Is that intended to stay that way? One practical question/example: how do we create a job of type STREAMING, when OL API only allows to pass name, namespace and facets. Do we now move all properties into facets?
*Thread Reply:* > OpenLineage API is very limited in attributes that can be passed. Can you specify where do you think it's limited? The way to solve that problems would be to evolve OpenLineage.
> One practical question/example: how do we create a job of type STREAMING, So, here I think the question is more how streaming jobs differ from batch jobs. One obvious difference is that output of the job is continuous (in practice, probably "microbatched" or commited on checkpoint). However, deprecated Marquez API didn't give us tools to properly indicate that. On the contrary, OpenLineage with different event types allows us to properly do that. > Do we now move all properties into facets? Basically, yes. Marquez should handle specific facets. For example, https://github.com/MarquezProject/marquez/pull/1847
*Thread Reply:* Hey Maciej
first off - thanks for being active on the channel!
> So, here I think the question is more how streaming jobs differ from batch jobs
Not really. I just gave an example of how would you express a specific job type creation which can be done with https://marquezproject.github.io/marquez/openapi.html#tag/Jobs/paths/~1namespaces~1{namespace}~1jobs~1{job}/put|/api/v1/namespaces/.../jobs/... , by passing the type field which is required. In the call to /api/v1/lineage the job field offers just to specify (namespace, name), but no other attributes.
> However, deprecated Marquez API didn't give us tools to properly indicate that. On the contrary, OpenLineage with different event types allows us to properly do that. I have the feeling I'm still missing some key concepts on how OpenLineage is designed. I think I went over the API and documentation, but trying to use just OpenLineage failed to reproduce mildly complex chain-of-job scenarios, and when I took a look how Marquez seed demo is doing it - it was heavily based on deprecated API. So, I'm kinda lost on how to use OpenLineage.
I'm looking forward to some open-public meeting, as I don't think asking these long questions on chat really works. 😞 Any pointers are welcome!
*Thread Reply:* > I just gave an example of how would you express a specific job type creation Yes, but you're trying to achieve something by passing this parameter or creating a job in a certain way. We're trying to cover everything in OpenLineage API. Even if we don't have everything, the spec from the beginning is focused to allow emitting custom data by custom facet mechanism.
> I have the feeling I'm still missing some key concepts on how OpenLineage is designed. This talk by @Julien Le Dem is a great place to start: https://www.youtube.com/watch?v=HEJFCQLwdtk
*Thread Reply:* > Any pointers are welcome! BTW: OpenLineage is an open standard. Everyone is welcome to contribute and discuss. Every feedback ultimately helps us build better systems.
*Thread Reply:* I agree, but for now I'm more likely to be in the I didn't get it category, and not in the brilliant new idea category 🙂
My temporary goal is to go over the documentation and to write the gaps that confused me (and the solutions) and maybe publish that as an article for wider audience. So far I realized that: • I don't get the naming convention - it became clearer that it's important with the Naming examples, but more info is needed • I mis-interpret the namespaces. I was placing datasources and jobs in the same namespace which caused a lot of issues until I started using different ones. Not sure why... So now I'm interpreting namespaces=source as suggested by the naming convention • JSON schema actually clarified things a lot, but that's not the most reader-friendly of resources, so surely there should be a better one • I was questioning whether to move away from Marquez completely and go with DataHub, but for my scenario Marquez (with limitations outstanding) is still most suitable • Marquez for some reason does not tolerate the datetimes if they're missing the 'T' delimiter in the ISO, which caused a lot of trial-and-error because the message is just "JSON parsing failed" • Marquez doesn't give you (at least by default) meaningful OpenLineage parsing errors, so running examples against it is a very slow learning process

Hi everyone,
I'm running the Spark Listener on Databricks. It works fine for the event emit part for a basic Databricks SQL Create Table query. Nevertheless, it throws a NullPointerException exception after sending lineage successfully.
I tried to debug a bit. Looks like it's thrown at the line:
QueryExecution queryExecution = SQLExecution.getQueryExecution(executionId);
So, does this mean that the listener can't get the query exec from Spark SQL execution?
Please see the logs in the thread. Thanks.
*Thread Reply:* Driver logs from Databricks:
```22/04/21 14:05:07 INFO EventEmitter: Lineage completed successfully: ResponseMessage(responseCode=200, body={}, error=null) {"eventType":"COMPLETE",[...], "schemaURL":"https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunEvent"}
22/04/21 14:05:07 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception java.lang.NullPointerException at io.openlineage.spark.agent.lifecycle.ContextFactory.createSparkSQLExecutionContext(ContextFactory.java:43) at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$getSparkSQLExecutionContext$8(OpenLineageSparkListener.java:221) at java.util.HashMap.computeIfAbsent(HashMap.java:1127) at java.util.Collections$SynchronizedMap.computeIfAbsent(Collections.java:2674) at io.openlineage.spark.agent.OpenLineageSparkListener.getSparkSQLExecutionContext(OpenLineageSparkListener.java:220) at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:143) at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:135) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:102) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:119) at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:103) at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1588) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)```
*Thread Reply:* @Karatuğ Ozan BİRCAN are you running on Spark 3.2? If yes, then new release should have fixed your problem: https://github.com/OpenLineage/OpenLineage/issues/609
*Thread Reply:* Spark 3.1.2 with Scala 2.12
*Thread Reply:* In fact, I couldn't make it work in Spark 3.2. But I'll test it again. Thanks for the info.
*Thread Reply:* Has this been resolved? I am facing the same issue with spark 3.2.

Does anyone have thoughts on the difference between the sourceCode and sql job facets - and whether we’d expect to ever see both on a particular job?
*Thread Reply:* I don't think that the facets are particularly strongly defined, but I would expect that it could be possible to see both on a pythonOperator that's executing SQL queries, depending on how the extractor was written

Just get to know open lineage and it's really a great project! One question for the granularity on Spark + Openlineage - is it possible to track column level lineage (rather than the table lineage that's currently there)? Thanks!
*Thread Reply:* We're actively working on it - expect it in next OpenLineage release. https://github.com/OpenLineage/OpenLineage/pull/645
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Assuming we don't need to do anything except using the next update? Or do you expect that we need to change quite a lot of configs?
*Thread Reply:* No, it should be automatic.
Hey, Team - We are starting to get requests for other, non Microsoft data sources (e.g. Teradata) for the Spark Integration. We (I) don't have a lot of bandwidth to fill every request but I DO want to help these people new to OpenLineage get started.
Has anyone on the team written up a blog post about extending open lineage or is this an area that we could collaborate on for the OpenLineage blog? Alternatively, is it a bad idea to write this down since the internals have changed a few times over the past six months?
*Thread Reply:* Hey Will,
while I would not consider myself in the team, I'm dabbling in OL, hitting walls and learning as I go. If I don't have enough experience to contribute, I'd be happy to at least proof-read and point out things which are not clear from a novice perspective. Let me know!
*Thread Reply:* I'll hold you to that @Mirko Raca 😉
*Thread Reply:* I will support! I’ve done a few recent presentations on the internals of OpenLineage that might also be useful - maybe some diagrams can be reused.
*Thread Reply:* Any chance you have links to those old presentations? Would be great to build off of an existing one and then update for some of the new naming conventions.
*Thread Reply:* the most recent one was an astronomer webinar
happy to share the slides with you if you want 👍 here’s a PDF:
*Thread Reply:* the other ones have not been public, unfortunately 😕
*Thread Reply:* architecture, object model, run lifecycle, naming conventions == the basics IMO
*Thread Reply:* Thank you so much, Ross! This is a great base to work from.
Hi All, I have a simple spark job from converting csv to parquet and I am using https://openlineage.io/integration/apache-spark/ to generate lineage events and posting to maquez but I see that both events (START & COMPLETE) have the same event except eventType, i thought we should see outputsarray in the complete event right?
*Thread Reply:* For a spark job like that, you'd have at least four events:
- START event - This represents the SparkSQLExecutionStart
- START event #2 - This represents a JobStart event
- COMPLET event - This represents a JobEnd event
- COMPLETE event #2 - This represents a SparkSQLExectionEnd event For CSV to Parquet, you should be seeing inputs and outputs that match across each event. OpenLineage scans the logical plan and reports back the inputs / outputs / metadata across the different facets for each event BECAUSE each event might give you some different information.
For example, the JobStart event might give you access to properties that weren't there before. The JobEnd event might give you information about how many rows were written.
Marquez / OpenLineage expects that you collect all of the resulting events and then aggregate the results.
*Thread Reply:* Hi @Will Johnson good evening. We are seeing an issue while using spark integaration and found that when we provide openlinegae.host property a value like <http://lineage.com/common/marquez> where my marquez api is running I see that the below line is modifying the host to become <http://lineage.com/api/v1/lineage> instead of <http://lineage.com/common/marquez/api/v1/lineage> which is causing the problem
https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/src/main/common/java/io/openlineage/spark/agent/EventEmitter.java#L49
I see that it has been added 5 months ago and released it as part of 0.4.0, is there anyway that we can fix the line to be like below
this.lineageURI =
new URI(
hostURI.getScheme(),
hostURI.getAuthority(),
hostURI.getPath() + uriPath,
queryParams,
null);
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Can you open up a Github issue for this? I had this same issue and so our implementation always has to feature the /api/v1/lineage. The host config is literally the host. You're specifying a host and path. I'd be happy to see greater flexibility with the api endpoint but the /v1/ is important to know which version of OpenLineage's specification you're communicating with.
Hi all, guys ... anyone have an example of a custom extractor with different source-destination, I'm trying to build an extractor from a custom operator like mysql_to_s3
*Thread Reply:* @Michael Collado made one for a recent webinar:
https://gist.github.com/collado-mike/d1854958b7b1672f5a494933f80b8b58
*Thread Reply:* it's not exactly for an operator that has source-destination, but it shows how to format lineage events for a few different kinds of datasets
A release has been requested by @Howard Yoo and @Ross Turk pending the merging of PR 644. Are there any +1s?
*Thread Reply:* Thanks for your input. The release is authorized. Look for it tomorrow!
Hi All, We are seeing the below exception when we integrate the openlineage-spark into our spark job, can anyone share pointers
Exception uncaught: java.lang.NoSuchMethodError: com.fasterxml.jackson.databind.SerializationConfig.hasExplicitTimeZone()Z at openlineage.jackson.datatype.jsr310.ser.InstantSerializerBase.formatValue(InstantSerializerBase.java:144) at openlineage.jackson.datatype.jsr310.ser.InstantSerializerBase.serialize(InstantSerializerBase.java:103) at openlineage.jackson.datatype.jsr310.ser.ZonedDateTimeSerializer.serialize(ZonedDateTimeSerializer.java:79) at openlineage.jackson.datatype.jsr310.ser.ZonedDateTimeSerializer.serialize(ZonedDateTimeSerializer.java:13) at com.fasterxml.jackson.databind.ser.BeanPropertyWriter.serializeAsField(BeanPropertyWriter.java:727) at com.fasterxml.jackson.databind.ser.std.BeanSerializerBase.serializeFields(BeanSerializerBase.java:719) at com.fasterxml.jackson.databind.ser.BeanSerializer.serialize(BeanSerializer.java:155) at com.fasterxml.jackson.databind.ser.DefaultSerializerProvider._serialize(DefaultSerializerProvider.java:480) at com.fasterxml.jackson.databind.ser.DefaultSerializerProvider.serializeValue(DefaultSerializerProvider.java:319) at com.fasterxml.jackson.databind.ObjectMapper._configAndWriteValue(ObjectMapper.java:3906) at com.fasterxml.jackson.databind.ObjectMapper.writeValueAsString(ObjectMapper.java:3220) at io.openlineage.spark.agent.client.OpenLineageClient.executeAsync(OpenLineageClient.java:123) at io.openlineage.spark.agent.client.OpenLineageClient.executeSync(OpenLineageClient.java:85) at <a href="http://io.openlineage.spark.agent.client.OpenLineageClient.post">io.openlineage.spark.agent.client.OpenLineageClient.post</a>(OpenLineageClient.java:80) at <a href="http://io.openlineage.spark.agent.client.OpenLineageClient.post">io.openlineage.spark.agent.client.OpenLineageClient.post</a>(OpenLineageClient.java:75) at <a href="http://io.openlineage.spark.agent.client.OpenLineageClient.post">io.openlineage.spark.agent.client.OpenLineageClient.post</a>(OpenLineageClient.java:70) at io.openlineage.spark.agent.EventEmitter.emit(EventEmitter.java:67) at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:69) at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$sparkSQLExecStart$0(OpenLineageSparkListener.java:90) at java.util.Optional.ifPresent(Optional.java:159) at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:90) at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:81) at org.apache.spark.scheduler.SparkListenerBus$class.doPostEvent(SparkListenerBus.scala:80) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.util.ListenerBus$class.postToAll(ListenerBus.scala:91) at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$super$postToAll(AsyncEventQueue.scala:92) at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply$mcJ$sp(AsyncEventQueue.scala:92) at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87) at org.apache.spark.scheduler.AsyncEventQueue$$anonfun$org$apache$spark$scheduler$AsyncEventQueue$$dispatch$1.apply(AsyncEventQueue.scala:87) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:58) at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:87) at org.apache.spark.scheduler.AsyncEventQueue$$anon$1$$anonfun$run$1.apply$mcV$sp(AsyncEventQueue.scala:83) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1302) at org.apache.spark.scheduler.AsyncEventQueue$$anon$1.run(AsyncEventQueue.scala:82)
*Thread Reply:* What's the spark job that's running - this looks similar to an error that can happen when jobs have a very short lifecycle
*Thread Reply:* nothing in spark job, its just a simple csv to parquet conversion file
*Thread Reply:* ah yeah that's probably it - when the job is finished before the Openlineage integration can poll it for information this error is thrown. Since the job is very quick it creates a race condition
*Thread Reply:* @John Thomas may i know how to solve this kind of issue?
*Thread Reply:* This is probably an issue with the integration - for now you can either open an issue, or see if you're still getting a subset of events and take it as is. I'm not sure what you could do on your end aside from adding a sleep call or similar
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/src/main/common/java/io/openlineage/spark/agent/OpenLineageSparkListener.java#L151 you meant if we add a sleep in this method this will solve this
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* oh no I meant making sure your jobs don't close too quickly
*Thread Reply:* Hi @John Thomas we figured out the error that it is indeed causing with conflicted versions and with shadowJar and shading, we are not seeing it anymore.
@channel The latest release (0.8.1) of OpenLineage is now available, featuring a new TaskInstance listener API for Airflow 2.3+, an HTTP client in the openlineage-java library for emitting run events, support for HiveTableRelation as an input source in the Spark integration, a new SQL parser used by multiple integrations, and bug fixes. For more info, visit https://github.com/OpenLineage/OpenLineage/releases/tag/0.8.1
*Thread Reply:* Amazing work on the new sql parser @Maciej Obuchowski 💯 :firstplacemedal:
The May meeting of the TSC will be postponed because most of the TSC will be attending the Astronomer Spring Summit the week of May 9th. Details to follow along with a new meeting day/time for the meeting going forward (thanks to all who responded to the poll!).

Are there examples of using openlineage with streaming data pipelines? Thanks
*Thread Reply:* Hi @Hubert Dulay,
while I'm not an expert, I can offer the following:
• Marquez has had the

Hey OL! My company is in the process of migrating off of Palantir and into Databricks/Azure. There are a couple of business units not wanting to budge due to the built-in data lineage and code reference features Palantir has. I am tasked with researching an alternative data lineage solution and I quickly came across OL. I love what I have read and seen demos of so far and want to do a POC for my org of its capabilities. I was able to set up the Marquez server on a VM and get it talking to Databricks. I also have the iniit script installed on the cluster and I can see from the log4j logs it’s communicating fine (I think). However, I am embarrassed to admit I can’t figure out how the instrumentation works for the databricks notebooks. I ran a simple notebook that loads data, runs a simple transform, and saves the output somewhere but I don’t see any entries in my namespace I configured. I am sure I missed something very obvious somewhere, but are there examples of how to get a simple example into Marquez from databricks? Thanks so much for any guidance you can give!
*Thread Reply:* Hi Kostikey - this blog has an example with Spark and jupyter, which might be a good place to start!
*Thread Reply:* Hi @John Thomas, thanks for the reply. I think I am close but my cluster is unable to talk to the marquez server. After looking at log4j I see the following rows:
22/05/02 18:43:39 INFO SparkContext: Registered listener io.openlineage.spark.agent.OpenLineageSparkListener
22/05/02 18:43:40 INFO EventEmitter: Init OpenLineageContext: Args: ArgumentParser(host=<http://135.170.226.91:8400>, version=v1, namespace=gus-namespace, jobName=default, parentRunId=null, apiKey=Optional.empty, urlParams=Optional[{}]) URI: <http://135.170.226.91:8400/api/v1/lineage>?
22/05/02 18:46:21 ERROR EventEmitter: Could not emit lineage [responseCode=0]: {"eventType":"START","eventTime":"2022-05-02T18:44:08.36Z","run":{"runId":"91fd4e13-52ac-4175-8956-c06d7dee97fc","facets":{"spark_version":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.8.1/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","spark-version":"3.2.1","openlineage_spark_version":"0.8.1"},"spark.logicalPlan":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.8.1/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.ShowNamespaces","num-children":1,"namespace":0,"output":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num-children":0,"name":"databaseName","dataType":"string","nullable":false,"metadata":{},"exprId":{"product-class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":4,"jvmId":"eaa0543b_5e04_4f5b_844b_0e4598f019a7"},"qualifier":[]}]]},{"class":"org.apache.spark.sql.catalyst.analysis.ResolvedNamespace","num_children":0,"catalog":null,"namespace":[]}]},"spark_unknown":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.8.1/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","output":{"description":"Unable to serialize logical plan due to: Infinite recursion (StackOverflowError) ...
OpenLineageHttpException(code=0, message=java.lang.RuntimeException: java.util.concurrent.ExecutionException: openlineage.hc.client5.http.ConnectTimeoutException: Connect to <http://135.170.226.91:8400> [/135.170.226.91] failed: Connection timed out, details=java.util.concurrent.CompletionException: java.lang.RuntimeException: java.util.concurrent.ExecutionException: openlineage.hc.client5.http.ConnectTimeoutException: Connect to <http://135.170.226.91:8400> [/135.170.226.91] failed: Connection timed out)
at io.openlineage.spark.agent.EventEmitter.emit(EventEmitter.java:68)
at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:69)
at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$sparkSQLExecStart$0(OpenLineageSparkListener.java:90)
at java.util.Optional.ifPresent(Optional.java:159)
at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:90)
at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:81)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:102)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:119)
at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:103)
at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1612)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
the connection timeout is surprising because I can connect just fine using the example curl code from the same cluster:
%sh
curl -X POST <http://135.170.226.91:8400/api/v1/lineage> \
-H 'Content-Type: application/json' \
-d '{
"eventType": "START",
"eventTime": "2020-12-28T19:52:00.001+10:00",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "gus2~-namespace",
"name": "my-job"
},
"inputs": [{
"namespace": "gus2-namespace",
"name": "gus-input"
}],
"producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>"
}'
Spark config:
spark.openlineage.host <http://135.170.226.91:8400>
spark.openlineage.version v1
spark.openlineage.namespace gus-namespace
Not sure what is going on, the EventEmitter init log looks like it's right but clearly something is off. Thanks so much for the help
*Thread Reply:* hmmm, interesting - if it's easy could you spin both up locally and check that it's just a communication issue? It helps with diagnosis
It might also be a firewall issue, but your cURL should preclude that
*Thread Reply:* Since it's Databricks I was having a hard time figuring out how to try locally. Other than just using plain 'ol spark on my laptop and a localhost Marquez...
*Thread Reply:* hmm, that could be an interesting test to see if it's a databricks issue - the databricks integration is pretty much the same as the spark integration, just with a little bit of a wrapper and the init script
*Thread Reply:* yeah, i was going to try that but it just didnt seem like helpful troubleshooting for exactly that reason... but i may just do that anyways just so i can see something working 🙂 (morale booster)
*Thread Reply:* oh totally! Network issues are a huge pain in the ass, and if you're still seeing issues locally with spark/mz then we'll know a lot more than we do now 🙂
*Thread Reply:* sounds good, i will give it a go!
*Thread Reply:* @Kostikey Mustakas - I think spark.openlineage.version should be equal to 1 not v1.
In addition, is http://135.170.226.91:8400 accessible to Databricks? Could you try doing a %sh command inside of a databricks notebook and see if you can ping that IP address (https://linux.die.net/man/8/ping)?
For your Databricks cluster did you VNET inject it into an existing VNET? If it's in an existing VNET, you should confirm that the VM running marquez can access it. If it's in a non-VNET injected VNET, you probably need to redeploy to a VNET that has that VM or has connectivity to that VM.
*Thread Reply:* Ya, know i meant to ask about that. Docs say 1 like you mention: https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/databricks. I second guessed from this thread https://openlineage.slack.com/archives/C01CK9T7HKR/p1638848249159700.
 }
}
*Thread Reply:* @Will Johnson, ping fails... this is surprising as the curl command mentioned above works fine.
*Thread Reply:* I’m also trying to set up Databricks according to Running Marquez on AWS. Right now I’m stuck on the database part rather than the Marquez part — I can’t connect my EKS cluster to the RDS database which I described in more detail on the Marquez slack.
@Kostikey Mustakas Sorry for the distraction, but I’m curious how you have set up your networking to make the API requests work with Databricks. Good luck with your issue!
*Thread Reply:* @Julius Rentergent We are using Azure and leverage Private Endpoints to connect resources in separate subscriptions. There is a Bastion proxy in place that we can map http traffic through and I have a Load Balancer Inbound NAT rule I setup that maps one our whitelisted port ranges (8400) to 5000.
*Thread Reply:* @Will Johnson a little progress maybe... I created a private endpoint and updated dns to point to it. Now I get a 404 Not Found error instead of a timeout
*Thread Reply:* 22/05/03 00:09:24 ERROR EventEmitter: Could not emit lineage [responseCode=404]: {"eventType":"START","eventTime":"2022-05-03T00:09:22.498Z","run":{"runId":"f41575a0-e59d-4cbc-a401-9b52d2b020e0","facets":{"spark_version":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.8.1/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","spark-version":"3.2.1","openlineage_spark_version":"0.8.1"},"spark.logicalPlan":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.8.1/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.ShowNamespaces","num-children":1,"namespace":0,"output":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num-children":0,"name":"databaseName","dataType":"string","nullable":false,"metadata":{},"exprId":{"product-class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":4,"jvmId":"aad3656d_8903_4db3_84f0_fe6d773d71c3"},"qualifier":[]}]]},{"class":"org.apache.spark.sql.catalyst.analysis.ResolvedNamespace","num_children":0,"catalog":null,"namespace":[]}]},"spark_unknown":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.8.1/integration/spark>","_schemaURL":"<https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/RunFacet>","output":{"description":"Unable to serialize logical plan due to: Infinite recursion (StackOverflowError) (through reference chain: org.apache.spark.sql.catalyst.expressions.AttributeReference[\"preCanonicalized\"] ....
OpenLineageHttpException(code=null, message={"code":404,"message":"HTTP 404 Not Found"}, details=null)
at io.openlineage.spark.agent.EventEmitter.emit(EventEmitter.java:68)
*Thread Reply:* Following up on this as I encounter the same issue with the Openlineage Databricks integration. This issue seems quite malicious as it crashes the Spark Context and requires a restart.
I have marquez running on AWS EKS; I’m using Openlineage 0.8.2 on Databricks 10.4 (Spark 3.2.1) and my Spark config looks like this:
spark.openlineage.host <https://internal-xxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxx.us-east-1.elb.amazonaws.com>
spark.openlineage.namespace default
spark.openlineage.version v1 <- also tried "1"
I can run some simple read and write commands and successfully find the log4j events highlighted in the docs:
INFO SparkContext;
INFO OpenLineageContext;
INFO AsyncEventQueue for each time I run the cell
After doing this a few times I get The spark context has stopped and the driver is restarting. Your notebook will be automatically reattached.
stderr shows a bunch of things. log4j shows the same as for Kostikey: ERROR EventEmitter: [...] Unable to serialize logical plan due to: Infinite recursion (StackOverflowError)
I have one more piece of information which I can’t make much sense of, but hopefully someone else can; if I include the port in the host, I can very reliably crash the Spark Context on the first attempt. So:
<https://internal-xxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxx.us-east-1.elb.amazonaws.com> <- crashes after a couple of attempts, sometimes it takes me a while to reproduce it while repeatedly reading/writing the same datasets
<https://internal-xxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxx.us-east-1.elb.amazonaws.com:80> <- crashes on first try
Any insights would be greatly appreciated! 🙂
*Thread Reply:* I tried two more things:
• curl works, ping fails, just like in the previous report
• Databricks allows providing spark configs without quotes, whereas quotes are generally required for Spark. So I added the quotes to the host name, but now I’m getting: ERROR OpenLineageSparkListener: Unable to parse open lineage endpoint. Lineage events will not be collected
*Thread Reply:* @Kostikey Mustakas May I ask what is the reason for migration from Palantir? Sorry for this off-topic question!
*Thread Reply:* @Julius Rentergent created issue on project github: https://github.com/OpenLineage/OpenLineage/issues/795
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you @Maciej Obuchowski. Just to clarify, the Spark Context crashes with and without port; it’s just that adding the port causes it to crash more quickly (on the 1st attempt).
I will run some more experiments when I have time, and add the results to the ticket.
Edit - added to issue:
I ran some more experiments, this time with a fake host and on OpenLineage 0.9.0, and was not able to reproduce the issue with regards to the port; instead, the new experiments show that Spark 3.2 looks to be involved.
On Spark 3.2.1 / Databricks 10.4 LTS: Using (fake) host http://ac7aca38330144df9.amazonaws.com:5000 crashes when the first notebook cell is evaluated with The spark context has stopped and the driver is restarting.
The same occurs when the port is removed.
On Spark 3.1.2 / Databricks 9.1 LTS: Using (fake) host http://ac7aca38330144df9.amazonaws.com:5000 does not impede the cluster but, reasonably, produces for each lineage event ERROR EventEmitter: Could not emit lineage w/ exception io.openlineage.client.OpenLineageClientException: java.net.UnknownHostException
The same occurs when the port is removed.
@channel The poll results are in, and the new day/time for the monthly TSC meeting is each second Thursday at 10 am PT. The next meeting will take place on Thursday, 5/19, at 10 am PT, due to a conflict with the Astronomer Spring Summit. Future meetings will take place on the second Thursday of each month. Calendar updates will be forthcoming. Thanks!
*Thread Reply:* @Michael Robinson - just to be sure, is the 5/19 meeting at 10 AM PT as well?
*Thread Reply:* Yes, and I’ll update the msg for others. Thank you
Hii Team, as i saw marquez is building lineage by java code, from seed command, what should i do to connect with mysql (our database) with credentials and building a lineage for our data?
@here How do we clear old jobs, datasets and namespaces from Marquez?
*Thread Reply:* It seems we can't for now. This was the same question I had last week:
https://github.com/MarquezProject/marquez/issues/1736
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Seems that it's really popular request 🙂
Hello,
I'm sending lineage events to astrocloud.datakin DB with the Marquez API. The event is sent- but the metadata for inputs and outputs isn't coming through. Below is an example of the event I'm sending. Not sure if this is the place for this question. Cross-posting to Marquez Slack.
{
"eventTime": "2022-05-03T17:20:04.151087+00:00",
"run": {
"runId": "2dfc6dcd4011d2a1c3dc1e5861127e5b"
},
"job": {
"namespace": "from-airflow",
"name": "Postgres_1_to_Snowflake_2.extract"
},
"producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>",
"inputs": [
{
"name": "Postgres_1_to_Snowflake_2.extract",
"namespace": "from-airflow"
}
]
}
Thanks.
*Thread Reply:* @Mirko Raca pointed out that I was missing eventType.
Mirko Raca :
"From a quick glance - you're missing "eventType": "START", attribute. It's also worth noting that metadata typically shows up after the second event (type COMPLETE)"
thanks again.
Hii Team, could anyone tell me, to view lineage in marquez do we have to write metadata as a code, or does marquez has a feature to scan the sql code and build a lineage automatically?please clarify my doubt regarding this.
*Thread Reply:* As far as I understand, OpenLineage has tools to extract metadata from sources. Depend on your source, you could find an integration, if it doesn't exists you should write your own integration (and collaborate with the project)
*Thread Reply:* @Sandeep Bhat take a look at https://openlineage.io/integration - there is some info there on the different integrations that can be used to automatically pull metadata.
*Thread Reply:* The Airflow integration, in particular, uses a SQL parser to determine input/output tables (in cases where the data store can't be queried for that info)

Hi all. We are looking at using OpenLineage for capturing some lineage in our custom processing system. I think we got the lineage events understood, but we have often datasets that get appended, or get overwritten by an operation. Is there anything in openlineage that would facilitate making this distinction? (ie. if a set gets overwritten we would be interested in the lineage events from the last overwrite, if it gets appended we would like to have all of these in the display)
*Thread Reply:* To my understanding - datasets model the structure, not the content. So, as long as your table doesn't change number of columns, it's the same thing.
The catch-all would be to create a Dataset facet which would record the distinction between append/overwrite per run. But, while this is supported by the standard, Marquez does not handle custom facets at the moment (I'll happily be corrected).
*Thread Reply:* Thanks, that makes sense. We're looking for a way to get the lineage of table contents. We may have to opt for new names on overwrite, or indeed extend a facet to flag these.
*Thread Reply:* Use case is compliancy, where we need to show how a certain delivered data product (at a given point in time) was constructed. We have all our transforms/transfers as code, but there are a few parts where datasets get recreated in the process after fixes have been made, and I wouldn't want to bother the auditors with those stray paths
*Thread Reply:* We have LifecycleStateChangeDataset facet that captures this information. It's currently emitted when using Spark integration
*Thread Reply:* > But, while this is supported by the standard, Marquez does not handle custom facets at the moment (I'll happily be corrected). It displays this information when it exists
*Thread Reply:* Oh that looks perfect! I completely missed that, thanks!
Are there any examples on how to use this facet ColumnLineageDatasetFacet.json?
*Thread Reply:* Work with Spark is not yet fully merged
Hi All, I am trying to see where we can provide owner details when using openlineage-spark configuration, i see only namespace and other config parameters but not the owner. Can we add owner configuration also as part of openlineage-spark like spark.openlineage.owner? Owner will be used to even filter namespaces when showing the jobs or namespaces in Marquez UI.
@channel The next OpenLineage Technical Steering Committee meeting is next Thursday, 5/19, at 10 am PT! Going forward, meetings will take place on the second Thursday of each month at 10 am PT. Join us on Zoom: https://astronomer.zoom.us/j/87156607114?pwd=a3B0K210dnRaQmdkaFdGMytBREZEQT09 All are welcome! Agenda: • releases 0.7.1 & 0.8.1 • column-level lineage • open lineage For notes and the agenda visit the wiki: https://tinyurl.com/openlineagetsc

Hi all, we are considering using OL to send lineage events from various jobs and places in our company. Since there will be multiple producers, we would like to use Kafka as our main hub for communication. One of our sources will be Airflow (more particularly MWAA, ie airflow in its 2.2.2 version). Is there a way to configure the Airflow lineage backend to send event to kafka instead of Marquez directly? So far, from what I've seen in the docs and in here, the only way would be to create a simple proxy to stream the http events to Kafka. Is it still the case?
*Thread Reply:* I think you can either use proxy backend: https://github.com/OpenLineage/OpenLineage/tree/main/proxy
or configure OL client to send data to kafka: https://github.com/OpenLineage/OpenLineage/tree/main/client/python#kafka
*Thread Reply:* Thank you very much for the useful pointers. The proxy solutions could indeed work in our case but it implies creating another service in front of Kafka, and thus and another layer of complexity to the architecture. If there is another more "native" way of streaming event directly from the Airflow backend that'll be great to know
*Thread Reply:* The second link 😉
*Thread Reply:* Sure, we already implemented the python client for jobs outside airflow and it works great 🙂 You are saying that there is a way to use this python client in conjonction with the MWAA lineage backend to relay the job events that come with the airflow integration (without including it in the DAGs)? Our strategy is to use both the airflow backend to collect automatic lineage events without modifying any existing DAGs, and the in-code implementation to allow our data engineers to send their own events if they want to. The second option works perfectly but the first one is where we struggle a bit, especially with MWAA.
*Thread Reply:* If you can mount file to MWAA, then yes - it should work with config file option: https://github.com/OpenLineage/OpenLineage/tree/main/client/python#config-file
*Thread Reply:* Brilliant! I'm going to test that. Thank you Maciej!
A release has been requested. Are there any +1s? Three from committers will authorize. Thanks.
The OpenLineage TSC meeting is tomorrow at 10am PT! https://openlineage.slack.com/archives/C01CK9T7HKR/p1652483224119229
Hey all, Do custom extractors work with the taskflow api?
*Thread Reply:* Hey Tyler - A custom extractor just needs to be able to assemble the runEvents and send the information out to the lineage backends.
If the things you're sending/receiving with TaskFlow are accessible in terms of metadata in the environment the DAG is running in, then you should be able to make one that would work!
This Webinar goes over creating custom extractors for reference.
Does that answer your question?
*Thread Reply:* Taskflow internally is just PythonOperator. If you'd write extractor that assumes something more than just it being PythonOperator then you'd probably make it work 🙂
*Thread Reply:* Thanks @John Thomas @Maciej Obuchowski, Your answers both make sense. I just keep running into this error in my logs:
[2022-05-18, 20:52:34 UTC] {__init__.py:97} WARNING - Unable to find an extractor. task_type=_PythonDecoratedOperator airflow_dag_id=Postgres_1_to_Snowflake_1_v3 task_id=Postgres_1 airflow_run_id=scheduled__2022-05-18T20:51:34.334045+00:00
The picture is my custom extractor, it's not doing anything currently as this is just a test.
*Thread Reply:* thanks again for the help yall
*Thread Reply:* did you set the environment variable with the path to your extractor?
*Thread Reply:* i believe thats correct @John Thomas
*Thread Reply:* and the versions im using: Astronomer Runtime 5.0.0 based on Airflow 2.3.0+astro.1
*Thread Reply:* this might not be the problem, but you should have only one of extract and extract_on_complete - which one are you meaning to use?
*Thread Reply:* if it's still not working I'm not really sure at this point - that's about what I had when I spun up my own custom extractor
*Thread Reply:* is there anything in logs regarding extractors?
*Thread Reply:* just this:
[2022-05-18, 21:36:59 UTC] {__init__.py:97} WARNING - Unable to find an extractor. task_type=_PythonDecoratedOperator airflow_dag_id=competitive_oss_projects_git_to_snowflake task_id=Transform_git_logs_to_S3 airflow_run_id=scheduled__2022-05-18T21:35:57.694690+00:00
*Thread Reply:* @John Thomas Thanks, I appreciate your help.
*Thread Reply:* No Failed to import messages?
*Thread Reply:* @Maciej Obuchowski None that I can see. Here is the full log: ```* Failed to verify remote log exists s3:///dag_id=Postgres_1_to_Snowflake_1_v3/run_id=scheduled2022-05-19T15:23:49.248097+00:00/task_id=Postgres_1/attempt=1.log. Please provide a bucket_name instead of "s3:///dag_id=Postgres_1_to_Snowflake_1_v3/run_id=scheduled2022-05-19T15:23:49.248097+00:00/task_id=Postgres_1/attempt=1.log" Falling back to local log * Reading local file: /usr/local/airflow/logs/dagid=Postgres1toSnowflake1v3/runid=scheduled2022-05-19T15:23:49.248097+00:00/taskid=Postgres1/attempt=1.log [2022-05-19, 15:24:50 UTC] {taskinstance.py:1158} INFO - Dependencies all met for <TaskInstance: Postgres1toSnowflake1v3.Postgres1 scheduled2022-05-19T15:23:49.248097+00:00 [queued]> [2022-05-19, 15:24:50 UTC] {taskinstance.py:1158} INFO - Dependencies all met for <TaskInstance: Postgres1toSnowflake1v3.Postgres1 scheduled_2022-05-19T15:23:49.248097+00:00 [queued]>
[2022-05-19, 15:24:50 UTC] {taskinstance.py:1355} INFO -
[2022-05-19, 15:24:50 UTC] {taskinstance.py:1356} INFO - Starting attempt 1 of 1
[2022-05-19, 15:24:50 UTC] {taskinstance.py:1357} INFO -
[2022-05-19, 15:24:50 UTC] {taskinstance.py:1376} INFO - Executing <Task(PythonDecoratedOperator): Postgres1> on 2022-05-19 15:23:49.248097+00:00 [2022-05-19, 15:24:50 UTC] {standardtaskrunner.py:52} INFO - Started process 3957 to run task [2022-05-19, 15:24:50 UTC] {standardtaskrunner.py:79} INFO - Running: ['airflow', 'tasks', 'run', 'Postgres1toSnowflake1v3', 'Postgres1', 'scheduled2022-05-19T15:23:49.248097+00:00', '--job-id', '96473', '--raw', '--subdir', 'DAGSFOLDER/pgtosnow.py', '--cfg-path', '/tmp/tmp9n7u3i4t', '--error-file', '/tmp/tmp9a55v9b'] [2022-05-19, 15:24:50 UTC] {standardtaskrunner.py:80} INFO - Job 96473: Subtask Postgres1 [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/configuration.py:470 DeprecationWarning: The sqlalchemyconn option in [core] has been moved to the sqlalchemyconn option in [database] - the old setting has been used, but please update your config. [2022-05-19, 15:24:50 UTC] {taskcommand.py:369} INFO - Running <TaskInstance: Postgres1toSnowflake1v3.Postgres1 scheduled2022-05-19T15:23:49.248097+00:00 [running]> on host 056ca0b6c7f5 [2022-05-19, 15:24:50 UTC] {taskinstance.py:1568} INFO - Exporting the following env vars: AIRFLOWCTXDAGOWNER=airflow AIRFLOWCTXDAGID=Postgres1toSnowflake1v3 AIRFLOWCTXTASKID=Postgres1 AIRFLOWCTXEXECUTIONDATE=20220519T15:23:49.248097+00:00 AIRFLOWCTXTRYNUMBER=1 AIRFLOWCTXDAGRUNID=scheduled2022-05-19T15:23:49.248097+00:00 [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'executiondate' from the template is deprecated and will be removed in a future version. Please use 'dataintervalstart' or 'logicaldate' instead. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'nextds' from the template is deprecated and will be removed in a future version. Please use '{{ dataintervalend | ds }}' instead. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'nextdsnodash' from the template is deprecated and will be removed in a future version. Please use '{{ dataintervalend | dsnodash }}' instead. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'nextexecutiondate' from the template is deprecated and will be removed in a future version. Please use 'dataintervalend' instead. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'prevds' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'prevdsnodash' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'prevexecutiondate' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'prevexecutiondatesuccess' from the template is deprecated and will be removed in a future version. Please use 'prevdataintervalstartsuccess' instead. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'tomorrowds' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'tomorrowdsnodash' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'yesterdayds' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/utils/context.py:202 AirflowContextDeprecationWarning: Accessing 'yesterdaydsnodash' from the template is deprecated and will be removed in a future version. [2022-05-19, 15:24:50 UTC] {python.py:173} INFO - Done. Returned value was: extract [2022-05-19, 15:24:50 UTC] {loggingmixin.py:115} WARNING - /usr/local/lib/python3.9/site-packages/airflow/models/baseoperator.py:1369 DeprecationWarning: Passing 'executiondate' to 'TaskInstance.xcompush()' is deprecated. [2022-05-19, 15:24:50 UTC] {init.py:97} WARNING - Unable to find an extractor. tasktype=PythonDecoratedOperator airflowdagid=Postgres1toSnowflake1v3 taskid=Postgres1 airflowrunid=scheduled2022-05-19T15:23:49.248097+00:00 [2022-05-19, 15:24:50 UTC] {client.py:74} INFO - Constructing openlineage client to send events to https://api.astro-livemaps.datakin.com/ [2022-05-19, 15:24:50 UTC] {taskinstance.py:1394} INFO - Marking task as SUCCESS. dagid=Postgres1toSnowflake1v3, taskid=Postgres1, executiondate=20220519T152349, startdate=20220519T152450, enddate=20220519T152450 [2022-05-19, 15:24:50 UTC] {localtaskjob.py:156} INFO - Task exited with return code 0 [2022-05-19, 15:24:50 UTC] {localtask_job.py:273} INFO - 1 downstream tasks scheduled from follow-on schedule check```

*Thread Reply:* @Maciej Obuchowski is our ENV var wrong maybe? Do we need to mention the file to import somewhere else that we may have missed?
*Thread Reply:* @Josh Owens one thing I can think of is that you might have older openlineage integration version, as OPENLINEAGE_EXTRACTORS variable was added very recently: https://github.com/OpenLineage/OpenLineage/pull/694
*Thread Reply:* @Maciej Obuchowski, that was it! For some reason, my requirements.txt wasn't pulling the latest version of openlineage-airflow. Working now with 0.8.2

Hi 👋, I'm looking at OpenLineage as a solution for fine-grained data lineage tracking. Could I clarify a couple of points?
Where does one specify the version of an input dataset in the RunEvent? In the Marquez seed data I can see that it's recorded, but I'm not sure where it goes from looking at the OpenLineage schema. Or does it just assume the last version?
*Thread Reply:* Currently, it assumes latest version. There's an effort with DatasetVersionDatasetFacet to be able to specify it manually - or extract this information from cases like Iceberg or Delta Lake tables.
*Thread Reply:* Ah ok. Is it Marquez assuming the latest version when it records the OpenLineage event?
*Thread Reply:* yes
*Thread Reply:* Thanks, that's very helpful 👍

Hi all, I was testing https://github.com/MarquezProject/marquez/tree/main/examples/airflow#step-21-create-dag-counter, and the following error was observed in my airflow env:
Anybody know why this is happening? Any comments would be welcomed.
*Thread Reply:* @Howard Yoo What version of airflow?
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow Id refer to the docs again.
"Airflow 2.3+ Integration automatically registers itself for Airflow 2.3 if it's installed on Airflow worker's python. This means you don't have to do anything besides configuring it, which is described in Configuration section."
*Thread Reply:* Right, configuring I don't see any issues
*Thread Reply:* so you dont need:
from openlineage.airflow import DAG
in your dag files
*Thread Reply:* so if you need to import DAG it would just be:
from airflow import DAG
@channel OpenLineage 0.8.2 is now available! The project now supports credentialing from the Airflow Secrets Backend and for the Azure Databricks Credential Passthrough, detection of datasets wrapped by ExternalRDDs, bug fixes, and more. For the details, see: https://github.com/OpenLineage/OpenLineage/releases/tag/0.8.2
Hi~ everyone Is there possible to let openlineage to support camel pipeline?
*Thread Reply:* What changes do you mean by letting openlineage support? Or, do you mean, to write Apache Camel integration?
*Thread Reply:* @Maciej Obuchowski Yes, let openlineage work as same as airflow
*Thread Reply:* I think this is a very valuable thing. I wish openlineage can support some commonly used pipeline tools, and try to abstract out some general interfaces so that users can expand by themselves
*Thread Reply:* For Python, we have OL client, common libraries (well, at least beginning of them) and SQL parser
*Thread Reply:* As we support more systems, the general libraries will grow as well.
I see a change in the metadata collected from Airflow jobs which I think was introduced with the combination of Airflow 2.3/OpenLineage 0.8.1. There's an airflow_version facet that contains an operator attribute.
Previously that attribute had values such as: airflow.providers.postgres.operators.postgres.PostgresOperator but I now see that for the very same task the operator is now tracked as: airflow.models.taskinstance.TaskInstance
( fwiw there's also a taskInfo attribute in there containing a json string which itself has a operator that is still set to PostgresOperator )
Is this an already known issue?
*Thread Reply:* This looks like a bug. we are probably not looking at the right instance in the TaskInstanceListener
*Thread Reply:* @Howard Yoo I filed: https://github.com/OpenLineage/OpenLineage/issues/767 for this
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Would anyone happen to have a link to the Technical Steering Committee meeting recordings?
I have quite a few people interested in seeing the overview of column lineage that Pawel provided during the Technical Steering Committee meeting on Thursday May 19th.
The wiki does not include a link to the recordings: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
Are the recordings made public? Thank you for any links and guidance!
That would be @Michael Robinson Yes the recordings are made public.
@Will Johnson I’ll put this on the https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting|wiki soon, but here is the link to the recording: https://astronomer.zoom.us/rec/share/xUBW-n6G4u1WS89tCSXStx8BMl99rCfCC6jGdXLnkN6gMGn5G-_BC7pxHKKeELhG.0JFl88isqb64xX-3 PW: 1VJ=K5&X
Is there documentation/examples around creating custom facets?
*Thread Reply:* In Python or Java?
*Thread Reply:* In python just inherit BaseFacet and add _get_schema static method that would point to some place where you have your json schema of a facet. For example our DbtVersionRunFacet
In Java you can take a look at Spark's custom facets.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks, @Maciej Obuchowski, I was asking in regards to Python, sorry I should have clarified.
I'm not sure what the disconnect is, but the facets aren't showing up in the inputs and outputs. The Lineage event is sent successfully to my astrocloud.
below is the facet and extractor, any help is appreciated. Thanks!
```import logging from openlineage.airflow.extractors.base import BaseExtractor, TaskMetadata from openlineage.client.run import InputDataset, OutputDataset from typing import List, Optional from openlineage.client.facet import BaseFacet import attr
log = logging.getLogger(name)
@attr.s class ManualLineageFacet(BaseFacet): database: Optional[str] = attr.ib(default=None) cluster: Optional[str] = attr.ib(default=None) connectionUrl: Optional[str] = attr.ib(default=None) target: Optional[str] = attr.ib(default=None) source: Optional[str] = attr.ib(default=None) _producer: str = attr.ib(init=False) _schemaURL: str = attr.ib(init=False)
@staticmethod
def _get_schema() -> str:
return {
"$schema": "<http://json-schema.org/schema#>",
"$defs": {
"ManualLineageFacet": {
"allOf": [
{
"type": "object",
"properties": {
"database": {
"type": "string",
"example": "Snowflake",
},
"cluster": {
"type": "string",
"example": "us-west-2",
},
"connectionUrl": {
"type": "string",
"example": "<http://snowflake>",
},
"target": {
"type": "string",
"example": "Postgres",
},
"source": {
"type": "string",
"example": "Stripe",
},
"description": {
"type": "string",
"example": "Description of inlet/outlet",
},
"_producer": {
"type": "string",
},
"_schemaURL": {
"type": "string",
},
},
},
],
"type": "object",
}
},
}
class ManualLineageExtractor(BaseExtractor): @classmethod def getoperatorclassnames(cls) -> List[str]: return ["PythonOperator", "_PythonDecoratedOperator"]
def extract_on_complete(self, task_instance) -> Optional[TaskMetadata]:
return TaskMetadata(
f"{task_instance.dag_run.dag_id}.{task_instance.task_id}",
inputs=[
InputDataset(
namespace="default",
name=self.operator.get_inlet_defs()[0]["name"],
inputFacets=ManualLineageFacet(
database=self.operator.get_inlet_defs()[0]["database"],
cluster=self.operator.get_inlet_defs()[0]["cluster"],
connectionUrl=self.operator.get_inlet_defs()[0][
"connectionUrl"
],
target=self.operator.get_inlet_defs()[0]["target"],
source=self.operator.get_inlet_defs()[0]["source"],
),
)
if self.operator.get_inlet_defs()
else {},
],
outputs=[
OutputDataset(
namespace="default",
name=self.operator.get_outlet_defs()[0]["name"],
outputFacets=ManualLineageFacet(
database=self.operator.get_outlet_defs()[0]["database"],
cluster=self.operator.get_outlet_defs()[0]["cluster"],
connectionUrl=self.operator.get_outlet_defs()[0][
"connectionUrl"
],
target=self.operator.get_outlet_defs()[0]["target"],
source=self.operator.get_outlet_defs()[0]["source"],
),
)
if self.operator.get_outlet_defs()
else {},
],
job_facets={},
run_facets={},
)
def extract(self) -> Optional[TaskMetadata]:
pass```
*Thread Reply:* _get_schema should return address to the schema hosted somewhere else - afaik sending object field where server expects string field might cause some problems
*Thread Reply:* can you register ManualLineageFacet as facets not as inputFacets or outputFacets?
*Thread Reply:* Thanks for the advice @Maciej Obuchowski, I was able to get it working! Also great talk today at the airflow summit.
Hey guys! I'm pretty new with OL but would like to start using it for a combination of data lineage in Airflow + data quality metrics collection. I was wondering if that was possible, but Ross clarified that in the deeper dive webinar from some weeks ago (great one by the way!).
I'm referencing this comment from Julien to see if you have any updates or more examples apart from the one from great expectations. We have some custom operators and would like to push lineage and data quality metrics to Marquez using custom extractors. Any reference will be highly appreciated. Thanks in advance!

*Thread Reply:* We're also getting data quality from dbt if you're running dbt test or dbt build
https://github.com/OpenLineage/OpenLineage/blob/main/integration/common/openlineage/common/provider/dbt.py#L399
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Generally, you'd need to construct DataQualityAssertionsDatasetFacet and/or DataQualityMetricsInputDatasetFacet and attach it to tested dataset
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hi all, https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow#development <-- does this still work? I did follow the instructions, but running pytest failed with error messages like
________________________________________________ ERROR collecting tests/extractors/test_bigquery_extractor.py ________________________________________________
ImportError while importing test module '/Users/howardyoo/git/OpenLineage/integration/airflow/tests/extractors/test_bigquery_extractor.py'.
Hint: make sure your test modules/packages have valid Python names.
Traceback:
openlineage/airflow/utils.py:251: in import_from_string
module = importlib.import_module(module_path)
/opt/homebrew/Caskroom/miniconda/base/envs/airflow/lib/python3.9/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
<frozen importlib._bootstrap>:1030: in _gcd_import
???
<frozen importlib._bootstrap>:1007: in _find_and_load
???
<frozen importlib._bootstrap>:986: in _find_and_load_unlocked
???
<frozen importlib._bootstrap>:680: in _load_unlocked
???
<frozen importlib._bootstrap_external>:850: in exec_module
???
<frozen importlib._bootstrap>:228: in _call_with_frames_removed
???
../../../airflow.master/airflow/providers/google/cloud/operators/bigquery.py:39: in <module>
from airflow.providers.google.cloud.hooks.bigquery import BigQueryHook, BigQueryJob
../../../airflow.master/airflow/providers/google/cloud/hooks/bigquery.py:46: in <module>
from googleapiclient.discovery import Resource, build
E ModuleNotFoundError: No module named 'googleapiclient'
looks like just running the pytest wouldn't be able to run all the tests - as some of these dag tests seems to be requiring connectivities to google's big query, databases, etc..

👋 Hi everyone! I didn't find this in the documentation. Can open lineage show me which source columns the final DataFrame column came from? (Spark)
*Thread Reply:* We're working on this feature - should be in the next release from OpenLineage side
*Thread Reply:* Thanks! I will keep an eye on updates.
Hi all, showcase time:
We have implemented a native OpenLineage endpoint and metadata writer in our Keboola all-in-one data platform.
The reason was that for more complex data pipeline scenarios it is beneficial to display the lineage in more detail. Additionally, we hope that OpenLineage as a standard will catch up and open up the ability to push lineage data into other data governance tools than Marquez.
The implementation started as an internal POC of tweaking our metadata into OpenLineage /lineage format and resulted into a native API endpoint and later on an app within Keboola platform ecosystem - feeding platform job metadata in a regular cadence.
We furthermore use a namespace for each keboola project so users can observe the data through their whole data mesh setup (multi-project architecture).
Please reach me out if you have any questions!
*Thread Reply:* Looks great! Thanks for sharing!

Hi OpenLineage team,
I am Gopi Krishnan Rajbahadur, one of the core members of OpenDatalogy project (a project that we are currently trying to sandbox as a part of LF-AI). Our OpenDatalogy project focuses on providing a process that allows users of publicly available datasets (e.g., CIFAR-10) to ensure license compliance. In addition, we also aim to provide a public repo that documents the final rights and obligations associated with common publicly available datasets, so that users of these datasets can use them compliantly in their AI models and software.
One of the key aspects of conducting dataset license compliance analysis involves tracking the lineage and provenance of the dataset (as we highlight in this paper here: https://arxiv.org/abs/2111.02374). We think that in this regard, our projects (i.e., OpenLineage and OpenDatalogy) could work together to use the existing OpenLineage standard and also collaborate to adopt/modify/enhance and use OpenLineage to track and document the lineage of a publicly available dataset. On that note, we are also working with the SPDX community to make the lineage and provenance of a dataset be tracked as a part of the SPDX BOM that is in the works for representing AI software (AI SBOM).
We think our projects could mutually benefit from collaborating with each other. Our project's Github could be found here: https://github.com/OpenDataology/OpenDataology. Any feedback that you have about our project would be greatly appreciated. Also, as we are trying to sandbox our project, if you could also show us your support we would greatly appreciate it!
Look forward to hearing back from you
Sincerely, Gopi

Hi guys, sorry for basics. I did some PoC for OpenLineage usage for gathering metrics on Spark job, especially for table creation, alter and drop I detect that Drop/Alter table statements is not trigger listener to post lineage data, Is it normal behaviour?
*Thread Reply:* Might be that case if you're using Spark 3.2
*Thread Reply:* There were some changes to those operators
*Thread Reply:* If you're not using 3.2, please share more details 🙂
*Thread Reply:* Yeap, im using spark version 3.2.1
*Thread Reply:* is it open issue, or i have some option to force them to be sent?)
*Thread Reply:* btw thank you for quick response @Maciej Obuchowski
*Thread Reply:* Yes, we have issue for AlterTable at least

*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/616 -> that’s the issue for altering tables in Spark 3.2.
@Ilqar Memmedov Did you mean drop table or drop columns? I am not aware of any drop table issue.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Paweł Leszczyński drop table statement.
*Thread Reply:* For reproduce it, i just create simple spark job. Create table as select from other, Select data from table, and then drop entire table.
Lineage data was posted only for "Create table as select" part
*Thread Reply:* hi xiang 👋 lineage in airflow depends on the operator. some operators have extractors as part of the integration, but when they are missing you only see job information in Marquez.
*Thread Reply:* take a look at https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow#extractors--sending-the-correct-data-from-your-dags for a bit more detail
Another problem is that if I declare a skip task(e.g. DummyOperator) in the DAG, it will never appear in the job list. I think this is a problem, because even if it can not run, it should be able to see it as a metadata object.
@channel The next OpenLineage Technical Steering Committee meeting is on Thursday, June 9 at 10 am PT. Join us on Zoom: https://us02web.zoom.us/j/81831865546?pwd=RTladlNpc0FTTDlFcWRkM2JyazM4Zz09 All are welcome! Agenda:
- a recent blog post about Snowflake
- the Great Expectations integration
- the dbt integration
- Open discussion Notes: https://tinyurl.com/openlineagetsc Is there a topic you think the community should discuss at this or a future meeting? DM me to add items to the agenda.
@channel OpenLineage 0.9.0 is now available, featuring column-level lineage in the Spark integration, bug fixes and more! For the details, see: https://github.com/OpenLineage/OpenLineage/releases/tag/0.9.0 and https://github.com/OpenLineage/OpenLineage/compare/0.8.2...0.9.0. Thanks to all the contributors who made this release possible, including @Paweł Leszczyński for authoring the column-level lineage PRs and new contributor @JDarDagran!
Hey, all. Working on a PR to OpenLineage. I'm curious about file naming conventions for facets. Im noticing that there are two conventions being used:
• In OpenLineage.spec.facets; ex. ExampleFacet.json • In OpenLineage.integration.common.openlineage.common.schema; ex. example-facet.json. Thanks
*Thread Reply:* I think internal naming is more important 🙂
I guess, for now, try to match what the local directory has.
Hi Team, we are seeing DatasetName as the Custom query when we run a spark job which queries Oracle DB using JDBC with a Custom Query and the custom query is having newline syntax in it which is causing the NodeId ID_PATTERN match to fail. How to give custom dataset name when we use custom queries?
Marquez API regex ref: https://github.com/MarquezProject/marquez/blob/main/api/src/main/java/marquez/service/models/NodeId.java#L44
ERROR [2022-06-07 06:11:49,592] io.dropwizard.jersey.errors.LoggingExceptionMapper: Error handling a request: 3648e87216d7815b
! java.lang.IllegalArgumentException: node ID (dataset:oracle:thin:_//<host-name>:1521:(
! SELECT
! RULE.RULE_ID,
! ASSG.ASSIGNED_OBJECT_ID, ASSG.ORG_ID, ASSG.SPLIT_PCT,
! PRTCP.PARTICIPANT_NAME, PRTCP.START_DATE, PRTCP.END_DATE
! FROM RULE RULE,
! ASSG ASSG,
! PRTCP PRTCP
! WHERE
! RULE.RULE_ID = ASSG.RULE_ID(+)
! --AND RULE.RULE_ID = 300100207891651
! AND PRTCP.PARTICIPANT_ID = ASSG.ASSIGNED_OBJECT_ID
! -- and RULE.created_by = ' 1=1 '
! and 1=1
! )) must start with 'dataset', 'job', or 'run'

Hi Team,
We have a spark job xyz that uses OpenLineageListener which posts Lineage events to Marquez server. But we are seeing some unknown jobs in the Marquez UI :
• xyz.collect_limit
• xyz.execute_insert_into_hadoop_fs_relation_command
What jobs are these (collect_limit, execute_insert_into_hadoop_fs_relation_command ) ?
How do we get the lineage listener to post only our job (xyz) ?
*Thread Reply:* Those jobs are actually what Spark does underneath 🙂
*Thread Reply:* Are you using Delta Lake btw?

*Thread Reply:* No, this is not Delta Lake. It is a normal Spark app .
*Thread Reply:* @Maciej Obuchowski i think David posted about this before. https://openlineage.slack.com/archives/C01CK9T7HKR/p1636011698055200
 }
}
*Thread Reply:* I agree that it looks bad on UI, but I also think integration is going good job here. The eventual "aggregation" should be done by event consumer.
If anything, we should filter some 'useless' nodes like collect_limit since they add nothing.
We have an issue for doing this to specifically delta lake operations, as they are the biggest offenders: https://github.com/OpenLineage/OpenLineage/issues/628
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Maciej Obuchowski but we only see these 2 jobs in the namespace, no other jobs were part of the lineage metadata, are we doing something wrong?
*Thread Reply:* @Michael Robinson On this note, may we know how to form a lineage if we have different set of API's before calling the spark job (already integrated with OpenLineageSparkListener), we want to see how the different set of params pass thru these components before landing into the spark job. If we use openlineage client to post the lineage events into the Marquez, do we need to mention the same Run UUID across the lineage events for the run or is there any other way to do this? Can you pls advise?
*Thread Reply:* I think I understand what you are asking -
The runID is used to correlate different state updates (i.e., start, fail, complete, abort) across the lifespan of a run. So if you are trying to add additional metadata to the same job run, you’d use the same runID.
So you’d generate a runID and send a START event, then in the various components you could send OTHER events containing the same runID + params you want to study in facets, then at the end you would send a COMPLETE.
(I think there should be an UPDATE event type in the spec for this sort of thing.)
*Thread Reply:* thanks @Ross Turk but what i am looking for is lets say for example, if we have 4 components in the system then we want to show the 4 components as job icons in the graph and the datasets between them would show the input/output parameters that these components use. A(job) --> DS1(dataset) --> B(job) --> DS2(dataset) --> C(job) --> DS3(dataset) --> D(job)
*Thread Reply:* then you would need to have separate Jobs for each, with inputs and outputs defined
*Thread Reply:* so there would be a Run of job B that shows DS1 as an input and DS2 as an output
*Thread Reply:* (fyi: I know openlineage but my understanding stops at spark 😄)
*Thread Reply:* > The eventual “aggregation” should be done by event consumer. @Maciej Obuchowski Are there any known client side libraries that support this aggregation already ? In case of spark applications running as part of ETL pipelines, most of the times our end user is interested in seeing only the aggregated view where all jobs spawned as part of a single application are rolled up into 1 job.
*Thread Reply:* I believe Microsoft @Will Johnson has something similar to that, but it's probably proprietary.
We'd love to have something like it, but AFAIK it affects only some percentage of Spark jobs and we can only do so much.
With exception of Delta Lake/Databricks, where it affects every job, and we know some nodes that could be safely filtered client side.
*Thread Reply:* @Maciej Obuchowski Microsoft ❤️ OSS!
Apache Atlas doesn't have the same model as Marquez. It only knows of effectively one entity that represents the complete asset.
@Mark Taylor designed this solution available now on Github to consolidate OpenLineage messages
In addition, we do some filtering only based on inputs and outputs to limit the messages AFTER it has been emitted.
<a href="https://github.com/microsoft/Purview-ADB-Lineage-Solution-Accelerator">microsoft/Purview-ADB-Lineage-Solution-Accelerator</a>
@channel The next OpenLineage TSC meeting is tomorrow! https://openlineage.slack.com/archives/C01CK9T7HKR/p1654093173961669
*Thread Reply:* Hi, is the link correct? The meeting room is empty
*Thread Reply:* sorry about that, thanks for letting us know

Hello all, after sending dbt openlineage events to Marquez, I am now looking to use the Marquez API to extract the lineage information. I am able to use python requests to call the Marquez API to get other information such as namespaces, datasets, etc., but I am a little bit confused about what I need to enter to get the lineage. I included screenshots for what the API reference shows regarding retrieving the lineage where it shows that a nodeId is required. However, this is where I seem to be having problems. It is not exactly clear where the nodeId needs to be set or what the nodeId needs to include. I would really appreciate any insights. Thank you!
*Thread Reply:* Hey @Mark Beebe!
In this case, nodeId is going to be either a dataset or a job. You need to tell Marquez where to start since there is likely to be more than one graph. So you need to get your hands on an identifier for that starting node.
*Thread Reply:* aaaaannnnd that’s actually all the ways I can think of.
*Thread Reply:* That worked, thank you so much!
Hi all, I need to send the lineage information from spark integration directly to a kafka topic. Java client seems to have a KafkaTransport, is it planned to have this support from inside the spark integration as well?
Hi all, I’m working on a blog post about the Spark integration and would like to credit @tnazarew and @Sbargaoui for their contributions. Anyone know these contributors’ names? Are you on here? Thanks for any leads.
*Thread Reply:* tnazarew - Tomasz Nazarewicz
Has anyone tried getting the OpenLineage Spark integration working with GCP Dataproc ?

Hi Folks, DataEngBytes is a community data engineering conference here in Australia and will be hosted on the 27th and 29th of September. Our CFP is open for just under a month and tickets are on sale now: Call for paper: https://sessionize.com/dataengbytes-2022/ Tickets: https://www.tickettailor.com/events/dataengbytes/713307 Promo video https://youtu.be/1HE_XNLvHss


A release of OpenLineage has been requested pending the merging of #856. Three +1s will authorize a release today. @Willy Lulciuc @Michael Collado @Ross Turk @Maciej Obuchowski @Paweł Leszczyński @Mandy Chessell @Daniel Henneberger @Drew Banin @Julien Le Dem @Ryan Blue @Will Johnson @Zhamak Dehghani
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

👋 Hi everyone!

hi
@channel OpenLineage 0.10.0 is now available! We added SnowflakeOperatorAsync extractor support to the Airflow integration, an InMemoryRelationInputDatasetBuilder for InMemory datasets to the Spark integration, a static code analysis tool to run in CircleCI on Python modules, a copyright to all source files, and a debugger called PMD to the build process.
Changes we made include skipping FunctionRegistry.class serialization in the Spark integration, installing the new rust-based SQL parser by default in the Airflow integration, improving the integration tests for the Airflow integration, reducing event payload size by excluding local data and including an output node in start events, and splitting the Spark integration into submodules.
Thanks to all the contributors who made this release possible!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.10.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.9.0...0.10.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

Why has put dataset been deprecated? How do I add an initial data set via api?
*Thread Reply:* I think you’re reference the deprecation of the DatasetAPI in Marquez? A milestone for the Marquez is to only collect metadata via OpenLineage events. This includes metadata for datasets , jobs , and runs . The DatasetAPI won’t be removed until support for collecting dataset metadata via OpenLineage has been added, see https://github.com/OpenLineage/OpenLineage/issues/323
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Once the spec supports dataset metadata, we’ll outline steps in the Marquez project to switch to using the new dataset event type
*Thread Reply:* The DatasetAPI was also deprecated to avoid confusion around which API to use
So how would you propose I create the initial node if I am trying to do a POC?
*Thread Reply:* Do you want to register just datasets? Or are you extracting metadata for a job that would include input / output datasets? (outside of Airflow of course)
*Thread Reply:* Sorry didn't notice you over here ! lol
*Thread Reply:* So ideally I would like to map out our current data flow from on prem to aws
*Thread Reply:* What do you mean by mapping to AWS? Like send OL events to a service on AWS that would process the lineage metadata?
*Thread Reply:* no, just visualize the current migration flow.
*Thread Reply:* Ah I see, youre doing a infra migration from on prem to AWS 👌
*Thread Reply:* really AWS is irrelevant. Source sink -> migration scriipts -> s3 -> additional processing -> final sink
*Thread Reply:* right right. so you want to map out that flow and visualize it in Marquez? (or some other meta service)
*Thread Reply:* which I think I can do once the first nodes exist
*Thread Reply:* But I don't know how to get that initial node. I tried using the input facet at job start , that didn't do it. I also can't get the sql context that is in these examples.
*Thread Reply:* really just want to re-create food_devlivery using my own biz context
*Thread Reply:* Have you looked over our workshops and this example? (assuming you’re using python?)
<a href="https://github.com/OpenLineage/workshops">OpenLineage/workshops</a>
*Thread Reply:* that goes over the py client with some OL examples, but really calling openlineage.emit(...) method with RunEvents and specifying Marquez as the backend will get you up and running!
*Thread Reply:* Don’t forget to configure the transport for the client
*Thread Reply:* sweet. Thank you! I'll take a look. Also.. Just came across datakin for the first time. very nice 🙂
*Thread Reply:* thanks! …. but we’re now part of astronomer.io 😉
*Thread Reply:* making airflow oh-so-easy-to-use one DAG at a time

Hello, Is OpenLineage planning to add support for inlets and outlets for Airflow integration? I am working on a project that relies on it and was hoping to contribute to this feature if its something that is in the talks. I saw an open issue here
I am willing to work on it. My plan was to just support Files and Tables entities (for inlets and outlets).
Pass the inlets and outlets info into extract_metadata function here and then convert Airflow entities into TaskMetaData entities here.
Does this sound reasonable?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Honestly, I’ve been a huge fan of using / falling back on inlets and outlets since day 1. AND if you’re willing to contribute this support, you get a +1 from me (I’ll add some minor comments to the issue) /cc @Julien Le Dem
*Thread Reply:* would be great to get @Maciej Obuchowski thoughts on this as well
*Thread Reply:* I have created a draft PR for this here. Please let me know if the changes make sense.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think this effort: https://github.com/OpenLineage/OpenLineage/pull/904 ultimately makes more sense, since it will allow getting lineage on Airflow 2.3+ too
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I have made the changes in-line to the mentioned comments here. Does this look good?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think it looks good! Would be great to have tests for this feature though.
*Thread Reply:* I have added the tests! Would really appreciate it if someone can take a look and let me know if anything else needs to be done. Thank you for the support! 😄
*Thread Reply:* One change and I think it will be good for now.
*Thread Reply:* Have you tested it manually?
*Thread Reply:* Thanks a lot for the review! Appreciate it 🙌 Yes, I tested it manually (for Airflow versions 2.1.4 and 2.3.3) and it works 🎉
*Thread Reply:* I think this is such a useful feature to have, thank you! Would you mind adding a little example to the PR of how to use it? Like a little example DAG or something? ( either in a comment or edit the PR description )
*Thread Reply:* Yes, Sure! I will add it in the PR description
*Thread Reply:* I think it would be easy to convert to integration test then if you provided example dag
*Thread Reply:* ping @Fenil Doshi if possible I would really love to see the example DAG on there 🙂 🙏
*Thread Reply:* Yes, I was going to but the PR got merged so did not update the description. Should I just update the description of merged PR? Or should I add it somewhere in the docs?
*Thread Reply:* ^ @Ross Turk is it easy for @Fenil Doshi to contribute doc for manual inlet definition on the new doc site?
*Thread Reply:* It is easy 🙂 it's just markdown: https://github.com/openlineage/docs/
*Thread Reply:* @Fenil Doshi feel free to create new page here and don't sweat where to put it, we'll still figuring the structure of it out and will move it then
*Thread Reply:* exactly, yes - don’t be worried about the doc quality right now, the doc site is still in a pre-release state. so whatever you write will be likely edited or moved before it becomes official 👍
*Thread Reply:* I added documentations here - https://github.com/OpenLineage/docs/pull/16
Also, have added an example for it. 🙂 Let me know if something is unclear and needs to be updated.
<a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
*Thread Reply:* Does Airflow check the types of the inlets/outlets btw?
Like I wonder if a user could directly define an OpenLineage DataSet ( which might even have various other facets included on it ) and specify it in the inlets/outlets ?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Yeah, I was also curious about using the models from airflow.lineage.entities as opposed to openlineage.client.run.
*Thread Reply:* I am accustomed to creating OpenLineage entities like this:
taxes = Dataset(namespace="<postgres://foobar>", name="schema.table")
*Thread Reply:* I don’t dislike the airflow.lineage.entities models especially, but if we only support one of them…
*Thread Reply:* yeah, if Airflow allows that class within inlets/outlets it'd be nice to support both imo.
Like we would suggest users to use openlineage.client.run.Dataset but if a user already has DAGs that use Table then they'd still work in a best efforts way.
*Thread Reply:* either Airflow depends on OpenLineage or we can probably change those entities as part of AIP-48 overhaul to more openlineage-like ones
*Thread Reply:* hm, not sure I understand the dependency issue. isn’t this extractor living in openlineage-airflow?
*Thread Reply:* I gave manual lineage a try with native OL Datasets specified in the Airflow inlets/outlets and it seems to work! Had to make some small tweaks which I have attempted here: https://github.com/OpenLineage/OpenLineage/pull/1015
( I left the support for converting the Airflow Table to Dataset because I think that's nice to have also )
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
food_delivery example example.etl_categories node
*Thread Reply:* Ahh great question! I actually just updated the seeding cmd for Marquez to do just this (but in java of course)
*Thread Reply:* Give me a sec to send you over the diff…
*Thread Reply:* … continued here https://openlineage.slack.com/archives/C01CK9T7HKR/p1656456734272809?thread_ts=1656456141.097229&cid=C01CK9T7HKR
I'm very new to DBT but wanted to give it a try with OL. I had a couple of questions when going through the DBT tutorial here: https://docs.getdbt.com/guides/getting-started/learning-more/getting-started-dbt-core
- An earlier part of the tutorial has you build a model in a single sql file: https://docs.getdbt.com/guides/getting-started/learning-more/getting-started-dbt-core#build-your-first-model When I did this and ran
dbt-olI got a lineage graph like this:
then a later part of the tutorial has you split that same example into multiple models and when I run it again I get the graph like:
^ I'm just kind of curious if it's working as expected? And/or could it be possible to parse the DBT .sql so that the lineage in the first case would still show those staging tables?
*Thread Reply:* I think you should declare those as sources? Or do you need something different?
*Thread Reply:* I'll try to experiment with this.
- I see that DBT has a concept of adding tests to your models. Could those add data quality facets in OL ?
*Thread Reply:* this should already be working if you run dbt-ol test or dbt-ol build

Hi everyone, i am trying openlineage-dbt. It works perfectly on locally when i try to publish the events to Marquez...but when i run the same commands from mwaa...i dont see those events triggered..i amnt able to view any logs if there is any error. How do i debug the issue
*Thread Reply:* Maybe @Maciej Obuchowski knows? You need to check, it's using the dbt-ol command and that the configuration is available. (environment variables or conf file)
*Thread Reply:* Maybe some aws networking stuff? I'm not really sure how mwaa works internally (or, at all - never used it)
*Thread Reply:* anyway, any logs/errors should be in the same space where your task logs are
Agenda items are requested for the next OpenLineage Technical Steering Committee meeting on July 14. Reply in thread or ping me with your item(s)!
*Thread Reply:* What is the status on the Flink / Streaming decisions being made for OpenLineage / Marquez?
A few months ago, Flink was being introduced and it was said that more thought was needed around supporting streaming services in OpenLineage.
It would be very helpful to know where the community stands on how streaming data sources should work in OpenLineage.
*Thread Reply:* @Will Johnson added your item
Request for Creating a New OpenLineage Release
Hello #general, as per the Governance guide (https://github.com/OpenLineage/OpenLineage/blob/main/GOVERNANCE.md#openlineage-project-releases), I am asking that we generate a new release based on the latest commit by @Maciej Obuchowski (c92a93cdf3df636a02984188563d019474904b2b) which fixes a critical issue running OpenLineage on Azure Databricks.
Having this release made available to the general public on Maven would allow us to enable the hundred+ users of the solution to run OpenLineage on the latest LTS versions of Databricks. In addition, it would enable the Microsoft team to integrate the amazing column level lineage feature contributed by @Paweł Leszczyński with our solution for Microsoft Purview.
@channel The next OpenLineage Technical Steering Committee meeting is on Thursday, July 14 at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom All are welcome! Agenda:
- Announcements/recent talks
- Release 0.10.0 overview
- Flink integration retrospective
- Discuss: streaming services in Flink integration
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda.

*Thread Reply:* would appreciate a TSC discussion on OL philosophy for Streaming in general and where/if it fits in the vision and strategy for OL. fully appreciate current maturity, moreso just validating how OL is being positioned from a vision perspective. as we consider aligning enterprise lineage solution around OL want to make sure we're not making bad assumptions. neat discussion might be "imagine that Confluent decided to make Stream Lineage OL compliant/capable - are we cool with that and what are the implications?".
*Thread Reply:* @Michael Robinson could I also have a quick 5m to talk about plans for a documentation site?
*Thread Reply:* @David Cecchi @Ross Turk Added your items to the agenda. Thanks and looking forward to the discussion!
*Thread Reply:* this is great - will keep an eye out for recording. if it got tabled due to lack of attendance will pick it up next TSC.

*Thread Reply:* I think OpenLineage should have some representation at https://impactdatasummit.com/2022
I’m happy to help craft the abstract, look over slides, etc. (I could help present, but all I’ve done with OpenLineage is one tutorial, so I’m hardly an expert).
CfP closes 31 Aug so there’s plenty of time, but if you want a 2nd set of eyes on things, we can’t just wait until the last minute to submit 😄
How to create custom facets without recompiling OpenLineage?
I have a customer who is interested in using OpenLineage but wants to extend the facets WITHOUT recompiling OL / maintaining a clone of OL with their changes.
Do we have any examples of how someone might create their own jar but using the OpenLineage CustomFacetBuilder and then have that jar's classes be injected into OpenLineage?
*Thread Reply:* @Michael Collado would you have any thoughts on how to extend the Facets without having to alter OpenLineage itself?
*Thread Reply:* This is described here. Notably:
> Custom implementations are registered by following Java's ServiceLoader conventions. A file called io.openlineage.spark.api.OpenLineageEventHandlerFactory must exist in the application or jar's META-INF/service directory. Each line of that file must be the fully qualified class name of a concrete implementation of OpenLineageEventHandlerFactory. More than one implementation can be present in a single file. This might be useful to separate extensions that are targeted toward different environments - e.g., one factory may contain Azure-specific extensions, while another factory may contain GCP extensions.
*Thread Reply:* This example is present in the test package - https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/tes[…]ervices/io.openlineage.spark.api.OpenLineageEventHandlerFactory
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Michael Collado you are amazing! Thank you so much for pointing me to the docs and example!
@channel @Will Johnson
OpenLineage 0.11.0 is now available!
We added:
• an HTTP option to override timeout and properly close connections in openlineage-java lib,
• dynamic mapped tasks support to the Airflow integration,
• a SqlExtractor to the Airflow integration,
• PMD to Java and Spark builds in CI.
We changed:
• when testing extractors in the Airflow integration, the extractor list length assertion is now dynamic,
• templates are rendered at the start of integration tests for the TaskListener in the Airflow integration.
Thanks to all the contributors who made this release possible!
For the bug fixes and more details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.11.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.10.0...0.11.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Hi all, I am using openlineage-spark in my project where I lock the dependency versions in gradle.lockfile. After release 0.10.0, this is not working. Is this a known limitation of switching to splitting the integration into submodules?
*Thread Reply:* Can you expand on what's not working exactly?
This is not something we're aware of.
*Thread Reply:* @Maciej Obuchowski Sure, I have my own library where I am creating a shadowJar. This includes the open lineage library into the new uber jar. This worked fine till 0.9.0 but now building the shadowJar gives this error
Could not determine the dependencies of task ':shadowJar'.
> Could not resolve all dependencies for configuration ':runtimeClasspath'.
> Could not find spark:app:0.10.0.
Searched in the following locations:
- <https://repo.maven.apache.org/maven2/spark/app/0.10.0/app-0.10.0.pom>
If the artifact you are trying to retrieve can be found in the repository but without metadata in 'Maven POM' format, you need to adjust the 'metadataSources { ... }' of the repository declaration.
Required by:
project : > io.openlineage:openlineage_spark:0.10.0
> Could not find spark:shared:0.10.0.
Searched in the following locations:
- <https://repo.maven.apache.org/maven2/spark/shared/0.10.0/shared-0.10.0.pom>
If the artifact you are trying to retrieve can be found in the repository but without metadata in 'Maven POM' format, you need to adjust the 'metadataSources { ... }' of the repository declaration.
Required by:
project : > io.openlineage:openlineage_spark:0.10.0
> Could not find spark:spark2:0.10.0.
Searched in the following locations:
- <https://repo.maven.apache.org/maven2/spark/spark2/0.10.0/spark2-0.10.0.pom>
If the artifact you are trying to retrieve can be found in the repository but without metadata in 'Maven POM' format, you need to adjust the 'metadataSources { ... }' of the repository declaration.
Required by:
project : > io.openlineage:openlineage_spark:0.10.0
> Could not find spark:spark3:0.10.0.
Searched in the following locations:
- <https://repo.maven.apache.org/maven2/spark/spark3/0.10.0/spark3-0.10.0.pom>
If the artifact you are trying to retrieve can be found in the repository but without metadata in 'Maven POM' format, you need to adjust the 'metadataSources { ... }' of the repository declaration.
Required by:
project : > io.openlineage:openlineage_spark:0.10.0
*Thread Reply:* Can you try 0.11? I think we might already fixed that.
*Thread Reply:* Tried with that as well. Doesn't work
*Thread Reply:* Same error with 0.11.0 as well
*Thread Reply:* I think I see - we removed internal dependencies from maven's pom.xml but we also publish gradle metadata: https://repo1.maven.org/maven2/io/openlineage/openlineage-spark/0.11.0/openlineage-spark-0.11.0.module
*Thread Reply:* we should remove the dependencies or disable the gradle metadata altogether, it's not required
*Thread Reply:* @Varun Singh For now I think you can try ignoring gradle metadata: https://docs.gradle.org/current/userguide/declaring_repositories.html#sec:supported_metadata_sources

*Thread Reply:* @Varun Singh did you find out how to build shadowJar successful with release 0.10.0. I can build shadowJar with 0.9.0, but not higher version. If your problem already resolved, could you share some suggestion. thanks ^^
*Thread Reply:* @Hanbing Wang I followed @Maciej Obuchowski's instructions (Thank you!) and added this to my build.gradle file:
repositories {
mavenCentral() {
metadataSources {
mavenPom()
ignoreGradleMetadataRedirection()
}
}
}
I am able to build the jar now. I am not proficient in gradle so don't know if this is the right way to do this. Please correct me if I am wrong.
*Thread Reply:* Also, I am not able to see the 3rd party dependencies in the dependency lock file, but they are present in some folder inside the jar (relocated in subproject's build file). But this is a different problem ig
*Thread Reply:* Thanks @Varun Singh for the very helpful info. I will also try update build.gradle and rebuild shadowJar again.
Java Question: Why Can't I Find a Class on the Class Path? / How the heck does the ClassLoader know where to find a class?
Are there any java pros that would be willing to share alternatives to searching if a given class exists or help explain what should change in the Kusto package to make it work for the behaviors as seen in Kafka and SQL DW relation visitors? --- Details --- @Hanna Moazam and I are trying to introduce two new Azure data sources into OpenLineage's Spark integration. The https://github.com/Azure/azure-kusto-spark package is nearly done but we're getting tripped up on some Java concepts. In order to know if we should add the KustoRelationVisitor to the input dataset visitors, we need to see if the Kusto jar is installed on the spark / databricks cluster. In this case, the com.microsoft.kusto.spark.datasource.DefaultSource is a public class but it cannot be found using the KustRelationVisitor.class.getClassLoader().loadClass("class name") methods as seen in:
• https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/[…]nlineage/spark/agent/lifecycle/plan/SqlDWDatabricksVisitor.java • https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/[…]penlineage/spark/agent/lifecycle/plan/KafkaRelationVisitor.java At first I thought it was the Azure packages but then I tried to do the same approach with a simple java library
I instantiate a spark-shell like this
spark-shell --master local[4] \
--conf spark.driver.extraClassPath=/mnt/repos/SparkListener-Basic/lib/build/libs/custom-listener.jar \
--conf spark.extraListeners=listener.MyListener
--jars /mnt/repos/wjtestlib/lib/build/libs/lib.jar
With lib.jar containing a class that looks like this:
```package wjtestlib;
public class WillLibrary {
public boolean someLibraryMethod() {
return true;
}
}
And the custom listener is very simple.
public class MyListener extends org.apache.spark.scheduler.SparkListener {
private static final Logger log = LoggerFactory.getLogger("MyLogger");
public MyListener() { log.info("INITIALIZING"); }
@Override public void onJobStart(SparkListenerJobStart jobStart) { log.info("MYLISTENER: ON JOB START"); try{ log.info("Trying wjtestlib.WillLibrary"); MyListener.class.getClassLoader().loadClass("wjtestlib.WillLibrary"); log.info("Got wjtestlib.WillLibrary"); } catch(ClassNotFoundException e){ log.info("Could not get wjtestlib.WillLibrary"); }
try{
<a href="http://log.info">log.info</a>("Trying wjtestlib.WillLibrary using Class.forName");
Class.forName("wjtestlib.WillLibrary", false, this.getClass().getClassLoader());
<a href="http://log.info">log.info</a>("Got wjtestlib.WillLibrary using Class.forName");
} catch(ClassNotFoundException e){
<a href="http://log.info">log.info</a>("Could not get wjtestlib.WillLibrary using Class.forName");
}
}
}
And I still a result indicating it cannot find the class.
2022-07-12 23:58:22,048 INFO MyLogger: MYLISTENER: ON JOB START
2022-07-12 23:58:22,048 INFO MyLogger: Trying wjtestlib.WillLibrary
2022-07-12 23:58:22,057 INFO MyLogger: Could not get wjtestlib.WillLibrary
2022-07-12 23:58:22,058 INFO MyLogger: Trying wjtestlib.WillLibrary using Class.forName
2022-07-12 23:58:22,065 INFO MyLogger: Could not get wjtestlib.WillLibrary using Class.forName```
Are there any java pros that would be willing to share alternatives to searching if a given class exists or help explain what should change in the Kusto package to make it work for the behaviors as seen in Kafka and SQL DW relation visitors?
Thank you for any guidance.!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Could you unzip the created jar and verify that classes you’re trying to use are present? Perhaps there’s some relocate in shadowJar plugin, which renames the classes. Making sure the classes are present in jar good point to start.
Then you can try doing classForName just from the spark-shell without any listeners added. The classes should be available there.
*Thread Reply:* Thank you for the reply Pawel! Hanna and I just wrapped up some testing.
It looks like Databricks AND open source spark does some magic when you install a library OR use --jars on the spark-shell. In both Databricks and Apache Spark, the thread running the SparkListener cannot see the additional libraries installed unless they're on the original / main class path.
• Confirmed the uploaded jars are NOT shaded / renamed. • The databricks class path ($CLASSPATH) is focused on /databricks/jars • The added libraries are in /local_disk0/tmp and are not found in $CLASSPATH. • The sparklistener only recognizes $CLASSPATH. • Using a classloader with an object like spark does not find our installed class: spark.getClass().getClassLoader().getResource("com/microsoft/kusto/spark/datasource/KustoSourceOptions.class") • When we use a classloader on a class we installed and imported, it DOES find the class. myImportedClass.getClass().getClassLoader().getResource("com/microsoft/kusto/spark/datasource/KustoSourceOptions.class") @Michael Collado and @Maciej Obuchowski have you seen any challenges with using --jars on the spark-shell and detecting if the class is installed?
*Thread Reply:* We run tests using --packages for external stuff like Delta - which is the same as --jars , but getting them from maven central, not local disk, and it works, like in KafkaRelationVisitor.
What if you did it like it? By that I mean adding it to your code with compileOnly in gradle or provided in maven, compiling with it, then using static method to check if it loads?
*Thread Reply:* > • When we use a classloader on a class we installed and imported, it DOES find the class. myImportedClass.getClass().getClassLoader().getResource("com/microsoft/kusto/spark/datasource/KustoSourceOptions.class") Isn't that this actual scenario?
*Thread Reply:* Thank you for the reply, Maciej!
I will try the compileOnly route tonight!
Re: myImportedClass.getClass().getClassLoader().getResource("com/microsoft/kusto/spark/datasource/KustoSourceOptions.class")
I failed to mention that this was only achieved in the interactive shell / Databricks notebook. It never worked inside the SparkListener UNLESS we installed the Kusto jar on the databricks class path.
*Thread Reply:* The difference between --jars and --packages is that for packages all transitive dependencies will be handled. But this does not seem to be the case here.
More doc can be found here: (https://spark.apache.org/docs/latest/submitting-applications.html#advanced-dependency-management)
When starting a SparkContext, all the jars available on the classpath should be listed and put into Spark logs. So that’s the place one can check if the jar is loaded or not.
If --conf spark.driver.extraClassPath is working, you can add multiple jar files there (they must be separated by commas).
Other examples of adding multiple jars to spark classpath can be found here -> https://sparkbyexamples.com/spark/add-multiple-jars-to-spark-submit-classpath/
*Thread Reply:* @Paweł Leszczyński thank you for the reply! Hanna and I experimented with jars vs extraClassPath.
When using jars, the spark listener does NOT find the class using a classloader.
When using extraClassPath, the spark listener DOES find the class using a classloader.
When using --jars, we can see in the spark logs that after spark starts (and after the spark listener is already established?) there are Spark.AddJar commands being executed.
@Maciej Obuchowski we also experimented with doing a compileOnly on OpenLineage's spark listener, it did not change the behavior. OpenLineage still failed to identify that I had the kusto-spark-connector.
I'm going to reach out to Databricks to see if there is any guidance on letting the SparkListener be aware of classes added via their libraries / --jar method on the spark-shell.
*Thread Reply:* So, this is only relevant to Databricks now? Because I don't understand what do you do different than us with Kafka/Iceberg/Delta
*Thread Reply:* I'm not the spark/classpath expert though - maybe @Michael Collado have something to add?
*Thread Reply:* @Maciej Obuchowski that's a super good question on Iceberg. How do you instantiate a spark job with Iceberg installed?
*Thread Reply:* It is still relevant to apache spark because I can't get OpenLineage to find the installed package UNLESS I use extraClassPath.
*Thread Reply:* Basically, by adding --packages org.apache.iceberg:iceberg_spark_runtime_3.1_2.12:0.13.0
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Using --packages wouldn't let me find the Spark relation's default source:
Spark Shell command
spark-shell --master local[4] \
--conf spark.driver.extraClassPath=/customListener-1.0-SNAPSHOT.jar \
--conf spark.extraListeners=listener.MyListener \
--jars /WillLibrary.jar \
--packages com.microsoft.azure.kusto:kusto_spark_3.0_2.12:3.0.0
Code inside customListener:
try{
<a href="http://log.info">log.info</a>("Trying Kusto DefaultSource");
MyListener.class.getClassLoader().loadClass("com.microsoft.kusto.spark.datasource.DefaultSource");
<a href="http://log.info">log.info</a>("Got Kusto DefaultSource!!!!");
} catch(ClassNotFoundException e){
<a href="http://log.info">log.info</a>("Could not get Kusto DefaultSource");
}
Logs indicating it still can't find the class when using --packages.
2022-07-14 10:47:35,997 INFO MyLogger: MYLISTENER: ON JOB START
2022-07-14 10:47:35,997 INFO MyLogger: Trying wjtestlib.WillLibrary
2022-07-14 10:47:36,000 INFO 2022-07-14 10:47:36,052 INFO MyLogger: Trying LogicalRelation
2022-07-14 10:47:36,053 INFO MyLogger: Got logical relation
2022-07-14 10:47:36,053 INFO MyLogger: Trying Kusto DefaultSource
2022-07-14 10:47:36,064 INFO MyLogger: Could not get Kusto DefaultSource
😢
*Thread Reply:* what if you load your listener using also packages?
*Thread Reply:* That's how I'm doing it locally using spark.conf:
spark.jars.packages com.google.cloud.bigdataoss:gcs_connector:hadoop3-2.2.2,io.delta:delta_core_2.12:1.0.0,org.apache.iceberg:iceberg_spark3_runtime:0.12.1,io.openlineage:openlineage_spark:0.9.0
*Thread Reply:* @Maciej Obuchowski - You beautiful bearded man!
🙏
2022-07-14 11:14:21,266 INFO MyLogger: Trying LogicalRelation
2022-07-14 11:14:21,266 INFO MyLogger: Got logical relation
2022-07-14 11:14:21,266 INFO MyLogger: Trying org.apache.iceberg.catalog.Catalog
2022-07-14 11:14:21,295 INFO MyLogger: Got org.apache.iceberg.catalog.Catalog!!!!
2022-07-14 11:14:21,295 INFO MyLogger: Trying Kusto DefaultSource
2022-07-14 11:14:21,361 INFO MyLogger: Got Kusto DefaultSource!!!!
I ended up setting my spark-shell like this (and used --jars for my custom spark listener since it's not on Maven).
spark-shell --master local[4] \
--conf spark.extraListeners=listener.MyListener \
--packages org.apache.iceberg:iceberg_spark_runtime_3.1_2.12:0.13.0,com.microsoft.azure.kusto:kusto_spark_3.0_2.12:3.0.0 \
--jars customListener-1.0-SNAPSHOT.jar
So, now I just need to figure out how Databricks differs from this approach 😢
*Thread Reply:* This is an annoying detail about Java ClassLoaders and the way Spark loads extra jars/packages
Remember Java's ClassLoaders are hierarchical - there are parent ClassLoaders and child ClassLoaders. Parents can't see their children's classes, but children can see their parent's classes.
When you use --spark.driver.extraClassPath , you're adding a jar to the main application ClassLoader. But when you use --jars or --packages, you're instructing the Spark application itself to load the extra jars into its own ClassLoader - a child of the main application ClassLoader that the Spark code creates and manages separately. Since your listener class is loaded by the main application ClassLoader, it can't see any classes that are loaded by the Spark child ClassLoader. Either both jars need to be on the driver classpath or both jars need to be loaded by the --jar or --packages configuration parameter
*Thread Reply:* In Databricks, we were not able to simply use the --packages argument to load the listener, which is why we have that init script that copies the jar into the classpath that Databricks uses for application startup (the main ClassLoader). You need to copy your visitor jar into the same location so that both jars are loaded by the same ClassLoader and can see each other
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* (as an aside, this is one of the major drawbacks of the java agent approach and one reason why all the documentation recommends using the spark.jars.packages configuration parameter for loading the OL library - it guarantees that any DataSource nodes loaded by the Spark ClassLoader can be seen by the OL library and we don't have to use reflection for everything)
*Thread Reply:* @Michael Collado Thank you so much for the reply. The challenge is that Databricks has their own mechanism for installing libraries / packages.
https://docs.microsoft.com/en-us/azure/databricks/libraries/
These packages are installed on databricks AFTER spark is started and the physical files are located in a folder that is different than the main classpath.
I'm going to reach out to Databricks and see if we can get any guidance on this 😢
*Thread Reply:* Unfortunately, I can't ask users to install their packages on Databricks in a non-standard way (e.g. via an init script) because no one will follow that recommendation.
*Thread Reply:* yeah, I'd prefer if we didn't need an init script to get OL on Databricks either 🤷♂️:skintone4:
*Thread Reply:* Quick update: • Turns out using a class loader from a Scala spark listener does not have this problem. • https://stackoverflow.com/questions/7671888/scala-classloaders-confusion • I'm trying to use URLClassLoader as recommended by a few MSFT folks and point it at the /local_disk0/tmp folder. • https://stackoverflow.com/questions/17724481/set-classloader-different-directory • I'm not having luck so far but hoping I can reason about it tomorrow and Monday. This is blocking us from adding additional data sources that are not pre-installed on databricks 😢
*Thread Reply:* Can't help you now, but I'd love if you dumped the knowledge you've gained through this process into some doc on new OpenLineage doc site 🙏

*Thread Reply:* We'll definitely put all of it together as a reference for others, and hopefully have a solution by the end of it too
@channel The next OpenLineage TSC meeting is tomorrow at 10 am PT! https://openlineage.slack.com/archives/C01CK9T7HKR/p1657204421157959
check this out folks - marklogic datahub flow lineage into OL/marquez with jobs and runs and more. i would guess this is a pretty narrow use case but it went together really smoothly and thought i'd share sometimes it's just cool to see what people are working on
*Thread Reply:* Soo cool, @David Cecchi 💯💯💯. I’m not familiar with marklogic, but pretty awesome ETL platform and the lineage graph looks 👌! Did you have to write any custom integration code? Or where you able to use our off the self integrations to get things working? (Also, thanks for sharing!)
*Thread Reply:* team had to write some custom stuff but it's all framework so it can be repurposed not rewritten over and over. i would see this as another "Platform" in the context of the integrations semantic OL uses, so no, we didn't start w/ an existing solution. just used internal hooks and then called lineage APIs.
*Thread Reply:* Ah totally make sense. Would you be open to a brief presentation and/or demo in a future OL community meeting? The community is always looking to hear how OL is used in the wild, and this seems aligned with that (assuming you can talk about the implementation at a high-level)
*Thread Reply:* ha not feeling any pressure. familiar with the intentions and dynamic. let's keep that on radar - i don't keep tabs on community meetings but mid/late august would be workable. and to be clear, this is being used in the wild in a sandbox 🙂.
*Thread Reply:* Sounds great, and a reasonable timeline! (cc @Michael Robinson can follow up). Even if it’s in a sandbox, talking about the level of effort helps with improving our APIs or sharing with others how smooth it can be!
*Thread Reply:* chiming in as well to say this is really cool 👍
*Thread Reply:* Nice! Would this become a product feature in Marklogic Data Hub?

*Thread Reply:* MarkLogic is a multi-model database and search engine. This implementation triggers off the MarkLogic Datahub Github batch records created when running the datahub flows. Just a toe in the water so far.
@Ross Turk, in the OL community meeting today, you presented the new doc site (awesome!) that isn’t up (yet!), but I’ve been talk with @Julien Le Dem about the usage of _producer and would like to add a section on the use / function of _producer in OL events. Feel like the new doc site would be a great place to add this! Let me know when’s a good time to start crowd sourcing content for the site
*Thread Reply:* That sounds like a good idea to me. Be good to have some guidance on that.
The repo is open for business! Feel free to add the page where you think it fits.
*Thread Reply:* @Ross Turk, feel free to assign to me https://github.com/OpenLineage/docs/issues/1!
<a href="https://github.com/OpenLineage/docs">OpenLineage/docs</a>
Hey everyone! As Willy says, there is a new documentation site for OpenLineage in the works.
It’s not quite ready to be, uh, a proper reference yet. But it’s not too far away. Help us get there by submitting issues, making page stubs, and adding sections via PR.
https://github.com/openlineage/docs/
*Thread Reply:* Thanks, @Ross Turk for finding a home for more technical / how-to docs… long overdue 💯
*Thread Reply:* BTW you can see the current site at http://openlineage.io/docs/ - merges to main will ship a new site.
*Thread Reply:* great, was using <a href="http://docs.openlineage.io">docs.openlineage.io</a> … we’ll eventually want the docs to live under the docs subdomain though?
*Thread Reply:* TBH I activated GitHub Pages on the repo expecting it to live at openlineage.github.io/docs, thinking we could look at it there before it's ready to be published and linked in to the website
*Thread Reply:* and it came live at openlineage.io/docs 😄
*Thread Reply:* still do not understand why, but I'll take it as a happy accident. we can move to docs.openlineage.io easily - just need to add the A record in the LF infra + the CNAME file in the static dir of this repo
Hi #general, how do i link the tasks of airflow which may not have any input or output datasets as they are running some conditions. the dataset is generated only on the last task
In the lineage, though there is option to link the parent , it doesnt show up the lineage of job -> job
*Thread Reply:* yes - openlineage is job -> dataset -> job. particularly, the model is designed to observe the movement of data
*Thread Reply:* the spec is based around run events, which are observed states of job runs. jobs are observed to see how they affect datasets, and that relationship is what OpenLineage traces
i am looking for some information regarding openlineage integration with AWS Glue jobs/workflows
i am wondering if it possible and someone already give a try and maybe documented it?

*Thread Reply:* This thread covers glue in some detail: https://openlineage.slack.com/archives/C01CK9T7HKR/p1637605977118000?threadts=1637605977.118000&cid=C01CK9T7HKR|https://openlineage.slack.com/archives/C01CK9T7HKR/p1637605977118000?threadts=1637605977.118000&cid=C01CK9T7HKR
 }
}
*Thread Reply:* TL;Dr: you can use the spark integration to capture some lineage, but it's not comprehensive
*Thread Reply:* i suspect there will be opportunities to influence AWS to be a "fast follower" if OL adoption and buy-in starts to feel authentically real in non-aws portions of the stack. i discussed OL casually with AWS analytics leadership (Rahul Pathak) last winter and he seemed curious and open to this type of idea. to be clear, ~95% chance he's forgotten that conversation now but hey it's still something.
*Thread Reply:* There are a couple of aws people here (including me) following.

Hi all, I have been playing around with Marquez for a hackday. I have been able to get some lineage information loaded in (using the local docker version for now). I have been trying set the location (for the link) and description information for a job (the text saying "Nothing to show here") but I haven't been able to figure out how to do this using the /lineage api. Any help would be appreciated.
*Thread Reply:* I believe what you want is the DocumentationJobFacet. It adds a description property to a job.
*Thread Reply:* You can see a Python example here, in the Airflow integration: https://github.com/OpenLineage/OpenLineage/blob/65a5f021a1ba3035d5198e759587737a05b242e1/integration/airflow/openlineage/airflow/adapter.py#L217
*Thread Reply:* I see, so there are special facet keys which will get translated into something special in the ui, is that correct?
Are these documented anywhere?
*Thread Reply:* Correct - info from the various OpenLineage facets are used in the Marquez UI.
*Thread Reply:* I couldn’t find a curl example with a description field, but I did generate this one with a sql field:
{
"job": {
"name": "order_analysis.find_popular_products",
"facets": {
"sql": {
"query": "DROP TABLE IF EXISTS top_products;\n\nCREATE TABLE top_products AS\nSELECT\n product,\n COUNT(order_id) AS num_orders,\n SUM(quantity) AS total_quantity,\n SUM(price ** quantity) AS total_value\nFROM\n orders\nGROUP BY\n product\nORDER BY\n total_value desc,\n num_orders desc;",
"_producer": "https: //github.com/OpenLineage/OpenLineage/tree/0.11.0/integration/airflow",
"_schemaURL": "<https://raw.githubusercontent.com/OpenLineage/OpenLineage/main/spec/OpenLineage.json#/definitions/SqlJobFacet>"
}
},
"namespace": "workshop"
},
"run": {
"runId": "13460e52-a829-4244-8c45-587192cfa009",
"facets": {}
},
"inputs": [
...
],
"outputs": [
...
],
"producer": "<https://github.com/OpenLineage/OpenLineage/tree/0.11.0/integration/airflow>",
"eventTime": "2022-07-20T00: 23: 06.986998Z",
"eventType": "COMPLETE"
}
*Thread Reply:* The facets (at least, those in the core spec) are here: https://github.com/OpenLineage/OpenLineage/tree/65a5f021a1ba3035d5198e759587737a05b242e1/spec/facets
*Thread Reply:* it’s designed so that facets can exist outside the core, in other repos, as well
*Thread Reply:* Thank you for sharing these, I was able to get the sql query highlighting to work. But I failed to get the location link or the documentation to work. My facet attempt looked like:
{
"facets": {
"description": "test-description-job",
"sql": {
"query": "SELECT QUERY",
"_schema": "<https://raw.githubusercontent.com/OpenLineage/OpenLineage/main/spec/OpenLineage.json#/definitions/SqlJobFacet>"
},
"documentation": {
"documentation": "Test docs?",
"_schema": "<https://raw.githubusercontent.com/OpenLineage/OpenLineage/main/spec/OpenLineage.json#/definitions/DocumentationJobFacet>"
},
"link": {
"type": "",
"url": "<a href="http://www.google.com/test_url">www.google.com/test_url</a>",
"_schema": "<https://raw.githubusercontent.com/OpenLineage/OpenLineage/main/spec/OpenLineage.json#/definitions/SourceCodeLocationJobFacet>"
}
}
}
*Thread Reply:* I got the documentation link to work by renaming the property from documentation -> description . I still haven't been able to get the external link to work
Hey all. I've been doing a cleanup of issues on GitHub. If I've closed your issue that you think is still relevant, please reopen it and let us know.
Is https://databricks.com/blog/2022/06/08/announcing-the-availability-of-data-lineage-with-unity-catalog.html - are they using OpenLineage? I know there’s been a lot of work to make sure OpenLineage integrates with Databricks, even earlier this year.

*Thread Reply:* There’s a good integration between OL and Databricks for pulling metadata out of running Spark clusters. But there’s not currently a connection between OL and the Unity Catalog.
I think it would be cool to see some discussions start to develop around it 👍
*Thread Reply:* Absolutely. I saw some mention of APIs and access, and was wondering if maybe they used OpenLineage as a framework, which would be awesome.
*Thread Reply:* (and since Azure Databricks uses it - https://openlineage.io/blog/openlineage-microsoft-purview/ I wasn’t sure about Unity Catalog)
*Thread Reply:* We're in the early stages of discussion regarding an OpenLineage integration for Unity. You showing interest would help increase the priority of that on the DB side.

*Thread Reply:* I'm interested in Databricks enabling an openlineage endpoint, serving as a catalogue. Similar to how they provide hosted MLFlow. I can mention this to our Databricks reps as well

Hi all I am trying to find the state of columnLineage in OL I see a proposal and some examples in https://github.com/OpenLineage/OpenLineage/search?q=columnLineage&type=|https://github.com/OpenLineage/OpenLineage/search?q=columnLineage&type= but I can't find it in the spec. Can anyone shed any light why this would be the case?
*Thread Reply:* Link to spec where I looked https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.json
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* My bad. I realize now that column lineage has been implemented as a facet, hence not visible in the main spec https://github.com/OpenLineage/OpenLineage/search?q=ColumnLineageDatasetFacet&type=|https://github.com/OpenLineage/OpenLineage/search?q=ColumnLineageDatasetFacet&type=
*Thread Reply:* It is supported in the Spark integration
*Thread Reply:* @Paweł Leszczyński could you add the Column Lineage facet here in the spec? https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md#standard-facets
SundayFunday
Putting together some internal training for OpenLineage and highlighting some of the areas that have been useful to me on my journey with OpenLineage. Many thanks to @Michael Collado, @Maciej Obuchowski, and @Paweł Leszczyński for the continued technical support and guidance.
*Thread Reply:* @Ross Turk I still want to contribute something like this to the OpenLineage docs / new site but the bar for an internal doc is lower in my mind 😅
*Thread Reply:* @Will Johnson happy to help you with docs, when the time comes! sketching outline --> editing, whatever you need
*Thread Reply:* This looks nice by the way.

hi all, really appreciate if anyone could help. I have been trying to create a poc project with openlineage with dbt. attached will be the pip list of the openlineage packages that i have. However, when i run "dbt-ol"command, it prompted as öpen as file, instead of running as a command. the regular dbt run can be executed without issue. i would want i had done wrong or if any configuration that i have missed. Thanks a lot
*Thread Reply:* do you have proper execute permissions?
*Thread Reply:* not sure how that works on windows, but it just looks like it does not recognize dbt-ol as executable
*Thread Reply:* yes i have admin rights. how to make this as executable?
*Thread Reply:* btw do we have a sample docker image where dbt-ol can run?
*Thread Reply:* I have also never tried on Windows 😕 but you might try python3 dbt-ol run?
Running a single unit test on the Spark Integration - How it works with the different modules?
Prior to splitting up the OpenLineage spark integration, I could run a command like the one below to test a single test or even a single test method. Now I get a failure and it's pointing to the app: module. Can anyone share the right syntax for running a unit test with the current package structure? Thank you!!
```wj@DESKTOP-ECF9QME:~/repos/OpenLineageWill/integration/spark$ ./gradlew test --tests io.openlineage.spark.agent.OpenLineageSparkListenerTest
> Task :app:test FAILED
SUCCESS: Executed 0 tests in 872ms
FAILURE: Build failed with an exception.
** What went wrong: Execution failed for task ':app:test'. > No tests found for given includes: io.openlineage.spark.agent.OpenLineageSparkListenerTest
** Try: > Run with --stacktrace option to get the stack trace. > Run with --info or --debug option to get more log output. > Run with --scan to get full insights.
** Get more help at https://help.gradle.org
Deprecated Gradle features were used in this build, making it incompatible with Gradle 8.0.
You can use '--warning-mode all' to show the individual deprecation warnings and determine if they come from your own scripts or plugins.
See https://docs.gradle.org/7.4/userguide/command_line_interface.html#sec:command_line_warnings
BUILD FAILED in 2s 18 actionable tasks: 4 executed, 14 up-to-date```
*Thread Reply:* This may be a result of splitting Spark integration into multiple submodules: app, shared, spark2, spark3, spark32, etc. If the test case is from shared submodule (this one looks like that), you could try running:
./gradlew :shared:test --tests io.openlineage.spark.agent.OpenLineageSparkListenerTest
*Thread Reply:* @Paweł Leszczyński, I tried running that command, and I get the following error:
```> Task :shared:test FAILED
FAILURE: Build failed with an exception.
** What went wrong: Execution failed for task ':shared:test'. > No tests found for given includes: io.openlineage.spark.agent.OpenLineageSparkListenerTest
** Try: > Run with --stacktrace option to get the stack trace. > Run with --info or --debug option to get more log output. > Run with --scan to get full insights.
** Get more help at https://help.gradle.org
Deprecated Gradle features were used in this build, making it incompatible with Gradle 8.0.
You can use '--warning-mode all' to show the individual deprecation warnings and determine if they come from your own scripts or plugins.
See https://docs.gradle.org/7.4/userguide/command_line_interface.html#sec:command_line_warnings
BUILD FAILED in 971ms 6 actionable tasks: 2 executed, 4 up-to-date```
*Thread Reply:* When running build and test for all the submodules, I can see outputs for tests in different submodules (spark3, spark2 etc), but for some reason, I cannot find any indication that the tests in
OpenLineage/integration/spark/app/src/test/java/io/openlineage/spark/agent/lifecycle/plan
are being run at all.
*Thread Reply:* That’s interesting. Let’s ask @Tomasz Nazarewicz about that.
*Thread Reply:* For reference, I attached the stdout and stderr messages from running the following:
./gradlew :shared:spotlessApply && ./gradlew :app:spotlessApply && ./gradlew clean build test

*Thread Reply:* I'll look into it
*Thread Reply:* Update: some test appeared to not be visible after split, that's fixed but now I have to solevr some dependency issues
*Thread Reply:* That's great, thank you!
*Thread Reply:* Hi Tomasz, thanks so much for looking into this. Is this your PR (https://github.com/OpenLineage/OpenLineage/pull/953) that fixes the whole issue, or is there still some work to do to solve the dependency issues you mentioned?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I'm still testing it, should've changed it to draft, sorry
*Thread Reply:* No worries! If I can help with testing or anything please let me know!
*Thread Reply:* Will do! Thanks :)
*Thread Reply:* Hi @Tomasz Nazarewicz, if possible, could you please share an estimated timeline for resolving the issue? We have 3 PRs which we are either waiting to open or to update which are dependent on the tests.
*Thread Reply:* @Hanna Moazam hi, it's quite difficult to do that because the issue is that all the tests are passing when I execute ./gradlew app:test
but one is failing with ./gradlew app:build
but if it fixes your problem I can disable this test for now and make a PR without it, then you can maybe unblock your stuff and I will have more time to investigate the issue.
*Thread Reply:* Oh that's a strange issue. Yes that would be really helpful if you can, because we have some tests we implemented which we need to make sure pass as expected.
*Thread Reply:* Thank you for your help Tomasz!
*Thread Reply:* @Hanna Moazam https://github.com/OpenLineage/OpenLineage/pull/980 here is the pull request with the changes
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* its waiting for review currently
Is there any doc yet about column level lineage? I see a spec for the facet here: https://github.com/openlineage/openlineage/issues/148
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* The doc site would benefit from a page about it. Maybe @Paweł Leszczyński?
*Thread Reply:* Sure, it’s already on my list, will do
*Thread Reply:* https://openlineage.io/docs/integrations/spark/spark_column_lineage
maybe another question for @Paweł Leszczyński: I was watching the Airflow summit talk that you and @Maciej Obuchowski did ( very nice! ). How is this exposed? I'm wondering if it shows up as an edge on the graph in Marquez? ( I guess it may be tracked as a parent run and if so probably does not show on the graph directly at this time? )
*Thread Reply:* To be honest, I have never seen that in action and would love to have that in our documentation.
@Michael Collado or @Maciej Obuchowski: are you able to create some doc? I think one of you was working on that.
*Thread Reply:* Yes, parent run
Hi #general, there has been a issue with airflow+dbt+openlineage. This was working fine with openlineage-dbt v0.11.0 but there has been some change to the typeextensions due to which i had to upgrade to latest dbt (from 1.0.0 to 1.1.0) and now the dbt-ol is failing with schema version support (the version generated is v5 vs dbt-ol supports only v4). Has anyone else been able to fix this
*Thread Reply:* Will take a look
*Thread Reply:* But generally this support message is just a warning
*Thread Reply:* @shweta p any actual error you've found? I've tested it with dbt-bigquery on 1.1.0 and it works despite warning:
➜ small OPENLINEAGE_URL=<http://localhost:5050> dbt-ol build
Running OpenLineage dbt wrapper version 0.11.0
This wrapper will send OpenLineage events at the end of dbt execution.
14:03:16 Running with dbt=1.1.0
14:03:17 Found 2 models, 3 tests, 0 snapshots, 0 analyses, 191 macros, 0 operations, 0 seed files, 0 sources, 0 exposures, 0 metrics
14:03:17
14:03:17 Concurrency: 2 threads (target='dev')
14:03:17
14:03:17 1 of 5 START table model dbt_test1.my_first_dbt_model .......................... [RUN]
14:03:21 1 of 5 OK created table model dbt_test1.my_first_dbt_model ..................... [CREATE TABLE (2.0 rows, 0 processed) in 3.31s]
14:03:21 2 of 5 START test unique_my_first_dbt_model_id ................................. [RUN]
14:03:22 2 of 5 PASS unique_my_first_dbt_model_id ....................................... [PASS in 1.55s]
14:03:22 3 of 5 START view model dbt_test1.my_second_dbt_model .......................... [RUN]
14:03:24 3 of 5 OK created view model dbt_test1.my_second_dbt_model ..................... [OK in 1.38s]
14:03:24 4 of 5 START test not_null_my_second_dbt_model_id .............................. [RUN]
14:03:24 5 of 5 START test unique_my_second_dbt_model_id ................................ [RUN]
14:03:25 5 of 5 PASS unique_my_second_dbt_model_id ...................................... [PASS in 1.38s]
14:03:25 4 of 5 PASS not_null_my_second_dbt_model_id .................................... [PASS in 1.42s]
14:03:25
14:03:25 Finished running 1 table model, 3 tests, 1 view model in 8.44s.
14:03:25
14:03:25 Completed successfully
14:03:25
14:03:25 Done. PASS=5 WARN=0 ERROR=0 SKIP=0 TOTAL=5
Artifact schema version: <https://schemas.getdbt.com/dbt/manifest/v5.json> is above dbt-ol supported version 4. This might cause errors.
Emitting OpenLineage events: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:00<00:00, 274.42it/s]
Emitted 10 openlineage events
When will the next version of OpenLineage be available tentatively?
*Thread Reply:* I think it's safe to say we'll see a release by the end of next week

👋 Hi everyone! Yesterday was a great presentation by @Julien Le Dem that talked about OpenLineage and did grate comparison between OL and Open-Telemetry, (i wrote a small summary here: https://bit.ly/3z5caOI )
Julian’s charm sparked inside me curiosity especially regarding OL in streaming. I saw the design/architecture of OL I got some questions/discussions that I would like to understand better.
In the context of streaming jobs reporting “start job” - “end job” might be more relevant in the context of a batch mode. or do you mean reporting start job/end job should be processed each event?
- and this will be equivalent to starting job each row in a table via UDF, for example.
Thank you in advance

*Thread Reply:* Welcome to the community!
We talked about this exact topic in the most recent community call. https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting#MonthlyTSCmeeting-Nextmeeting:Nov10th2021(9amPT)
Discussion: streaming in Flink integration • Has there been any evolution in the thinking on support for streaming? ◦ Julien: start event, complete event, snapshots in between limited to certain number per time interval ◦ Paweł: we can make the snapshot volume configurable • Does Flink support sending data to multiple tables like Spark? ◦ Yes, multiple outputs supported by OpenLineage model ◦ Marquez, the reference implementation of OL, combines the outputs
*Thread Reply:* > or do you mean reporting start job/end job should be processed each event? We definitely want to avoid tracking every single event 🙂
One thing worth mentioning is that OpenLineage events are meant to be cumulative - the streaming jobs start, run, and eventually finish or restart. In the meantime, we capture additional events "in the middle" - for example, on Apache Flink checkpoint, or every few minutes - where we can emit additional information connected to the state of the job.
*Thread Reply:* @Will Johnson and @Maciej Obuchowski Thank you for your answer
jobs start, run, and eventually finish or restart
This is the perspective that I have a hard time understanding in the context of streaming.
The classic streaming job should always be on it should not be “finish” event (Except failure). usually, streaming data is “dripping”.
It is possible to understand if the job starts/ends in the resolution of the running application and represents when the application begin and when it failed.
if you do start/stop events from the checkpoints on Flink it might be the wrong representation instead use the concept of event-driven for example reporting state.
What do you think?
*Thread Reply:* The idea is that jobs usually get upgraded - for example, you change Apache Flink version, increase resources, or change the structure of a job - that's the difference for us. The stop events make sense, because if you for example changed SQL of your Flink SQL job, you probably would want this to be captured - from X to Y job was running with older SQL version well, but after change, the second run started and throughput dropped to 10% of the previous one.
> if you do start/stop events from the checkpoints on Flink it might be the wrong representation instead use the concept of event-driven for example reporting state. But this is an misunderstanding 🙂 The information exposed from a checkpoints are in addition to start and stop events.
We want to get information from running job - I just argue that sometimes end of a streaming job is also relevant.
*Thread Reply:* The checkpoint would be captured as a new eventType: RUNNING - do I miss something why you want to add StateFacet?
*Thread Reply:* About argue - it’s depends on what the definition of job in streaming mode, i agree that if you already have ‘job’ you want to know about the job more information.
each event that entering the sub process (job) should do REST call “Start job” and “End job” ?
Nope, I just represented two possible ways that i thought, or StateFacet or add new Event type eg. RUNNING 😉
Hi everyone, I’d like to request a release to publish the new Flink integration (thanks, @Maciej Obuchowski) and an important fix to the Spark integration (thanks, @Paweł Leszczyński). As per our policy here, 3 +1s from committers will authorize an immediate release. Thanks!
*Thread Reply:* Thanks for the +1s. We will initiate the release by Tuesday.

Static code annotations for OpenLineage: hi everyone, i heard yesterday a great lecture by @Julien Le Dem on OpenLineage, and as i'm very interested in this area, i wanted to raise a question: are there any plans to have OpenLineage-like annotations on actual code (e.g. Spark, AirFlow, arbitrary code) to allow deducing some of the lineage informtion from static code analysis?
The reason i'm asking this is because while OpenLineage does a great job of integrating with multiple platforms (AirFlow, Dbt, Spark), some companies still have a lot of legacy-related data processing stack that will probably not get full OpenLineage (as it's a one-off, and the companies themselves will probably won't implement OpenLineage support for their custom frameworks). Having some standard way to annotate code with information like: "reads from X; writes to Y; Job name regexp: Z", may allow writing a "generic" OpenLineage colelctor that can go over the source code, collect this configuration information and then use it when constructing the lineage graph (even though it won't be as complete and full as the full OpenLineage info).
*Thread Reply:* I think this is an interesting idea, however, just the static analysis does not convey any runtime information.
We're doing something similar within Airflow now, but as a fallback mechanism: https://github.com/OpenLineage/OpenLineage/pull/914
You can manually annotate DAG with information instead of writing extractor for your operator. This still gives you runtime information. Similar features might get added to other integrations, especially with such a vast scope as Airflow has - but I think it's unlikely we'd work on a feature for just statically traversing code without runtime context.
*Thread Reply:* Thanks for the detailed response @Maciej Obuchowski! It seems like this solution is specific only to AirFlow, and i wonder why wouldn't we generalize this outside of just AirFlow? My thinking is that there are other areas where there is vast scope (e.g. arbitrary code that does data manipulations), and without such an option, the only path is to provide full runtime information via building your own extractor, which might be a bit hard/expensive to do. If i understand your response correctly, then you assume that OpenLineage can get wide enough "native" support across the stack without resorting to a fallback like 'static code analysis'. Is that your base assumption?

Hi all, does anybody have an experience extracting Airflow lineage using Marquez as documented here https://www.astronomer.io/guides/airflow-openlineage/#generating-and-viewing-lineage-data ? We tested it on our Airflow instance with Marquez hoping to get the standard .json files describing lineage in accord with open-lineage model as described in https://json-schema.org/draft/2020-12/schema. But there seems to be only one GET method related to lineage export in Marquez API library called "Get a lineage graph". This produces quite different .json structure than what we know from open-lineage. Could anybody help if there is a chance to get open-lineage .json structure from Marquez?

*Thread Reply:* The query API has a different spec than the reporting API, so what you’d get from Marquez would look different from what Marquez receives.
Few ideas:
- you could send the lineage to a pipedream endpoint to inspect, if you’re just trying to experiment
- you could grab them from the
lineagetable in Marquez’s postgres
*Thread Reply:* ok, now I understand, thank you
*Thread Reply:* FYI we want to have something like that too: https://github.com/MarquezProject/marquez/issues/1927
But if you need just the raw events endpoint, without UI, then Marquez might be overkill for your needs
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
Hi @everyone , we are trying to extract lineage information and import into amundsen .please point us right direction to move - based on the documentation -> Databricks + marquez + amundsen is this the only way to move on ?
*Thread Reply:* Short of implementing an open lineage endpoint in Amundsen, yes that's the right approach.
The Lineage endpoint in Marquez can output the whole graph centered on a node ID, and you can use the jobs/datasets apis to grab lists of each for reference
*Thread Reply:* Is your lineage information coming via OpenLineage? if so - you can quickly use the Amundsen scripts in order to load data into Amundsen, for example, see this script here: https://github.com/amundsen-io/amundsendatabuilder/blob/master/example/scripts/sample_data_loader.py
Where is your lineage coming from?
<a href="https://github.com/amundsen-io/amundsendatabuilder">amundsen-io/amundsendatabuilder</a>
*Thread Reply:* yes @Barak F we are using open lineage
*Thread Reply:* So, have you tried using Amundsen data builder scripts to load the lineage information into Amundsen? (maybe you'll have to "play" with those a bit)
*Thread Reply:* AFAIK there is OpenLineage extractor: https://www.amundsen.io/amundsen/databuilder/#openlineagetablelineageextractor
Not sure it solves your issue though 🙂
@channel OpenLineage 0.12.0 is now available! We added: • an Apache Flink integration, • support for Spark 3.3.0, • the ability to extend column level lineage mechanism, • an ErrorMessageRunFacet to the OpenLineage spec, • SQLCheckExtractors, a RedshiftSQLExtractor & RedshiftDataExtractor to the Airflow integration, • a dataset builder to the AlterTableCommand class in the Spark integration. We changed: • the filtering of Delta events to reduce noise, • the flow of metadata in the Airflow integration to allow metadata from Airflow through inlets and outlets. Thanks to all the contributors who made this release possible! For the bug fixes and more details, see: Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.12.0 Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.11.0...0.12.0 Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage PyPI: https://pypi.org/project/openlineage-python/ (edited)
What is the right way of handling/parsing facets on the server side?
I see the generated server side stubs are generic : https://github.com/OpenLineage/OpenLineage/blob/main/client/java/generator/src/main/java/io/openlineage/client/Generator.java#L131 and dont have any resolved facet information. Marquez seems to have duplicated the OL model with https://github.com/MarquezProject/marquez/blob/main/api/src/main/java/marquez/service/models/LineageEvent.java#L71 and converts the incoming OL events to a “LineageEvent” for appropriate handling. Is there a cleaner approach where in the known facets can be generated in io.openlineage.server?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* I think the reason for server model being very generic is because new facets can be added later (also as custom facets) - and generally server wants to accept all valid events and get the facet information that it can actually use, rather than reject event because it has unknown field.
Server model was added here after some discussion in Marquez which is relevant - I think @Michael Collado @Willy Lulciuc can add to that
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Thanks for the response. I realize the server stubs were created to support flexibility , but it also makes the parsing logic on server side a bit more complex as we need to maintain code on the server side to look for specific facets & their properties from maps or like maquez duplicate the OL model on our end with the facets we care about. Wanted to know whats the guidance around managing this server side. @Willy Lulciuc @Michael Collado Any suggestions ?
Agenda items are requested for the next OpenLineage Technical Steering Committee meeting on August 11 at 10am PT. Reply in thread or ping me with your item(s)!
Hi all, I am trying out the openlineage spark integration and can't find any column lineage information included with the events. I tried it out with an input dataset where I renamed one of the columns but the columnLineage facet was not present. Can anyone suggest some other examples where it might show up?
Thanks!
*Thread Reply:* @Paweł Leszczyński do we collect column level lineage on renames?
*Thread Reply:* @Maciej Obuchowski no, we don’t. @Varun Singh create table as select may suit you well. Other examples are within tests like: • https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/spark3/src/[…]lifecycle/plan/column/ColumnLevelLineageUtilsV2CatalogTest.java • https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/spark3/src/[…]ecycle/plan/column/ColumnLevelLineageUtilsNonV2CatalogTest.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I’ve created an issue for column lineage in case of renaming: https://github.com/OpenLineage/OpenLineage/issues/993
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks @Paweł Leszczyński!
Hey everyone! I am looking into Fivetran a bit, and it occurs to me that the NAMING.md document does not have an opinion about how to deal with entire systems as datasets. More in 🧵.
*Thread Reply:* Fivetran is a tool that copies data from source systems to target databases. One of these source systems might be SalesForce, for example.
This copying results in thousands of SQL queries run against the target database for each sync. I don’t think each of these queries should map to an OpenLineage job, I think the entire synchronization should. Maybe I’m wrong here.
*Thread Reply:* But if I’m right, that means that there needs to be a way to specify “SalesForce Account #45123452233” as a dataset.
*Thread Reply:* or it ends up just being a job with outputs and no inputs…but that’s not very illuminating
*Thread Reply:* You are looking at a pretty big topic here 🙂
Basically you're asking what is a job in OpenLineage - and it's not fully answered yet.
I think the discussion is kinda relevant to this proposed facet and I kinda replied there: https://github.com/OpenLineage/OpenLineage/issues/812#issuecomment-1205337556

*Thread Reply:* my 2 cents on this is that in the Salesforce example, the system is to complex to capture as a single dataset. and so maybe different objects within a salesforce account (org/account/opportunity/etc…) could be treated as individual datasets. But as @Maciej Obuchowski pointed out, this is quite a large topic 🙂
*Thread Reply:* I guess it depends on whether you actually care about the table/column level lineage for an operation like “copy salesforce to snowflake”.
I can see it being a nuisance having all of that on a lineage graph. OTOH, I can see it being useful to know that a datum can be traced back to a specific endpoint at SFDC.
@channel The next OpenLineage Technical Steering Committee meeting is on Thursday, August 11 at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom All are welcome! Agenda:
- Announcements
- Docs site update
- Release 0.11.0 and 0.12.0 overview
- Extractors: examples and how to write them
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda. (edited)

👋 Hi everyone!
@channel The next OpenLineage TSC meeting is tomorrow! https://openlineage.slack.com/archives/C01CK9T7HKR/p1659627000308969
*Thread Reply:* I am so sad I'm going to miss this month's meeting 😰 Looking forward to the recording!
*Thread Reply:* We missed you too @Will Johnson 😉

Hi everyone! I have a REST endpoint that I use for other pipelines that can POST their RunEvent and I forward that to marquez. I'm expecting a JSON which has the RunEvent details, which also has the input or output dataset depending upon the EventType. I can see the Run details always shows up on the marquez UI, but the dataset has issues. I can see the dataset listed but when I can click on it, just shows "something went wrong." I don't see any details of that dataset.
{
"eventType": "START",
"eventTime": "2022-08-09T19:49:24.201361Z",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "TEST-NAMESPACE",
"name": "test-job"
},
"inputs": [
{
"namespace": "TEST-NAMESPACE",
"name": "my-test-input",
"facets": {
"schema": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>",
"_schemaURL": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/spec/OpenLineage.json#/definitions/SchemaDatasetFacet>",
"fields": [
{
"name": "a",
"type": "INTEGER"
},
{
"name": "b",
"type": "TIMESTAMP"
},
{
"name": "c",
"type": "INTEGER"
},
{
"name": "d",
"type": "INTEGER"
}
]
}
}
}
],
"producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>"
}
In above payload, the input data set is never created on marquez. I can only see the Run details, but input data set is just empty. Does the input data set needs to created first and then only the RunEvent can be created?
*Thread Reply:* From the first look, you're missing outputsfield in your event - this might break something
*Thread Reply:* If not, then Marquez logs might help to see something
*Thread Reply:* Does the START event needs to have an output?
*Thread Reply:* It can have empty output 🙂
*Thread Reply:* well, in your case you need to send COMPLETE event
*Thread Reply:* Internally, Marquez does not create dataset version until you complete event. It makes sense when your semantics are transactional - you can still read from previous dataset version until it's finished writing.
*Thread Reply:* Thanks for the explanation @Maciej Obuchowski So, if I understand this correct. I won't see the my-test-input dataset till I have the COMPLETE event with input and output?
*Thread Reply:* @Raj Mishra Yes and no 🙂
Basically your COMPLETE event does not need to contain any input and output datasets at all - OpenLineage model is cumulative, so it's enough to have datasets on either start or complete.
That also means you can add different datasets in different moment of a run lifecycle - for example, you know inputs, but not outputs, so you emit inputs on START , but not COMPLETE.
Or, the job is modifying the same dataset it reads from (which happens surprisingly often), Then, you want to collect various input metadata from the dataset before modifying it - most likely you won't have them on COMPLETE 🙂
In this example I've added my-test-input on START and my-test-input2 on COMPLETE :
*Thread Reply:* @Maciej Obuchowski Thank you so much! This is great explanation.
Effectively handling file datasets on server side. We have a common usecase where dataset of type
*Thread Reply:* Would adding support for alias/grouping as a config on OL client side be valuable to other users ? i.e OL client could pass down an Alias/grouping facet Or should this be treated purely a server side feature
*Thread Reply:* Agreed 🙂
How do you produce this dataset? Spark integration? Are you using any system like Apache Iceberg/Delta Lake or just writing raw files?
*Thread Reply:* these are raw files written from Spark or map reduce jobs. And downstream Spark jobs read these raw files to produce tables
*Thread Reply:* written using Spark dataframe API, like
df.write.format("parquet").save("/tmp/spark_output/parquet")
or RDD?
*Thread Reply:* the actual API used matters, because we're handling different cases separately
*Thread Reply:* I see. Let me look that up to be absolutely sure
*Thread Reply:* It is like. this : df.write.format("parquet").save("/tmp/spark_output/parquet")
*Thread Reply:* @Maciej Obuchowski curious what you had in mind with respect to RDDs & Dataframes. Also what if we cannot integrate OL with the frameworks that produce this dataset , but only those that consume from the already produced datasets. Is there a way we could still capture the dataset appropriately ?
*Thread Reply:* @Sharanya Santhanam the naming should be consistent between reading and writing, so it wouldn't change much of you can't integrate OL into writers. For the rest, can you create an issue on OL GitHub so someone can pick it up? I'm at vacation now.
*Thread Reply:* Sounds good , Ty !
Hi, Minor Suggestion: This line https://github.com/OpenLineage/OpenLineage/blob/46efab1e7c2a0aa5ebe8d11185fe8d5225[…]/app/src/main/java/io/openlineage/spark/agent/EventEmitter.java is printing variables like api key and other parameters in the logs. Wouldn't it be more appropriate to use log.debug instead? I'll create an issue if others agree
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* please do create 🙂
dumb question but, is it easy to run all the OpenLineage tests locally? ( and if so how? 🙂 )
*Thread Reply:* it's per project. java based: ./gradlew test python based: https://github.com/OpenLineage/OpenLineage/tree/main/integration/airflow#development
Spark Integration: The Order of Processing Events in the Async Event Queue
Hey, OpenLineage team, I'm working on a PR (https://github.com/OpenLineage/OpenLineage/pull/849/) that is going to store information given in different spark events (e.g. SparkListenerSQLExecutionStart, SparkListenerJobStart).
However, I want to avoid holding all this data once the execution of the job is complete. As a result, I want to remove the data once I receive a SparkListenerSQLExecutionEnd.
However, can I be guaranteed that the ExecutionEnd event will be processed AFTER the JobStart event? Is it possible that I can take too long to process the the JobStart event that the ExecutionEnd executes prior to the JobStart finishing?
I know we do something similar to this with sparkSqlExecutionRegistry (https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/mai[…]n/java/io/openlineage/spark/agent/OpenLineageSparkListener.java) but do we have any docs to help explain how the AsyncEventQueue orders and consumes events for a listener?
Thank you so much for any insights
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hey Will! A bunch of folks are on vacation or out this week. Sorry for the delay, I am personally not sure but if it's not too urgent you can have an answer when knowledgable folks are back.
*Thread Reply:* Hah! No worries, @Julien Le Dem! I can definitely wait for the lucky people who are enjoying the last few weeks of summer unlike the rest of us 😋
*Thread Reply:* @Paweł Leszczyński might want to look at that
Hi, I try to find out if openLineage spark support pyspark (Non-sql) use cases? Is there any doc I could get more details about non-sql openLineage support? Thanks a lot
*Thread Reply:* Hello Hanbing, the spark integration works for PySpark since pyspark is wrapped into regular spark operators.
*Thread Reply:* @Julien Le Dem Thanks a lot for your help. I searched around, but I couldn't find any doc introduce how pyspark supported in openLineage. My company want to integrate with openLineage-spark, I am working on figure out what info does OpenLineage make available for non-sql and does it at least have support for logging the logical plan?
*Thread Reply:* Yes, it does send the logical plan as part of the event
*Thread Reply:* This configuration here should work as well for pyspark https://openlineage.io/docs/integrations/spark/
*Thread Reply:* --conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener"
*Thread Reply:* you need to add the jar, set the listener and pass your OL config
*Thread Reply:* Actually I'm demoing this at 27:10 right here 🙂 https://pretalx.com/bbuzz22/talk/FHEHAL/
*Thread Reply:* you can see the parameters I'm passing to the pyspark command line in the video
*Thread Reply:* @Julien Le Dem Thanks for the info, Let me take a look at the video now.
*Thread Reply:* The full demo starts at 24:40. It shows lineage connected together in Marquez coming from 3 different sources: Airflow, Spark and a custom integration
Hi everyone, a release has been requested by @Harel Shein. As per our policy here, 3 +1s from committers will authorize an immediate release. Thanks! Unreleased commits: https://github.com/OpenLineage/OpenLineage/compare/0.12.0...HEAD
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Michael Robinson can we start posting the “Unreleased” section in the changelog along with the release request? That way, we / the community will know what will be in the upcoming release
*Thread Reply:* The release is approved. Thanks @Willy Lulciuc, @Minkyu Park, @Harel Shein
@channel
OpenLineage 0.13.0 is now available!
We added:
• BigQuery check support
• RUNNING EventType in the spec and Python client
• databases and schemas to SQL extractors
• an event forwarding feature via HTTP
• Azure Cosmos Handler to the Spark integration
• support for OL datasets in manual lineage inputs/outputs
• ownership facets.
We changed:
• use RUNNING EventType in Flink integration for currently running jobs
• convert task object into JSON encodable when creating Airflow version facet.
Thanks to all the contributors who made this release possible!
For the bug fixes and more details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.13.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.12.0...0.13.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/ (edited)
*Thread Reply:* Cool! Are the new ownership facets populated by the Airflow integration ?

Hi everyone, excited to work with OpenLineage. I am new to both OpenLineage and Data Lineage in general. Are there working examples/blog posts around actually integrating OpenLineage with existing graph DBs like Neo4J, Neptune etc? (I understand the service layer in between) I understand we have Amundsen with sample open lineage sample data - databuilder/example/sample_data/openlineage/sample_openlineage_events.ndjson. Thanks in advance.
*Thread Reply:* There is not that I know of besides the Amundsen integration example you pointed at. A basic idea to do such a thing would be to implement an OpenLineage endpoint (receive the lineage events through http posts) and convert them to a format the graph db understand. If others in the community have ideas, please chime in
*Thread Reply:* Understood, thanks a lot Julien. Make sense.
Hey all, can I ask for a release for OpenLineage?
*Thread Reply:* Thanks, Harel. 3 +1s from committers is all we need to make this happen today.
*Thread Reply:* Thanks, all. The release is authorized
*Thread Reply:* can you also state the main purpose for this release?
*Thread Reply:* I believe (correct me if wrong, @Harel Shein) that this is to make available a fix of a bug in the compare functionality
*Thread Reply:* ParentRunFacet from the airflow integration is not compliant to OpenLineage spec and this release includes the fix of that so that the marquez can handle parent run/job information.
@channel
OpenLineage 0.13.1 is now available!
We fixed:
• Rename all parentRun occurrences to parent from Airflow integration #1037 @fm100
• Do not change task instance during on_running event #1028 @JDarDagran
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.13.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.13.0...0.13.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

Hi, I am new to openlineage. Any one know how to enable spark column level lineage? I saw the code comment, it said default is disabled, thanks
*Thread Reply:* What version of Spark are you using? it should be enabled by default for Spark 3 https://openlineage.io/docs/integrations/spark/spark_column_lineage
*Thread Reply:* Thanks. Good to here that. I am use 0.9.+ . I will try again
*Thread Reply:* I tested 0.9.+ 0.12.+ with spark 3.0 and 3.2 version. There still do not have dataset facet columnlineage. This is strange. I saw the column lineage design proposals 148. It should support from 0.9.+ Do I miss something?
*Thread Reply:* @Jason it depends on the data source. What sort of data are you trying to read? Is it in a hive metastore? Is it on an S3 bucket? Is it a delta file format?
*Thread Reply:* I tried read hive megastore on s3 and cave file on local. All are miss the columnlineage
*Thread Reply:* @Jason - Sorry, you'll have to translate a bit for me. Can you share a snippet of code you're using to do the read and write? Is it a special package you need to install or is it just using the hadoop standard for S3? https://hadoop.apache.org/docs/stable/hadoop-aws/tools/hadoop-aws/index.html
*Thread Reply:* spark.read \ .option("header", "true") \ .option("inferschema", "true") \ .csv("data/input/batch/wikidata.csv") \ .write \ .mode('overwrite') \ .csv("data/output/batch/python-sample.csv")
*Thread Reply:* This is simple code run on my local for testing
*Thread Reply:* Which version of OpenLineage are you running? You might look at the code on the main branch. This looks like a HadoopFSRelation which I implemented for column lineage but the latest release (0.13.1) does not include it yet.
*Thread Reply:* Specifically this commit is what implemented it. https://github.com/OpenLineage/OpenLineage/commit/ce30178cc81b63b9930be11ac7500ed34808edd3
*Thread Reply:* @Jason we have our monthly release coming up now, so it should be included in 0.14.0 when released today/tomorrow
Hi! I have ran into some issues and wanted to clarify my doubts.
• Why are input schema changes(column delete, new columns) doesn't show up on the UI. I have changed the input schema for the same job, but I'm not seeing getting updated on the UI.
• Why is there only ever 1 input schema version. Every change I make in input schema, I only see output schema has multiple versions but only 1 version for input schema.
• Is there a reason why can't we see the input schema till the COMPLETE event is posted?
I have used the examples from here. https://openlineage.io/getting-started/
curl -X POST <http://localhost:5000/api/v1/lineage> \
-H 'Content-Type: application/json' \
-d '{
"eventType": "START",
"eventTime": "2020-12-28T19:52:00.001+10:00",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "my-namespace",
"name": "my-job"
},
"inputs": [{
"namespace": "my-namespace",
"name": "my-input"
}],
"producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>"
}'
curl -X POST <http://localhost:5000/api/v1/lineage> \
-H 'Content-Type: application/json' \
-d '{
"eventType": "COMPLETE",
"eventTime": "2020-12-28T20:52:00.001+10:00",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "my-namespace",
"name": "my-job"
},
"outputs": [{
"namespace": "my-namespace",
"name": "my-output",
"facets": {
"schema": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>",
"_schemaURL": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/spec/OpenLineage.json#/definitions/SchemaDatasetFacet>",
"fields": [
{ "name": "a", "type": "VARCHAR"},
{ "name": "b", "type": "VARCHAR"}
]
}
}
}],
"producer": "<https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client>"
}'
Changing the inputs schema for START doesn't change the schema input version and doesn't update the UI.
Thanks!
*Thread Reply:* Reading dataset - which input dataset implies - does not mutate the dataset 🙂
*Thread Reply:* If you change the dataset, it would be represented as some other job with this datasets in the outputs list
*Thread Reply:* So, changing the input dataset will always create new output data versions? Sorry I have trouble understanding this, but if the input is changing, shouldn't the input data set will have different versions?
*Thread Reply:* @Raj Mishra if input is changing, there should be something else in your data infrastructure that changes this dataset - and it should emit this dataset as output

Hi Everyone, new here. i went thourhg the docs and examples. cant seem to understand how can i model views on top of base tables if not from a data processing job but rather via modeling something static that is coming from some software internals. i.e. i want to issue the lineage my self rather it will learn it dynamically from some Airflow DAG or spark DAG
*Thread Reply:* I think you want to emit raw events using python or java client: https://openlineage.io/docs/client/python
*Thread Reply:* (docs in progress 😉)
*Thread Reply:* can you give a hind what should i look for for modeling a dataset on top of other dataset? potentially also map columns?
*Thread Reply:* i can only see that i can have a dataset as input to a job run and not for another dataset
*Thread Reply:* Not sure I understand - jobs process input datasets into output datasets. There is always something that can be modeled into a job that consumes input and produces output.
*Thread Reply:* so openlineage force me to put a job between datasets? does not fit our use case
*Thread Reply:* unless we can some how easily hide the process that does that on the graph.
QQ, I saw that spark Column level lineage start with open lineage 0.9.+ version with spark 3.+, Does it mean it needs to run lower than open lineage 0.9 if our spark is 2.3 or 2.4?
*Thread Reply:* I don't think it will work for Spark 2.X.
*Thread Reply:* Is there have plan to support spark 2.x?
*Thread Reply:* Nope - on the other hand we plan to drop any support for it, as it's unmaintained for quite a bit and vendors are dropping support for it too - afaik Databricks in April 2023.
*Thread Reply:* I see. Thanks. Amazon Emr still support spark 2.x
Spark Integration: Handling Data Source V2 API datasets
Is it expected that a DataSourceV2 relation has a start event with inputs and outputs but a complete event with only outputs? Based on @Michael Collado’s previous comments, I think it's fair to say YES this is expected and we just need to handle it. https://openlineage.slack.com/archives/C01CK9T7HKR/p1645037070719159?thread_ts=1645036515.163189&cid=C01CK9T7HKR
@Hanna Moazam and I noticed this behavior when we looked at the Cosmos Db visitor and then reproduced it for the Iceberg visitor. We traced it down to the fact that the AbstractQueryPlanInputDatasetBuilder (which is the parent of DataSourceV2RelationInputDatasetBuilder) has an isDefinedAt that only includes SparkListenerJobStart and SparkListenerSQLExecutionStart
This means an Iceberg COMPLETE event will NEVER contain inputs because the isDefinedAt will always be false (since COMPLETE only fires for JobEnd and ExecutionEnd events). Does that sound correct (@Paweł Leszczyński)?
It seems that Delta tables (or at least Delta on Databricks) does not follow this same code path and as a result our complete events includes outputs AND inputs.
 }
}
*Thread Reply:* At least for Iceberg I've done it, since I want to emit DatasetVersionDatasetFacet for input dataset only at START - and after I finish writing the dataset might have different version than before writing.
*Thread Reply:* Same should be for output AFAIK - output version should be emitted only on COMPLETE, since the version changes after I finish writing.
*Thread Reply:* Ah! Okay, so this still requires us to truly combine START and COMPLETE to get a TOTAL picture of the entire run. Is that fair?
*Thread Reply:* Yes
*Thread Reply:* As usual, thank you Maciej for the responses and insights!
QQ team, I use spark sql with openlineage namespace weblog: spark.sql(“select ** from weblog where dt=‘
*Thread Reply:* Anyone can help for it? Does I miss something
Hi everyone, I’m opening up a vote on this month’s OpenLineage release. 3 +1s from committers will authorize. Additions include support for KustoRelationHandler in Kusto (Azure Data Explorer) and for ABFSS and Hadoop Logical Relation, both in the Spark integration. All commits can be found here: https://github.com/OpenLineage/OpenLineage/compare/0.13.1...HEAD. Thanks in advance!
*Thread Reply:* Thanks. The release is authorized. It will be initiated within 2 business days.

Is there a reference on how to deploy openlineage on a Non AWS infrastructure ?
*Thread Reply:* Which integration are you looking to implement?
And what environment are you looking to deploy it on? The Cloud? On-Prem?
*Thread Reply:* We are planning to deploy on premise with Kerberos as authentication for postgres
*Thread Reply:* Ah! Are you planning on running Marquez as well and that is your main concern or are you planning on building your own store of OpenLineage Events and using the SQL integration to generate those events?
https://github.com/OpenLineage/OpenLineage/tree/main/integration
*Thread Reply:* I am looking to deploy Marquez on-prem with onprem postgres as back-end with Kerberos authentication.
*Thread Reply:* Is the the right forum for Marquez as well or there is different slack channel for Marquez available
*Thread Reply:* There is another slack channel just for Marquez! That might be a better spot with more dedicated Marquez developers.
@channel
OpenLineage 0.14.0 is now available!
We added:
• Support ABFSS and Hadoop Logical Relation in Column-level lineage #1008 @wjohnson
• Add Kusto relation visitor #939 @hmoazam
• Add ColumnLevelLineage facet doc #1020 @julienledem
• Include symlinks dataset facet #935 @pawel-big-lebowski
• Add support for dbt 1.3 beta’s metadata changes #1051 @mobuchowski
• Support Flink 1.15 #1009 @mzareba382
• Add Redshift dialect to the SQL integration #1066 @mobuchowski
We changed:
• Make the timeout configurable in the Spark integration #1050 @tnazarew
We fixed:
• Add a dialect parameter to Great Expectations SQL parser calls #1049 @collado-mike
• Fix Delta 2.1.0 with Spark 3.3.0 #1065 @pawel-big-lebowski
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.14.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.13.1...0.14.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
*Thread Reply:* Thanks for breaking up the changes in the release! Love the new format 💯
Hello all, I’m requesting a patch release to fix a bug in the Spark integration. Currently, OpenlineageSparkListener fails when no openlineage.timeout is provided. PR #1069 by @Paweł Leszczyński, merged today, will fix it. As per our policy here, 3 +1s from committers will authorize an immediate release.
*Thread Reply:* Is PR #1069 all that’s going in 0.14.1 ?
*Thread Reply:* There’s also 1058. 1069 is urgently needed. We can technically wait…
*Thread Reply:* (edited prior message because I’m not sure how accurately I was describing the issue)
*Thread Reply:* Thanks, all. The release is authorized.
*Thread Reply:* 1058 also fixes some bugs
Hello all, question: Views on top of base table is also a use case for lineage and there is no job in between. i dont seem to find a way to have a dataset on top of others to represent a view on top of tables. is there a way to do that without a job in between?
*Thread Reply:* Usually there is something creating the view, for example dbt materialization: https://docs.getdbt.com/docs/building-a-dbt-project/building-models/materializations
Besides that, there is this proposal that did not get enough love yet https://github.com/OpenLineage/OpenLineage/issues/323
*Thread Reply:* but we are not working iwth dbt. we try to model lineage of our internal view/tables hirarchy which is related to a propriety application of ours. so we like OpenLineage that lets me explicily model stuff and not only via scanning some DW. but in that case we dont want a job in between.
*Thread Reply:* this PR does not seem to support lineage between datasets
*Thread Reply:* This is something core to the OpenLineage design - the lineage relationships are defined as dataset-job-dataset, not dataset-dataset.
In OpenLineage, something observes the lineage relationship being created.
*Thread Reply:* It’s a bit different from some other lineage approaches, but OL is intended to be a push model. A job is observed as it runs, metadata is pushed to the backend.
*Thread Reply:* so in this case, according to openlineage 🙂, the job would be whatever runs within the pipeline that creates the view. very operational point of view.
*Thread Reply:* but what about the view definition use case? u have lineage of columns in view/base table relation ships
*Thread Reply:* how would you model that in OpenLineage? would you create a dummy job ?
*Thread Reply:* would you say that because this is my use case i might better choose some other lineage tool?
*Thread Reply:* for the context: i am not talking about some view and table definitions in some warehouse e.g. SF but its internal data processing mechanism with propriety view/tables definition (in Flink SQL) and we want to push this metadata for visibility
*Thread Reply:* Ah, gotcha. Yeah, I would say it’s probably best to create a job in this case. You can send the view definition using a sourcecodefacet, so it will be collected as well. You’d want to send START and STOP events for it.
*Thread Reply:* regarding the PR linked before, you are right - I wonder if someday the spec should have a way to express “the system was made aware that these datasets are related, but did not observe the relationship being created so it can’t tell you i.e. how long it took or whether it changed over time”
@channel
OpenLineage 0.14.1 is now available!
We fixed:
• Fix Spark integration issues including error when no openlineage.timeout #1069 @pawel-big-lebowski
Bug fixes were also included in this release.
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.14.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.14.0...0.14.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Hello, any future plans for integrating Airbyte with openlineage?
*Thread Reply:* Hey, @data_fool! Not in the near term. but of course we’d love to see this happen. We’re open to having an Airbyte integration driven by the community. Want to open an issue to start the discussion?
*Thread Reply:* hey @Willy Lulciuc, Yep, will open an issue. Thanks!
Hi can you create lineage across namespaces? Thanks
*Thread Reply:* Any example or ticket on how to lineage across namespace
Hello, Does OpenLineage support column level lineage?
*Thread Reply:* Yes https://openlineage.io/blog/column-lineage/
*Thread Reply:* • More details on Spark & Column level lineage integration: https://openlineage.io/docs/integrations/spark/spark_column_lineage • Proposal on how to implement column level lineage in Marquez (implementation is currently work in progress): https://github.com/MarquezProject/marquez/blob/main/proposals/2045-column-lineage-endpoint.md @Iftach Schonbaum let us know if you find the information useful.
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>

where can i find docs on just simply using extractors? without marquez. for example, a basic BashOperator on Airflow 1.10.15
*Thread Reply:* or is it automatic for anything that exists in extractors/?

*Thread Reply:* Yes
*Thread Reply:* so anything i add to extractors directory with the same name as the operator will automatically extract the metadata from the operator is that correct?
*Thread Reply:* please take a look at the source code of one of the extractors
*Thread Reply:* also, there are docs available at openlineage.io/docs
*Thread Reply:* ok, i'll take a look. i think one thing that would be helpful is having a custom setup without marquez. a lot of the docs or videos i found were integrated with marquez
*Thread Reply:* I see. Marquez is a openlineage backend that stores the lineage data, so many examples do need them.
*Thread Reply:* If you do not want to run marquez but just test out the openlineage, you can also take a look at OpenLineage Proxy.
*Thread Reply:* awesome thanks Howard! i'll take a look at these resources and come back around if i need to
*Thread Reply:* http://openlineage.io/docs/integrations/airflow/extractor - this is the doc you might want to read
*Thread Reply:* yeah, saw that doc earlier. thanks @Maciej Obuchowski appreciate it 🙏

Hey team! I’m pretty new to the field in general
In the real world, I would be running pyspark scripts on AWS EMR. Could you explain to me how the metadata is sent to Marquez from my pyspark script, and where it’s persisted?
Would I need to set up an S3 bucket to store the lineage data?
I’m also unsure about how I would run the Marquez UI on AWS - Would I need to have an EC2 instance running permanently in order to access that UI?
*Thread Reply:* In my head, I have:
Pyspark script -> Store metadata in S3 -> Marquez UI gets data from S3 and displays it
I suspect this is incorrect?
*Thread Reply:* It’s more like: you add openlineage jar to Spark job, configure it what to do with the events. Popular options are: * sent to rest endpoint (like Marquez), * send as an event onto Kafka, ** print it onto console There is no S3 in between Spark & Marquez by default. Marquez serves both as an API where events are sent and UI to investigate them.
*Thread Reply:* Yeah S3 was just an example for a storage option.
I actually found the answer I was looking for, turns out I had to look at Marquez documentation: https://marquezproject.ai/resources/deployment/
The answer is that Marquez uses a postgres instance to persist the metadata it is given. Thanks for your time though! I appreciate the effort 🙂
Hello team, For the OpenLineage Spark, even when I processed one Spark sql query (CTAS Create Table As Select), I will received multiple events back (2+ Start events, 2 Complete events). I try to understand why OpenLineage need to send back that much events, and what is the primary difference between Start VS Start events, Start VS Complete events? Do we have any doc can help me understand more on it? Thanks
*Thread Reply:* The Spark execution model follows:
- Spark SQL Execution Start event
- Spark Job Start event
- Spark Job End event
- Spark SQL Execution End event As a result, OpenLineage tracks all of those execution and jobs. There is a proposed plan to distinguish between those events (e.g. you wouldn't get two starts but one Start and one Job Start or something like that).
You should collect all of these events in order to be sure you are receiving all the data since each event may contain a subset of the complete facets that represent what occurred in the job.
*Thread Reply:* Thanks @Will Johnson Can I get an example of how the proposed plan can be used to distinguish between start and job start events? Because I compare the 2 starts events I got, only the event_time is different, all other information are the same.
*Thread Reply:* One followup question, if I process multiple queries in one command, for example (Drop + Create Table + Insert Overwrite), should I expected for (1). 1 Spark SQL execution start event (2). 3 Spark job start event (Each query has a job start event ) (3). 3 Spark job end event (Each query has a job end event ) (4). 1 Spark SQL execution end event
*Thread Reply:* Re: Distinguish between start and job start events. There was a proposal to differentiate the two (https://github.com/OpenLineage/OpenLineage/issues/636) but the current discussion is here: https://github.com/OpenLineage/OpenLineage/issues/599 As it currently stands, there is not a way to tell which one is which (I believe). The design of OpenLineage is such that you should consume ALL events under the same run id and job name / namespace.
Re: Multiple Queries in One Command: This is where Spark's execution model comes into play. I believe each one of those commands are executed sequentially and as a result, you'd actually get three execution start and three execution end. If you chose DROP + Create Table As Select, that would be only two commands and thus only two execution start events.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks a lot for your help 🙏 @Will Johnson,
For multiple queries in one command, I still have a confused place why Drop + CreateTable and Drop + CreateTableAsSelect act different.
When I test Drop + Create Table
Query:
DROP TABLE IF EXISTS shadow_test.test_sparklineage_4; CREATE TABLE IF NOT EXISTS shadow_test.test_sparklineage_4 (val INT, region STRING) PARTITIONED BY ( ds STRING ) STORED AS PARQUET;
I only received 1 start + 1 complete event
And the events only contains DropTableCommandVisitor/DropTableCommand.
I expected we should also received start and complete events for CreateTable query with CreateTableCommanVisitor/CreateTableComman .
But when I test Drop + Create Table As Select
Query:
DROP TABLE IF EXISTS shadow_test.test_sparklineage_5; CREATE TABLE IF NOT EXISTS shadow_test.test_sparklineage_5 AS SELECT ** from shadow_test.test_sparklineage where ds > '2022-08-24'"
I received 1 start + 1 complete event with DropTableCommandVisitor/DropTableCommand
And 2 start + 2 complete events with CreateHiveTableAsSelectCommandVisitor/CreateHiveTableAsSelectCommand
*Thread Reply:* @Hanbing Wang are you running this on Databricks with a hive metastore that is defaulting to Delta by any chance?
I THINK there are some gaps in OpenLineage because of the way Databricks Delta handles things and now there is Unity catalog that is causing some hiccups as well.
*Thread Reply:* > For multiple queries in one command, I still have a confused place why Drop + CreateTable and Drop + CreateTableAsSelect act different.
@Hanbing Wang That's basically why we capture all the events (SQL Execution, Job) instead of one of them. We're just inconsistently notified of them by Spark.
Some computations emit SQL Execution events, some emit Job events, I think majority emits both. This also differs by spark version.
The solution OpenLineage assumes is having cumulative model of job execution, where your backend deals with possible duplication of information.
> I THINK there are some gaps in OpenLineage because of the way Databricks Delta handles things and now there is Unity catalog that is causing some hiccups as well. @Will Johnson would be great if you created issue with some complete examples
*Thread Reply:* @Will Johnson and @Maciej Obuchowski Thanks a lot for your help We are not running on Databricks. We implemented the OpenLineage Spark listener, and custom the Event Transport which emitting the events to our own events pipeline with a hive metastore. We are using Spark version 3.2.1 OpenLineage version 0.14.1
*Thread Reply:* Ooof! @Hanbing Wang then I'm not certain why you're not receiving the extra event 😞 You may need to run your spark cluster in debug mode to step through the Spark Listener.
*Thread Reply:* @Maciej Obuchowski - I'll add it to my list!
*Thread Reply:* @Will Johnson Thanks a lot for your help. Let us debug and continue investigating on this issue.

Hi team, I find Openlineage posts a lot for run events to the backend.
eg. I submit jar to Spark cluster with computations like
- count from table1. --> this will have more than one run events inputs:[table1], outputs:[]
- count from table2 --> this will have more than one run events inputs:[table2], outputs:[]
- write Seq[(t1, count1), (t2, count2)) to table3. --> this may give inputs:[] outputs [table3] can I just get one post with a summary telling me, inputs:[table1, table2], outputs:[table3] alongside with a merged columnareLineage?
*Thread Reply:* One of assumptions was to create a stateless integration model where multiple events can be sent for a single job run. This has several advantages like sending events for jobs which suddenly fail, sending events immediately, etc.
The events can be merged then at the backend side. The behavior, you describe, can be then achieved by using backends like Marquez and Marquez API to obtain combined data.
Currently, we’re developing column-lineage dedicated endpoint in Marquez according to the proposal: https://github.com/MarquezProject/marquez/blob/main/proposals/2045-column-lineage-endpoint.md This will allow you to request whole column lineage graph based on multiple jobs.
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
Is there a provision to include additional MDC properties as part of openlineage ? Or something like sparkSession.sparkContext().setLocalProperties("key","value")
*Thread Reply:* Hello @srutikanta hota, could you elaborate a bit on your use case? I'm not sure what you are trying to achieve. Possibly @Paweł Leszczyński will know.
*Thread Reply:* @srutikanta hota - Not sure what MDC properties stands for but you might take inspiration from the DatabricksEnvironmentHandler Facet Builder: https://github.com/OpenLineage/OpenLineage/blob/65a5f021a1ba3035d5198e759587737a05[…]ark/agent/facets/builder/DatabricksEnvironmentFacetBuilder.java
You can create a facet that could extract out the properties that you might set from within the spark session.
I don't think OpenLineage / a Spark Listener can affect the SparkSession itself so you wouldn't be able to SET the properties in the listener.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Many thanks for the details. My usecase is simple, I like to default the sparkgroupjob Id as openlineage parent runid if there is no parent run Id set. sc.setJobGroup("myjobgroupid", "job description goes here") This set the value in spark as setLocalProperty(SparkContext.SPARKJOBGROUPID, group_id)
I like to use myjobgroup_id as openlineage parent run id
*Thread Reply:* MDC is an ability to add extra key -> value pairs to a log entry, while not doing this within message body. So the question here is (I believe): how to add custom entries / custom facets to OpenLineage events?
@srutikanta hota What information would you like to include? There is great chance we already have some fields for that. If not it’s still worth putting in in write place like: is this info job specific, run specific or relates to some of input / output datasets?
*Thread Reply:* @srutikanta hota sounds like you want to set up
spark.openlineage.parentJobName
spark.openlineage.parentRunId
https://openlineage.io/docs/integrations/spark/
*Thread Reply:* @… we are having a long-running spark context(the context may run for a week) where we submit jobs. Settings the parentrunid at beginning won't help. We are submitting the job with sparkgroupid. I like to use the group Id as parentRunId
https://spark.apache.org/docs/1.6.1/api/R/setJobGroup.html

Hi team - I am from Matillion and we would like to build support for openlineage. Who would be best placed to move the conversation with my product team?
*Thread Reply:* Hi Trevor, thank you for reaching out. I’d be happy to discuss with you how we can help you support OpenLineage. Let me send you an email.
cccccbctlvggfhvrcdlbbvtgeuredtbdjrdfttbnldcb
Hi Everyone! Would anybody be interested in participation in MANTA Open Lineage connector testing? We are specially looking for an environment with rich Airflow implementation but we will be happy to test on any other OL Producer technology. Send me a direct message for more information. Thanks, Petr
Question about Apache Airflow that I think folks here would know, because doing a web search has failed me:
Is there a way to interact with Apache Airflow to retrieve the contents of the files in the sql directory, but NOT to run them?
(the APIs all seem to run sql, and when I search I just get “how to use the airflow API to run queries”)
*Thread Reply:* Is this in the context of an OpenLineage extractor?
*Thread Reply:* Yes! I was specifically looking at the PostgresOperator
*Thread Reply:* (as Snowflake lineage can be retrieved from their internal ACCESS_HISTORY tables, we wouldn’t need to use Airflow’s SnowflakeOperator to get lineage, we’d use the method on the openlineage blog)
*Thread Reply:* The extractor for the SQL operators gets the query like this: https://github.com/OpenLineage/OpenLineage/blob/45fda47d8ef29dd6d25103bb491fb8c443[…]gration/airflow/openlineage/airflow/extractors/sql_extractor.py
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* let me see if I can find the corresponding part of the Airflow API docs...
*Thread Reply:* aha! I’m not so far behind the times, it was only put in during July https://github.com/OpenLineage/OpenLineage/pull/907
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hm. The PostgresOperator seems to extend BaseOperator directly: https://github.com/apache/airflow/blob/029ebacd9cbbb5e307a03530bdaf111c2c3d4f51/airflow/providers/postgres/operators/postgres.py#L58
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* yeah 😞 I couldn’t find a way to make that work as an end-user.
*Thread Reply:* perhaps that can't be assumed for all operators that deal with SQL. I know that @Maciej Obuchowski has spent a lot of time on this.
*Thread Reply:* I don't know enough about the airflow internals 😞
*Thread Reply:* No worries. In case it saves you work, I also had a look at https://github.com/apache/airflow/blob/029ebacd9cbbb5e307a03530bdaf111c2c3d4f51/airflow/providers/common/sql/operators/sql.py - which also extends BaseOperator but not with a way to just get the SQL.
<a href="https://github.com/apache/airflow">apache/airflow</a>

*Thread Reply:* that's more of an Airflow question indeed. As far as I understand you need to read file with SQL statement within Airflow Operator and do something but run the query (like pass as an XCom)? SQLExtractors we have get same SQL that operators render and uses it to extract additional information like table schema straight from database
(I’m also ok with a way to get the SQL that has been run - but from Airflow, not the data source - I’m looking for a db-neutral way to do this, otherwise I can just parse query logs on any specific db system)
👋 are there any docs on how the listener hooks in and gets run with openlineage-airflow? trying to write some unit tests but no docs seem to exist on the flow.
*Thread Reply:* There's a design doc linked from the PR: https://github.com/apache/airflow/pull/20443 https://docs.google.com/document/d/1L3xfdlWVUrdnFXng1Di4nMQYQtzMfhvvWDR9K4wXnDU/edit
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* amazing thank you I will take a look
@channel Hello everyone, I’m opening up a vote on releasing OpenLineage 0.15.0, including • an improved development experience in the Airflow integration • updated proposal and integration templates • a change to the BigQuery client in the Airflow integration • plus bug fixes across the project. 3 +1s from committers will authorize an immediate release. For all the commits, see: https://github.com/OpenLineage/OpenLineage/compare/0.14.0...HEAD. Note: this will be the last release to support Airflow 1.x! Thanks!
*Thread Reply:* Hey @Michael Robinson. Removal of Airflow 1.x support is planned for next release after 0.15.0
*Thread Reply:* 0.15.0 would be the last release supporting Airflow 1.x
*Thread Reply:* just caught this myself. I’ll make the change
*Thread Reply:* we’re still on 1.10.15 at the moment so i guess our team would have to rely on <=0.15.0?
*Thread Reply:* Is this something you want to continue doing or do you want to migrate relatively soon?
We want to remove 1.10 integration because for multiple PRs, maintaining compatibility with it takes a lot of time; the code is littered with checks like this.
if parse_version(AIRFLOW_VERSION) >= parse_version("2.0.0"):
*Thread Reply:* hey Maciej, we do have plans to migrate in the coming months but for right now we need to stay on 1.10.15.
*Thread Reply:* Thanks, all. The release is authorized, and you can expect it by Thursday.
👋 what would be a possible reason for the built in airflow backend being utilized instead of a custom wrapper over airflow.lineage.Backend ? double checked the [lineage] key in our airflow.cfg
there doesn't seem to be any errors being thrown and the object loads 🤔
*Thread Reply:* running airflow 2.3.4 with openlineage-airflow 0.14.1
*Thread Reply:* if you're talking about LineageBackend, it is used in Airflow 2.1-2.2. It did not have functionality where you can be notified on task start or failure, so we wanted to expand the functionality: https://github.com/apache/airflow/issues/17984
Consensus of Airflow maintainers wasn't positive about changing this interface, so we went with another direction: https://github.com/apache/airflow/pull/20443
<a href="https://github.com/apache/airflow">apache/airflow</a>
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* Why nothing happens? https://github.com/OpenLineage/OpenLineage/blob/895160423643398348154a87e0682c3ab5c8704b/integration/airflow/openlineage/lineage_backend/__init__.py#L91
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* ah hmm ok, i will double check. i commented that part out so technically it should run but maybe i missed something
*Thread Reply:* thank you for your fast response @Maciej Obuchowski ! i appreciate it
*Thread Reply:* it seems like it doesn't use my custom wrapper but instead uses the openlineage implementation.
*Thread Reply:* @Maciej Obuchowski ok, after checking we are emitting events with our custom backend but an odd thing is an attempt is always made with the openlineage backend. is there something obvious i am perhaps missing 🤔
ends up with requests.exceptions.HTTPError: 401 Client Error: Unauthorized for url immediately after task start. but by the end on task success/failure it emits the event with our custom backend both RunState.COMPLETE and RunState.START into our own pipeline.
*Thread Reply:* If you're on 2.3 and trying to use some wrapped LineageBackend, what I think is happening is OpenLineagePlugin that automatically registers via setup.py entrypoint https://github.com/OpenLineage/OpenLineage/blob/65a5f021a1ba3035d5198e759587737a05b242e1/integration/airflow/openlineage/airflow/plugin.py#L30
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think if you want to extend it with proprietary code there are two good options.
First, if your code only needs to touch HTTP client side - which I guess is the case due to 401 error - then you can create custom Transport.
Second, is that you fork OL code and create your own package, without entrypoint script or with adding your own if you decide to extend OpenLineagePlugin instead of LineageBackend
*Thread Reply:* amazing thank you for your help. i will take a look
*Thread Reply:* @Maciej Obuchowski is there a way to extend the plugin like how we can wrap the custom backend with 2.2? or would it be necessary to fork it.
we're trying to not fork and instead opt with extending.
*Thread Reply:* I think it's best to fork, since it's getting loaded by Airflow as an entrypoint: https://github.com/OpenLineage/OpenLineage/blob/133110300e8ea4e42e3640608cfed459683d5a8d/integration/airflow/setup.py#L70
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* got it. and in terms of the openlineage.yml and defining a custom transport is there a way i can define where openlineage-python should look for the custom transport? e.g. different path
*Thread Reply:* because from the docs i. can't tell except for the file i'm supposed to copy and implement.
*Thread Reply:* @Paul Lee you should derive from Transport base class and register type as full python import path to your custom transport, for example https://github.com/OpenLineage/OpenLineage/blob/f8533266491acea2159f602f782a99a4f8a82cca/client/python/tests/openlineage.yml#L2
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* your custom transport should have also define custom class Config , and this class should implement from_dict method
*Thread Reply:* the whole process is here: https://github.com/OpenLineage/OpenLineage/blob/a62484ec14359a985d283c639ac7e8b9cfc54c2e/client/python/openlineage/client/transport/factory.py#L47
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* and I know we need to document this better 🙂
*Thread Reply:* amazing, thanks for all your help 🙂 +1 to the docs, if i have some time when done i will push up some docs to document what i've done
*Thread Reply:* https://github.com/openlineage/docs/ - let me know and I'll review 🙂
@channel Hi everyone, opening a vote on a release (0.15.1) to add #1131 to fix the release process on CI. 3 +1s from committers will authorize an immediate release. Thanks. More details are here: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks, all. The release is authorized.
@channel OpenLineage 0.15.1 is now available! We added: • Airflow: improve development experience #1101 @JDarDagran • Documentation: update issue templates for proposal & add new integration template #1116 @rossturk • Spark: add description for URL parameters in readme, change overwriteName to appName #1130 @tnazarew We changed: • Airflow: lazy load BigQuery client #1119 @mobuchowski Many bug fixes were also included in this release. Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.15.1 Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.14.1...0.15.1 Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage PyPI: https://pypi.org/project/openlineage-python/
Is there a topic you think the community should discuss at the next OpenLineage TSC meeting? Reply or DM with your item, and we’ll add it to the agenda.
*Thread Reply:* would love to add improvement in docs :) for newcomers
*Thread Reply:* Technical Steering Committee, but it’s open to everyone
*Thread Reply:* and we encourage newcomers to attend
has anyone seen their COMPLETE/FAILED listeners not firing on Airflow 2.3.4 but START events do emit? using openlineage-airflow 0.14.1
*Thread Reply:* is there any error/warn message logged maybe?
*Thread Reply:* none that i'm seeing on our workers. i do see that our custom http transport is being utilized on START.
but on SUCCESS nothing fires.
*Thread Reply:* which makes me believe the listeners themselves aren't being utilized? 🤔
*Thread Reply:* uhm, any chance you're experiencing this with custom extractors?
*Thread Reply:* I'd be happy to jump on a quick call if you wish
*Thread Reply:* but in more EU friendly hours 🙂
*Thread Reply:* no custom extractors, its usingt he base extractor. a call would be 👍. let me look at my calendar and EU hours.
@channel The next OpenLineage Technical Steering Committee meeting is on Thursday, October 13 at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom All are welcome! Agenda:
- Announcements
- Recent Release 0.15.1
- Project roadmap review
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda.

hello all. I am trying to run the airflow example from here
I changed the Marquez web port from 5000 to 15000 but when I start the docker images, it seems to always default to port 5000 and therefore when I go to localhost:3000, the jobs don't load up as they are not able to connect to the marquez app running in 15000. I've overriden the values in docker-compose.yml and in openLineage.env but it seems to be picking up the 5000 value from some other location.
This is what I see in the logs. Any pointers on this or please redirect me to the appropriate channel. Thanks!
INFO [2022-10-07 10:48:58,022] org.eclipse.jetty.server.AbstractConnector: Started application@782fd504{HTTP/1.1, (http/1.1)}{0.0.0.0:5000}
INFO [2022-10-07 10:48:58,034] org.eclipse.jetty.server.AbstractConnector: Started admin@1537c744{HTTP/1.1, (http/1.1)}{0.0.0.0:5001}
Hi #general - @Will Johnson and I are working on adding support for Snowflake to OL, and as we were going to specify the package under the compileOnly dependencies in gradle, we had some doubts looking at the existing dependencies. Taking bigQuery as an example - we see it's included as a dependency in both the shared build.gradle file, and in the app build.gradle file. We're a bit confused about the following:
- Why do we need to have the bigQuery package in shared's dependencies? App of course contains the
bigQueryNodeVisitorbut we couldn't spot where it's being used within shared. - For all the dependencies in the shared gradle file, the versions for Scala and Spark are fixed (Scala 2.11, Spark 2.4.8), whereas for app, the
versionsMapallows for different combinations of spark and scala versions. Why is this so? - How do the dependencies between app and shared interact? Does one or the other take precedence for which version of the bigQuery connector is compiled? We'd appreciate any guidance!
Thank you in advance!
*Thread Reply:* Hi @Hanna Moazam,
Within recent PR https://github.com/OpenLineage/OpenLineage/pull/1111, I removed BigQuery dependencies from spark2, spark32 and spark3 subprojects. It has to stay in sharedbecause of BigQueryNodeVisitor. The usage of BigQueryNodeVisitor is tricky as we never know if bigquery classes are available on runtime or not. The check is done in io.openlineage.spark.agent.lifecycle.BaseVisitorFactory
if (BigQueryNodeVisitor.hasBigQueryClasses()) {
list.add(new BigQueryNodeVisitor(context, factory));
}
Regarding point 2, there were some Spark versions which allowed two Scala versions (2.11 and 2.12). Then it makes sense to make it configurable. On the other hand, for Spark 3.2 we only support 2.12 which is hardcoded in build.gradle.
The idea of app project is let's create a separate project to aggregate all the dependecies and run integration tests on it . Subprojects spark2, spark3, etc. do depend on shared . Putting integration tests in shared would create additional opposite-way dependency, which we wanted to avoid.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* So, if we wanted to add Snowflake, we would need to:
- Pick a version of snowflake's spark library
- Pick a version of scala that we target (i.e. we are only going to support Snowflake in Spark 3.2 so scala 2.12 will be hard coded)
- Add the visitor code to Shared
- Add the dependencies to app (ONLY if there is an integration test in app?? This is the confusing part still)
*Thread Reply:* Yes. Please note that snowflake library will not be included in target OpenLineage jar. So you may test it manually against multiple Snowflake library versions or even adjust code in case of minor differences.
*Thread Reply:* Basically the same pattern you've already done with Kusto 😉 https://github.com/OpenLineage/OpenLineage/blob/a96ecdabe66567151e7739e25cd9dd03d6[…]va/io/openlineage/spark/agent/lifecycle/BaseVisitorFactory.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* We actually used only reflection for Kusto and were hoping to do it the 'better' way with the package itself for snowflake - if it's possible :)

Hi Community,
I was going through the code of dbt integration with Open lineage, Once the events has been emitted from client code , I wanted to check the server code where the events are read and the lineage is formed. Where can I find that code ?
Thanks
*Thread Reply:* Reference implementation of OpenLineage consumer is Marquez: https://github.com/MarquezProject/marquez
This month’s OpenLineage TSC meeting is tomorrow at 10 am PT! https://openlineage.slack.com/archives/C01CK9T7HKR/p1665084207602369
Is there anyone in the Open Lineage community in San Diego? I’ll be there Nov 1-3 and would love to meet some of y’all in person
👋 is there a way to define a base extractor to be defaulted to? for example, i'd like to have all our operators (50+) default to my custom base extractor instead of having a list of 50+ operators in get_operator_classnames
I don't think that's possible yet, as the extractor checks are based on the class name... and it wouldn't check which parent operator has it inherited from.
😢 ok, i would contribute upstream but unfortunately we're still on 1.10.15. looking like we might have to hardcode for a bit.
is this the correct assumption? we're still on 0.14.1 ^
If you'll move to 2.x series and OpenLineage 0.16, you could use this feature: https://github.com/OpenLineage/OpenLineage/pull/1162
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
thanks @Maciej Obuchowski we're working on it. hoping we'll land on 2.3.4 in the coming month.

👋 Hi everyone!
*Thread Reply:* Hey @Austin Poulton, welcome! 👋
@channel
Hi everyone, I’m opening a vote to release OpenLineage 0.16.0, featuring:
• support for boolean arguments in the DefaultExtractor
• a more efficient get_connection_uri method in the Airflow integration
• a reorganized, Rust-based SQL integration (easing the addition of language interfaces in the future)
• bug fixes and more.
3 +1s from committers will authorize an immediate release. Thanks. More details are here:
https://github.com/OpenLineage/OpenLineage/compare/0.15.1...HEAD
*Thread Reply:* Thanks, all! The release is authorized. We will initiate it within 48 hours.
Anybody with a success use-case of ingesting column-level lineage into amundsen?
*Thread Reply:* I think amundsen-openlineage dataloader precedes column-level lineage in OL by a bit, so I doubt this works
*Thread Reply:* do you want to open up an issue for it @Iftach Schonbaum?
Hi everyone, you might notice Dependabot opening PRs to update dependencies now that it’s been configured and turned on (https://github.com/OpenLineage/OpenLineage/pull/1182). There will probably be a large number of PRs to start with, but this shouldn’t always be the case and we can change the tool’s behavior, as well. (Some background: this will help us earn the OSSF Silver badge for the project, which will help us advance in the LFAI.)
@channel I’m opening a vote to release OpenLineage 0.16.1 to fix an issue in the SQL integration. This release will also include all the commits announced for 0.16.0. 3 +1s from committers will authorize an immediate release. Thanks.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks, all. The release is authorized and will be initiated shortly.
@channel
OpenLineage 0.16.1 is now available, featuring:
Additions:
• Airflow: add dag_run information to Airflow version run facet #1133 @fm100
• Airflow: add LoggingMixin to extractors #1149 @JDarDagran
• Airflow: add default extractor #1162 @mobuchowski
• Airflow: add on_complete argument in DefaultExtractor #1188 @JDarDagran
• SQL: reorganize the library into multiple packages #1167 @StarostaGit @mobuchowski
Changes:
• Airflow: move get_connection_uri as extractor’s classmethod #1169 @JDarDagran
• Airflow: change get_openlineage_facets_on_start/complete behavior #1201 @JDarDagran
Bug fixes and more!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.16.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.15.1...0.16.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

Are there any tutorial and documentation how to create an Openlinage connector. For example, what if we Argo workflow instead of Apache airflow for orchestrating ETL jobs? How are we going to create Openlinage Argo workflow connector? How much efforts, roughly? And can people contribute such connectors to the community if they create one?
*Thread Reply:* > Are there any tutorial and documentation how to create an Openlinage connector. We have somewhat of a start of a doc: https://openlineage.io/docs/development/developing/
Here we have an example of using Python OL client to emit OL events: https://openlineage.io/docs/client/python#start-docker-and-marquez
> How much efforts, roughly? I'm not familiar with Argo workflows, but usually the effort needed depends on extensibility of the underlying system. From the first look, Argo looks like it has sufficient mechanisms for that: https://argoproj.github.io/argo-workflows/executor_plugins/#examples-and-community-contributed-plugins
Then, it depends if you can get the information that you need in that plugin. Basic need is to have information from which datasets the workflow/job is reading and to which datasets it's writing.
> And can people contribute such connectors to the community if they create one? Definitely! And if you need help with anything OpenLineage feel free to write here on Slack
Is there a topic you think the community should discuss at the next OpenLineage TSC meeting? Reply or DM with your item, and we’ll add it to the agenda.
@channel This month’s OpenLineage TSC meeting is next Thursday, November 10th, at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom. All are welcome! On the tentative agenda:
- Recent release overview [Michael R.]
- Update on LFAI & Data Foundation progress [Michael R.]
- Proposal: Defining “implementing OpenLineage” [Julien]
- Update from MANTA on their OpenLineage integration [Eric and/or Petr from MANTA]
- Linking CMF (a common ML metadata framework) and OpenLineage [Suparna and AnnMary from HP Enterprise]
- Open discussion
Hi all 👋 I’m Kenton — a Software Engineer and founder of Swiple. I’m looking forward to working with OpenLineage and its community to integrate data lineage and data observability. https://swiple.io
*Thread Reply:* Welcome Kenton! Happy to help 👍

Hi everyone, We wanted to pass some dynamic metadata from spark job that we can catch up in OpenLineage event and use it for processing. Presently I have seen that we have few conf parameters like openlineage params that we can send only with Spark conf. Is there any other option we have where we can send some information dynamically from the spark jobs.
*Thread Reply:* What kind of data? My first feeling is that you need to extend the Spark integration
*Thread Reply:* Yes, we wanted to add information like user/job description that we can use later with rest of openlineage event fields in our system
*Thread Reply:* I can see in this PR https://github.com/OpenLineage/OpenLineage/pull/490 that env values can be captured which we can use to add some custom metadata but it seems it is specific to Databricks only.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think it makes sense to have something like that, but generic, if you want to contribute it
*Thread Reply:* @Maciej Obuchowski Do you mean adding something like
spark.openlineage.jobFacet.FacetName.Key=Value to the spark conf should add a new job facet like
"FacetName": {
"Key": "Value"
}
*Thread Reply:* We can argue about name of that key, but yes, something like that. Just notice that while it's possible to attach something to run and job facets directly, it would be much harder to do this with datasets
*Thread Reply:* Hi @Varun Singh, what version of openlineage-spark where you using? Are you able to copy lineage event here?
@channel This month’s TSC meeting is tomorrow at 10 am PT! https://openlineage.slack.com/archives/C01CK9T7HKR/p1667512998061829
Hi #general, quick question: do we plan to disable spark 2 support in the near future?
Longer question: I've recently made a PR (https://github.com/OpenLineage/OpenLineage/pull/1231) to support capturing lineage from Snowflake, but it fails at a specific integration test due to what we think is a dependency mismatch for guava. I've tried to exclude any transient dependencies which may cause the problem but no luck with that so far.
Just wondering if:
- It makes sense to spend more time trying to ensure that test passes? Especially if we plan to remove spark 2 support soon.
- Assuming we do want to make sure to pass the test, does anyone have any other ideas for where to look/modify to prevent the error? Here's the test failure message: ```io.openlineage.spark.agent.lifecycle.LibraryTest testRdd(SparkSession) FAILED (16s)
java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.<init>()V from class org.apache.hadoop.mapred.FileInputFormat at io.openlineage.spark.agent.lifecycle.LibraryTest.testRdd(LibraryTest.java:113) ``` Thanks in advance!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* What if we just not include it in the BaseVisitorFactory but only in the Spark3 visitor factories?
quick question: how do i get the <<non-serializable Time...to show in the extraction? or really any object that gets passed in.
*Thread Reply:* You might look here: https://github.com/OpenLineage/OpenLineage/blob/f7049c599a0b1416408860427f0759624326677d/client/python/openlineage/client/serde.py#L51
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Is there a way I can update the detaset description and the column description. While generating the open lineage spark events and columns
*Thread Reply:* I don’t think this is possible at the moment.
Hey all, I'd like to ask for a release for OpenLineage. #1256 fixes bug in DefaultExtractor. This blocks people from migrating code from custom extractors to get_openlineage_facets methods.
*Thread Reply:* Thanks, all. The release is authorized.
*Thread Reply:* The PR for the changelog updates: https://github.com/OpenLineage/OpenLineage/pull/1306
Hi, small question: Is it possible to disable the /api/{version}/lineage suffix that gets added to every url automatically? Thanks!
*Thread Reply:* I think we had similar request before, but nothing was implemented.
@channel
OpenLineage 0.17.0 is now available, featuring:
Additions:
• Spark: support latest Spark 3.3.1 #1183 @pawel-big-lebowski
• Spark: add Kinesis Transport and support config Kinesis in Spark integration #1200 @yogyang
• Spark: disable specified facets #1271 @pawel-big-lebowski
• Python: add facets implementation to Python client #1233 @pawel-big-lebowski
• SQL: add Rust parser interface #1172 @StarostaGit @mobuchowski
• Proxy: add helm chart for the proxy backend #1068 @wslulciuc
• Spec: include possible facets usage in spec #1249 @pawel-big-lebowski
• Website: publish YML version of spec to website #1300 @rossturk
• Docs: update language on nominating new committers #1270 @rossturk
Changes:
• Website: publish spec into new website repo location #1295 @rossturk
• Airflow: change how pip installs packages in tox environments #1302 @JDarDagran
Removals:
• Deprecate HttpTransport.Builder in favor of HttpConfig #1287 @collado-mike
Bug fixes and more!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.17.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.16.1...0.17.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

Hi everyone,
I'm trying to get the lineage of a dataset per version. I initially had something like
Dataset A -> Dataset B -> DataSet C (version 1)
then:
Dataset D -> Dataset E -> DataSet C (version 2)
I can get the graph for version 2 without problems, but I'm wondering if there's any way to retrieve the entire graph for DataSet C version 1.
Thanks
*Thread Reply:* It's kind of a hard problem UI side. Backend can express that relationship
*Thread Reply:* Thanks for replying. Could you please point me to the API that allows me to do that? I've been calling GET /lineage with dataset in the node ID, e g., nodeId=dataset:my_dataset . Where could I specify the version of my dataset?
👋 how do we get the actual values from macros? e.g. a schema name is passed in with {{params.table_name}} and thats what shows in lineage instead of the actual table name
*Thread Reply:* Templated fields are rendered before generating lineage data. Do you have some sample code or logs preferrably?
*Thread Reply:* If you're on 1.10 then I think it won't work
*Thread Reply:* @Maciej Obuchowski we are still on airflow 1.10.15 unfortunately.
cc. @Eli Schachar @Allison Suarez
*Thread Reply:* is there no workaround we can make work?
*Thread Reply:* @Jakub Dardziński is this for airflow versions 2.0+?
Hey, quick question: I see there is Kafka transport in the java client, but it's not supported in the spark integration, right?
*Thread Reply:* Yeah. However, to add it, just tiny bit of code would be required.
Either in the URL version https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/main/java/io/openlineage/spark/agent/EventEmitter.java#L48
Or as separate Spark config entry: https://github.com/OpenLineage/OpenLineage/blob/182d2e5a907e6602f7fe132e07ea569c7e[…]n/java/io/openlineage/spark/agent/OpenLineageSparkListener.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
How can we auto instrument a dataset owner at Java agent level? Is there any spark property available?
Is there a way if we are running a job with business day as yesterday to capture the information. Just think if I am running yesterday missing job today. Or Friday's file on Monday as we received file late from vendor etc..
*Thread Reply:* I think that's what NominalTimeFacet covers

hello Team, i wanna to use data lineage using airflow but not getting understand from docs please let me know if someone have pretty docs
*Thread Reply:* Hey @Rahul Sharma, what version of Airflow are you running?
*Thread Reply:* i am using airflow 2.x
*Thread Reply:* can we connect if you have time ?
*Thread Reply:* did you see these docs before? https://openlineage.io/integration/apache-airflow/#airflow-20
*Thread Reply:* i already set configuration in airflow.cfg file
*Thread Reply:* where are you sending the events to?
*Thread Reply:* i have a docker machine on which marquez is working
*Thread Reply:* so, what is the issue you are seeing?
*Thread Reply:* ```[lineage]
what lineage backend to use
backend =openlineage.lineage_backend.OpenLineageBackend
MARQUEZ_URL=http://10.36.37.178:3000
MARQUEZ_NAMESPACE=airflow
MARQUEZBACKEND=HTTP MARQUEZURL=http://10.36.37.178:5000
MARQUEZAPIKEY=[YOURAPIKEY]
MARQUEZ_NAMESPACE=airflow```
*Thread Reply:* above config i have set
*Thread Reply:* please let me know any other thing need to do

hey i wonder if somebody can link me to the lineage ( table lineage ) event schema ?
*Thread Reply:* please have a look at openapi definition of the event: https://openlineage.io/apidocs/openapi/

Hello Team, I am from Genpact Data Analytics team, we are looking for demo of your product
Hello all, I’m calling for a vote on releasing OpenLineage 0.18.0, including: • improvements to the Spark integration, • extractors for Sagemaker operators and SFTPOperator in the Airflow integration, • a change to the Databricks integration to support Databricks Runtime 11.3, • new governance docs, • bug fixes, • and more. Three +1s from committers will authorize an immediate release.
*Thread Reply:* Thanks, all. The release is authorized will be initiated within two business days.
@channel This month’s OpenLineage TSC meeting is next Thursday, December 8th, at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom. All are welcome! On the tentative agenda:
- an overview of the new Rust implementation of the SQL integration
- a pesentation/discussion of what it actually means to “implement” OpenLineage
- open discussion.

Hello everyone! General question here, aside from ‘consumer’ orgs/integrations (dbt/dagster/manta), is anyone aware of any enterprise organizations that are leveraging OpenLineage today? Example lighthouse brands?
*Thread Reply:* Microsoft https://openlineage.io/blog/openlineage-microsoft-purview/
*Thread Reply:* I think we can share that we have over 2,000 installs of that Microsoft solution accelerator using OpenLineage.
That means we have thousands of companies having experimented with OpenLineage and Microsoft Purview.
We can't name any customers at this point unfortunately.
@channel This month’s TSC meeting is tomorrow at 10 am PT. All are welcome! https://openlineage.slack.com/archives/C01CK9T7HKR/p1669925470878699
*Thread Reply:* For open discussion, I'd like to ask the team for an overview of how the different gradle files are working together for the Spark implementation. I'm terribly confused on where dependencies need to be added (whether it's in shared, app, or a spark version specific folder). Maybe @Maciej Obuchowski...?
*Thread Reply:* Unfortunately I'll be unable to attend the meeting @Will Johnson 😞
*Thread Reply:* This is starting now. CC @Will Johnson
*Thread Reply:* @Will Johnson Check the notes and the recording. @Michael Collado did a pass at explaining the relationship between shared, app and the versions
*Thread Reply:* feel free to follow up here as well
*Thread Reply:* ascii art to the rescue! (top “depends on” bottom)
/ \
/ / \ \
/ / \ \
/ / \ \
/ / \ \
/ | | \
/ | | \
/ | | \
/ | | \
/ | | \
/ | | \
/ | | \
spark2 spark3 spark32 spark33
\ | | /
\ | | /
\ | | /
\ | | /
\ | | /
\ | | /
\ | | /
\ | / /
\ \ / /
\ \ / /
\ \ / /
\ /
\ /
share
*Thread Reply:* (btw, we should have written datakin to output ascii art; it’s obviously the superior way to generate graphs 😜)

*Thread Reply:* Hi, is there a recording for this meeting?

Hi! I have a basic question about the naming conventions for blob storage. The spec is not totally clear to me. Is the convention to use (1) namespace=bucket name=bucket+path or (2) namespace=bucket name=path?
*Thread Reply:* The namespace is the bucket and the dataset name is the path. Is there a blob storage provider in particular you are thinking of?
*Thread Reply:* Thanks, that makes sense. We use GCS, so it is already covered by the naming conventions documented. I was just not sure if I was understanding the document correctly or not.
*Thread Reply:* No problem. Let us know if you have suggestions on the wording to make the doc clearer
@channel
OpenLineage 0.18.0 is available now, featuring:
• Airflow: support SQLExecuteQueryOperator #1379 @JDarDagran
• Airflow: introduce a new extractor for SFTPOperator #1263 @sekikn
• Airflow: add Sagemaker extractors #1136 @fhoda
• Airflow: add S3 extractor for Airflow operators #1166 @fhoda
• Spec: add spec file for ExternalQueryRunFacet #1262 @howardyoo
• Docs: add a TSC doc #1303 @merobi-hub
• Plus bug fixes.
Thanks to all our contributors, including new contributor @Faisal Hoda!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.18.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.17.0...0.18.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
1) Is there a specifications to capture dataset dependency. ds1 is dependent on ds2
*Thread Reply:* Dataset dependencies are represented through common relationship with a Job - e.g., the task that performed the transformation.
*Thread Reply:* Is it possible to populate table level dependency without any transformation using open lineage specifications? Like to define dataset 1 is dependent of table 1 and table 2 which can be represented as separate datasets
*Thread Reply:* Not explicitly, in today's spec. The guiding principle is that something created that dependency, and the dependency changes over time in a way that is important to study.
*Thread Reply:* I say this to explain why it is the way it is - but the spec can change over time to serve new uses cases, certainly!
Hi everyone, I'd like to use openlineage to capture column level lineage for spark. I would also like to capture a few custom environment variables along with the column lineage. May I know how this can be done? Thanks!
*Thread Reply:* Hi @Anirudh Shrinivason, you could start with column-lineage & spark workshop available here -> https://github.com/OpenLineage/workshops/tree/main/spark
*Thread Reply:* Hi @Paweł Leszczyński Thanks for the link! But this does not really answer the concern.
*Thread Reply:* I am already able to capture column lineage
*Thread Reply:* What I would like is to capture some extra environment variables, and send it to the server along with the lineage
*Thread Reply:* i remember we already have a facet for that: https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/main/java/io/openlineage/spark/agent/facets/EnvironmentFacet.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* but it is only used at the moment to capture some databricks environment attributes
*Thread Reply:* so you can contribute to project and add a feature which adds specified/al environment variables to lineage event.
you can also have a look at extending section of spark integration docs (https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#extending) and create a class thats add run facet builder according to your needs.
*Thread Reply:* the third way is to create an issue related to this bcz being able to send selected/all environment variables in OL event seems to be really cool feature.
*Thread Reply:* That is great! Thank you so much! This really helps!
*Thread Reply:* List<String> dbPropertiesKeys =
Arrays.asList(
"orgId",
"spark.databricks.clusterUsageTags.clusterOwnerOrgId",
"spark.databricks.notebook.path",
"spark.databricks.job.type",
"spark.databricks.job.id",
"spark.databricks.job.runId",
"user",
"userId",
"spark.databricks.clusterUsageTags.clusterName",
"spark.databricks.clusterUsageTags.azureSubscriptionId");
dbPropertiesKeys.stream()
.forEach(
(p) -> {
dbProperties.put(p, jobStart.properties().getProperty(p));
});
It seems like it is obtaining these env variable information from the jobStart obj, but not capturing from the env directly?
*Thread Reply:* I have opened an issue in the community here: https://github.com/OpenLineage/OpenLineage/issues/1419
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Paweł Leszczyński I have opened a PR for helping to add this use case. Please do help to see if we can merge it in. Thanks! https://github.com/OpenLineage/OpenLineage/pull/1545
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hey @Anirudh Shrinivason, sorry for late reply, but I reviewed the PR.
*Thread Reply:* Hey thanks a lot! I have made the requested changes! Thanks!
*Thread Reply:* @Maciej Obuchowski ^ 🙂
*Thread Reply:* Hey @Anirudh Shrinivason, took a look at it but it unfortunately fails integration tests (throws NPE), can you take a look again?
23/02/06 12:18:39 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
java.lang.NullPointerException
at io.openlineage.spark.agent.EventEmitter.<init>(EventEmitter.java:39)
at io.openlineage.spark.agent.OpenLineageSparkListener.initializeContextFactoryIfNotInitialized(OpenLineageSparkListener.java:276)
at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:80)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:100)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117)
at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101)
at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1433)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
*Thread Reply:* Hi yeah my bad. It should be fixed in the latest push. But I think the tests are not running in the CI because of some GCP environment issue? I am not really sure how to fix it...
*Thread Reply:* I can make them run, it's just that running them on forks is disabled. We need to make it more clear I suppose
*Thread Reply:* Ahh I see thanks! Also, some of the tests are failing on my local, such as https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/test/java/io/openlineage/spark/agent/lifecycle/DeltaDataSourceTest.java. Is this expected behaviour?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* tests failing isn't expected behaviour 🙂
*Thread Reply:* Ahh yeap it was a local ide issue on my side. I added some tests to verify the presence of env variables too.
*Thread Reply:* @Anirudh Shrinivason let me know then when you'll push fixed version, I can run full tests then
*Thread Reply:* I have pushed just now
*Thread Reply:* You can run the tests
*Thread Reply:* @Maciej Obuchowski mb I pushed again rn. Missed out a closing bracket.
*Thread Reply:* @Maciej Obuchowski Hi, could we merge this PR in? I'd like to see if we can have these changes in the new release...

Hi All- I am sending lineage from ADF for each activity which i am performing. But the individual activities are representing correctly. How can I represent task1 as a parent to task2. can someone please share the sample json request for it.
*Thread Reply:* Hi 👋 this would require a series of JSON calls:
- start the first task
- end the first task, specify output dataset
- start the second task, specify input dataset
- end the second task
*Thread Reply:* in OpenLineage relationships are typically Job -> Dataset -> Job, so • you create a relationship between datasets by referring to them in the same job - i.e., this task ran that read from these datasets and wrote to those datasets • you create a relationship between tasks by referring to the same datasets across both of them - i.e., this task wrote that dataset and this other task read from it
*Thread Reply:* @Bramha Aelem if you look in this directory, you can find example start/complete JSON calls that show how to specify input/output datasets.
(it’s an airflow workshop, but those examples are for a part of the workshop that doesn’t involve airflow)
*Thread Reply:* (these can also be found in the docs)
*Thread Reply:* @Ross Turk - Thanks for the details. will try and get back to you on it
*Thread Reply:* @Ross Turk - Good Evening, It worked as expected. I am able to replicate the scenarios which I am looking for.
*Thread Reply:* @Ross Turk - Thanks for your response.
*Thread Reply:* @Ross Turk - First activity : I am making HTTP Call to pull the lookup data and store it in ADLS. Second Activity : After the completion of first activity I am making Azure databricks call to use the lookup file and generate the output tables. How I can refer the databricks generated tables facets as an input to the subsequent activities in the pipeline. When I refer it's as an input the spark tables metadata is not showing up. How can this be achievable. After the execution of each activity in ADF Pipeline I am sending start and complete/fail event lineage to Marquez.
Can someone please guide me on this.
I am not using airflow in my Process. pls suggest
Hi All - Good Morning, how the column lineage of data source when it ran by different teams and jobs in openlineage.

Hey folks! I'm al from Koii.network, very happy to have heard about this project :)
*Thread Reply:* welcome! let’s us know if you have any questions

Hello! I found the OpenLineage project today after searching for “OpenTelemetry” in the dbt Slack.
*Thread Reply:* Hey Matt! Happy to have you here! Feel free to reach out if you have any questions

Hi guys - I am really excited to test open lineage. I had a quick question, sorry if this is not the right place for it. We are testing dbt-ol with airflow and I was hoping this would by default push the number of rows updated/created in that dbt transformation to marquez. It runs fine on airflow, but when I check in marquez there doesn't seem to be a 'dataset' created, only 'jobs' with job level metadata. When i check here I see that the dataset facets should have it though https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md Does anyone know if creating a dataset & sending row counts to OL is out of the box on dbt-ol or if I need to build another script to get that number from my snowflake instance and push it to OL as another step in my process? Thanks a lot!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

*Thread Reply:* @Ross Turk maybe you can help with this?
*Thread Reply:* hmm, I believe the dbt-ol integration does capture bytes/rows, but only for some data sources: https://github.com/OpenLineage/OpenLineage/blob/6ae1fd5665d5fd539b05d044f9b6fb831ce9d475/integration/common/openlineage/common/provider/dbt.py#L567
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I haven't personally tried it with Snowflake in a few versions, but the code suggests that it's one of them.
*Thread Reply:* @Max you say your dbt-ol run is resulting in only jobs and no datasets emitted, is that correct?
*Thread Reply:* if so, I'd say something rather strange is going on because in my experience each model should result in a Job and a Dataset.

Hi All, Curious to see if there is an openlineage integration with luigi or any open source projects working on it.
*Thread Reply:* I was looking for something similar to the airflow integration
*Thread Reply:* hey @Kuldeep - i don't think there's something for Luigi right now - is that something you'd potentially be interested in?
*Thread Reply:* @Viraj Parekh Yes this is something we are interested in! There are a lot of projects out there that use luigi
Hello all, I’m opening a vote to release OpenLineage 0.19.0, including:
• new extractors for Trino and S3FileTransformOperator in the Airflow integration
• a new, standardized run facet in the Airflow integration
• a new NominalTimeRunFacet and OwnershipJobFacet in the Airflow integration
• Postgres support in the dbt integration
• a new client-side proxy (skeletal version)
• a new, improved mechanism for passing conf parameters to the OpenLineage client in the Spark integration
• a new ExtractionErrorRunFacet to reflect internal processing errors for the SQL parser
• testing improvements, bug fixes and more.
As always, three +1s from committers will authorize an immediate release. Thanks in advance!
*Thread Reply:* Hi @Michael Robinson a new, improved mechanism for passing conf parameters to the OpenLineage client in the Spark integration
Would it be possible to have more details on what this entails please? Thanks!
*Thread Reply:* @Tomasz Nazarewicz might explain this better
*Thread Reply:* @Anirudh Shrinivason until now If you wanted to add new property to OL client, you had to also implement it in the integration because it had to parse all properties, create appropriate objects etc. New implementation makes client properties transparent to integration, they are only passed through and parsing happens inside the client.
*Thread Reply:* Thanks, all. The release is authorized and will commence shortly 🙂
*Thread Reply:* @Tomasz Nazarewicz Ahh I see. Okay thanks!
@channel This month’s OpenLineage TSC meeting is next Thursday, January 12th, at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom. All are welcome! On the tentative agenda:
- Recent release overview @Michael Robinson
- Column lineage update @Maciej Obuchowski
- Airflow integration improvements @Jakub Dardziński
- Discussions: • Real-world implementation of OpenLineage (What does it really mean?) @Sheeri Cabral (Collibra) • Using namespaces @Michael Robinson
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda.
*Thread Reply:* @Michael Robinson Will there be a recording?
*Thread Reply:* @Anirudh Shrinivason Yes, and the recording will be here: https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting
OpenLineage 0.19.2 is available now, including:
• Airflow: add Trino extractor #1288 @sekikn
• Airflow: add S3FileTransformOperator extractor #1450 @sekikn
• Airflow: add standardized run facet #1413 @JDarDagran
• Airflow: add NominalTimeRunFacet and OwnershipJobFacet #1410 @JDarDagran
• dbt: add support for postgres datasources #1417 @julienledem
• Proxy: add client-side proxy (skeletal version) #1439 #1420 @fm100
• Proxy: add CI job to publish Docker image #1086 @wslulciuc
• SQL: add ExtractionErrorRunFacet #1442 @mobuchowski
• SQL: add column-level lineage to SQL parser #1432 #1461 @mobuchowski @StarostaGit
• Spark: pass config parameters to the OL client #1383 @tnazarew
• Plus bug fixes and testing and CI improvements.
Thanks to all the contributors, including new contributor Saurabh (@versaurabh)
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.19.2
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.18.0...0.19.2
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Question on Spark Integration and External Hive Metastores
@Hanna Moazam and I are working with a team using OpenLineage and wants to extract out the server name of the hive metastore they're using when writing to a Hive table through Spark.
For example, the hive metastore is an Azure SQL database and the table name is sales.transactions.
OpenLineage will give something like /usr/hive/warehouse/sales.db/transactions for the name.
However, this is not a complete picture since sales.db/transactions is defined like this for a given hive metastore. In Hive, you'd define the fully qualified name as sales.transactions@sqlservername.database.windows.net .
Has anyone else come across this before? If not, we plan on raising an issue and suggesting we extract out the spark.hadoop.javax.jdo.option.ConnectionURL in the DatabricksEnvironmentFacetBuilder but ideally there would be a better way of extracting this.
There was an issue by @Maciej Obuchowski or @Paweł Leszczyński that talked about providing a facet of the alias of a path but I can't find it at this point :(
*Thread Reply:* Hi @Hanna Moazam, we've written Jupyter notebook to demo dataset symlinks feature: https://github.com/OpenLineage/workshops/blob/main/spark/dataset_symlinks.ipynb
For scenario you describe, there should be symlink facet sent similar to:
{
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/0.15.1/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet>",
"identifiers": [
{
"namespace": "<hive://metastore>",
"name": "default.some_table",
"type": "TABLE"
}
]
}
Within Openlineage Spark integration code, symlinks are included here:
https://github.com/OpenLineage/OpenLineage/blob/0.19.2/integration/spark/shared/src/main/java/io/openlineage/spark/agent/util/PathUtils.java#L75
and they are added only when spark catalog is hive and metastore URI in spark conf is present.
<a href="https://github.com/OpenLineage/workshops">OpenLineage/workshops</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* This is so awesome, @Paweł Leszczyński - Thank you so much for sharing this! I'm wondering if we could extend this to capture the hive JDBC Connection URL. I will explore this and put in an issue and PR to try and extend it. Thank you for the insights!
@channel Friendly reminder: this month’s OpenLineage TSC meeting is tomorrow at 10am, and all are welcome. https://openlineage.slack.com/archives/C01CK9T7HKR/p1672933029317449
Hi, are there any plans to add an Azure EventHub transport similar to the Kinesis one?
*Thread Reply:* @Varun Singh why not just use the KafkaTransport and the Event Hub's Kafka endpoint?
https://learn.microsoft.com/en-us/azure/event-hubs/event-hubs-kafka-stream-analytics
<a href="https://github.com/yogyang/OpenLineage">yogyang/OpenLineage</a>
Following up on last month’s discussion (
*Thread Reply:* @Julien Le Dem is there a channel to discuss the community call / ask follow-up questions on the communiyt call topics? For example, I wanted to ask more about the AirflowFacet and if we expected to introduce more tool specific facets into the spec. Where's the right place to ask that question? On the PR?
*Thread Reply:* I think asking in #general is the right place. If there’s a specific github issue/PR, his is a good place as well. You can tag the relevant folks as well to get their attention

@here I am using the Spark listener and whenever a query like INSERT OVERWRITE TABLE gets executed it looks like I can see some outputs, but there are no symlinks for the output table. The operation type being executed is InsertIntoHadoopFsRelationCommand . I am not sure why I cna see symlinks for all the input tables but not the output tables. Anyone know the reason behind this?
*Thread Reply:* Hello @Allison Suarez, in case of InsertIntoHadoopFsRelationCommand, Spark Openlineage implementation uses method:
DatasetIdentifier di = PathUtils.fromURI(command.outputPath().toUri(), "file");
(https://github.com/OpenLineage/OpenLineage/blob/0.19.2/integration/spark/shared/sr[…]ark/agent/lifecycle/plan/InsertIntoHadoopFsRelationVisitor.java)
If the dataset identifier is constructed from a path, then no symlinks are added. That's the current behaviour.
Calling io.openlineage.spark.agent.util.DatasetIdentifier#withSymlink(io.openlineage.spark.agent.util.DatasetIdentifier.Symlink) on DatasretIdentifier in InsertIntoHadoopFsRelationVisitor
could be a remedy to that.
Do you have some Spark code snippet to reproduce this issue?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Allison Suarez it would also be good to know what compute engine you're using to run your code on? On-Prem Apache Spark? Azure/AWS/GCP Databricks?
*Thread Reply:* I created a custom visitor and fixed the issue that way, thank you!
Hi, I am trying to use kafka transport in spark for sending events to an EventHub but it requires me to set a property sasl.jaas.config which needs to have semicolons (;) in its value. But this gives an error about being unable to convert Array to a String. I think this is due to this line which splits property values into an array if they have a semicolon https://github.com/OpenLineage/OpenLineage/blob/92adbc877f0f4008928a420a1b8a93f394[…]pp/src/main/java/io/openlineage/spark/agent/ArgumentParser.java
Does this seem like a bug or is it intentional?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* seems like a bug to me, but tagging @Tomasz Nazarewicz / @Paweł Leszczyński
*Thread Reply:* So we needed a generic way of passing parameters to client and made an assumption that every field with ; will be treated as an array
*Thread Reply:* Thanks for the confirmation, should I add a condition to split only if it's a key that can have array values? We can have a list of such keys like facets.disabled
*Thread Reply:* We thought about this solution but it forces us to know the structure of each config and we wanted to avoid that as much as possible
*Thread Reply:* Maybe the condition could be having ; and [] in the value
*Thread Reply:* Makes sense, I can add this check. Thanks @Tomasz Nazarewicz!
*Thread Reply:* Created issue https://github.com/OpenLineage/OpenLineage/issues/1506 for this
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hi everyone, I’m excited to share some good news about our progress in the LFAI & Data Foundation: we’ve achieved Incubation status! This required us to earn a Silver Badge from the OpenSSF, get 300+ stars on GitHub (which was NBD as we have over 1100 already), and win the approval of the LFAI & Data’s TAC. Now that we’ve cleared this hurdle, we have access to additional services from the foundation, including assistance with creative work, marketing and communication support, and event-planning assistance. Graduation from the program, which will earn us a voting seat on the TAC, is on the horizon. Stay tuned for updates on our progress with the foundation.
LF AI & Data is an umbrella foundation of the Linux Foundation that supports open source innovation in artificial intelligence (AI) and data. LF AI & Data was created to support open source AI and data, and to create a sustainable open source AI and data ecosystem that makes it easy to create AI and data products and services using open source technologies. They foster collaboration under a neutral environment with an open governance in support of the harmonization and acceleration of open source technical projects.
For more info about the foundation and other LFAI & Data projects, visit their website.
if you want to share this news (and I hope you do!) there is a blog post here: https://openlineage.io/blog/incubation-stage-lfai/
and I'll add a quick shoutout of @Michael Robinson, who has done a whole lot of work to make this happen 🎉 thanks, man, you're awesome!
*Thread Reply:* Thank you, Ross!! I appreciate it. I might have coordinated it, but it’s been a team effort. Lots of folks shared knowledge and time to help us check all the boxes, literally and figuratively (lots of boxes). ;)
Congrats @Michael Robinson and @Ross Turk - > major step for Open Lineage!

Hi all, I am new to the https://openlineage.io/integration/dbt/, I followed the steps on Windows Laptop. But the dbt-ol does not get executed.
'dbt-ol' is not recognized as an internal or external command, operable program or batch file.
I see the following Packages installed too openlineage-dbt==0.19.2 openlineage-integration-common==0.19.2 openlineage-python==0.19.2
*Thread Reply:* What are the errors?
*Thread Reply:* 'dbt-ol' is not recognized as an internal or external command, operable program or batch file.
*Thread Reply:* Hm, I think this is due to different windows conventions around scripts.
*Thread Reply:* I have not tried it on Windows before myself, but on mac/linux if you make a Python virtual environment in venv/ and run pip install openlineage-dbt, the script winds up in ./venv/bin/dbt-ol.
*Thread Reply:* This might not work, but I think I have an idea that would allow it to run as python -m dbt-ol run ...
*Thread Reply:* That needs one fix though
*Thread Reply:* Hi @Maciej Obuchowski, thanks for the input, when I try to use python -m dbt-ol run, I see the below error :( \python.exe: No module named dbt-ol
*Thread Reply:* We’re seeing a similar issue with the Great Expectations integration at the moment. This is purely a guess, but what happens when you try with openlineage-dbt 0.18.0?
*Thread Reply:* @Michael Robinson GE issue is on Windows?
*Thread Reply:* No, not Windows
*Thread Reply:* (that I know of)
*Thread Reply:* @Michael Robinson - I see the same error. I used 2 Combinations
- Python 3.8.10 with openlineage-dbt 0.18.0 & Latest
- Python 3.9.7 with openlineage-dbt 0.18.0 & Latest
*Thread Reply:* Hm. You should be able to find the dbt-ol command wherever pip is installing the packages. In my case, that's usually in a virtual environment.
But if I am not in a virtual environment, it installs the packages in my PYTHONPATH. You might try this to see if the dbt-ol script can be found in one of the directories in sys.path.
*Thread Reply:* Again, I think this is windows issue
*Thread Reply:* @Maciej Obuchowski you think even if dbt-ol could be found in the path, that might not be the issue?
*Thread Reply:* Hi @Ross Turk - I could not find the dbt-ol in the site-packages.
*Thread Reply:* Hm 😕 then perhaps @Maciej Obuchowski is right and there is a bigger issue here
*Thread Reply:* @Ross Turk & @Maciej Obuchowski I see the issue event when I do the install using the https://pypi.org/project/openlineage-dbt/#files - openlineage-dbt-0.19.2.tar.gz.
For some reason, I see only the following folder created
- openlineage
- openlineage_dbt-0.19.2.dist-info
- openlineageintegrationcommon-0.19.2.dist-info
- openlineage_python-0.19.2.dist-info and not brining in the openlineage-dbt-0.19.2, which has the scripts/dbt-ol
If it helps I am using pip 21.2.4
@Paul Villena @Stephen Said and Vishwanatha Nayak published an AWS blog Automate data lineage on Amazon MWAA with OpenLineage

*Thread Reply:* This is excellent! May we promote it on openlineage and marquez social channels?
*Thread Reply:* This is an amazing write up! 🔥 💯 🚀
*Thread Reply:* Happy to have it promoted. 😄 Vish posted on LinkedIn: https://www.linkedin.com/posts/vishwanatha-nayak-b8462054automate-data-lineage-on-amazon-mwaa-with-activity-7021589819763945473-yMHF?utmsource=share&utmmedium=memberios|https://www.linkedin.com/posts/vishwanatha-nayak-b8462054automate-data-lineage-on-amazon-mwaa-with-activity-7021589819763945473-yMHF?utmsource=share&utmmedium=memberios if you want something to repost there.

Hi guys, I am trying to build the openlineage jar locally for spark. I ran ./gradlew shadowJar in the /integration/spark directory. However, I am getting this issue:
** What went wrong:
A problem occurred evaluating project ':app'.
> Could not resolve all files for configuration ':app:spark33'.
> Could not resolve io.openlineage:openlineage_java:0.20.0-SNAPSHOT.
Required by:
project :app > project :shared
> Could not resolve io.openlineage:openlineage_java:0.20.0-SNAPSHOT.
> Unable to load Maven meta-data from <https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-java/0.20.0-SNAPSHOT/maven-metadata.xml>.
> Could not GET '<https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-java/0.20.0-SNAPSHOT/maven-metadata.xml>'. Received status code 401 from server: Unauthorized
It used to work a few weeks ago...May I ask if anyone would know what the reason might be? Thanks! 🙂
*Thread Reply:* Hello @Anirudh Shrinivason, you need to build your openlineage-java package first. Possibly you built in some time ao in different version
*Thread Reply:* ./gradlew clean build publishToMavenLocal
in /client/java should help.
*Thread Reply:* Ahh yeap this works thanks! 🙂
Are there any resources to explain the differences between lineage with Apache Atlas vs. lineage using OpenLineage? we have discussions with customers and partners, and some of them are looking into which is more “ready for industry”.
*Thread Reply:* It's been a while since I looked at Atlas, but does it even now supports something else than very Java Apache-adjacent projects like Hive and HBase?
*Thread Reply:* To directly answer your question @Sheeri Cabral (Collibra): I am not aware of any resources currently that explain this 😞 but I would welcome the creation of one & pitch in where possible!
*Thread Reply:* I don’t know enough about Atlas to make that doc.

Hi everyone, I am currently working on a project and we have some questions to use OpenLineage with Apache Airflow : • How does it work : ux vs code/script? How can we implement it? a schema of its architecture for example • What are the visual outputs available? • Is the lineage done from A to Z? if there are multiple intermediary transformations for example? • Is the lineage done horizontally across the organization or vertically on different system levels? or both? • Can we upgrade it to industry-level? • Does it work with Python and/or R? • Does it read metadata or scripts? Thanks a lot if you can help 🙂
*Thread Reply:* I think most of your questions will be answered by this video: https://www.youtube.com/watch?v=LRr-ja8_Wjs
*Thread Reply:* I agree - a lot of the answers are in that overview video. You might also take a look at the docs, they do a pretty good job of explaining how it works.
*Thread Reply:* More explicitly:
• Airflow is an interesting platform to observe because it runs a large variety of workloads and lineage can only be automatically extracted for some of them
• In general, OpenLineage is essentially a standard and data model for lineage. There are integrations for various systems, including Airflow, that cause them to emit lineage events to an OpenLineage compatible backend. It's a push model.
• Marquez is one such backend, and the one I recommend for testing & development
• There are a few approaches for lineage in Airflow:
◦ Extractors, which pair with Operators to extract and emit lineage
◦ Manual inlets/outlets on a task, defined by a developer - useful for PythonOperator and other cases where an extractor can't do it auto
◦ Orchestration of an underlying OpenLineage integration, like openlineage-dbt
• IDK about "A to Z", that depends on your environment. The goal is to capture every transformation. Depending on your pipeline, there may be a set of integrations that give you the coverage you need. We often find that there are gaps.
• It works with Python. You can use the openlineage-python client to emit lineage events to a backend. This is useful if there isn't an integration for something your pipeline does.
• It describes the pipeline by observing running jobs and the way they affect datasets, not the organization. I don't know what you mean by "industry-level".
• I am not aware of an integration that parses source code to determine lineage at this time.
• The openlineage-dbt integration consumes the various metadata that dbt leaves behind to construct lineage. Dunno if that's what you mean by "read metadata".
*Thread Reply:* FWIW I did a workshop on openlineage and airflow a while back, and it's all in this repo. You can find slides + a quick Python example + a simple Airflow example in there.
*Thread Reply:* Thanks a lot!! Very helpful!

Hey folks, my team is working on a solution that would support the OL standard with column level lineage. I'm working through the architecture now and I'm wondering if everyone uses the standard rest api backed by a db or if other teams found success using other technologies such as webhooks, streams, etc in order to capture and process lineage events. I'd be very curious to connect on the topic
*Thread Reply:* Hello Brad, on top of my head:
*Thread Reply:* • Marquez uses the API HTTP Post. so does Astro • Egeria and Purview prefer consuming through a Kafka topic. There is a ProxyBackend that takes HTTP Posts and writes to Kafka. The client can also be configured to write to Kafka
*Thread Reply:* @Will Johnson @Mandy Chessell might have opinions
*Thread Reply:* The Microsoft Purview approach is documented here: https://learn.microsoft.com/en-us/samples/microsoft/purview-adb-lineage-solution-accelerator/azure-databricks-to-purview-lineage-connector/
*Thread Reply:* There’s a blog post about Egeria here: https://openlineage.io/blog/openlineage-egeria/
*Thread Reply:* @Brad Paskewitz at Microsoft, the solution that Julien linked above, we are using the HTTP Transport (REST API) as we are consuming the OpenLineage Events and transforming them to Apache Atlas / Microsoft Purview.
However, there is a good deal of interest in using the kafka transport instead and that's our future roadmap.

❓ Hi everyone, I am trying to use openlineage with Databricks (using 11.3 LTS runtime, and openlineage 0.19.2)
Using this documentation I managed to install openlineage and send events to marquez
However marquez did not received all COMPLETE events, it seems like databricks cluster is shutdown immediatly at the end of the job. It is not the first time that i see this with databricks, last year I tried to use spline and we noticed that Databricks seems to not wait that spark session is nicely closed before shutting down instances (see this issue)
My question is: has anyone faced the same issue? Does somebody know a workaround? 🙏
*Thread Reply:* Hmm, if Databricks is shutting the process down without waiting for the ListenerBus to clear, I don’t know that there’s a lot we can do. The best thing is to somehow delay the main application thread from exiting. One thing you could try is to subclass the OpenLineageSparkListener and generate a lock for each SparkListenerSQLExecutionStart and release it when the accompanying SparkListenerSQLExecutionEnd event is processed. Then, in the main application, block until all such locks are released. If you try it and it works, let us know!
*Thread Reply:* Ok thanks for the idea! I'll tell you if I try this and if it works 🤞
Hi, would anybody be able and willing to help us configure S3 and Snowflake extractors within Airflow integration for one of our clients? Our trouble is that Airflow integration returns valid OpenLineage .json files but it lacks any information about input and output DataSets. Thanks in advance 🙂
*Thread Reply:* Hey Petr. Please DM me or describe the issue here 🙂

Hello.. I am trying to play with openlineage spark integration with Kafka and currently trying to just use the config as part of the spark submit command but I run into errors. Details in the 🧵
*Thread Reply:* Command
spark-submit --packages "io.openlineage:openlineage_spark:0.19.+" \
--conf "spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener" \
--conf "spark.openlineage.transport.type=kafka" \
--conf "spark.openlineage.transport.topicName=topicname" \
--conf "spark.openlineage.transport.localServerId=Kafka_server" \
file.py
*Thread Reply:* 23/01/27 17:29:06 ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
java.lang.NullPointerException
at io.openlineage.client.transports.TransportFactory.build(TransportFactory.java:44)
at io.openlineage.spark.agent.EventEmitter.<init>(EventEmitter.java:40)
at io.openlineage.spark.agent.OpenLineageSparkListener.initializeContextFactoryIfNotInitialized(OpenLineageSparkListener.java:278)
at io.openlineage.spark.agent.OpenLineageSparkListener.onApplicationStart(OpenLineageSparkListener.java:267)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:55)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117)
at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101)
at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1446)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
*Thread Reply:* I would appreciate any pointers on getting started with using openlineage-spark with Kafka.
*Thread Reply:* Also this might seem a little elementary but the kafka topic itself, should it be hosted on the spark cluster or could it be any kafka topic?
*Thread Reply:* 👀 Could I get some help on this, please?
*Thread Reply:* I think any NullPointerException is clearly our bug, can you open issue on OL GitHub?
*Thread Reply:* @Maciej Obuchowski Another interesting thing is if I use 0.19.2 version specifically, I get
23/01/30 14:28:33 INFO RddExecutionContext: RDDs are empty: skipping sending OpenLineage event
I am trying to print to console at the moment. I haven't been able to get Kafka transport type working though.
*Thread Reply:* Are you getting events printed on the console though? This log should not affect you if you're running, for example Spark SQL jobs
*Thread Reply:* I am trying to run a python file using pyspark. 23/01/30 14:40:49 INFO RddExecutionContext: RDDs are empty: skipping sending OpenLineage event
I see this and don't see any events on the console.
*Thread Reply:* Any logs filling pattern
log.warn("Unable to access job conf from RDD", nfe);
or
<a href="http://log.info">log.info</a>("Found job conf from RDD {}", jc);
before?
*Thread Reply:* ```23/01/30 14:40:48 INFO DAGScheduler: Submitting ShuffleMapStage 0 (PairwiseRDD[2] at reduceByKey at /tmp/spark-20487725-f49b-4587-986d-e63a61890673/statusapidemo.py:47), which has no missing parents 23/01/30 14:40:49 WARN RddExecutionContext: Unable to access job conf from RDD java.lang.NoSuchFieldException: Field is not instance of HadoopMapRedWriteConfigUtil at io.openlineage.spark.agent.lifecycle.RddExecutionContext.lambda$setActiveJob$0(RddExecutionContext.java:117) at java.util.Optional.orElseThrow(Optional.java:290) at io.openlineage.spark.agent.lifecycle.RddExecutionContext.setActiveJob(RddExecutionContext.java:115) at java.util.Optional.ifPresent(Optional.java:159) at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$onJobStart$9(OpenLineageSparkListener.java:148) at java.util.Optional.ifPresent(Optional.java:159) at io.openlineage.spark.agent.OpenLineageSparkListener.onJobStart(OpenLineageSparkListener.java:145) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:37) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1446) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
23/01/30 14:40:49 INFO RddExecutionContext: Found job conf from RDD Configuration: core-default.xml, core-site.xml, mapred-default.xml, mapred-site.xml, yarn-default.xml, yarn-site.xml, hdfs-default.xml, hdfs-rbf-default.xml, hdfs-site.xml, hdfs-rbf-site.xml, resource-types.xml
23/01/30 14:40:49 INFO RddExecutionContext: Found output path null from RDD PythonRDD[5] at collect at /tmp/spark-20487725-f49b-4587-986d-e63a61890673/statusapidemo.py:48 23/01/30 14:40:49 INFO RddExecutionContext: RDDs are empty: skipping sending OpenLineage event``` I see both actually.
*Thread Reply:* I think this is same problem as this: https://github.com/OpenLineage/OpenLineage/issues/1521
*Thread Reply:* and I think I might have solution on a branch for it, just need to polish it up to release
*Thread Reply:* Aah got it. I will give it a try with SQL and a jar.
Do you have a ETA on when the python issue would be fixed?
*Thread Reply:* @Maciej Obuchowski Well I run into the same errors if I run spark-submit on a jar.
*Thread Reply:* I think that has nothing to do with python
*Thread Reply:* BTW, which Spark version are you using?
*Thread Reply:* We are on 3.3.1
*Thread Reply:* @Maciej Obuchowski Do you have a estimated release date for the fix. Our team is specifically interested in using the Emitter to write out to Kafka.
*Thread Reply:* I think we plan to release somewhere in the next week
*Thread Reply:* @Susmitha Anandarao PR fixing this has been merged, release should be today
👋
what would be the reason conn_id on something like SQLCheckOperator ends up being None when OpenLineage attempts to extract metadata but is fine on task execution?
i'm using OpenLineage for Airflow 0.14.1 on 2.3.4 and i'm getting an error about connid not being found. it's a SQLCheckOperator where the check runs fine but the task fails because when OpenLineage goes to extract task metadata it attempts to grab the connid but at that moment it finds it to be None.
*Thread Reply:* hmmm, I am not sure. perhaps @Benji Lampel can help, he’s very familiar with those operators.
*Thread Reply:* @Benji Lampel any help would be appreciated!

*Thread Reply:* Hey Paul, the SQLCheckExtractors were written with the intent that they would be used by a provider that inherits for them - they are all treated as a sort of base class. What is the exact error message you're getting? And what is the operator code?
Could you try this with a PostgresCheckOperator ?
(Also, only the SqlColumnCheckOperator and SqlTableCheckOperator will provide data quality facets in their output, those functions are not implementable in the other operators at this time)
*Thread Reply:* @Benji Lampel here is the error message. i am not sure what the operator code is.
3-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - Traceback (most recent call last):
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/usr/lib/python3.8/threading.py", line 932, in _bootstrap_inner
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - self.run()
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/usr/lib/python3.8/threading.py", line 870, in run
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - self._target(**self._args, ****self._kwargs)
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/code/venvs/venv/lib/python3.8/site-packages/openlineage/airflow/listener.py", line 99, in on_running
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - task_metadata = extractor_manager.extract_metadata(dagrun, task)
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/code/venvs/venv/lib/python3.8/site-packages/openlineage/airflow/extractors/manager.py", line 28, in extract_metadata
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - extractor = self._get_extractor(task)
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/code/venvs/venv/lib/python3.8/site-packages/openlineage/airflow/extractors/manager.py", line 96, in _get_extractor
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - self.task_to_extractor.instantiate_abstract_extractors(task)
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/code/venvs/venv/lib/python3.8/site-packages/openlineage/airflow/extractors/extractors.py", line 118, in instantiate_abstract_extractors
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - task_conn_type = BaseHook.get_connection(task.conn_id).conn_type
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/code/venvs/venv/lib/python3.8/site-packages/airflow/hooks/base.py", line 67, in get_connection
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - conn = Connection.get_connection_from_secrets(conn_id)
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - File "/code/venvs/venv/lib/python3.8/site-packages/airflow/models/connection.py", line 430, in get_connection_from_secrets
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - raise AirflowNotFoundException(f"The conn_id `{conn_id}` isn't defined")
[2023-01-31, 00:32:38 UTC] {logging_mixin.py:115} WARNING - airflow.exceptions.AirflowNotFoundException: The conn_id `None` isn't defined
*Thread Reply:* and above that
[2023-01-31, 00:32:38 UTC] {connection.py:424} ERROR - Unable to retrieve connection from secrets backend (EnvironmentVariablesBackend). Checking subsequent secrets backend.
Traceback (most recent call last):
File "/code/venvs/venv/lib/python3.8/site-packages/airflow/models/connection.py", line 420, in get_connection_from_secrets
conn = secrets_backend.get_connection(conn_id=conn_id)
File "/code/venvs/venv/lib/python3.8/site-packages/airflow/secrets/base_secrets.py", line 91, in get_connection
value = self.get_conn_value(conn_id=conn_id)
File "/code/venvs/venv/lib/python3.8/site-packages/airflow/secrets/environment_variables.py", line 48, in get_conn_value
return os.environ.get(CONN_ENV_PREFIX + conn_id.upper())
*Thread Reply:* sorry, i should mention we're wrapping over the CheckOperator as we're still migrating from 1.10.15 @Benji Lampel
*Thread Reply:* What do you mean by wrapping the CheckOperator? Like how so, exactly? Can you show me the operator code you're using in the DAG?
*Thread Reply:* like so
class CustomSQLCheckOperator(CheckOperator):
....
*Thread Reply:* i think i found the issue though, we have our own get_hook function and so we don't follow the traditional Airflow way of setting CONN_ID which is why CONN_ID is always None and that path only gets called through OpenLineage which doesn't ever get called with our custom wrapper
Hi everyone, I am using openlineage to capture column level lineage from spark databricks. I noticed that the environment variables captured are only present in the start event, but are not present in the complete event. Is there a reason why it is implemented like this? It seems more intuitive that whatever variables are present in the start event should also be present in the complete event...
Hi everyone.. Does the DBT integration provide an option to emit events to a Kafka topic similar to the Spark integration? I could not find anything regarding this in the documentation and I wanted to make sure if only http transport type is supported. Thank you!
*Thread Reply:* The dbt integration uses the python client, you should be able to do something similar than with the java client. See here: https://github.com/OpenLineage/OpenLineage/tree/main/client/python#kafka
*Thread Reply:* Thank you for this!
I created a openlineage.yml file with the following data to test out the integration locally.
transport:
type: "kafka"
config: { 'bootstrap.servers': 'localhost:9092', }
topic: "ol_dbt_events"
However, I run into a no module named 'confluent_kafka' error from this code.
Running OpenLineage dbt wrapper version 0.19.2
This wrapper will send OpenLineage events at the end of dbt execution.
Traceback (most recent call last):
File "/Users/susmithaanandarao/.pyenv/virtualenvs/dbt-examples-domain-repo/3.9.8/bin/dbt-ol", line 168, in <module>
main()
File "/Users/susmithaanandarao/.pyenv/virtualenvs/dbt-examples-domain-repo/3.9.8/bin/dbt-ol", line 94, in main
client = OpenLineageClient.from_environment()
File "/Users/susmithaanandarao/.pyenv/virtualenvs/dbt-examples-domain-repo/3.9.8/lib/python3.9/site-packages/openlineage/client/client.py", line 73, in from_environment
return cls(transport=get_default_factory().create())
File "/Users/susmithaanandarao/.pyenv/virtualenvs/dbt-examples-domain-repo/3.9.8/lib/python3.9/site-packages/openlineage/client/transport/factory.py", line 37, in create
return self._create_transport(yml_config)
File "/Users/susmithaanandarao/.pyenv/virtualenvs/dbt-examples-domain-repo/3.9.8/lib/python3.9/site-packages/openlineage/client/transport/factory.py", line 69, in _create_transport
return transport_class(config_class.from_dict(config))
File "/Users/susmithaanandarao/.pyenv/virtualenvs/dbt-examples-domain-repo/3.9.8/lib/python3.9/site-packages/openlineage/client/transport/kafka.py", line 43, in __init__
import confluent_kafka as kafka
ModuleNotFoundError: No module named 'confluent_kafka'
Manually installing confluent-kafka worked. But I am curious why it was not automatically installed and if I am missing any config.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Susmitha Anandarao It's not installed because it's large binary package. We don't want to install for every user something giant majority won't use, and it's 100x bigger than rest of the client.
We need to indicate this way better, and do not throw this error directly at user thought, both in docs and code.
~Hey, would love to see a release of OpenLineage~
Hello, I have been working on a proposal to bring an OpenLineage provider to Airflow. I am currently looking for feedback on a draft AIP. See the thread here: https://lists.apache.org/thread/2brvl4ynkxcff86zlokkb47wb5gx8hw7
@Willy Lulciuc, - Any updates on - https://github.com/OpenLineage/OpenLineage/discussions/1494
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hello, While trying to use OpenLineage with spark, I've noticed that sometimes the query execution is missing or already got closed (here is the relevant code). As a result, some of the events are skipped. Is this a known issue? Is there a way to overcome it?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/999#issuecomment-1209048556
Does this fit your experience?
*Thread Reply:* We sometimes experience this in context of very small, quick jobs
*Thread Reply:* Yes, my scenarios are dealing with quick jobs. Good to know that we will be able to solve it with future spark versions. Thanks!
@channel This month’s OpenLineage TSC meeting is next Thursday, February 9th, at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom. All are welcome! On the tentative agenda:
- Recent release overview @Michael Robinson
- AIP: OpenLineage in Airflow
- Discussions: • Real-world implementation of OpenLineage (What does it really mean?) @Sheeri Cabral (Collibra) (continued) • Using namespaces @Michael Robinson
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda.
Hi folks, I’m opening a vote to release OpenLineage 0.20.0, featuring:
• Airflow: add new extractor for GCSToGCSOperator
Adds a new extractor for this operator.
• Proxy: implement lineage event validator for client proxy
Implements logic in the proxy (which is still in development) for validating and handling lineage events.
• A fix of a breaking change in the common integration and other bug fixes in the DBT, Airflow, Spark, and SQL integrations and in the Java and Python clients.
As per the policy here, three +1s from committers will authorize. Thanks in advance.
*Thread Reply:* exciting to see the client proxy work being released by @Minkyu Park 💯
*Thread Reply:* This was without a doubt among the fastest release votes we’ve ever had 😉 . Thank you! You can expect the release to happen on Monday.
*Thread Reply:* Lol the proxy is still in development and not ready for use
*Thread Reply:* Good point! Let’s make that clear in the release / docs?
*Thread Reply:* But it doesn’t block anything anyway, so happy to see the release
*Thread Reply:* We can celebrate that the proposal for the proxy is merged. I’m happy with that 🥳

Hey 👋 From what I gather, there's no solution to getting column level lineage from spark streaming jobs. Is there a issue I can follow to keep track?
*Thread Reply:* Hey @Daniel Joanes! thanks for the question.
I am not aware of an issue that captures this. Column-level lineage is a somewhat new facet in the spec, and implementations across the various integrations are in varying states of readiness.
I invite you to create the issue - that way it's attributed to you, which makes sense because you're the one who first raised it. But I'm happy to create it for you & give you the PR# if you'd rather, just let me know 👍
*Thread Reply:* Go for it, once it's created i'll add a watch
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1581
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
@channel
OpenLineage 0.20.4 is now available, including:
Additions:
• Airflow: add new extractor for GCSToGCSOperator #1495 @sekikn
• Flink: resolve topic names from regex, support 1.16.0 #1522 @pawel-big-lebowski
• Proxy: implement lineage event validator for client proxy #1469 @fm100
Changes:
• CI: use ruff instead of flake8, isort, etc., for linting and formatting #1526 @mobuchowski
Plus many bug fixes & doc changes.
Thank you to all our contributors!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.20.4
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.19.2...0.20.4
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
@channel Friendly reminder: this month’s OpenLineage TSC meeting is tomorrow at 10am, and all are welcome. https://openlineage.slack.com/archives/C01CK9T7HKR/p1675354153489629
Hey, can we please schedule a release of OpenLineage? I would like to have a release that includes the latest fixes for Async Operator on Airflow and some dbt bug fixes.
*Thread Reply:* Thanks for requesting a release. 3 +1s from committers will authorize an immediate release.
*Thread Reply:* 0.20.5 ?
*Thread Reply:* 👍 the release is authorized

Hi all, I have been experimenting with OpenLineage for a few days and it's great! I successfully setup the openlineage-spark listener on my Databricks cluster and that pushes openlineage data to our Marquez backend. That was all pretty easy to do 🙂
Now for my challenge: I would like to actually extend the metadata that my cluster pushes with custom values (you can think of spark config settings, commit hash of the executed code, or maybe even runtime defined values). I browsed through some documentation and found custom facets one can define. The link below describes how to use Python to push custom metadata to a backend, but I was actually hoping that there was a way to do this automatically in Spark. So ideally I would like to write my own OpenLineage.json (that has my custom facet) and tell Spark to use that Openlineage spec instead of the default one. In that way I hope my custom metadata will be forwarded automatically.
I just do not know how to do that (and whether that is even possible), since I could not find any tutorials on that topic. Any help on this would be greatly appreciated!
https://openlineage.io/docs/spec/facets/custom-facets
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I am also exploring something similar, but writing to kafka, and would want to know more on how we could add custom metadata from spark.
*Thread Reply:* Hi @Avinash Pancham @Susmitha Anandarao, it's great to hear about successful experimenting on your side.
Although Openlineage spec provides some built-in facets definition, a facet object can be anything you want (https://openlineage.io/apidocs/openapi/#tag/OpenLineage/operation/postRunEvent). The example metadata provided in this chat could be put into job or run facets I believe.
There is also a way to extend Spark integration to collect custom metadata described here (https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#extending). One needs to create own JAR with DatasetFacetBuilders, RunFacetsBuilder (whatever is needed). openlineage-spark integration will make use of those bulders.
*Thread Reply:* (I would love to see what your specs are! I’m not with Astronomer, just a community member, but I am finding that many of the customizations people are making to the spec are valuable ones that we should consider adding to core)
*Thread Reply:* Are there any examples out there of customizations already done in Spark? An example would definitely help!
*Thread Reply:* I think @Will Johnson might have something to add about customization
*Thread Reply:* Oh man... Mike Collado did a nice write up on Slack of how many different ways there are to customize / extend OpenLineage. I know we all talked about doing a blog post at one point!
@Susmitha Anandarao - You might take a look at https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/[…]ark/agent/facets/builder/DatabricksEnvironmentFacetBuilder.java which has a hard coded set of properties we are extracting.
It looks like Avinash's changes were accepted as well: https://github.com/OpenLineage/OpenLineage/pull/1545
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
@channel
OpenLineage 0.20.6 is now available, including:
Additions
• Airflow: add new extractor for FTPFileTransmitOperator #1603 @sekikn
Changes
• Airflow: make extractors for async operators work #1601 @JDarDagran
Thanks to all our contributors!
For the bug fixes and details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.20.6
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.20.4...0.20.6
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Hi everyone, in case you missed the announcement at the most recent community meeting, our first-ever meetup will be held on March 9th in Providence, RI. Join us there to learn more about the present and future of OpenLineage, meet other members of the ecosystem, learn about the project’s goals and fundamental design, and participate in a discussion about the future of the project. Food will be provided, and the meetup is open to all. Don’t miss this opportunity to influence the direction of this important new standard! We hope to see you there. More information: https://openlineage.io/blog/data-lineage-meetup/
Hi, I opened a PR to fix the way that Athena extractor get the database, but spark integration tests failed. However I don't think that it is related to my PR, since I only updated the Airflow integration Can anybody help me with that please? 🙏
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/6398/workflows/9d2d19c8-f2d9-4148-a4f3-5dad3ba99eb1/jobs/97759
ERROR: Missing environment variable {i}
*Thread Reply:* @Quentin Nambot this happens because we run additional integration tests against real databases (like BigQuery) which aren't ever configured on forks, since we don't want to expose our secrets. We need to figure out how to make this experience better, but in the meantime we've pushed your code using git-push-fork-to-upstream-branch and it passes all the tests.
*Thread Reply:* Feel free to un-draft your PR if you think it's ready for review
*Thread Reply:* I think it's ready, however should I update the version somewhere?
*Thread Reply:* @Quentin Nambot I don't think so - it's just that you opened PR as Draft , so I'm not sure if you want to add something else to it.
*Thread Reply:* No I don't want to add anything so I opened it 👍
@here I have a question about extending the spark integration. Is there a way to use a custom visitor factory? I am trying to see if I can add a visitor for a command that is not currently covered in this integration (AlterTableAddPartitionCommand). It seems that because its not in the base visitor factory I am unable to use the visitor I created.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* You can add your own EventHandlerFactory https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/main/java/io/openlineage/spark/api/OpenLineageEventHandlerFactory.java . See the docs about extending here - https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#extending
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I have that set up already like this:
public class LyftOpenLineageEventHandlerFactory implements OpenLineageEventHandlerFactory {
@Override
public Collection<PartialFunction<LogicalPlan, List<OutputDataset>>>
createOutputDatasetQueryPlanVisitors(OpenLineageContext context) {
Collection<PartialFunction<LogicalPlan, List<OutputDataset>>> visitors = new ArrayList<PartialFunction<LogicalPlan, List<OutputDataset>>>();
visitors.add(new LyftInsertIntoHadoopFsRelationVisitor(context));
visitors.add(new AlterTableAddPartitionVisitor(context));
visitors.add(new AlterTableDropPartitionVisitor(context));
return visitors;
}
}
*Thread Reply:* do I just add a constructor? the visitorFactory is private so I wasn't sure if that's something that was intended to change
*Thread Reply:* The VisitorFactory is only used by the internal EventHandlerFactory. It shouldn’t be needed for your custom one
*Thread Reply:* Have you added the file to the META-INF folder of your jar?
*Thread Reply:* yes, I am able to use my custom event handler factory with a list of visitors but for some reason I cant access the visitors for some commands (AlterTableAddPartitionCommand) is one
*Thread Reply:* so even if I set up everything correctly I am unable to reach the code for that specific visitor
*Thread Reply:* and my assumption is I can reach other commands but not this one because the command is not defined in the BaseVisitorFactory but maybe im wrong @Michael Collado
*Thread Reply:* the VisitorFactory is loaded by the InternalEventHandlerFactory here. However, the createOutputDatasetQueryPlanVisitors should contain a union of everything defined by the VisitorFactory as well as your custom visitors: see this code.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* there might be a conflict with another visitor that’s being matched against that command. Can you turn on debug logging and look for this line to see what visitor is being applied to that command?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* This was helpful, it works now, thank you so much Michael!
*Thread Reply:* what is the curl cmd you are running? and what endpoint are you hitting? (assuming Marquez?)

*Thread Reply:* yep I am running curl - X curl -X POST http://localhost:5000/api/v1/namespaces/test ^ -H 'Content-Type: application/json' ^ -d '{ownerName:"me", description:"no description"^ }'
the weird thing is the log where I don't have a 0.0.0.0 IP (the log correspond to the equivament postman command)
marquez-api | WARN [2023-02-17 00:14:32,695] marquez.logging.LoggingMdcFilter: status: 405 marquez-api | XXX.23.0.1 - - [17/Feb/2023:00:14:32 +0000] "POST /api/v1/namespaces/test HTTP/1.1" 405 52 "-" "PostmanRuntime/7.30.0" 2
*Thread Reply:* Marquez logs all supported endpoints (and methods) on start up. For example, here are all the supported methods on /api/v1/namespaces/{namespace} :
marquez-api | DELETE /api/v1/namespaces/{namespace} (marquez.api.NamespaceResource)
marquez-api | GET /api/v1/namespaces/{namespace} (marquez.api.NamespaceResource)
marquez-api | PUT /api/v1/namespaces/{namespace} (marquez.api.NamespaceResource)
To ADD a namespace, you’ll want to use PUT (see API docs)
*Thread Reply:* 3rd stupid question of the night Sorry kept on trying POST who knows why
*Thread Reply:* no worries! keep the questions coming!
*Thread Reply:* well, maybe because it’s so late on your end! get some rest!
*Thread Reply:* Yeah but I want to see how it works Right now I have a response 200 for the creation of the names ... but it seems that nothing occurred nor on marquez front end (localhost:3000) nor on the database
*Thread Reply:* can you curl the list namespaces endpoint?
*Thread Reply:* yep : nothing changed only default and food_delivery
*Thread Reply:* can you post your server logs? you should see the request
*Thread Reply:* marquez-api | XXX.23.0.4 - - [17/Feb/2023:00:30:38 +0000] "PUT /api/v1/namespaces/ciro HTTP/1.1" 500 110 "-" "-" 7 marquez-api | INFO [2023-02-17 00:32:07,072] marquez.logging.LoggingMdcFilter: status: 200
*Thread Reply:* the server is returning a 500 ?
*Thread Reply:* odd that LoggingMdcFilter is logging 200
*Thread Reply:* Bit confused because now I realize that postman is returning bad request
*Thread Reply:* You'll notice that I go to use 3000 in the url If I use 5000 I get No host
*Thread Reply:* odd, the API should be using port 5000, have you followed our quickstart for Marquez?
*Thread Reply:* Hello Willy I am starting from scratch followin instruction from https://openlineage.io/docs/getting-started/ I am on Windows Instead of git clone git@github.com:MarquezProject/marquez.git && cd marquez I run the git clone
git clone <https://github.com/MarquezProject/marquez.git>
But before I had to clear the auto carriage return in git
git config --global core.autocrlf false
This avoid an error message on marquez-api when running wait-for-it.sh àt line 1 where
#!/usr/bin/env bash
is otherwise read as
#!/usr/bin/env bash\r'
It turns out that when switching off the autocr, this impacts some file containing marquez password ... and I get a fail on accessing the db to overcome this I run notepad++ and replaced ALL the \r\n with \n And in this way I managed to run docker\up.sh and docker\down.sh correctly (with or without seed ... with access to the db, via pgadmin)
Hi, I'd like to capture column lineage from spark, but also capture how the columns are transformed, and any column operations that are done too. May I ask if this feature is supported currently, or will be supported in future based on current timeline? Thanks!
*Thread Reply:* Hi @Anirudh Shrinivason, this is a great question. We included extra fields in OpenLineage spec to contain that information:
"transformationDescription": {
"type": "string",
"description": "a string representation of the transformation applied"
},
"transformationType": {
"type": "string",
"description": "IDENTITY|MASKED reflects a clearly defined behavior. IDENTITY: exact same as input; MASKED: no original data available (like a hash of PII for example)"
}
so the standard is ready to support it. We included two fields, so that one can contain human readable description of what is happening. However, we don't have this implemented in Spark integration.
*Thread Reply:* Thanks a lot! That is great. Is there a potential plan in the roadmap to support this for spark?
*Thread Reply:* I think there will be a growing interest in that. In general a dependency may really difficult to express if many Spark operators are used on input columns to produce output one. The simple version would be just to detect indetity operation or some kind of hashing.
To sum up, we don't have yet a proposal on that but this seems to be a natural next step in enriching column lineage features.
*Thread Reply:* Got it. Thanks! If this item potentially comes on the roadmap, then I'd be happy to work with other interested developers to help contribute! 🙂
*Thread Reply:* Great to hear that. What you could perhaps start with, is come to our monthly OpenLineage meetings and ask @Michael Robinson to put this item on discussions' list. There are many strategies to address this issue and hearing your story, usage scenario and would are you trying to achieve, would be super helpful in design and implementation phase.
*Thread Reply:* Got it! The monthly meeting might be a bit hard for me to attend live, because of the time zone. But I'll try my best to make it to the next one! thanks!
*Thread Reply:* Thank you for bringing this up, @Anirudh Shrinivason. I’ll add it to the agenda of our next meeting because there might be interest from others in adding this to the roadmap.
Hello how can I improve the verbosity of the marquez-api? Regards
*Thread Reply:* Hi @thebruuu, pls take a look at logging documentation of Dropwizard (https://www.dropwizard.io/en/latest/manual/core.html#logging) - the framework Marquez is implemented in. The logging configuration section is present in marquez.yml .
Hey, can we please schedule a release of OpenLineage? I would like to have the release that includes the feature to capture custom env variables from spark clusters... Thanks!
*Thread Reply:* We generally schedule a release every month, next one will be in the next week - is that okay @Anirudh Shrinivason?
*Thread Reply:* Yes, there’s one scheduled for next Wednesday, if that suits.
*Thread Reply:* Okay yeah sure that works. Thanks
*Thread Reply:* @Anirudh Shrinivason we’re expecting the release to happen today or tomorrow, FYI
*Thread Reply:* Awesome thanks

Hello team, we used OpenLineage and Great Expectations integrated. I want to use GE to verify the table in Snowflake. I found that the configuration I added OpenLineage into GE produced this error after running. Could someone please give me some answers? 👀
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/great_expectations/validation_operators/validation_operators.py", line 469, in _run_actions
action_result = self.actions[action["name"]].run(
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/great_expectations/checkpoint/actions.py", line 106, in run
return self._run(
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/openlineage/common/provider/great_expectations/action.py", line 156, in _run
datasets = self._fetch_datasets_from_sql_source(
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/openlineage/common/provider/great_expectations/action.py", line 362, in _fetch_datasets_from_sql_source
self._get_sql_table(
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages/openlineage/common/provider/great_expectations/action.py", line 395, in _get_sql_table
if engine.connection_string:
AttributeError: 'Engine' object has no attribute 'connection_string'
'Engine' object has no attribute 'connection_string'
*Thread Reply:* This is my checkponit configuration in GE. ```name: 'openlineagecheckpoint' configversion: 1.0 templatename: modulename: greatexpectations.checkpoint classname: Checkpoint runnametemplate: '%Y%m%d-%H%M%S-mycheckpoint' expectationsuitename: EMAILVALIDATION batchrequest: actionlist:
- name: storevalidationresult action: class_name: StoreValidationResultAction
- name: storeevaluationparams action: class_name: StoreEvaluationParametersAction
- name: updatedatadocs action: classname: UpdateDataDocsAction sitenames: []
- name: openlineage
action:
classname: OpenLineageValidationAction
modulename: openlineage.common.provider.greatexpectations
openlineagehost: http://localhost:5000
# openlineageapiKey: 12345
openlineagenamespace: geexpectations # Replace with your job namespace; we recommend a meaningful namespace like
devorprod, etc. jobname: gevalidation evaluationparameters: {} runtime_configuration: {} validations: - batchrequest: datasourcename: LANDINGDEV dataconnectorname: defaultinferreddataconnectorname dataassetname: 'snowpipe.pii' dataconnectorquery: index: -1 expectationsuitename: EMAILVALIDATION
profilers: [] gecloudid: expectationsuitegecloudid:```
*Thread Reply:* What version of GX are you running? And is this being run directly through GX or through Airflow with the operator?
*Thread Reply:* I use the latest version of Great Expectations. This error occurs either directly through Great Expectations or airflow
*Thread Reply:* I noticed another issue in the latest version as well. Try dropping to GE version great-expectations==0.15.44 for now. That is the latest one that works for me.
*Thread Reply:* You should definitely open an issue here, and you can tag me @denimalpaca in the comment
*Thread Reply:* Thanks Benji, but I still have the same problem after I drop to great-expectations==0.15.44 , this is my requirement file
great_expectations==0.15.44
sqlalchemy
psycopg2-binary
numpy
pandas
snowflake-connector-python
snowflake-sqlalchem
*Thread Reply:* interesting... I do think this may be a GX issue so let's see if they say anything. I can also cross post this thread to their slack

Hello Team, I’m trying to use Open Lineage with AWS Glue and Marquez. Has anyone successfully integrated AWS Workflows/ Glue ETL jobs with Open Lineage?
*Thread Reply:* I know I’m responding to an older post - I’m not sure if this would work in your environment? https://aws.amazon.com/blogs/big-data/build-data-lineage-for-data-lakes-using-aws-glue-amazon-neptune-and-spline/ Are you using AWS Glue with Spark jobs?
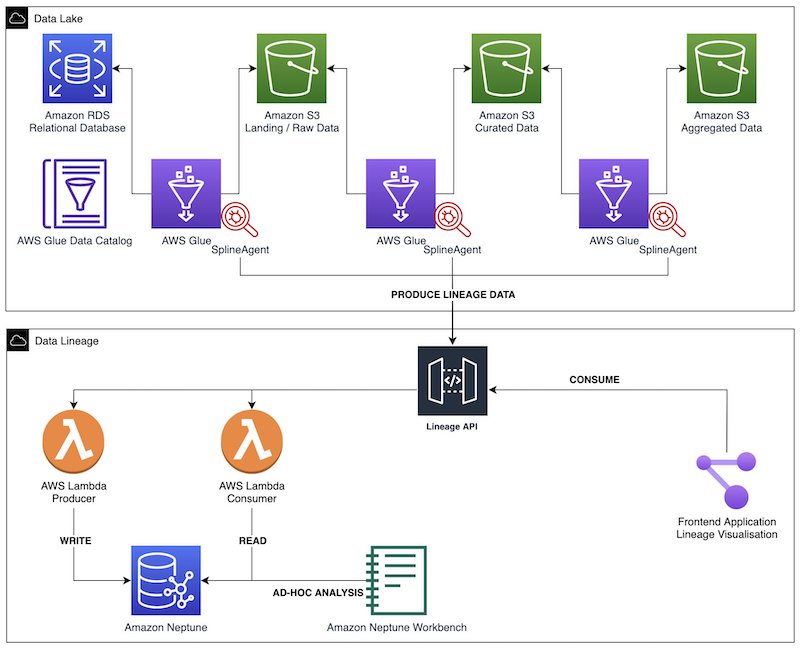
*Thread Reply:* This was proposed by our AWS Solution architect but we are not seeing much improvement compared to open lineage. Have you deployed the above solution to prod?
*Thread Reply:* We are currently in the research phase, so we have not deployed to prod. We have customers with thousands of existing scripts that they don’t want to rewrite to add openlineage libraries - i would imagine that if you are already integrating OpenLineage in your code, the spark listener isn’t an improvement. Our research is on magically getting lineage from existing scripts 😄
Hello everyone, I’m opening a vote to release OpenLineage 0.21.0, featuring:
• a new CustomEnvironmentFacetBuilder class and new output visitors AlterTableAddPartitionCommandVisitor and AlterTableSetLocationCommandVisitor in the Spark integration
• a Linux-ARM version of the SQL parser’s native library
• DEBUG logging of events in transports
• bug fixes and more.
Three +1s from committers will authorize an immediate release.
*Thread Reply:* Thanks, all. The release is authorized and will be initiated as soon as possible.

I’ve got some security related questions/observations. The main site suggests opening an issue to report vulnerabilities etc. I wanted to check if there is a private mailing list/DM channel to just check a few things first? I’m happy to use github issues otherwise. Thanks!

*Thread Reply:* GitHub has a new issue template for reporting vulnerabilities, actually. If you use a config that enables this issue template.
Reminder: our first meetup is one week from today in Providence, RI! You can find the details in the meetup blog post. And if you’re coming, it would be great if you could RSVP. Looking forward to seeing some of you there!

@channel
We released OpenLineage 0.21.1, including:
Additions
• Clients: add DEBUG logging of events to transports #1633 by @mobuchowski
• Spark: add CustomEnvironmentFacetBuilder class #1545 by New contributor @Anirudh181001
• Spark: introduce the new output visitors AlterTableAddPartitionCommandVisitor and AlterTableSetLocationCommandVisitor #1629 by New contributor @nataliezeller1
• Spark: add column lineage for JDBC relations #1636 by @tnazarew
• SQL: add linux-aarch64 native library to Java SQL parser #1664 by @mobuchowski
Changes
• Airflow: get table database in Athena extractor #1631 by New contributor @rinzool
Removals
• Airflow: remove JobIdMapping and update macros to better support Airflow version 2+ #1645 by @JDarDagran
Thanks to all our contributors!
For the bug fixes and details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.21.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.20.6...0.21.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
how do you turn off the openlineage listener in airflow 2? for some reason we're seeing a Thread-2 and seeing it fire twice in tasks
*Thread Reply:* Hey @Paul Lee, are you seeing this happen for Async operators?
*Thread Reply:* might be related to this issue https://github.com/OpenLineage/OpenLineage/pull/1601 that was fixed in 0.20.6
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Harel Shein if i want to turn off openlineage listener how do i do that? do i just remove the package?
*Thread Reply:* meaning, you don’t want openlineage to collect any information from your Airflow deployment?
*Thread Reply:* in that case, you could either remove it from your requirements file, or set OPENLINEAGE_DISABLED=True in your Airflow env vars
*Thread Reply:* removed it from requirements and also the backend key in airflow config. needed both
@channel This month’s OpenLineage TSC meeting is next Thursday, March 9th, at 10 am PT. Join us on Zoom: https://bit.ly/OLzoom. All are welcome! On the tentative agenda:
- Recent release overview
- A new consumer
- Custom env variable support in Spark
- Async operator support in Airflow
- JDBC relations support in Spark
- Discussion topics: • New feature idea: column transformations/operations in the Spark integration • Using namespaces
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda.
Hi everyone, I noticed that Openlineage is sending each of the events twice for spark. Is this expected? Is there some way to disable this behaviour?
*Thread Reply:* Are you seeing duplicate START events or do you see two events one that is a START and one that is COMPLETE?
OpenLineage's events may send partial information. You should expect to collect all events for a given RunId and merge them together to get the complete events.
In addition, some data sources are really chatty like Delta tables. That may cause you to see many events that look very similar.
*Thread Reply:* Hmm...I'm seeing 2 start events for the same runnable command
*Thread Reply:* And 2 complete
*Thread Reply:* I am currently only testing on parquet tables...
*Thread Reply:* One of openlineage assumptions is the ability to merge lineage events in the backend to make client integrations stateless. So, it is possible that Spark can emit multiple events for the same job. However, sometimes it does not make any sense to send or collect some events, which happened to us some time ago with delta. In that case we decided to filter them and created filtering mechanism (https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/shared/src/main/java/io/openlineage/spark/agent/filters) than can be extended in case of other unwanted events being generated and sent.
*Thread Reply:* Ahh I see...okay thanks!
*Thread Reply:* in general , you should build any event consumer system with at least once semantics. Even if this issue is fixed, there is a possibility of duplicates for other valid scenarios
*Thread Reply:* Hi..I compared some duplicate 'START' events just now, and noticed that they are exactly the same, with the only exception of one of them having an 'environment-properties' field... Could I just quickly check if this is a bug or a feature haha?
*Thread Reply:* CC: @Paweł Leszczyński ^
@channel Reminder: this month’s OpenLineage TSC meeting is tomorrow at 10am PT. All are welcome. https://openlineage.slack.com/archives/C01CK9T7HKR/p1677806982084969
Hi if we have OpenLineage listener configured as a default spark conf, is there an easy way to disable ol for a specific notebook?
*Thread Reply:* if you can set up env variables for particular notebooks, you can set OPENLINEAGE_DISABLED=true
Hey all,
I opened a PR (and corresponding issue) to change how naming works in OpenLineage. The idea generally is to move from Naming.md as the end-all-be-all of names for integrations, and towards JSON schemas per integration, with each schema defining very precisely what fields a name and namespace should contain, how they're connected, and how they're validated. Would really appreciate some feedback as this is a pretty big change!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

What do i need to do to enable dag level metric capturing for airflow. I followed the instruction to install openlineage 0.21.1 on airflow 2.3.3. When i run a DAG i see metrics related to Task start, success/failure. But i dont see any metrics for Dag success/failure. Do i have to do something to enable DAG execution capturing ?
*Thread Reply:* is DAG run capturing enabled starting airflow 2.5.1 ? https://github.com/apache/airflow/pull/27113
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* you're right, only the change was included in 2.5.0
Fresh on the heels of our first-ever in-person event, we’re meeting up again soon at Data Council Austin! Join us on March 30th (the same day as @Julien Le Dem’s talk) at 12:15 pm to discuss the project’s goals and design, meet other members of the data ecosystem, and help shape the future of the spec. For more info, check out the OpenLineage blog. If you haven’t registered for the conference yet, click OpenLineage20 for a special rate. Hope to see you there!

If someone is using airflow and DAG-docs for lineage, can they export the lineage in, say, OL format?
*Thread Reply:* I don’t see it currently on the AirflowRunFacet, but probably not a big deal to add it? @Benji Lampel wdyt?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Definitely could be a good thing to have--is there not some info facet that could hold this data already? I don't see an issue with adding to the AirflowRunFacet tho (full disclosure, I'm not super familiar with this facet)
*Thread Reply:* Perhaps DocumentationJobFacet or DocumentationDatasetFacet?
(is it https://docs.astronomer.io/learn/airflow-openlineage ? )

Happy Friday 👋 I am looking for some help setting the parent information for a dbt run. I have set the namespace variable in the openlineage.yml but doesn't seem to take effect and ends up using the default value of dbt. Also using openlineage.yml to set the transport properties for emitting to kafka. Is there a way to set parent namespace, name and run id in the yml file? Thank you!
*Thread Reply:* dbt-ol does not read from openlineage.yml so you need to pass this information in OPENLINEAGE_NAMESPACE environment variable
*Thread Reply:* Hmmm. Interesting! I thought that it used client = OpenLineageClient.from_environment(), I’ll do some testing with Kafka backends.
*Thread Reply:* Thank you for the hint. I was able to make it work with specifying the env OPENLINEAGE_CONFIGto specify the yml file holding transport info and OPENLINEAGE_NAMESPACE
*Thread Reply:* Awesome! That’s exactly what I was going to test.
*Thread Reply:* I think it also works if you put it in $HOME/.openlineage/openlineage.yml.
*Thread Reply:* @Susmitha Anandarao I might have provided misleading information. I meant that dbt-ol does not read OL namespace from openlineage.yml but from OPENLINEAGE_NAMESPACE env var instead
Data Council Austin, the host of our next meetup, is one week away: https://openlineage.slack.com/archives/C01CK9T7HKR/p1678822654288379
In addition to Data Council Austin next week, the hybrid Big Data Technology Warsaw Summit will be taking place on March 28th-30th, featuring three of our committers: @Maciej Obuchowski, @Paweł Leszczyński and @Ross Turk ! There’s more info here: https://bigdatatechwarsaw.eu/

hey folks, is anyone capturing dataset metadata for multi-table schemas? I'm looking at the schema dataset facet: https://openlineage.io/docs/spec/facets/dataset-facets/schema but it looks like this only represents a single table so im wondering if I'll need to write a custom facet
*Thread Reply:* It should be represented by multiple datasets, unless I misunderstood what you mean by multi-table
*Thread Reply:* here at Fivetran when we sync data it is generally 1 schema with multiple tables (sometimes many) so we would want to represent all of that
*Thread Reply:* So what I understand:
- your single job represents synchronization of multiple tables
- you want to have precise input-output dataset lineage? am I right?
I would model that as multiple OL jobs that describe each dataset mappings. Additionally, I'd have one "wrapping" job that represents your definition of a job. Rest of those jobs would refer to it in ParentRunFacet.
This is a pattern we use for Airflow and dbt dags.
*Thread Reply:* Yes your statements are correct. Thanks for sharing that model, that makes sense to me
has anyone had success creating custom facets using java? I'm following this guide: https://openlineage.io/docs/spec/facets/custom-facets and im wondering if it makes sense to manually create POJOs or if others are creating the json schema for the object and then automatically generating the java code?
*Thread Reply:* I think it's better to just create POJO. This is what we do in Spark integration, for example.
For now, JSON Schema generator isn't flexible enough to generate custom facets from whatever schema we give it, so it would be unnecessary complexity
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Agreed, just a POJO would work. This is using Jackson, so you would use annotations as needed. You can also use a Jackson JSONNode or even Map.
One other question: I'm in the process of adding different types of facets to our base payloads and I'm wondering if we have any related guidelines / best practices / standards / conventions. For example if I add a full source schema as a schema dataset facet to every start event it seems like that could be inefficient compared to a 1-time full-source-schema followed by incremental diffs for each following sync. Curious how others are thinking about + solving these types of problems in practice
*Thread Reply:* That depends on the OL consumer, but for something like SchemaDatasetFacet it seems to be okay to assume schema stays the same if not send.
For others, like OutputStatisticsOutputDatasetFacet you definitely can't assume that, as the data is unique to each run.
*Thread Reply:* ok great thanks, that makes sense to me
*Thread Reply:* OpenLineage API: https://openlineage.io/docs/getting-started/
Hi everyone, I recently encountered this error saying V2SessionCatalog is not supported by openlineage. May I ask if support for this will be added in near future? Thanks!
*Thread Reply:* I think it would be great to support V2SessionCatalog, and it would very much help if you created GitHub issue with more explanation and examples of it's use.
*Thread Reply:* Sure thanks!
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1747 I have opened an issue here. Thanks! 🙂
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Maciej Obuchowski Just curious, is this issue on the potential roadmap for the next Openlineage release?

Hi all! Can anyone provide me some advice on how to solve this error:
ValueError: `emit` only accepts RunEvent class
[2023-04-02, 23:22:00 UTC] {taskinstance.py:1326} INFO - Marking task as FAILED. dag_id=etl_openlineage, task_id=send_ol_events, execution_date=20230402T232112, start_date=20230402T232114, end_date=20230402T232200
[2023-04-02, 23:22:00 UTC] {standard_task_runner.py:105} ERROR - Failed to execute job 400 for task send_ol_events (`emit` only accepts RunEvent class; 28020)
[2023-04-02, 23:22:00 UTC] {local_task_job.py:212} INFO - Task exited with return code 1
[2023-04-02, 23:22:00 UTC] {taskinstance.py:2585} INFO - 0 downstream tasks scheduled from follow-on schedule check
I'm trying to follow this tutorial (https://openlineage.io/blog/openlineage-snowflake/) on connecting Snowflake to OpenLineage through Apache Airflow, however, the last step (sending the OpenLineage events) returns an error.
*Thread Reply:* The blog post is a bit old and in the meantime there were changes in OpenLineage Python Client introduced. May I ask if you want just to test the flow or looking for any viable Snowflake data lineage solution?
*Thread Reply:* I believe that this will work if you change the line to client.transport.emit()
*Thread Reply:* (this would be in the dags/lineage folder, if memory serves)
*Thread Reply:* Ross is right, that should work
*Thread Reply:* This works! Thank you so much!
*Thread Reply:* @Jakub Dardziński I want to use a viable Snowflake data lineage solution alongside a Amazon DataZone Catalog 🙂
*Thread Reply:* I have been meaning to revisit that tutorial 👍
Hello all,
I’d like to open a vote to release OpenLineage 0.22.0, including:
• a new properties facet in the Spark integration
• a new field in HttpConfig for passing custom headers in the Spark integration
• improved namespace generation for JDBC connections in the Spark integration
• removal of unnecessary warnings about column lineage in the Spark integration
• support for alter, truncate, and drop statements in the SQL parser
• typing hints in the SQL integration
• a new from_dict class method in the Python client to support creating it from a dictionary
• a case-insensitive env variable for disabling OpenLineage in the Python client and Airflow integration
• bug fixes, docs changes, and more.
Three +1s from committers will authorize an immediate release. For more details about the release process, see GOVERNANCE.md.
*Thread Reply:* Thanks, all. The release is authorized and will be initiated within 48 hours.
@channel
We released OpenLineage 0.22.0, including:
Additions:
• Spark: add properties facet #1717 by @tnazarew
• SQL: SQLParser supports alter, truncate and drop statements #1695 by @pawel-big-lebowski
• Common/SQL: provide public interface for openlineage_sql package #1727 by @JDarDagran
• Java client: add configurable headers to HTTP transport #1718 by @tnazarew
• Python client: create client from dictionary #1745 by @JDarDagran
Changes:
• Spark: remove URL parameters for JDBC namespaces #1708 by @tnazarew
• Make OPENLINEAGE_DISABLED case-insensitive #1705 by @jedcunningham
Removals:
• Spark: remove unnecessary warnings for column lineage #1700 by @pawel-big-lebowski
• Spark: remove deprecated configs #1711 by @tnazarew
Thanks to all the contributors!
For the bug fixes and details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.22.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.21.1...0.22.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Hi everyone, if I set executors to 0, and bind address to localhost, and then if I want to use openlineage to capture metadata, I seem to run into an error where the executor tries to fetch the spark jar from the driver, even though there is no executor set. Then, it fails because a connection cannot be established. This is some of the error stack trace:
INFO Executor: Fetching spark://<DRIVER_IP>:44541/jars/io.openlineage_openlineage-spark-0.21.1.jar with timestamp 1680506544239
ERROR Utils: Aborting task
java.io.IOException: Failed to connect to /<DRIVER_IP>:44541
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:287)
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218)
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230)
at org.apache.spark.rpc.netty.NettyRpcEnv.downloadClient(NettyRpcEnv.scala:399)
at org.apache.spark.rpc.netty.NettyRpcEnv.$anonfun$openChannel$4(NettyRpcEnv.scala:367)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1473)
at org.apache.spark.rpc.netty.NettyRpcEnv.openChannel(NettyRpcEnv.scala:366)
at org.apache.spark.util.Utils$.doFetchFile(Utils.scala:755)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:541)
at org.apache.spark.executor.Executor.$anonfun$updateDependencies$13(Executor.scala:953)
at org.apache.spark.executor.Executor.$anonfun$updateDependencies$13$adapted(Executor.scala:945)
at scala.collection.TraversableLike$WithFilter.$anonfun$foreach$1(TraversableLike.scala:877)
at scala.collection.mutable.HashMap.$anonfun$foreach$1(HashMap.scala:149)
at scala.collection.mutable.HashTable.foreachEntry(HashTable.scala:237)
at scala.collection.mutable.HashTable.foreachEntry$(HashTable.scala:230)
at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:44)
at scala.collection.mutable.HashMap.foreach(HashMap.scala:149)
at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:876)
at <a href="http://org.apache.spark.executor.Executor.org">org.apache.spark.executor.Executor.org</a>$apache$spark$executor$Executor$$updateDependencies(Executor.scala:945)
at org.apache.spark.executor.Executor.<init>(Executor.scala:247)
at org.apache.spark.scheduler.local.LocalEndpoint.<init>(LocalSchedulerBackend.scala:64)
at org.apache.spark.scheduler.local.LocalSchedulerBackend.start(LocalSchedulerBackend.scala:132)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:220)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:579)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.base/java.lang.reflect.Constructor.newInstance(Unknown Source)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:238)
at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.base/java.lang.Thread.run(Unknown Source)
Caused by: io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: /<DRIVER_IP>:44541
Caused by: java.net.ConnectException: Connection refused
at java.base/sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at java.base/sun.nio.ch.SocketChannelImpl.finishConnect(Unknown Source)
at io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:330)
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:334)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:702)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:650)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:576)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:493)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.base/java.lang.Thread.run(Unknown Source)
Just curious if anyone here has run into a similar problem before, and what the recommended way to resolve this would be...
*Thread Reply:* Do you have small configuration and job to replicate this?
*Thread Reply:* Yeah. For configs:
spark.driver.bindAddress: "localhost"
spark.master: "local[**]"
spark.sql.catalogImplementation: "hive"
spark.openlineage.transport.endpoint: "<endpoint>"
spark.openlineage.transport.type: "http"
spark.sql.catalog.spark_catalog: "org.apache.spark.sql.delta.catalog.DeltaCatalog"
spark.openlineage.transport.url: "<url>"
spark.extraListeners: "io.openlineage.spark.agent.OpenLineageSparkListener"
and job is submitted via spark submit in client mode with number of executors set to 0.
The spark job by itself could be anything...I think the job fails before initializing the spark session itself.
*Thread Reply:* The issue is because of the spark.jars.packages config... spark.jars config also runs into the same issue. Because the executor tries to fetch the jar from driver for some reason even though there is no executors set...
*Thread Reply:* TBH I'm not sure if we can do anything about it. Seems like just having any SparkListener which is not in Spark jars would fall under the same problems, right?
*Thread Reply:* Yeah... Actually, this was because of binding the driver ip to localhost. In that case, the executor was not able to get the jar from the driver. But yeah I don't think we could have done anything from openlienage end anyway for this. Was just an interesting error to encounter lol

Hi, I am new to open lineage. I was able to follow https://openlineage.io/getting-started/ to create a lineage "my-input-->my-job-->my-output". I want to use "my-output" as an input dataset, and connect to the next job, thing like this "my-input-->my-job-->my-output-->my-job2-->my-final-output". How to do it? I have trouble to set eventType and runId, etc. Once the new lineages get massed up, the Marquez UI becomes blank (which is a separated issue).
*Thread Reply:* In this case you would have four runevents:
- a
STARTevent onmy-jobwheremy-inputis the input andmy-outputis the output, with a runId you generate on the client - a
COMPLETEevent onmy-jobwith the same runId from #1 - a
STARTevent onmy-job2where the input ismy-outputand the output ismy-final-output, with a separate runId you generate - a
COMPLETEevent onmy-job2with the same runId from #3
*Thread Reply:* thanks for the response. I tried it but now the UI only shows like one second and then turn to blank. I has similar issue before. It seems to me every time when I added a bad lineage, the UI stops working. I have to delete the docker image:-( Not sure whether it is MacOS M1 related issue.
*Thread Reply:* Hmmm, that's interesting. Not sure I've seen that before. If you happen to catch it in that state again, perhaps capture the contents of the lineage_events table so it can be replicated.
*Thread Reply:* I can fairly easy to reproduce this blank UI issue. Apparently I used the same runId for two different jobs. If I use different unId (which I should), the lineage displays correctly. Thanks again!
*Thread Reply:* You can add https://openlineage.io/docs/spec/facets/dataset-facets/column_lineage_facet/ to your datasets.
However, I don't think you can currently do any filtering over it
*Thread Reply:* you can see a good example here, @Lq Dodo: https://github.com/MarquezProject/marquez/blob/289fa3eef967c8f7915b074325bb6f8f55480030/docker/metadata.json#L430
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* those examples really help. I can at least build the lineage with column level info using the apis. thanks a lot! Ideally I'd like select one column from the UI and then show me the column level graph. Seems not possible.
*Thread Reply:* correct, right now there isn't column-level metadata on the lineage graph 😞

Is airflow mandatory, while integrating snowflake with openlineage?
I am currently looking for a solution which can capture lineage details from snowflake execution
*Thread Reply:* something needs to trigger lineage collection, are you using some sort of scheduler / execution engine?
*Thread Reply:* Nope... We currently don't have scheduling tool. Isn't it possible to use open lineage api and collect the details?
@channel This month’s OpenLineage TSC meeting is on Thursday, April 20th, at 10 am PT. Meeting info: https://openlineage.io/meetings/. All are welcome! On the tentative agenda:
- Announcements
- Updates (new!) a. OpenLineage in Airflow AIP b. Static lineage support c. Reworking namespaces
- Recent release overview
- A new consumer
- Caching support for column lineage
- Discussion items a. Snowflake tagging
- Open discussion Notes: https://bit.ly/OLwiki Is there a topic you think the community should discuss at this or a future meeting? Reply or DM me to add items to the agenda.
Hi!
I have a specific question about how OpenLineage fits in between Amazon MWAA and Marquez on AWS EKS. I guess I need to change for example the etl_openlineage DAG in this Snowflake integration tutorial and the OPENLINEAGE_URL here. However, I'm wondering how to reproduce the Docker containers airflow, airflow_scheduler, and airflow_worker here.
I heard from @Ross Turk that @Willy Lulciuc and @Michael Collado are experts on the K8s integration for OpenLineage and Marquez. Could you provide me some recommendations on how to approach this integration? Or can anyone else help me?
Kind regards,
Tom

[RESOLVED]👋 Hi there, I’m doing a POC of OpenLineage for our airflow deployment. We have a ton of custom operators and I’m trying to test out extracting lineage using the get_openlineage_facets_on_start method. Currently when I’m testing I can see that the OpenLineage plugin is running via airflow plugins but am not able to see that the method is ever getting called. Do I need to do anything else to tell the default extractor to use get_openlineage_facets_on_start? This is the documentation I’m referencing: https://openlineage.io/docs/integrations/airflow/extractors/default-extractors
*Thread Reply:* E.g. do I need to update my custom operators to inherit from DefaultExtractor?
*Thread Reply:* FWIW, I can tell some level of connectivity to my Marquez deployment is working since I can see it created the default namespace I defined in my OPENLINEAGE_NAMESPACE env var.
*Thread Reply:* hey John, it is enough to add the method to your custom operator. Perhaps something breaks inside the method. Did anything show up in the logs?
*Thread Reply:* That’s the strange part. I’m not seeing anything to suggest that the method is ever getting called. I’m also expecting that the listener created by the plugin should at least be calling this log line when the task runs. However, I’m not seeing that either. I’m able to verify the plugin is registered using airflow plugins and have debug level logging enabled via AIRFLOW__LOGGING__LOGGING_LEVEL='DEBUG'. This is the output of airflow plugins
name | macros | listeners | source
==================+================================================+==============================+=================================================
OpenLineagePlugin | openlineage.airflow.macros.lineage_run_id,open | openlineage.airflow.listener | openlineage-airflow==0.22.0:
| lineage.airflow.macros.lineage_parent_id | | EntryPoint(name='OpenLineagePlugin',
| | | value='openlineage.airflow.plugin:OpenLineagePlu
| | | gin', group='airflow.plugins')
Appreciate any ideas you might have!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Figured this out. Just needed to run the airflow scheduler and trigger tasks through the DAGs vs. airflow tasks test …
I have a question that I believe will be very easy to answer, and I think I know the answer already, but I want to confirm my understanding of extracting OpenLineage with airflow python scripts.
Extractors extract lineage from operators, so they have to be using operators, right? If someone asks if I can get lineage from their Airflow-orchestrated python scripts, and they show me their scripts but they’re not importing anything starting with airflow.operators, then I can’t use extractors and therefore can’t get lineage. Is that accurate?
*Thread Reply:* (they are importing dagkit sdk stuff like Job, JobContext, ExecutionContext, and NodeContext.)
*Thread Reply:* Do they run those scripts in PythonOperator? If so, they should receive some events but with no datasets extracted
*Thread Reply:* How can I know that? Would it be in the scripts or the airflow configuration or...
*Thread Reply:* And "with no datasets extracted" that means I wouldn't have the schema of the input and output datasets? (I need the db/schema/table/column names for my purposes)
*Thread Reply:* That really depends what is the current code but in general any custom code in Airflow does not extract any extra information, especially datasets. One can write their own extractors (more in the docs)
*Thread Reply:* Thanks! This is very helpful. Exactly what I needed.

Hi. I was exploring OpenLineage and I want to know does OpenLineage integrate with MS-SQL (Microsoft SQL Server) ? If yes, how to generate OpenLineage events for MS-SQL Views/Tables/Queries?
*Thread Reply:* Currently there's no extractor implemented for MS-SQL. We try to update list of supported databases here: https://openlineage.io/docs/integrations/about/
@channel Save the date: the next OpenLineage meetup will be in New York on April 26th! More info is coming soon…
@channel Due to many TSC members being on vacation this week, this month’s TSC meeting will be moved to next Thursday, April 20th. All are welcome! https://openlineage.slack.com/archives/C01CK9T7HKR/p1680801164289949
Hi everyone!
I'm so sorry for all the messages but I'm trying to get Snowflake, OpenLineage and Marquez working for days now. Hopefully, this is my last question.
The snowflake.connector import connect package seems to be outdated here in extract_openlineage.py and is not working for airflow. Does anyone know how to rewrite this code (e.g., with SnowflakeOperator ) and extract the openlineage access history? You'd be my absolute hero!!!
<a href="https://github.com/Snowflake-Labs/OpenLineage-AccessHistory-Setup">Snowflake-Labs/OpenLineage-AccessHistory-Setup</a>
*Thread Reply:* > The snowflake.connector import connect package seems to be outdated here in extract_openlineage.py and is not working for airflow.
What's the error?
> Does anyone know how to rewrite this code (e.g., with SnowflakeOperator )
Current extractor for SnowflakeOperator extracts lineage for SQL executed in the task, in contrast to the method above with OPENLINEAGE_ACCESS_HISTORY view
<a href="https://github.com/Snowflake-Labs/OpenLineage-AccessHistory-Setup">Snowflake-Labs/OpenLineage-AccessHistory-Setup</a>
*Thread Reply:* Hi Maciej!Thank you so much for the reply! I managed to generate a working combination on Windows between the airflow example in the marquez git and the snowflake openlineage git. The only error I still get is:
****** Log file does not exist: /opt/bitnami/airflow/logs/dag_id=etl_openlineage/run_id=manual__2023-04-10T14:12:53.764783+00:00/task_id=send_ol_events/attempt=1.log
****** Fetching from: <http://1c8bb4a78f14:8793/log/dag_id=etl_openlineage/run_id=manual__2023-04-10T14:12:53.764783+00:00/task_id=send_ol_events/attempt=1.log>
****** !!!! Please make sure that all your Airflow components (e.g. schedulers, webservers and workers) have the same 'secret_key' configured in 'webserver' section and time is synchronized on all your machines (for example with ntpd) !!!!!
************ See more at <https://airflow.apache.org/docs/apache-airflow/stable/configurations-ref.html#secret-key>
************ Failed to fetch log file from worker. Client error '403 FORBIDDEN' for url '<http://1c8bb4a78f14:8793/log/dag_id=etl_openlineage/run_id=manual__2023-04-10T14:12:53.764783+00:00/task_id=send_ol_events/attempt=1.log>'
For more information check: <https://httpstatuses.com/403>
This one doesn't make sense to me. I found a workaround for the ETL examples in the OpenLineage git by manually creating a Snowflake connector in Airflow, however, the error is still present for the extract_openlineage.py file. I noticed this file is the only one that uses snowflake.connector import connect and not airflow.providers.snowflake.operators.snowflake import SnowflakeOperator like the other ETL Dags.
*Thread Reply:* I think it's Airflow error related to getting logs from worker
*Thread Reply:* snowflake.connector is a Snowflake connector library that SnowflakeOperator uses underneath to connect to Snowflake
*Thread Reply:* Ah alright! Thanks for pointing that out! 🙂 Do you know how to solve it? Or do you have any recommendations on how to look for the solution?
*Thread Reply:* I have no experience with Windows, and I think it's the issue: https://github.com/apache/airflow/issues/10388
I would try running it in Docker TBH
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* Yeah I was running Airflow in Docker but this didn't work. I'll try to use my Macbook for now because I don't think there is a solution for this in the short time. Thank you so much for the support though!!
Hi All, My team and I have been building a status page based on open lineage and I did a talk about it… keen for feedback and thoughts: https://youtu.be/nGh5_j3hXrE

*Thread Reply:* Very interesting!
Hi Peter. Looks good. I like the way you introduced the premise of, and benefits of, using OpenLineage for your project. Have you also explored other integrations in addition to dbt?
*Thread Reply:* Thanks Ernie, I’m looking at Airflow as well as GE and would like to contribute back to the project as well… we’re close to getting a public preview release of our product done and then we want to help build out open lineage
[Resolved] Has anyone seen this error before where the openlineage-airflow plugin / listener fails to deepcopy the task instance? I’m using the native airflow DAG / BashOperator objects to do a basic test of static lineage tagging. More details in 🧵
*Thread Reply:* The dag is basically just: ```dag = DAG( dagid="asanaexampledag", defaultargs=defaultargs, scheduleinterval=None, )
samplelineagetask = BashOperator( taskid="samplelineagetask", bashcommand='echo $OPENLINEAGEURL', dag=dag, inlets=[Table(database="redshift", cluster="someschema", name="someinputtable")], outlets=[Table(database="redshift", cluster="someotherschema", name="someoutputtable")] )```
*Thread Reply:* This is the error I’m getting, seems to be coming from this line:
[2023-04-13, 17:45:33 UTC] {logging_mixin.py:115} WARNING - Exception in thread Thread-1:
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/threading.py", line 926, in _bootstrap_inner
self.run()
File "/opt/conda/lib/python3.7/threading.py", line 870, in run
self._target(**self._args, ****self._kwargs)
File "/opt/conda/lib/python3.7/site-packages/openlineage/airflow/listener.py", line 89, in on_running
task_instance_copy = copy.deepcopy(task_instance)
File "/opt/conda/lib/python3.7/copy.py", line 180, in deepcopy
y = _reconstruct(x, memo, **rv)
File "/opt/conda/lib/python3.7/copy.py", line 281, in _reconstruct
state = deepcopy(state, memo)
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 161, in deepcopy
y = copier(memo)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/baseoperator.py", line 1156, in __deepcopy__
setattr(result, k, copy.deepcopy(v, memo))
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 161, in deepcopy
y = copier(memo)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/dag.py", line 1941, in __deepcopy__
setattr(result, k, copy.deepcopy(v, memo))
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 161, in deepcopy
y = copier(memo)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/baseoperator.py", line 1156, in __deepcopy__
setattr(result, k, copy.deepcopy(v, memo))
File "/opt/conda/lib/python3.7/copy.py", line 180, in deepcopy
y = _reconstruct(x, memo, **rv)
File "/opt/conda/lib/python3.7/copy.py", line 281, in _reconstruct
state = deepcopy(state, memo)
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 150, in deepcopy
y = copier(x, memo)
File "/opt/conda/lib/python3.7/copy.py", line 241, in _deepcopy_dict
y[deepcopy(key, memo)] = deepcopy(value, memo)
File "/opt/conda/lib/python3.7/copy.py", line 161, in deepcopy
y = copier(memo)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/baseoperator.py", line 1156, in __deepcopy__
setattr(result, k, copy.deepcopy(v, memo))
File "/opt/conda/lib/python3.7/site-packages/airflow/models/baseoperator.py", line 1000, in __setattr__
self.set_xcomargs_dependencies()
File "/opt/conda/lib/python3.7/site-packages/airflow/models/baseoperator.py", line 1107, in set_xcomargs_dependencies
XComArg.apply_upstream_relationship(self, arg)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/xcom_arg.py", line 186, in apply_upstream_relationship
op.set_upstream(ref.operator)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/taskmixin.py", line 241, in set_upstream
self._set_relatives(task_or_task_list, upstream=True, edge_modifier=edge_modifier)
File "/opt/conda/lib/python3.7/site-packages/airflow/models/taskmixin.py", line 185, in _set_relatives
dags: Set["DAG"] = {task.dag for task in [**self.roots, **task_list] if task.has_dag() and task.dag}
File "/opt/conda/lib/python3.7/site-packages/airflow/models/taskmixin.py", line 185, in <setcomp>
dags: Set["DAG"] = {task.dag for task in [**self.roots, **task_list] if task.has_dag() and task.dag}
File "/opt/conda/lib/python3.7/site-packages/airflow/models/dag.py", line 508, in __hash__
val = tuple(self.task_dict.keys())
AttributeError: 'DAG' object has no attribute 'task_dict'
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* This is with Airflow 2.3.2 and openlineage-airflow 0.22.0
*Thread Reply:* Seems like it might be some issue like this with a circular structure? https://stackoverflow.com/questions/46283738/attributeerror-when-using-python-deepcopy
*Thread Reply:* Just by quick look at it, it will definitely be fixed with Airflow 2.6, as it won't need to deepcopy anything.
*Thread Reply:* I can't seem to reproduce the issue. I ran following example DAG with same Airflow and OL versions as yours: ```import datetime
from airflow.lineage.entities import Table from airflow.models import DAG from airflow.operators.bash import BashOperator
defaultargs = { "startdate": datetime.datetime.now() }
dag = DAG( dagid="asanaexampledag", defaultargs=defaultargs, scheduleinterval=None, )
samplelineagetask = BashOperator( taskid="samplelineagetask", bashcommand='echo $OPENLINEAGEURL', dag=dag, inlets=[Table(database="redshift", cluster="someschema", name="someinputtable")], outlets=[Table(database="redshift", cluster="someotherschema", name="someoutputtable")] )```
*Thread Reply:* is there any extra configuration you made possibly?
*Thread Reply:* @John Lukenoff, I was finally able to reproduce this when passing xcom as task.output
looks like this was reported here and solved by this PR (not sure if this was released in 2.3.3 or later)
<a href="https://github.com/apache/airflow">apache/airflow</a>
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* Ah interesting. Let me see if bumping my Airflow version resolves this. Haven’t had a chance to tinker with it much since yesterday.
*Thread Reply:* I ran it against 2.4 and same dag works
*Thread Reply:* 👍 Looks like a fix for that issue was rolled out in 2.3.3. I’m gonna try that for now (my company has a notoriously difficult time with airflow major version updates 😅)
*Thread Reply:* Got this working! We just monkey patched the __deepcopy__ method of the BaseOperator for now until we can get bandwidth for an airflow upgrade. Thanks for the help here!
Hi everyone, I am facing this null pointer error:
ERROR AsyncEventQueue: Listener OpenLineageSparkListener threw an exception
java.lang.NullPointerException
java.base/java.util.concurrent.ConcurrentHashMap.putVal(Unknown Source)
java.base/java.util.concurrent.ConcurrentHashMap.put(Unknown Source)
io.openlineage.spark.agent.JobMetricsHolder.addMetrics(JobMetricsHolder.java:40)
io.openlineage.spark.agent.OpenLineageSparkListener.onTaskEnd(OpenLineageSparkListener.java:179)
org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:45)
org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117)
org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101)
org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
<a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1381)
org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
Could I get some help on this pls 🙇
*Thread Reply:* This is the spark submit command:
spark-submit --py-files /usr/local/lib/common_utils.zip,/usr/local/lib/team_utils.zip,/usr/local/lib/project_utils.zip
--conf spark.executor.cores=16
--conf spark.hadoop.fs.s3a.connection.maximum=100 --conf spark.sql.shuffle.partitions=1000
--conf spark.speculation=true --conf spark.sql.adaptive.advisoryPartitionSizeInBytes=256MB
--conf spark.hadoop.fs.s3a.multiobjectdelete.enable=false --conf spark.memory.fraction=0.7 --conf spark.kubernetes.executor.label.experiment=some_label --conf spark.kubernetes.executor.label.team=team_name --conf spark.driver.memory=26112m --conf <a href="http://spark.kubernetes.executor.label.app.kubernetes.io/managed-by=pipeline_name">spark.kubernetes.executor.label.app.kubernetes.io/managed-by=pipeline_name</a> --conf spark.kubernetes.executor.label.instance-type=4xlarge --conf spark.executor.instances=10 --conf spark.kubernetes.executor.label.env=prd --conf spark.kubernetes.executor.label.job-name=job_name --conf spark.kubernetes.executor.label.owner=owner --conf spark.kubernetes.executor.label.pipeline=pipeline --conf spark.kubernetes.executor.label.platform-name=platform_name --conf spark.speculation.multiplier=10 --conf spark.memory.storageFraction=0.4 --conf spark.driver.maxResultSize=26112m --conf spark.kubernetes.executor.request.cores=15000m --conf spark.speculation.interval=1s --conf spark.executor.memory=104g --conf spark.sql.catalogImplementation=hive --conf spark.eventLog.dir=file:///logs/spark-events --conf spark.hadoop.fs.s3a.threads.max=100 --conf spark.speculation.quantile=0.75 job.py
*Thread Reply:* @Anirudh Shrinivason pls create an issue for this and I will look at it. Although it may be difficult to find the root cause, null pointer exception should be always avoided and this seems to be a bug.
*Thread Reply:* Hmm yeah sure. I'll create an issue on github for this issue. Thanks!
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1784 Opened an issue here
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hey! Question about spark column lineage. What is the intended way to write custom code for getting column lineage? i am trying to implement CustomColumnLineageVisitor but when I try to do so I get:
io.openlineage.spark3.agent.lifecycle.plan.column.CustomColumnLineageVisitor is not public in io.openlineage.spark3.agent.lifecycle.plan.column; cannot be accessed from outside package
*Thread Reply:* Hi @Allison Suarez, CustomColumnLineageVisitor should be definitely public. I'll prepare a fix PR for that. We do have a test for custom column lineage visitors (CustomColumnLineageVisitorTestImpl), but they're in the same package. Thanks for bringing this.
*Thread Reply:* This PR should resolve problem: https://github.com/OpenLineage/OpenLineage/pull/1788
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you so much @Paweł Leszczyński 🙂
*Thread Reply:* How does the release process work for OL? Do we have to wait a certain amount of time to get this change in a new release?
*Thread Reply:* 0.22.0 was released two weeks ago, so the next schedule should be in next two weeks. We can ask @Michael Robinson his opinion on releasing 0.22.1 before that.
*Thread Reply:* Hi Allison 👋, Anyone can request a release in the #general channel. I encourage you to go this route. You’ll need three +1s (there’s more info about the process here: https://github.com/OpenLineage/OpenLineage/blob/main/GOVERNANCE.md), but I don’t know of any reasons why we can’t do a mid-cycle release. 🙂
*Thread Reply:* seems like we got enough +1s
*Thread Reply:* We need three committers to give a +1. I’ll reach out again to see if I can recruit a third
*Thread Reply:* Yeah, sorry I forgot to mention that!
*Thread Reply:* we have it now
@channel This month’s TSC meeting is tomorrow, 4/20, at 10 am PT: https://openlineage.slack.com/archives/C01CK9T7HKR/p1681167638153879
I would like to get a 0.22.1 patch release to get the issue described in this thread before the next scheduled release.
 }
}
*Thread Reply:* The release is authorized and will be initiated within 2 business days (not including tomorrow).
Here are the details about next week’s OpenLineage Meetup at Astronomer’s NY offices: https://openlineage.io/blog/nyc-meetup. Hope to see you there if you can make it!

Hi Team, I tried integrating openLineage with spark databricks and followed the steps as per the documentation. Installation and all looks good as the listener is enabled, but no event is getting passed to Marquez. I can see below message in log4j logs. Am I missing any configuration to be set?
Running few spark commands in databricks notebook to create events.
23/04/20 11:10:34 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionStart 23/04/20 11:10:34 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionEnd
*Thread Reply:* Hi Sai,
Perhaps you could try within printing OpenLineage events into logs. This can be achieved with Spark config parameter:
spark.openlineage.transport.type
equal to console .
This can help you determine if a problem is generating Openlineage events itself or emitting them into Marquez.
*Thread Reply:* Hi @Paweł Leszczyński I passed this config as below, but could not see any changes in the logs. The events are getting generated sometimes like below:
23/04/20 10:00:15 INFO ConsoleTransport: {"eventType":"START","eventTime":"2023-04-20T10:00:15.085Z","run":{"runId":"ef4f46d1-d13a-420a-87c3-19fbf6ffa231","facets":{"spark.logicalPlan":{"producer":"https://github.com/OpenLineage/OpenLineage/tree/0.22.0/integration/spark","schemaURL":"https://openlineage.io/spec/1-0-5/OpenLineage.json#/$defs/RunFacet","plan":[{"class":"org.apache.spark.sql.catalyst.plans.logical.CreateTableAsSelect","num-children":2,"name":0,"partitioning":[],"query":1,"tableSpec":null,"writeOptions":null,"ignoreIfExists":false},{"class":"org.apache.spark.sql.catalyst.analysis.ResolvedTableName","num-children":0,"catalog":null,"ident":null},{"class":"org.apache.spark.sql.catalyst.plans.logical.Project","num-children":1,"projectList":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"workorderid","dataType":"integer","nullable":true,"metadata":{},"exprId":{"product-cl
*Thread Reply:* Ok, great. This means the issue is related to Spark <-> Marquez connection
*Thread Reply:* Some time ago Spark config has changed and here is the up-to-date-documentation: https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark
*Thread Reply:* please note that spark.openlineage.transport.url has to be used which is different from what you have on screenshot attached
*Thread Reply:* You mean instead of "spark.openlineage.host" I need to use "spark.openlineage.transport.url"?
*Thread Reply:* yes, please give it a try
*Thread Reply:* sure will give a try and let you know the outcome
*Thread Reply:* and set spark.openlineage.transport.type to http
*Thread Reply:* does these configs suffice or I need to add anything else
spark.extraListeners io.openlineage.spark.agent.OpenLineageSparkListener spark.openlineage.consoleTransport true spark.openlineage.version v1 spark.openlineage.transport.type http spark.openlineage.transport.url http://<host>:5000/api/v1/namespaces/sparkintegrationpoc/
*Thread Reply:* spark.openlineage.consoleTransport true this one can be removed
*Thread Reply:* otherwise shall be OK
*Thread Reply:* I added these configs and run, but still same issue. Now I am not able to see the events in log file as well.
*Thread Reply:* 23/04/20 13:51:22 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionStart 23/04/20 13:51:22 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerSQLExecutionEnd
Does this need any changes in the config side?
If you are trying to get into the OpenLineage Technical Steering Committee meeting, you have to RSVP to the specific event at https://www.addevent.com/calendar/pP575215 to get the password (in the invitation to add to your calendar)

Here is a nice article I found online that briefly explains about the spark catalogs just for some context: https://www.waitingforcode.com/apache-spark-sql/pluggable-catalog-api/read In reference to the V2SessionCatalog use case brought up in the meeting just now

*Thread Reply:* @Anirudh Shrinivason Thanks for linking this as it contains a clear explanation on Spark catalogs. However, I am still unable to write a failing integration test that reproduces the scenario. Could you provide an example of Spark which is failing on V2SessionCatalog and provide more details how are you trying to read/write data?
*Thread Reply:* Hi @Paweł Leszczyński I noticed this issue on one of our pipelines before actually. I didn't note down which pipeline the issue was occuring in unfortunately. I'll keep checking from my end to identify the spark job that ran into this error. In the meantime, I'll also try to see for which cases deltaCatalog makes use of the V2SessionCatalog to understand this better. Thanks!
*Thread Reply:* Hi @Paweł Leszczyński
'''
CREATE TABLE IF NOT EXISTS TABLE_NAME (
SOME COLUMNS
) USING delta
PARTITIONED BY (col)
location 's3 location'
'''
A spark sql like this actually triggers the V2SessionCatalog
*Thread Reply:* Thanks @Anirudh Shrinivason, will look into that.
*Thread Reply:* which spark & delta versions are you using?
*Thread Reply:* I am not 100% sure if this is something you described, but this was an error I was able to replicate and fix. Please look at the exception stacktrace and let me know if it is same on your side. https://github.com/OpenLineage/OpenLineage/pull/1798
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hmm actually I am noticing this error on my local
*Thread Reply:* But on the prod job, I am seeing no such error in the logs...
*Thread Reply:* Also, I was using spark 3.1.2
*Thread Reply:* then perhaps it's sth different :face_palm: will try to replicate on spark 3.1.2
*Thread Reply:* Not too sure which delta version the prod job was using...
*Thread Reply:* I was running on Spark 3.1.2 the following command:
spark.sql(
"CREATE TABLE t_partitioned (a int, b int) USING delta "
+ "PARTITIONED BY (a) LOCATION '/tmp/delta/tbl'"
);
and I got Openlineage event emitted with t_partitioned output dataset.
*Thread Reply:* Oh... hmm... that is strange. Let me check more from my end too
*Thread Reply:* for spark 3.1, we're using delta 1.0.0

Hi team! I have two Spark jobs chained together to process incoming data files, and I'm using openlineage-spark-0.22.0 with Marquez to visualize. I'm struggling to figure out the best way to use spark.openlineage.parentRunId and spark.openlineage.parentJobName. Should these values be unique for each Spark job? Should they be unique for each execution of the chain of both spark jobs? Or should they be the same for all runs? I'm setting them to be unique to the execution of the chain and I'm getting strange results (jobs are not showing completed, and not showing at all)
*Thread Reply:* Hi Cory, I think the definition of ParentRunFacet (https://openlineage.io/docs/spec/facets/run-facets/parent_run) contains answer to that:
Commonly, scheduler systems like Apache Airflow will trigger processes on remote systems, such as on Apache Spark or Apache Beam jobs. Those systems might have their own OpenLineage integration and report their own job runs and dataset inputs/outputs. The ParentRunFacet allows those downstream jobs to report which jobs spawned them to preserve job hierarchy. To do that, the scheduler system should have a way to pass its own job and run id to the child job.
For example, when airflow is used to run Spark job, we want Spark events to contain some information on what triggered the spark job and parameters, you ask about, are used to pass that information from airflow operator to spark job.
*Thread Reply:* Thank you for pointing me at this documentation; I did not see it previously. In my setup, the calling system is AWS Step Functions, which have no integration with OpenLineage.
So I've been essentially passing non-existing parent job information to OpenLineage. It has been useful as a data point for searches and reporting though.
Is there any harm in doing what I am doing? Is it causing the jobs that I see never completing?
*Thread Reply:* I think parentRunId should be the same for Openlineage START and COMPLETE event. Is it like this in your case?
*Thread Reply:* that makes sense, and based on my configuration, i would think that it would be. however, given that i am seeing incomplete jobs in Marquez, i'm wondering if somehow the parentrunID is changing. I need to investigate
@channel
We released OpenLineage 0.23.0, including:
Additions:
• SQL: parser improvements to support: copy into, create stage, pivot #1742 @pawel-big-lebowski
• dbt: add support for snapshots #1787 @JDarDagran
Changes:
• Spark: change custom column lineage visitors #1788 @pawel-big-lebowski
Plus bug fixes, doc changes and more.
Thanks to all the contributors!
For the bug fixes and details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.23.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.22.0...0.23.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Just curious, how long before we can see 0.23.0 over here: https://mvnrepository.com/artifact/io.openlineage/openlineage-spark
*Thread Reply:* I think @Michael Robinson has to manually promote artifacts
*Thread Reply:* I promoted the artifacts, but there is a delay before they appear in Maven. A couple releases ago, the delay was about 24 hours long
*Thread Reply:* Ahh I see... Thanks!
*Thread Reply:* @Anirudh Shrinivason are you using search.maven.org by chance? Version 0.23.0 is not appearing there yet, but I do see it on central.sonatype.com.
*Thread Reply:* Hmm I can see it now on search.maven.org actually. But I still cannot see it on https://mvnrepository.com/artifact/io.openlineage/openlineage-spark ...
*Thread Reply:* Understood. I believe you can download the 0.23.0 jars from central.sonatype.com. For Spark, try going here: https://central.sonatype.com/artifact/io.openlineage/openlineage-spark/0.23.0/versions
*Thread Reply:* Yup. I can see it on all maven repos now haha. I think its just the delay.
*Thread Reply:* ~24 hours ig

Hello Everyone, I am facing an issue while trying to integrate openlineage with Jupyter notebook. I am following the Docs. My containers are running and I am getting the URL for Jupyter notebook but when I try with the token in the terminal, I get invalid credentials error. Can someone please help resolve this ? Am I doing something wrong..
*Thread Reply:* Good news, everyone! The login worked on the second attempt after starting the Docker containers. Although it's unclear why it failed the first time.
Hi team, I have a question regarding the customization of transport types in OpenLineage. At my company, we are using OpenLineage to report lineage from our Spark jobs to OpenMetadata. We have created a custom OpenMetadataTransport to send lineage to the OpenMetadata APIs, conforming to the OpenMetadata format. Currently, we are using a fork of OpenLineage, as we needed to make some changes in the core to identify the new TransportConfig. We believe it would be more optimal for OpenLineage to support custom transport types, which would allow us to use OpenLineage JAR alongside our own JAR containing the custom transport. I noticed some comments in the code suggesting that customizations are possible. However, I couldn't make it work without modifying the TransportFactory and the TransportConfig interface, as the transport types are hardcoded. Am I missing something? 🤔 If custom transport types are not currently supported, we would be more than happy to contribute a PR that enables custom transports. What are your thoughts on this?
*Thread Reply:* Hi Natalie, it's wonderful to hear you're planning to contribute. Yes, you're right about TransportFactory . What other transport type was in your mind? If it is something generic, then it is surely OK to include it within TransportFactory. If it is a custom feature, we could follow ServiceLoader pattern that we're using to allow including custom plan visitors and dataset builders.
*Thread Reply:* Hi @Paweł Leszczyński Yes, I was planning to change TransportFactory to support custom/generic transport types using ServiceLoader pattern. After this change is done, I will be able to use our custom OpenMetadataTransport without changing anything in OpenLineage core. For now I don't have other types in mind, but after we'll add the customization support anyone will be able to create their own transport type and report the lineage to different backends
*Thread Reply:* Perhaps it's not strictly related to this particular usecase, but you may also find interesting our recent PoC about Fluentd & Openlineage integration. This will bring some cool backend features like: copy event and send it to multiple backends, send it to backends supported by fluentd output plugins etc. https://github.com/OpenLineage/OpenLineage/pull/1757/files?short_path=4fc5534#diff-4fc55343748f353fa1def0e00c553caa735f9adcb0da18baad50a989c0f2e935
*Thread Reply:* Sounds interesting. Thanks, I will look into it
Are you planning to come to the first New York OpenLineage Meetup this Wednesday at Astronomer’s offices in the Flatiron District? Don’t forget to RSVP so we know much food and drink to order!


*Thread Reply:* import json import os from pendulum import datetime
from airflow import DAG from airflow.decorators import task from openlineage.client import OpenLineageClient from snowflake.connector import connect
SNOWFLAKEUSER = os.getenv('SNOWFLAKEUSER') SNOWFLAKEPASSWORD = os.getenv('SNOWFLAKEPASSWORD') SNOWFLAKEACCOUNT = os.getenv('SNOWFLAKEACCOUNT')
@task def sendolevents(): client = OpenLineageClient.from_environment()
with connect(
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
account=SNOWFLAKE_ACCOUNT,
database='OPENLINEAGE',
schema='PUBLIC',
) as conn:
with conn.cursor() as cursor:
ol_view = 'OPENLINEAGE_ACCESS_HISTORY'
ol_event_time_tag = 'OL_LATEST_EVENT_TIME'
var_query = f'''
use warehouse {SNOWFLAKE_WAREHOUSE};
'''
cursor.execute(var_query)
var_query = f'''
set current_organization='{SNOWFLAKE_ACCOUNT}';
'''
cursor.execute(var_query)
ol_query = f'''
SELECT ** FROM {ol_view}
WHERE EVENT:eventTime > system$get_tag('{ol_event_time_tag}', '{ol_view}', 'table')
ORDER BY EVENT:eventTime ASC;
'''
cursor.execute(ol_query)
ol_events = [json.loads(ol_event[0]) for ol_event in cursor.fetchall()]
for ol_event in ol_events:
client.emit(ol_event)
if len(ol_events) > 0:
latest_event_time = ol_events[-1]['eventTime']
cursor.execute(f'''
ALTER VIEW {ol_view} SET TAG {ol_event_time_tag} = '{latest_event_time}';
''')
with DAG( 'etlopenlineage', startdate=datetime(2022, 4, 12), scheduleinterval='@hourly', catchup=False, defaultargs={ 'owner': 'openlineage', 'dependsonpast': False, 'emailonfailure': False, 'emailonretry': False, 'email': ['demo@openlineage.io'], 'snowflakeconnid': 'openlineagesnowflake' }, description='Send OL events every minutes.', tags=["extract"], ) as dag: sendol_events()
*Thread Reply:* OpenLineageClient expects RunEvent classes and you're sending it raw json. I think at this point your options are either sending them by constructing your own HTTP client, using something like requests, or using something like https://github.com/python-attrs/cattrs to structure json to RunEvent
*Thread Reply:* @Jakub Dardziński suggested that you can
change client.emit(ol_event) to client.transport.emit(ol_event) and it should work

*Thread Reply:* @Maciej Obuchowski I believe this is from https://github.com/Snowflake-Labs/OpenLineage-AccessHistory-Setup/blob/main/examples/airflow/dags/lineage/extract_openlineage.py
<a href="https://github.com/Snowflake-Labs/OpenLineage-AccessHistory-Setup">Snowflake-Labs/OpenLineage-AccessHistory-Setup</a>
*Thread Reply:* I believe this example no longer works - perhaps a new access history pull/push example could be created that is simpler and doesn’t use airflow.
*Thread Reply:* I think separating the actual getting data from the view and Airflow DAG would make sense
*Thread Reply:* Yeah - I also think that Airflow confuses the issue. You don’t need Airflow to get lineage from Snowflake Access History, the only reason Airflow is in the example is a) to simulate a pipeline that can be viewed in Marquez; b) to establish a mechanism that regularly pulls and emits lineage…
but most people will already have A, and the simplest example doesn’t need to accomplish B.
*Thread Reply:* just a few weeks ago 🙂 I was working on a script that you could run like SNOWFLAKE_USER=foo ./process_snowflake_lineage.py --from-date=xxxx-xx-xx --to-date=xxxx-xx-xx
*Thread Reply:* Hi @Ross Turk! Do you have a link to this script? Perhaps this script can fix the connection issue 🙂
*Thread Reply:* No, it never became functional before I stopped to take on another task 😕
Hi,
Currently, In the .env file, we have using the OPENLINEAGE_URL as <http://marquez-api:5000> and got the error
requests.exceptions.HTTPError: 422 Client Error: for url: <http://marquez-api:5000/api/v1/lineage>
we have tried using OPENLINEAGE_URL as <http://localhost:5000> and getting the error as
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=5000): Max retries exceeded with url: /api/v1/lineage (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fc71edb9590>: Failed to establish a new connection: [Errno 111] Connection refused'))
I'm not sure which variable value to use for OPENLINEAGE_URL, so please offer the correct variable value.
*Thread Reply:* Looks like the first URL is proper, but there's something wrong with entity - Marquez logs would help here.
*Thread Reply:* Airflow log does not tell us why Marquez rejected the event. Marquez logs would be more helpful
*Thread Reply:* We investigated the marquez container logs and were unable to locate the error. Could you please specify the log file that belongs to marquez while connecting the airflow or snowflake?
Is it correct that the marquez-web log points to <http://api:5000/>?
[HPM] Proxy created: /api/v1 -> <http://api:5000/>
App listening on port 3000!
*Thread Reply:* I've the same error at the moment but can provide some additional screenshots. The Event data in Snowflake seems fine and the data is being retrieved correctly by the Airflow DAG. However, there seems to be a warning in the Marquez API logs. Hopefully we can troubleshoot this together!
*Thread Reply:* Possibly the Python part between does some weird things, like double-jsonning the data? I can imagine it being wrapped in second, unnecessary JSON object
*Thread Reply:* I guess only way to check is print one of those events - in the form they are send in Python part, not Snowflake - and see how they are like. For example using ConsoleTransport or setting DEBUG log level in Airflow
*Thread Reply:* Here is a code snippet by using logging in DEBUG on the snowflake python connector:
[20230426T17:16:55.166+0000] {cursor.py:593} DEBUG - binding: [set currentorganization='[PRIVATE]';] with input=[None], processed=[{}] [2023-04-26T17:16:55.166+0000] {cursor.py:800} INFO - query: [set currentorganization='[PRIVATE]';] [2023-04-26T17:16:55.166+0000] {connection.py:1363} DEBUG - sequence counter: 2 [2023-04-26T17:16:55.167+0000] {cursor.py:467} DEBUG - Request id: f7bca188-dda0-4fe6-8d5c-a92dc5f9c7ac [2023-04-26T17:16:55.167+0000] {cursor.py:469} DEBUG - running query [set currentorganization='[PRIVATE]';] [2023-04-26T17:16:55.168+0000] {cursor.py:476} DEBUG - isfiletransfer: True [2023-04-26T17:16:55.168+0000] {connection.py:1035} DEBUG - _cmdquery [2023-04-26T17:16:55.168+0000] {connection.py:1062} DEBUG - sql=[set currentorganization='[PRIVATE]';], sequenceid=[2], isfiletransfer=[False] [2023-04-26T17:16:55.168+0000] {network.py:1162} DEBUG - Session status for SessionPool [PRIVATE]', SessionPool 1/1 active sessions [2023-04-26T17:16:55.169+0000] {network.py:850} DEBUG - remaining request timeout: None, retry cnt: 1 [2023-04-26T17:16:55.169+0000] {network.py:828} DEBUG - Request guid: 4acea1c3-6a68-4691-9af4-22f184e0f660 [2023-04-26T17:16:55.169+0000] {network.py:1021} DEBUG - socket timeout: 60 [2023-04-26T17:16:55.259+0000] {connectionpool.py:465} DEBUG - [PRIVATE]"POST /queries/v1/query-request?requestId=f7bca188-dda0-4fe6-8d5c-a92dc5f9c7ac&requestguid=4acea1c3-6a68-4691-9af4-22f184e0f660 HTTP/1.1" 200 1118 [2023-04-26T17:16:55.261+0000] {network.py:1047} DEBUG - SUCCESS [2023-04-26T17:16:55.261+0000] {network.py:1168} DEBUG - Session status for SessionPool [PRIVATE], SessionPool 0/1 active sessions [2023-04-26T17:16:55.261+0000] {network.py:729} DEBUG - ret[code] = None, after post request [2023-04-26T17:16:55.261+0000] {network.py:751} DEBUG - Query id: 01abe3ac-0603-4df4-0042-c78307975eb2 [2023-04-26T17:16:55.262+0000] {cursor.py:807} DEBUG - sfqid: 01abe3ac-0603-4df4-0042-c78307975eb2 [2023-04-26T17:16:55.262+0000] {cursor.py:813} INFO - query execution done [2023-04-26T17:16:55.262+0000] {cursor.py:827} DEBUG - SUCCESS [2023-04-26T17:16:55.262+0000] {cursor.py:846} DEBUG - PUT OR GET: False [2023-04-26T17:16:55.263+0000] {cursor.py:941} DEBUG - Query result format: json [2023-04-26T17:16:55.263+0000] {resultbatch.py:433} DEBUG - parsing for result batch id: 1 [2023-04-26T17:16:55.263+0000] {cursor.py:956} INFO - Number of results in first chunk: 1 [2023-04-26T17:16:55.263+0000] {cursor.py:735} DEBUG - executing SQL/command [2023-04-26T17:16:55.263+0000] {cursor.py:593} DEBUG - binding: [SELECT * FROM OPENLINEAGE_ACCESS_HISTORY WHERE EVENT:eventTime > system$get_tag(...] with input=[None], processed=[{}] [2023-04-26T17:16:55.264+0000] {cursor.py:800} INFO - query: [SELECT * FROM OPENLINEAGEACCESSHISTORY WHERE EVENT:eventTime > system$gettag(...] [2023-04-26T17:16:55.264+0000] {connection.py:1363} DEBUG - sequence counter: 3 [2023-04-26T17:16:55.264+0000] {cursor.py:467} DEBUG - Request id: 21e2ab85-4995-4010-865d-df06cf5ee5b5 [2023-04-26T17:16:55.265+0000] {cursor.py:469} DEBUG - running query [SELECT ** FROM OPENLINEAGEACCESSHISTORY WHERE EVENT:eventTime > system$gettag(...] [2023-04-26T17:16:55.265+0000] {cursor.py:476} DEBUG - isfiletransfer: True [2023-04-26T17:16:55.265+0000] {connection.py:1035} DEBUG - cmdquery [2023-04-26T17:16:55.265+0000] {connection.py:1062} DEBUG - sql=[SELECT ** FROM OPENLINEAGEACCESSHISTORY WHERE EVENT:eventTime > system$gettag(...], sequenceid=[3], isfiletransfer=[False] [2023-04-26T17:16:55.266+0000] {network.py:1162} DEBUG - Session status for SessionPool '[PRIVATE}', SessionPool 1/1 active sessions [2023-04-26T17:16:55.267+0000] {network.py:850} DEBUG - remaining request timeout: None, retry cnt: 1 [2023-04-26T17:16:55.268+0000] {network.py:828} DEBUG - Request guid: aba82952-a5c2-4c6b-9c70-a10545b8772c [2023-04-26T17:16:55.268+0000] {network.py:1021} DEBUG - socket timeout: 60 [2023-04-26T17:17:21.844+0000] {connectionpool.py:465} DEBUG - [PRIVATE] "POST /queries/v1/query-request?requestId=21e2ab85-4995-4010-865d-df06cf5ee5b5&requestguid=aba82952-a5c2-4c6b-9c70-a10545b8772c HTTP/1.1" 200 None [2023-04-26T17:17:21.879+0000] {network.py:1047} DEBUG - SUCCESS [2023-04-26T17:17:21.881+0000] {network.py:1168} DEBUG - Session status for SessionPool '[PRIVATE}', SessionPool 0/1 active sessions [2023-04-26T17:17:21.882+0000] {network.py:729} DEBUG - ret[code] = None, after post request [2023-04-26T17:17:21.882+0000] {network.py:751} DEBUG - Query id: 01abe3ac-0603-4df4-0042-c78307975eb6 [2023-04-26T17:17:21.882+0000] {cursor.py:807} DEBUG - sfqid: 01abe3ac-0603-4df4-0042-c78307975eb6 [2023-04-26T17:17:21.882+0000] {cursor.py:813} INFO - query execution done [2023-04-26T17:17:21.883+0000] {cursor.py:827} DEBUG - SUCCESS [2023-04-26T17:17:21.883+0000] {cursor.py:846} DEBUG - PUT OR GET: False [2023-04-26T17:17:21.883+0000] {cursor.py:941} DEBUG - Query result format: arrow [2023-04-26T17:17:21.903+0000] {resultbatch.py:102} DEBUG - chunk size=256 [2023-04-26T17:17:21.920+0000] {cursor.py:956} INFO - Number of results in first chunk: 112 [2023-04-26T17:17:21.949+0000] {arrowiterator.cpython-37m-x8664-linux-gnu.so:0} DEBUG - Batches read: 1 [2023-04-26T17:17:21.950+0000] {CArrowIterator.cpp:16} DEBUG - Arrow BatchSize: 1 [2023-04-26T17:17:21.950+0000] {CArrowChunkIterator.cpp:50} DEBUG - Arrow chunk info: batchCount 1, columnCount 1, usenumpy: 0 [2023-04-26T17:17:21.950+0000] {resultset.py:232} DEBUG - result batch 1 has id: data001 [2023-04-26T17:17:21.951+0000] {resultset.py:232} DEBUG - result batch 2 has id: data002 [2023-04-26T17:17:21.951+0000] {resultset.py:232} DEBUG - result batch 3 has id: data003 [2023-04-26T17:17:21.951+0000] {resultset.py:232} DEBUG - result batch 4 has id: data010 [2023-04-26T17:17:21.951+0000] {resultset.py:232} DEBUG - result batch 5 has id: data011 [2023-04-26T17:17:21.951+0000] {resultset.py:232} DEBUG - result batch 6 has id: data012 [2023-04-26T17:17:21.952+0000] {resultset.py:232} DEBUG - result batch 7 has id: data013 [2023-04-26T17:17:21.952+0000] {resultset.py:232} DEBUG - result batch 8 has id: data020 [2023-04-26T17:17:21.952+0000] {resultset.py:232} DEBUG - result batch 9 has id: data02_1
*Thread Reply:* I don't see any Airflow standard logs here, but anyway I looked at it and debugging it would not work if you're bypassing OpenLineageClient.emit and going directly to transport - the logging is done on Client level https://github.com/OpenLineage/OpenLineage/blob/acc207d63e976db7c48384f04bc578409f08cc8a/client/python/openlineage/client/client.py#L73
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I'm sorry, do you have a code snippet on how to get these logs from https://github.com/Snowflake-Labs/OpenLineage-AccessHistory-Setup/blob/main/examples/airflow/dags/lineage/extract_openlineage.py? I still get the ValueError for OpenLineageClient.emit
<a href="https://github.com/Snowflake-Labs/OpenLineage-AccessHistory-Setup">Snowflake-Labs/OpenLineage-AccessHistory-Setup</a>
*Thread Reply:* Hey does anyone have an idea on this? I'm still stuck on this issue 😞
*Thread Reply:* I've found the root cause. It's because facets don't have _producer and _schemaURL set. I'll provide a fix soon
The first New York OpenLineage Meetup is happening today at 5:30 pm ET at Astronomer’s offices in the Flatiron District! https://openlineage.slack.com/archives/C01CK9T7HKR/p1681931978353159
*Thread Reply:* I’ll be there! I’m looking forward to see you all.
*Thread Reply:* We’ll talk about the evolution of the spec.
delta_table = DeltaTable.forPath(spark, path)
delta_table.alias("source").merge(df.alias("update"),lookup_statement).whenMatchedUpdateAll().whenNotMatchedInsertAll().execute()
If I write based on df operations like this, I notice that OL does not emit any event. May I know whether these or similar cases can be supported too? 🙇
*Thread Reply:* I've created an integration test based on your example. The Openlineage event gets sent, however it does not contain output dataset. I will look deeper into that.
*Thread Reply:* Hey, sorry do you mean input dataset is empty? Or output dataset?
*Thread Reply:* I am seeing that input dataset is empty
*Thread Reply:* ooh, I see input datasets
*Thread Reply:* I create a test in SparkDeltaIntegrationTest class a test method:
```@Test
void testDeltaMergeInto() {
Dataset<Row> dataset =
spark
.createDataFrame(
ImmutableList.of(
RowFactory.create(1L, "bat"),
RowFactory.create(2L, "mouse"),
RowFactory.create(3L, "horse")
),
new StructType(
new StructField[] {
new StructField("a", LongType$.MODULE$, false, Metadata.empty()),
new StructField("b", StringType$.MODULE$, false, Metadata.empty())
}))
.repartition(1);
dataset.createOrReplaceTempView("temp");
spark.sql("CREATE TABLE t1 USING delta LOCATION '/tmp/delta/t1' AS SELECT ** FROM temp");
spark.sql("CREATE TABLE t2 USING delta LOCATION '/tmp/delta/t2' AS SELECT ** FROM temp");
DeltaTable.forName("t1")
.merge(spark.read().table("t2"),"t1.a = t2.a")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute();
verifyEvents(mockServer, "pysparkDeltaMergeIntoCompleteEvent.json");
}```
*Thread Reply:* Oh yeah my bad. I am seeing output dataset is empty.
*Thread Reply:* Checks out with your observation
*Thread Reply:* Hi @Paweł Leszczyński just curious, has a fix for this been implemented alr?
*Thread Reply:* Hi @Anirudh Shrinivason, I had some days ooo. I will look into this soon.
*Thread Reply:* Ahh okie! Thanks so much! Hope you had a good rest!
*Thread Reply:* yeah. this was an amazing extended weekend 😉
*Thread Reply:* This should be it: https://github.com/OpenLineage/OpenLineage/pull/1823
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Anirudh Shrinivason, please let me know if there is still something to be done within #1747 PROPOSAL] Support for V2SessionCatalog. I could not reproduce exactly what you described but fixed some issue nearby.
*Thread Reply:* Hmm yeah sure let me find out the exact cause of the issue. The pipeline that was causing the issue is now inactive haha. So I'm trying to backtrace from the limited logs I captured last time. Let me get back by next week thanks! 🙇
*Thread Reply:* Hi @Paweł Leszczyński I was trying to replicate the issue from my end, but couldn't do so. I think we can close the issue for now, and revisit later on if the issue resurfaces. Does that sound okay?
*Thread Reply:* sounds cool. we can surely create a new issue later on.

*Thread Reply:* @Paweł Leszczyński - I was trying to implement these new changes in databricks. I was wondering which java file should I use for building the jar file? Could you plese help me?
*Thread Reply:* Hi I found that these merge operations have no input datasets/col lineage: ```df.write.format(fileformat).mode(mode).option("mergeSchema", mergeschema).option("overwriteSchema", overwriteSchema).save(path)
df.write.format(fileformat).mode(mode).option("mergeSchema", mergeschema).option("overwriteSchema", overwriteSchema)\ .partitionBy(**partitions).save(path)
df.write.format(fileformat).mode(mode).option("mergeSchema", mergeschema).option("overwriteSchema", overwriteSchema)\
.partitionBy(**partitions).option("replaceWhere", where_clause).save(path)``
I also noticed the same issue when using theMERGE INTO` command from spark sql.
Would it be possible to extend the support to these df operations. too please? Thanks!
CC: @Paweł Leszczyński
*Thread Reply:* Hi @Anirudh Shrinivason, great to hear from you. Could you create an issue out of this? I am working at the moment on Spark 3.4. Once this is ready, I will look at the spark issues. And this one seems to be nicely reproducible. Thanks for that.
*Thread Reply:* Sure let me create an issue! Thanks!
*Thread Reply:* Created an issue here! https://github.com/OpenLineage/OpenLineage/issues/1919 Thanks! 🙇
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Paweł Leszczyński I just realised, https://github.com/OpenLineage/OpenLineage/pull/1823/files This PR doesn't actually capture column lineage for the MergeIntoCommand? It looks like there is no column lineage field in the events json.
*Thread Reply:* Hi @Paweł Leszczyński Is there a potential timeline in mind to support column lineage for the MergeIntoCommand? We're really excited for this feature and would be a huge help to overcome a current blocker. Thanks!
Thanks to everyone who came out to Wednesday night’s meetup in New York! In addition to great pizza from Grimaldi’s (thanks for the tip, @Harel Shein), we enjoyed a spirited discussion of: • the state of observability tooling in the data space today • the history and high-level architecture of the project courtesy of @Julien Le Dem • exciting news of an OpenLineage Scanner being planned at MANTA courtesy of @Ernie Ostic • updates on the project roadmap and some exciting proposals from @Julien Le Dem, @Harel Shein and @Willy Lulciuc • an introduction to and demo of Marquez from project lead @Willy Lulciuc • and more. Be on the lookout for an announcement about the next meetup!
As discussed during the April TSC meeting, comments are sought from the community on a proposal to support RunEvent-less (AKA static) lineage metadata emission. This is currently a WIP. For details and to comment, please see: • https://docs.google.com/document/d/1366bAPkk0OqKkNA4mFFt-41X0cFUQ6sOvhSWmh4Iydo/edit?usp=sharing • https://docs.google.com/document/d/1gKJw3ITJHArTlE-Iinb4PLkm88moORR0xW7I7hKZIQA/edit?usp=sharing
Hi all. Probably I just need to study the spec further, but what is the significance of _producer vs producer in the context of where they are used? (same question also for _schemaURL vs schemaURL)? Thx!
*Thread Reply:* “producer” is an element of the event run itself - e.g. what produced the JSON packet you’re studying. There is only one of these per event run. You can think of it as a top-level property.
“producer” (and “schemaURL”) are elements of a facet. They are the 2 required elements for any customized facet (though I don’t agree they should be required, or at least I believe they should be able to be compatible with a blank value and a null value).
A packet sent to an API should only have one “producer” element, but can have many _producer elements in sub-objects (though, only one _producer per facet).
*Thread Reply:* just curious --- is/was there any specific reason for the underscore prefix? If they are in a facet, they would already be qualified.......
*Thread Reply:* The facet “BaseFacet” that’s used for customization, has 2 required elements - _producer and _schemaURL. so I don’t believe it’s related to qualification.
I’m opening a vote to release OpenLineage 0.24.0, including:
• a new OpenLineage extractor for dbt Cloud
• a new interface - TransportBuilder - for creating custom transport types without modifying core components of OpenLineage
• a fix to the LogicalPlanSerializer in the Spark integration to make it operational again
• a new configuration parameter in the Spark integration for making dataset paths less verbose
• a fix to the Flink integration CI
• and more.
Three +1s from committers will authorize an immediate release.
*Thread Reply:* Thanks for voting. The release will commence within 2 days.
Does the Spark integration for OpenLineage also support ETL that uses the Apache Spark Structured Streaming framework?
*Thread Reply:* Although it is not documented, we do have an integration test for that: https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/test/resources/spark_scripts/spark_kafka.py
The test reads and writes data to Kafka and verifies if input/output datasets are collected.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Also, does it work for pyspark jobs? (Forgive me if Spark job = pyspark, I don’t have a lot of depth on how Spark works.
*Thread Reply:* From my experience, yeah it works for pyspark
(and in a less generic question, would it work on top of this Spline agent/lineage harvester, or is it a replacement for it?
*Thread Reply:* Also from my experience, I think we can only use one of them as we can only configure one spark listener... correct me if I'm wrong. But it seems like the latest releases of spline are already using openlineage to some capacity?
*Thread Reply:* In spark.extraListeners you can configure multiple listeners by comma separating them - I think you can use multiple ones with OpenLineage without obvious problems. I think we do pretty similar things to Spline though
*Thread Reply:* (I never said thank you for this, so, thank you!)
Hi Team,
I have configured Open lineage with databricks and it is sending events to Marquez as expected. I have a notebook which joins 3 tables and write the result data frame to an azure adls location. Each time I run the notebook manually, it creates two start events and two complete events for one run as shown in the screenshot. Is this something expected or I am missing something?
*Thread Reply:* Hello Sai, thanks for your question! A number of folks who could help with this are OOO, but someone will reply as soon as possible.
*Thread Reply:* That is interesting @Sai. Are you able to reproduce this with a simple code snippet? Which Openlineage version are you using?
*Thread Reply:* Yes @Paweł Leszczyński. Each join query I run on top of delta tables have two start and two complete events. We are using below jar for openlineage.
openlineage-spark-0.22.0.jar
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/1828
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Paweł Leszczyński any updates on this issue?
Also, OL is not giving column level lineage for group by operations on tables. Is this expected?
*Thread Reply:* Hi @Sai, https://github.com/OpenLineage/OpenLineage/pull/1830 should fix duplication issue
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* this would be part of next release?
*Thread Reply:* Regarding column lineage & group by issue, I think it's something on databricks side -> we do have an open issue for that #1821
*Thread Reply:* once #1830 is reviewed and merged, it will be the part of the next relase
*Thread Reply:* sure.. thanks @Paweł Leszczyński
*Thread Reply:* @Paweł Leszczyński I have used the latest jar (0.25.0) and still this issue persists. I see two events for same input/output lineage.

Has anyone used Open Lineage for application lineage? I'm particularly interested in how if/how you handled service boundaries like APIs and Kafka topics and what Dataset Naming (URI) you used.
*Thread Reply:* For example, MySQL is stored as producer + host + port + database + table as something like <mysql://db.foo.com:6543/metrics.orders>
For an API (especially one following REST conditions), I was thinking something like method + host + port + path or GET <https://api.service.com:433/v1/users>
*Thread Reply:* Hi Thomas, thanks for asking about this — it sounds cool! I don’t know of others working on this kind of thing, but I’ve been developing a SQLAlchemy integration and have been experimenting with job naming — which I realize isn’t exactly what you’re working on. Hopefully others will chime in here, but in the meantime, would you be willing to create an issue about this? It seems worth discussing how we could expand the spec for this kind of use case.
*Thread Reply:* I suspect this will definitely be a bigger discussion. Let me ponder on the problem a bit more and come back with something a bit more concrete.
*Thread Reply:* Looking forward to hearing more!
*Thread Reply:* On a tangential note, does OpenLineage's column level lineage have support for (I see it can be extended but want to know if someone had to map this before): • Properties as a path in a structure (like a JSON structure, Avro schema, protobuf, etc) maybe using something like JSON Path or XPath notation. • Fragments (when a column is a JSON blob, there is an entire sub-structure that needs to be described) • Transformation description (how an input affects an output. Is it a direct copy of the value or is it part of a formula)
*Thread Reply:* I don’t know, but I’ll ping some folks who might.
*Thread Reply:* Hi @Thomas. Column-lineage support currently does not include json fields. We have included in specification fields like transformationDescription and transformationType to store a string representation of the transformation applied and its type like IDENTITY|MASKED. However, those fields aren't filled within Spark integration at the moment.
@channel
We released OpenLineage 0.24.0, including:
Additions:
• Support custom transport types #1795 @nataliezeller1
• Airflow: dbt Cloud integration #1418 @howardyoo
• Spark: support dataset name modification using regex #1796 @pawel-big-lebowski
Plus bug fixes and more.
Thanks to all the contributors!
For the bug fixes and details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.24.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.23.0...0.24.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

@channel This month’s TSC meeting is next Thursday, May 11th, at 10:00 am PT. The tentative agenda will be on the wiki. More info and the meeting link can be found on the website. All are welcome! Also, feel free to reply or DM me with discussion topics, agenda items, etc.
Hello all, noticed that openlineage is not able to give column level lineage if there is a groupby operation on a spark dataframe. Has anyone else faced this issue and have any fixes or workarounds? Apache Spark 3.0.1 and Openlineage version 1 are being used. Also tried on Spark version 3.3.0
Log4j error details follow:
23/05/05 18:09:11 ERROR ColumnLevelLineageUtils: Error when invoking static method 'buildColumnLineageDatasetFacet' for Spark3 java.lang.reflect.InvocationTargetException at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at io.openlineage.spark.agent.lifecycle.plan.column.ColumnLevelLineageUtils.buildColumnLineageDatasetFacet(ColumnLevelLineageUtils.java:35) at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.lambda$buildOutputDatasets$21(OpenLineageRunEventBuilder.java:424) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1384) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:566) at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildOutputDatasets(OpenLineageRunEventBuilder.java:437) at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.populateRun(OpenLineageRunEventBuilder.java:296) at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildRun(OpenLineageRunEventBuilder.java:279) at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.buildRun(OpenLineageRunEventBuilder.java:222) at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:70) at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$sparkSQLExecStart$0(OpenLineageSparkListener.java:91) at java.util.Optional.ifPresent(Optional.java:159) at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:91) at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:82) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:102) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:39) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:39) at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:118) at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:102) at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:107) at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:107) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:102) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:98) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1639) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:98) Caused by: java.lang.NoSuchMethodError: org.apache.spark.sql.catalyst.expressions.aggregate.AggregateExpression.resultId()Lorg/apache/spark/sql/catalyst/expressions/ExprId; at io.openlineage.spark3.agent.lifecycle.plan.column.ExpressionDependencyCollector.traverseExpression(ExpressionDependencyCollector.java:79) at io.openlineage.spark3.agent.lifecycle.plan.column.ExpressionDependencyCollector.lambda$traverseExpression$4(ExpressionDependencyCollector.java:74) at java.util.Iterator.forEachRemaining(Iterator.java:116) at scala.collection.convert.Wrappers$IteratorWrapper.forEachRemaining(Wrappers.scala:31) at java.util.Spliterators$IteratorSpliterator.forEachRemaining(Spliterators.java:1801) at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647) at io.openlineage.spark3.agent.lifecycle.plan.column.ExpressionDependencyCollector.traverseExpression(ExpressionDependencyCollector.java:74) at io.openlineage.spark3.agent.lifecycle.plan.column.ExpressionDependencyCollector.lambda$null$2(ExpressionDependencyCollector.java:60) at java.util.LinkedList$LLSpliterator.forEachRemaining(LinkedList.java:1235) at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647) at io.openlineage.spark3.agent.lifecycle.plan.column.ExpressionDependencyCollector.lambda$collect$3(ExpressionDependencyCollector.java:60) at org.apache.spark.sql.catalyst.trees.TreeNode.foreach(TreeNode.scala:285) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$foreach$1(TreeNode.scala:286) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$foreach$1$adapted(TreeNode.scala:286) at scala.collection.Iterator.foreach(Iterator.scala:943) at scala.collection.Iterator.foreach$(Iterator.scala:943) at scala.collection.AbstractIterator.foreach(Iterator.scala:1431) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at org.apache.spark.sql.catalyst.trees.TreeNode.foreach(TreeNode.scala:286) at io.openlineage.spark3.agent.lifecycle.plan.column.ExpressionDependencyCollector.collect(ExpressionDependencyCollector.java:38) at io.openlineage.spark3.agent.lifecycle.plan.column.ColumnLevelLineageUtils.collectInputsAndExpressionDependencies(ColumnLevelLineageUtils.java:70) at io.openlineage.spark3.agent.lifecycle.plan.column.ColumnLevelLineageUtils.buildColumnLineageDatasetFacet(ColumnLevelLineageUtils.java:40) ... 36 more
*Thread Reply:* Hi @Harshini Devathi, I think this the same as issue: https://github.com/OpenLineage/OpenLineage/issues/1821
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you @Paweł Leszczyński. So, is this an issue with databricks. The issue thread says that it was able to work on AWS Glue. If so, is there some kind of solution to make it work on Databricks?
Hello all, is there a way to get lineage in azure synapse analytics with openlineage
*Thread Reply:* There are few possible issues:
- The column-level lineage is not implemented for particular part of Spark LogicalPlan
- Azure SQL or Databricks have their own implementations of some Spark class, which does not exactly match our extractor. We've seen that happen
- You're using SQL JDBC connection with
SELECT **- in which case we can't do anything for now, since we don't know the input columns. - Possibly something else 🙂 @Paweł Leszczyński might have an idea To fully understand the issue, we'd have to see logs, LogicalPlan of the Spark job, or the job code itself
*Thread Reply:* @Sai, providing a short code snippet that is able to reproduce this would be super helpful in examining that.
*Thread Reply:* sure Pawel Will share the code I used in sometime
*Thread Reply:* I tried with putting a sql query having column names in it, still the lineage didn't show up..
2023-05-09T13:37:48.526698281Z java.lang.ClassCastException: class org.apache.spark.scheduler.ShuffleMapStage cannot be cast to class java.lang.Boolean (org.apache.spark.scheduler.ShuffleMapStage is in unnamed module of loader 'app'; java.lang.Boolean is in module java.base of loader 'bootstrap')
2023-05-09T13:37:48.526703550Z at scala.runtime.BoxesRunTime.unboxToBoolean(BoxesRunTime.java:87)
2023_05_09T13:37:48.526707874Z at scala.collection.LinearSeqOptimized.forall(LinearSeqOptimized.scala:85)
2023_05_09T13:37:48.526712381Z at scala.collection.LinearSeqOptimized.forall$(LinearSeqOptimized.scala:82)
2023_05_09T13:37:48.526716848Z at scala.collection.immutable.List.forall(List.scala:91)
2023_05_09T13:37:48.526723183Z at io.openlineage.spark.agent.lifecycle.OpenLineageRunEventBuilder.registerJob(OpenLineageRunEventBuilder.java:181)
2023_05_09T13:37:48.526727604Z at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.setActiveJob(SparkSQLExecutionContext.java:152)
2023_05_09T13:37:48.526732292Z at java.base/java.util.Optional.ifPresent(Unknown Source)
2023-05-09T13:37:48.526736352Z at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$onJobStart$10(OpenLineageSparkListener.java:150)
2023_05_09T13:37:48.526740471Z at java.base/java.util.Optional.ifPresent(Unknown Source)
2023-05-09T13:37:48.526744887Z at io.openlineage.spark.agent.OpenLineageSparkListener.onJobStart(OpenLineageSparkListener.java:147)
2023_05_09T13:37:48.526750258Z at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:37)
2023_05_09T13:37:48.526753454Z at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
2023_05_09T13:37:48.526756235Z at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
2023_05_09T13:37:48.526759315Z at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
2023_05_09T13:37:48.526762133Z at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117)
2023_05_09T13:37:48.526764941Z at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101)
2023_05_09T13:37:48.526767739Z at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
2023_05_09T13:37:48.526776059Z at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
2023_05_09T13:37:48.526778937Z at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
2023_05_09T13:37:48.526781728Z at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
2023_05_09T13:37:48.526786986Z at <a href="http://org.apache.spark.scheduler.AsyncEventQueue.org">org.apache.spark.scheduler.AsyncEventQueue.org</a>$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
2023_05_09T13:37:48.526789893Z at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
2023_05_09T13:37:48.526792722Z at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1446)
2023_05_09T13:37:48.526795463Z at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
Hi, noticing this error message from OL... anyone know why its happening?
*Thread Reply:* @Anirudh Shrinivason what's your OL and Spark version?
*Thread Reply:* Some example job would also help, or logs/LogicalPlan 🙂
*Thread Reply:* OL version is 0.23.0 and spark version is 3.3.1
*Thread Reply:* Hmm actually, it seems like the error is intermittent actually. I ran the same job again, but did not notice any errors this time...
*Thread Reply:* This is interesting and it happens within a line:
job.finalStage().parents().forall(toScalaFn(stage -> stageMap.put(stage.id(), stage)));
The result of stageMap.put is Stage and for some reason which I don't undestand it tries doing unboxToBoolean . We could rewrite that to:
job.finalStage().parents().forall(toScalaFn(stage -> {
stageMap.put(stage.id(), stage)
return true;
}));
but this is so weird that it is intermittent and I don't get why is it happening.
*Thread Reply:* @Anirudh Shrinivason, please let us know if it is still a valid issue. If so, we can create an issue for that.
*Thread Reply:* Hi @Paweł Leszczyński Sflr. Yeah, I think if we are able to fix this, it'll be better. If this is the dedicated fix, then I can create an issue and raise an MR.
*Thread Reply:* Opened an issue and PR. Do help check if its okay thanks!
*Thread Reply:* please run ./gradlew spotlessApply with Java 8

Hi all, I’m new to openlineage (and marquez) so I’m trying to figure out if it could be the right option form a client usecase in which: • a legacy custom data catalog (mongo backend + Java API backend for fronted in angular) • AS-IS component lineage realations are retrieve in a custom way from the each component’s APIs • the customer would like to bring in a basic data lineage feature based on already published metadata that represent custom workloads type (batch,streaming,interactive ones) + data access pattern (no direct relation with the datasources right now but only a abstraction layer upon them) I’d like to exploit directly Marquez as the metastore to publish metadata about datasource, workload (the workload is the declaration + business logic code deployed into the customer platform) once the component is deployed (e.g. the service that exposes the specific access pattern, or the workload custom declaration), but I saw the openlinage spec is based on strictly coupling between run,job and datasource; I mean I want to be able to publish one item at a time and then (maybe in a future release of the customer product) be able to exploit runtime lineage also
Am I in the right place? Thanks anyway :)
*Thread Reply:* > I mean I want to be able to publish one item at a time and then (maybe in a future release of the customer product) be able to exploit runtime lineage also This is not something that we support yet - there are definitely a lot of plans and preliminary work for that.
*Thread Reply:* Thanks for the response, btw I already took a look at the current capabilities provided by openlineage, so my “hidden” question is how do achieve what the customer want to in order to be integrated in some way with openalineage+marquez? should I choose between make or buy (between already supported platforms) and then try to align “static” (aka declarative) lineage metadata within the openlinage conceptual model?
@channel This month’s TSC meeting is tomorrow at 10am PT. All are welcome! https://openlineage.slack.com/archives/C01CK9T7HKR/p1683213923529529
Does anyone here have experience with vendors in this space like Atlan or Manta? I’m advocating pretty heavily for OpenLineage at my company and have a strong suspicion that the LoE of enabling an equivalent solution from a vendor is equal or greater than that of OL/Marquez. Curious if anyone has first-hand experience with these tools they might be willing to share?
*Thread Reply:* Hi John. Great question! [full disclosure, I am with Manta 🙂 ]. I'll let others answer as to their experience with ourselves or many other vendors that provide lineage, but want to mention that a variety of our customers are finding it beneficial to bring code based static lineage together with the event-based runtime lineage that OpenLineage provides. This gives them the best of both worlds, for analyzing the lineage of their existing systems, where rich parsers already exist (for everything from legacy ETL tools, reporting tools, rdbms, etc.), to newer or home-grown technologies where applying OpenLineage is a viable alternative.
*Thread Reply:* @Ernie Ostic do you see a single front-runner in the static lineage space? The static/event-based situation you describe is exactly the product roadmap I'm seeing here at Fivetran and I'm wondering if there's an opportunity to drive consensus towards a best-practice solution. If I'm not mistaken weren't there plans to start supporting non-run-based events in OL as well?
*Thread Reply:* I definitely like the idea of a 3rd party solution being complementary to OSS tools we can maintain ourselves while allowing us to offload maintenance effort where possible. Currently I have strong opinions on both sides of the build vs. buy aisle and this seems like the best of both worlds.
*Thread Reply:* @Brad Paskewitz that’s 100% our plan to extend the OL spec to support “run-less” events. We want to collect that static metadata for Datasets and Jobs outside of the context of a run through OpenLineage. happy to get your feedback here as well: https://github.com/OpenLineage/OpenLineage/pull/1839

*Thread Reply:* Hi @John Lukenoff. Here at Atlan we've been working with the OpenLineage community for quite some time to unlock the use case you describe. These efforts are adjacent to our ongoing integration with Fivetran. Happy to connect and give you a demo of what we've built and dig into your use case specifics.
*Thread Reply:* Thanks all! These comments are really informative, it’s exciting to hear about vendors leaning into the project to let us continue to benefit from the tremendous progress being made by the community. Had a great discussion with Atlan yesterday and plan to connect with Manta next week to discuss our use-cases.
*Thread Reply:* Reach out anytime, John. @John Lukenoff Looking forward to engaging further with you on these topics!
Hello all, I would like to have a new release of Openlineage as the new code base seems to have some issues fixed. I need these fixes for my project.
*Thread Reply:* Thank you for requesting an OpenLineage release. As stated here, three +1s from committers will authorize an immediate release. Our policy is not to release on Fridays, so the earliest we could initiate would be Monday.
*Thread Reply:* A release on Monday is totally fine @Michael Robinson.
*Thread Reply:* The release will be initiated today. Thanks @Harshini Devathi
*Thread Reply:* Appreciate it @Michael Robinson and thanks to all the committers for the prompt response
@channel
We released OpenLineage 0.25.0, including:
Additions:
• Spark: merge into query support #1823 @pawel-big-lebowski
Fixes:
• Spark: fix JDBC query handling #1808 @nataliezeller1
• Spark: filter Delta adaptive plan events #1830 @pawel-big-lebowski
• Spark: fix Java class cast exception #1844 @Anirudh181001
• Flink: include missing fields of Openlineage events #1840 @pawel-big-lebowski
Plus doc changes and more.
Thanks to all the contributors!
For the details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.25.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.24.0...0.25.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
@channel If you’re planning on being in San Francisco at the end of June — perhaps for this year’s Data+AI Summit — please stop by Astronomer’s offices on California Street on 6/27 for the first SF OpenLineage Meetup. We’ll be discussing spec changes planned for OpenLineage v1.0.0, progress on Airflow AIP 53, and more. Plus, dinner will be provided! For more info and to sign up, check out the OL blog. Join us!
Hi, I've been noticing this error that is intermittently popping up in some of the spark jobs:
AsyncEventQueue: Dropping event from queue appStatus. This likely means one of the listeners is too slow and cannot keep up with the rate at which tasks are being started by the scheduler.
spark.scheduler.listenerbus.eventqueue.size Increasing this spark config did not help either.
Any ideas on how to mitigate this issue? Seeing this in spark 3.1.2 btw
*Thread Reply:* Hi @Anirudh Shrinivason, are you able to send the OL events to console. This would let us confirm if the issue is related with event generation or emitting it and waiting for the backend to repond.
*Thread Reply:* Ahh okay sure. Let me see if I can do that
Hi Team
We are seeing an issue with OL configured cluster where delta table merge is failing with below error. It is running fine when we run with other clusters where OL is not configured. I ran it multiple times assuming its intermittent issue with memory, but it keeps on failing with same error. Attached the code for reference. We are using the latest release (0.25.0)
org.apache.spark.SparkException: Job aborted due to stage failure: Task serialization failed: java.lang.StackOverflowError
@Paweł Leszczyński @Michael Robinson
*Thread Reply:* Hi @Paweł Leszczyński
Thanks for fixing the issue and with new release merge is working. But I could not see any input and output datasets for this. Let me know if you need any further details to look into this.
},
"job": {
"namespace": "openlineage_poc",
"name": "spark_ol_integration_execute_merge_into_command_edge",
"facets": {}
},
"inputs": [],
"outputs": [],
*Thread Reply:* Oh man, it's just that vanilla spark differs from the one available in databricks platform. our integration tests do verify behaviour on vanilla spark which still leaves a possibility for inconsistency. will need to get back to it then at some time.
*Thread Reply:* Hi @Paweł Leszczyński
Did you get chance to look into this issue?
*Thread Reply:* Hi Sai, I am going back to spark. I am working on support for Spark 3.4, which is going to add some event filtering on internal delta operations that trigger unncecessarly the events
*Thread Reply:* this may be releated to issue you created
*Thread Reply:* I do have planned creating integration test for databricks which will be helpful to tackle the issues you raised
*Thread Reply:* so yes, I am looking at the Spark
*Thread Reply:* thanks much Pawel.. I am looking more into the merge part as first priority as we use is frequently.
*Thread Reply:* I know, this is important.
*Thread Reply:* It just need still some time.
*Thread Reply:* thank you for your patience and being so proactive on those issues.
*Thread Reply:* no problem.. Please do keep us posted with updates..
Our recent Openlineage release (0.25.0) proved there are many users that use Openlineage on databricks, which is incredible. I am super happy to know that, although we realised that as a side effect of a bug. Sorry for that.
I would like to opt for a new release which contains PR #1858 and should unblock databricks users.
*Thread Reply:* The release request has been approved and will be initiated shortly.
Actually, I noticed a few other stack overflow errors on 0.25.0. Let me raise an issue. Could we cut a release once this bug are fixed too please?
*Thread Reply:* Hi Anirudh, I saw your issue and I think it is the same one as solved within #1858. Are you able to reproduce it on a version built on the top of main?
*Thread Reply:* Hi I haven't managed to try with the main branch. But if its the same error then all's good! If the error resurfaces then we can look into it.

Hi All,
We are in POC phase OpenLineage integration with our core DBT, can anyone help me with document to start with.
*Thread Reply:* I know this one: https://openlineage.io/docs/integrations/dbt
*Thread Reply:* Hi @Paweł Leszczyński Thanks for the revert, I tried same but facing below issue
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=5000): Max retries exceeded with url:
Looks like I need to start the service
*Thread Reply:* @Lovenish Goyal, exactly. You need to start Marquez. More about it: https://marquezproject.ai/quickstart
*Thread Reply:* @Lovenish Goyal how are you running dbt core currently?
*Thread Reply:* Trying but facing issue while running marquezproject @Jakub Dardziński
*Thread Reply:* @Harel Shein we have created custom docker image of DBT + Airflow and running it on an EC2
*Thread Reply:* for running dbt core on Airflow, we have a utility that helps develop dbt natively on Airflow. There’s also built in support for collecting lineage if you have the airflow-openlineage provider installed. https://astronomer.github.io/astronomer-cosmos/#quickstart
*Thread Reply:* RE issues running Marquez, can you share what those are? I’m guessing that since you are running both of them in individual docker images, the airflow deployment might not be able to communicate with the Marquez endpoints?
*Thread Reply:* @Harel Shein I've already helped with running Marquez 🙂

@Paweł Leszczyński We are facing the following issue with Azure databricks. When we use aggregate functions in databricks notebooks, Open lineage is not able to provide column level lineage. I understand its an existing issue. Can you please let me know in which release this issue will be fixed ? It is one of the most needed feature for us to implement openlineage in our current project. Kindly let me know
*Thread Reply:* I am not sure if this is the same. If you see OL events collected with column-lineage missing, then it's a different one.
*Thread Reply:* Please also be aware, that it is extremely helpful to investigate the issues on your own before creating them.
Our integration traverses spark's logical plans and extracts lineage events from plan nodes that it understands. Some plan nodes are not supported yet and, from my experience, when working on an issue, 80% of time is spent on reproducing the scenario.
So, if you are able to produce a minimal amount of spark code that reproduces an issue, this can be extremely helpful and significantly speed up resolution time.
*Thread Reply:* @Paweł Leszczyński Thanks for the prompt response.
Provided sample codes with and without using aggregate functions and its respective lineage events for reference.
Please find the code without using aggregate function: finaldf=spark.sql(""" select productid ,OrderQty as TotalOrderQty ,ReceivedQty as TotalReceivedQty ,StockedQty as TotalStockedQty ,RejectedQty as TotalRejectedQty from openlineagepoc.purchaseorder --group by productid order by productid""")
final_df.write.mode("overwrite").saveAsTable("openlineage_poc.productordertest1")
Please find the Openlineage Events for the Input, Ouput datasets. We could find the column lineage in this.
"inputs": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "facets": { "dataSource": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet", "name": "dbfs", "uri": "dbfs" }, "schema": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet", "fields": [ { "name": "PurchaseOrderID", "type": "integer" }, { "name": "PurchaseOrderDetailID", "type": "integer" }, { "name": "DueDate", "type": "timestamp" }, { "name": "OrderQty", "type": "short" }, { "name": "ProductID", "type": "integer" }, { "name": "UnitPrice", "type": "decimal(19,4)" }, { "name": "LineTotal", "type": "decimal(19,4)" }, { "name": "ReceivedQty", "type": "decimal(8,2)" }, { "name": "RejectedQty", "type": "decimal(8,2)" }, { "name": "StockedQty", "type": "decimal(9,2)" }, { "name": "RevisionNumber", "type": "integer" }, { "name": "Status", "type": "integer" }, { "name": "EmployeeID", "type": "integer" }, { "name": "NationalIDNumber", "type": "string" }, { "name": "JobTitle", "type": "string" }, { "name": "Gender", "type": "string" }, { "name": "MaritalStatus", "type": "string" }, { "name": "VendorID", "type": "integer" }, { "name": "ShipMethodID", "type": "integer" }, { "name": "ShipMethodName", "type": "string" }, { "name": "ShipMethodrowguid", "type": "string" }, { "name": "OrderDate", "type": "timestamp" }, { "name": "ShipDate", "type": "timestamp" }, { "name": "SubTotal", "type": "decimal(19,4)" }, { "name": "TaxAmt", "type": "decimal(19,4)" }, { "name": "Freight", "type": "decimal(19,4)" }, { "name": "TotalDue", "type": "decimal(19,4)" } ] }, "symlinks": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers": [ { "namespace": "/mnt/dlzones/warehouse/openlineagepoc/gold", "name": "openlineagepoc.purchaseorder", "type": "TABLE" } ] } }, "inputFacets": {} } ], "outputs": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/productordertest1", "facets": { "dataSource": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet", "name": "dbfs", "uri": "dbfs" }, "schema": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet", "fields": [ { "name": "productid", "type": "integer" }, { "name": "TotalOrderQty", "type": "short" }, { "name": "TotalReceivedQty", "type": "decimal(8,2)" }, { "name": "TotalStockedQty", "type": "decimal(9,2)" }, { "name": "TotalRejectedQty", "type": "decimal(8,2)" } ] }, "storage": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/StorageDatasetFacet.json#/$defs/StorageDatasetFacet", "storageLayer": "unity", "fileFormat": "parquet" }, "columnLineage": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-1/ColumnLineageDatasetFacet.json#/$defs/ColumnLineageDatasetFacet", "fields": { "productid": { "inputFields": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "field": "ProductID" } ] }, "TotalOrderQty": { "inputFields": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "field": "OrderQty" } ] }, "TotalReceivedQty": { "inputFields": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "field": "ReceivedQty" } ] }, "TotalStockedQty": { "inputFields": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "field": "StockedQty" } ] }, "TotalRejectedQty": { "inputFields": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "field": "RejectedQty" } ] } } }, "symlinks": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers": [ { "namespace": "/mnt/dlzones/warehouse/openlineagepoc", "name": "openlineagepoc.productordertest1", "type": "TABLE" } ] }, "lifecycleStateChange": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "_schemaURL": "https://openlineage.io/spec/facets/1-0-0/LifecycleStateChangeDatasetFacet.json#/$defs/LifecycleStateChangeDatasetFacet", "lifecycleStateChange": "OVERWRITE" } }, "outputFacets": {} } ]
*Thread Reply:* 2. Please find the code using aggregate function:
final_df=spark.sql("""
select productid
,sum(OrderQty) as TotalOrderQty
,sum(ReceivedQty) as TotalReceivedQty
,sum(StockedQty) as TotalStockedQty
,sum(RejectedQty) as TotalRejectedQty
from openlineage_poc.purchaseorder
group by productid
order by productid""")
final_df.write.mode("overwrite").saveAsTable("openlineage_poc.productordertest2")
Please find the Openlineage Events for the Input, Ouput datasets. We couldnt find the column lineage in output section. Please find the sample
"inputs": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/gold/purchaseorder", "facets": { "dataSource": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet", "name": "dbfs", "uri": "dbfs" }, "schema": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet", "fields": [ { "name": "PurchaseOrderID", "type": "integer" }, { "name": "PurchaseOrderDetailID", "type": "integer" }, { "name": "DueDate", "type": "timestamp" }, { "name": "OrderQty", "type": "short" }, { "name": "ProductID", "type": "integer" }, { "name": "UnitPrice", "type": "decimal(19,4)" }, { "name": "LineTotal", "type": "decimal(19,4)" }, { "name": "ReceivedQty", "type": "decimal(8,2)" }, { "name": "RejectedQty", "type": "decimal(8,2)" }, { "name": "StockedQty", "type": "decimal(9,2)" }, { "name": "RevisionNumber", "type": "integer" }, { "name": "Status", "type": "integer" }, { "name": "EmployeeID", "type": "integer" }, { "name": "NationalIDNumber", "type": "string" }, { "name": "JobTitle", "type": "string" }, { "name": "Gender", "type": "string" }, { "name": "MaritalStatus", "type": "string" }, { "name": "VendorID", "type": "integer" }, { "name": "ShipMethodID", "type": "integer" }, { "name": "ShipMethodName", "type": "string" }, { "name": "ShipMethodrowguid", "type": "string" }, { "name": "OrderDate", "type": "timestamp" }, { "name": "ShipDate", "type": "timestamp" }, { "name": "SubTotal", "type": "decimal(19,4)" }, { "name": "TaxAmt", "type": "decimal(19,4)" }, { "name": "Freight", "type": "decimal(19,4)" }, { "name": "TotalDue", "type": "decimal(19,4)" } ] }, "symlinks": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers": [ { "namespace": "/mnt/dlzones/warehouse/openlineagepoc/gold", "name": "openlineagepoc.purchaseorder", "type": "TABLE" } ] } }, "inputFacets": {} } ], "outputs": [ { "namespace": "dbfs", "name": "/mnt/dlzones/warehouse/openlineagepoc/productordertest2", "facets": { "dataSource": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet", "name": "dbfs", "uri": "dbfs" }, "schema": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet", "fields": [ { "name": "productid", "type": "integer" }, { "name": "TotalOrderQty", "type": "long" }, { "name": "TotalReceivedQty", "type": "decimal(18,2)" }, { "name": "TotalStockedQty", "type": "decimal(19,2)" }, { "name": "TotalRejectedQty", "type": "decimal(18,2)" } ] }, "storage": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/StorageDatasetFacet.json#/$defs/StorageDatasetFacet", "storageLayer": "unity", "fileFormat": "parquet" }, "symlinks": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet", "identifiers": [ { "namespace": "/mnt/dlzones/warehouse/openlineagepoc", "name": "openlineagepoc.productordertest2", "type": "TABLE" } ] }, "lifecycleStateChange": { "producer": "https://github.com/OpenLineage/OpenLineage/tree/0.25.0/integration/spark", "schemaURL": "https://openlineage.io/spec/facets/1-0-0/LifecycleStateChangeDatasetFacet.json#/$defs/LifecycleStateChangeDatasetFacet", "lifecycleStateChange": "OVERWRITE" } }, "outputFacets": {} } ]
*Thread Reply:* amazing. https://github.com/OpenLineage/OpenLineage/issues/1861
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks for considering the request and looking into it
@channel
We released OpenLineage 0.26.0, including:
Additions:
• Proxy: Fluentd proxy support (experimental) #1757 @pawel-big-lebowski
Changes:
• Python client: use Hatchling over setuptools to orchestrate Python env setup #1856 @gaborbernat
Fixes:
• Spark: fix logicalPlan serialization issue on Databricks #1858 @pawel-big-lebowski
Plus an additional fix, doc changes and more.
Thanks to all the contributors, including new contributor @gaborbernat!
For the details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.26.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.25.0...0.26.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Hi Team , can someone please address https://github.com/OpenLineage/OpenLineage/issues/1866.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Bramha Aelem I replied in the ticket. Thank you for opening it.
*Thread Reply:* Hi @Julien Le Dem - Thanks for quick response. I replied in the ticket. Please let me know if you need any more details.
*Thread Reply:* Hi @Bramha Aelem - asked for more details in the ticket.
*Thread Reply:* Hi @Paweł Leszczyński - I replied with necessary details in the ticket. Please let me know if you need any more details.
*Thread Reply:* Hi @Paweł Leszczyński - any further updates on issue?
*Thread Reply:* hi @Bramha Aelem, i was out of office for a few days. will get back into this soon. thanks for update.
*Thread Reply:* Hi @Paweł Leszczyński -Thanks for your reply. will wait for your response to proceed further on the issue.
*Thread Reply:* Hi @Paweł Leszczyński -Hope you are doing well. Did you get a chance to look into the samples which are provided in the ticket. Kindly let me know your observations/recommendations.
*Thread Reply:* Hi @Paweł Leszczyński - Hope you are doing well. Did you get a chance to look into the samples which are provided in the ticket. Kindly let me know your observations/recommendations.
*Thread Reply:* Hi @Paweł Leszczyński - Good day. Did you get a chance to look into query which I have posted. can you please provide any thoughts on my observation/query.
Hello Everyone, I was trying to integrate openlineage with Jupyter Notebooks, I followed the docs but when I run the sample notebook I am getting an error
23/05/19 07:39:08 ERROR EventEmitter: Could not emit lineage w/ exception
Can someone Please help understand why am I getting this error and the resolution.
*Thread Reply:* Hello @John Doe, this mostly means there's somehting wrong with your transport config for emitting Openlineage events.
*Thread Reply:* what do you want to do with the events?
*Thread Reply:* Hi @Paweł Leszczyński, I am working on a PoC to understand the use cases of OL and how it build Lineages.
As for the transport config I am using the codes from the documentation to setup OL. https://openlineage.io/docs/integrations/spark/quickstart_local
Apart from these I dont have anything else in my nb
*Thread Reply:* ok, I am wondering if what you experience isn't similar to issue #1860. Could you try openlineage 0.23.0 to see if get the same error?
<https://github.com/OpenLineage/OpenLineage/issues/1860>
*Thread Reply:* I tried with 0.23.0 still getting the same error
*Thread Reply:* @Paweł Leszczyński any other way I can try to setup. The issue still persists
*Thread Reply:* hmyy, I've just redone steps from https://openlineage.io/docs/integrations/spark/quickstart_local with 0.26.0 and could not reproduce behaviour you encountered.
Hello Team!!! A part of my master thesis's case study was about data lineage in data mesh and how open-source initiatives such as OpenLineage and Marquez can realize this. Can you recommend me some material that can support the writing part of my thesis (more context: I tried to extract lineage events from Snowflake through Airlfow and used Docker Compose on EC2 to connect Airflow and the Marquez webserver)? We will divide the thesis into a few academic papers to make the content more digestible and publish one of them soon hopefully!
*Thread Reply:* Tom, thanks for your question. This is really exciting! I assume you’ve already started checking out the docs, but there are many other resources on the website, as well (on the blog and resources pages in particular). And don’t skip the YouTube channel, where we’ve recently started to upload short, more digestible excerpts from the community meetings. Please keep us updated as you make progress!
*Thread Reply:* Hi Michael! Thank you so much for sending these resources! I've been working on this thesis for quite some time already and it's almost finished. I just needed some additional information to help in accurately describing some of the processes in OpenLineage and Marquez. Will send you the case study chapter later this week to get some feedback if possible. Keep you posted on things such as publication! Perhaps it can make OpenLineage even more popular than it already is 😉
*Thread Reply:* Yes, please share it! Looking forward to checking it out. Super cool!
Hi Tom. Good luck. Sounds like a great case study. You might want to compare and contrast various kinds of lineage solutions....all of which complement each other, as well as having their own pros and cons. (...code based lineage via parsing, data similarity lineage, run-time lineage reporting, etc.) ...and then focus on open source and OpenLineage with Marquez in particular.
*Thread Reply:* Thank you so much Ernie! That sounds like a very interesting direction to keep in mind during research!
@channel For an easily digestible recap of recent events, communications and releases in the community, please sign up for our new monthly newsletter! Look for it in your inbox soon.

looking here https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.json#L64 it show that the schemaURL must be set, but then the examples in https://openlineage.io/getting-started#step-1-start-a-run do not contain it, is this a bug, expected? 😄
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* yeah, it's a bug
*Thread Reply:* so it's optional then? 😄 or bug in the example?
I noticed that DataQualityAssertionsDatasetFacet inherits from InputDatasetFacet, https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/DataQualityAssertionsDatasetFacet.json though I think should do from DatasetFacet like all else 🤔
@channel Two years ago last Saturday, we released the first version of OpenLineage, a test release of the Python client. So it seemed like an appropriate time to share our first annual ecosystem survey, which is both a milestone in the project’s growth and an important effort to set our course. This survey has been designed to help us learn more about who is using OpenLineage, what your lineage needs are, and what new tools you hope the project will support. Thank you in advance for taking the time to share your opinions and vision for the project! (Please note: the survey might seem longer than it actually is due to the large number of optional questions. Not all questions apply to all use cases.)

Open Lineage Spark Integration our spark workloads on Spark 2.4 are correctly setting .config("spark.sql.catalogImplementation", "hive") however sql queries for CREATE/INSERT INTO dont recoognize the datasets as “Hive”. As per https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/supported-commands.md USING HIVE is needed for appropriate parsing. Why is that the case ? Why cant HQL format for CREATE/INSERT be supported?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Michael Collado wondering if you could shed some light here
*Thread Reply:* can you show logical plan of your Spark job? I think using hive is not the most important part, but whether job's LogicalPlan parses to CreateHiveTableAsSelectCommand or InsertIntoHiveTable
*Thread Reply:* It parses into InsertIntoHadoopFsRelationCommand. example
== Optimized Logical Plan ==
InsertIntoHadoopFsRelationCommand <s3a://uchmsdev03/default/sharanyaOutputTable>, false, [id#89], Parquet, [serialization.format=1, mergeSchema=false, partitionOverwriteMode=dynamic], Append, CatalogTable(
Database: default
Table: sharanyaoutputtable
Owner: 2700940971
Created Time: Thu Jun 09 11:13:35 PDT 2022
Last Access: UNKNOWN
Created By: Spark 3.2.0
Type: EXTERNAL
Provider: hive
Table Properties: [transient_lastDdlTime=1654798415]
Location: <s3a://uchmsdev03/default/sharanyaOutputTable>
Serde Library: org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe
InputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
Storage Properties: [serialization.format=1]
Partition Provider: Catalog
Partition Columns: [`id`]
Schema: root
|-- displayName: string (nullable = true)
|-- serialnum: string (nullable = true)
|-- osversion: string (nullable = true)
|-- productfamily: string (nullable = true)
|-- productmodel: string (nullable = true)
|-- id: string (nullable = true)
), org.apache.spark.sql.execution.datasources.CatalogFileIndex@5fe23214, [displayName, serialnum, osversion, productfamily, productmodel, id]
+- Union false, false
:- Relation default.tablea[displayName#84,serialnum#85,osversion#86,productfamily#87,productmodel#88,id#89] parquet
+- Relation default.tableb[displayName#90,serialnum#91,osversion#92,productfamily#93,productmodel#94,id#95] parquet
*Thread Reply:* using spark 3.2 & this is the query
spark.sql(s"INSERT INTO default.sharanyaOutput select ** from (SELECT ** from default.tableA union all " +
s"select ** from default.tableB)")

Is there any example of how sourceCodeLocation / git info can be used from a spark job? What do we need to set to be able to see that as part of metadata?
*Thread Reply:* I think we can't really get it from Spark context, as Spark jobs are submitted in compiled, jar form, instead of plain text like for example Airflow dags.
*Thread Reply:* How about Jupyter Notebook based spark job?
*Thread Reply:* I don't think it changes much - but maybe @Paweł Leszczyński knows more
@channel Deprecation notice: support for Airflow 2.1 will end in about two weeks, when it will be removed from testing. The exact date will be announced as we get closer to it — this is just a heads up. After that date, use 2.1 at your own risk! (Note: the next release, 0.27.0, will still support 2.1.)
For the OpenLineageSparkListener, is there a way to configure it to send packets locally, e.g. save to a file? (instead of pushing to a URL destination)

*Thread Reply:* We developed a FileTransport class in order to save locally in json file our metrics if you interested in
*Thread Reply:* Does it also save the openlineage information, e.g. inputs/outputs?
*Thread Reply:* yes it save all json information, inputs / ouputs included
*Thread Reply:* Yes! then I am very interested. Is there guidance on how to use the FileTransport class?
*Thread Reply:* @alexandre bergere it would be pretty useful contribution if you can submit it 🙂
*Thread Reply:* We are using it on a transformed OpenLineage library we developed ! I'm going to make a PR in order to share it with you :)
*Thread Reply:* would be great to have. I had it in mind to implement as an enabler for databricks integration tests. great to hear that!
*Thread Reply:* PR sent: https://github.com/OpenLineage/OpenLineage/pull/1891 🙂 @Maciej Obuchowski could you tell me how to update the documentation once approved please?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @alexandre bergere we have separate repo for website + docs: https://github.com/OpenLineage/docs
Hi Team- When we run databricks job, lot of dbfs path namespaces are getting created. Can someone please let us know how to overwrite the symlink namespaces and link with the spark app name or openlineage namespace marquez UI.
Hello,
I am looking to connect the common data model in postgres marquez database and Azure Purview (which uses Apache Atlas API's) lineage endpoint. Does anyone have any how-to on this or can point me to some useful links for this?
Thanks in advance.
*Thread Reply:* I wonder if this blog post might help? https://openlineage.io/blog/openlineage-microsoft-purview
*Thread Reply:* This might not fully match your use case, either, but might help: https://learn.microsoft.com/en-us/samples/microsoft/purview-adb-lineage-solution-accelerator/azure-databricks-to-purview-lineage-connector/
*Thread Reply:* Thanks @Michael Robinson
Are there any constraints on facets? Such as is reasonable to expect that a single job will have a single parent? The schema hints to this by making the parent a single entry; but then one can send different parents for the START and COMPLETE event? 🤔
*Thread Reply:* I think, for now such thing is not defined other than by implementation of consumers.
*Thread Reply:* The idea is that for particular run, facets can be attached to any event type.
This has advantages, for example, job that modifies dataset that it's also reading from, can get particular version of dataset it's reading from and attach it on start; it would not work if you tried to do it on complete as the dataset would change by then.
Similarly, if the job is creating dataset, we could not get additional metadata on it, so we can attach those information only on complete.
There are also cases where we want facets to be cumulative. The reason for this are streaming jobs. For example, with Apache Flink, we could emit metadata on each checkpoint (or every N checkpoints) that contain metadata that show us how the job is progressing.
Generally consumers should be agnostic for that, but we don't want to overspecify what consumers should do - as people might want to use OL data in different ways, or even ignore some data we're sending.
Any reason why the lifecycle state change facet is not just on the output? But is also allowed on the inputs? 🤔 https://openlineage.io/docs/spec/facets/dataset-facets/lifecycle_state_change I can't see how would it be interpreted for an input 🤔
*Thread Reply:* I think it should be output-only, yes.
*Thread Reply:* @Paweł Leszczyński what do you think?
*Thread Reply:* yes, should be output only I think
*Thread Reply:* should we move it over then? 😄
*Thread Reply:* under Output Dataset Facets that is
@channel The first issue of OpenLineage News is now available. To get it directly in your inbox when it’s published, become a subscriber.
*Thread Reply:* Correction: Julien and Willy’s talk at Data+AI Summit will take place on June 28
Hello all, I’m opening a vote to release 0.27.0, featuring:
• Spark: fixed column lineage from databricks in the case of aggregate queries
• Python client: configurable job-name filtering
• Airflow: fixed urllib.parse.urlparse in case of [] values
Three +1s from committers will authorize an immediate release.
*Thread Reply:* Thanks, all. The release is authorized and will be initiated on Monday in accordance with our policy here.
@channel This month’s TSC meeting is next Thursday, June 8th, at 10:00 am PT. On the tentative agenda: announcements, meetup updates, recent releases, static lineage progress, and open discussion. More info and the meeting link can be found on the website. All are welcome! Also, feel free to reply or DM me with discussion topics, agenda items, etc.
@channel
We released OpenLineage 0.27.1, including:
Additions:
• Python client: add emission filtering mechanism and exact, regex filters #1878 @mobuchowski
Fixes:
• Spark: fix column lineage for aggregate queries on databricks #1867 @pawel-big-lebowski
• Airflow: fix unquoted [ and ] in Snowflake URIs #1883 @JDarDagran
Plus a CI fix and a proposal.
For the details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.27.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.26.0...0.27.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Looking for a reviewer under: https://github.com/OpenLineage/OpenLineage/pull/1892 🙂
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Bernat Gabor thanks for the PR!
Hey, I request release 0.27.2 to fix potential breaking change in Python client in 0.27.1: https://github.com/OpenLineage/OpenLineage/pull/1908
*Thread Reply:* Thanks @Maciej Obuchowski. The release is authorized and will be initiated as soon as possible.
@channel
We released OpenLineage 0.27.2, including:
Fixes:
• Python client: deprecate client.from_environment, do not skip loading config #1908 @Maciej Obuchowski
For the details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.27.2
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.27.1...0.27.2
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
Found a major bug in the python client - https://github.com/OpenLineage/OpenLineage/pull/1917, if someone can review
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
And also https://github.com/OpenLineage/OpenLineage/pull/1913 🙂 that fixes the type information not being packaged
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
@channel This month’s TSC meeting is tomorrow, and all are welcome! https://openlineage.slack.com/archives/C01CK9T7HKR/p1685725998982879

Hi team,
I wanted a lineage of my data for my tables and column level. I am using jupyter notebook and spark code.
spark = (SparkSession.builder.master('local') .appName('samplespark') .config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener') .config('spark.jars.packages', 'io.openlineage:openlineagespark:0.12.0') .config('spark.openlineage.host', 'http://marquez-api:5000') .config('spark.openlineage.namespace', 'spark_integration') .getOrCreate())
I used this and then opened the localhost:3000 for marquez
I can see my job there but when i click on the job when its supposed to show lineage, its just an empty screen
*Thread Reply:* Do you get any output in your devtools? I just ran into this yesterday and it looks like it’s related to this issue: https://github.com/MarquezProject/marquez/issues/2410
 <a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Seems like more of a Marquez client-side issue than something with OL
*Thread Reply:* Sorry I mean in the dev console of your web browser
*Thread Reply:* Seems like it’s coming from this line. Are there any job facets defined when you fetch from the API directly? That seems like kind of an old version of OL so maybe the schema is incompatible with the version Marquez is expecting
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* from pyspark.sql import SparkSession
spark = (SparkSession.builder.master('local')
.appName('sample_spark')
.config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener')
.config('spark.jars.packages', 'io.openlineage:openlineage_spark:0.12.0')
.config('spark.openlineage.host', '<http://marquez-api:5000>')
.config('spark.openlineage.namespace', 'spark_integration')
.getOrCreate())
spark.sparkContext.setLogLevel("INFO")
spark.createDataFrame([
{'a': 1, 'b': 2},
{'a': 3, 'b': 4}
]).write.mode("overwrite").saveAsTable("temp_table8")
*Thread Reply:* This is my only code, I havent done anything apart from this
*Thread Reply:* I would try a more recent version of OL. Looks like you’re using 0.12.0 and I think the project is on 0.27.x currently
*Thread Reply:* so i should change io.openlineage:openlineage_spark:0.12.0 to io.openlineage:openlineage_spark:0.27.1?
*Thread Reply:* it executed well, unable to see it in marquez
*Thread Reply:* I am actually doing a POC on OpenLineage to find table and column level lineage for my team at Amazon. If this goes through, the team could use openlineage to track data lineage on a larger scale..
*Thread Reply:* Maybe marquez is still pulling the data from the previous run using the old OL version. Do you still get the same error in the browser console? Do you get the same result if you rebuild and start with a clean marquez db?
*Thread Reply:* yes i did that as well
*Thread Reply:* the error was present only once you clicked on any of the jobs in marquez, since my job isnt showing up i cant check for the error itself
*Thread Reply:* docker run --network sparkdefault -p 3000:3000 -e MARQUEZHOST=marquez-api -e MARQUEZ_PORT=5000 --link marquez-api:marquez-api marquezproject/marquez-web:0.19.1
used this to rebuild marquez
*Thread Reply:* That’s odd, sorry, that’s probably the most I can help, I’m kinda new to OL/Marquez as well 😅
*Thread Reply:* no problem, can you refer me to someone who would know, so that i can ask them?
*Thread Reply:* Actually looking at in now I think you’re using a slightly outdated version of marquez-web too. I would update that tag to at least 0.33.0. that’s what I’m using
*Thread Reply:* Other than that I would ask in the marquez slack channel or raise an issue in github on that project. Seems like more of an issue with Marquez since some at least some data is rendering in the UI initially
*Thread Reply:* nope that version also didnt help
*Thread Reply:* can you share their slack link?
*Thread Reply:* that link is no longer active
*Thread Reply:* Hello @Rachana Gandhi could you point to the doc where you found the example .config(‘spark.jars.packages’, ‘io.openlineage:openlineage_spark:0.12.0’) ? We should update it to have the latest version instead.
*Thread Reply:* https://openlineage.io/docs/integrations/spark/quickstart_local/
*Thread Reply:* https://openlineage.io/docs/guides/spark
also the docker compose here has an earlier version of marquez

*Thread Reply:* Facing same issue with my initial POC. Did we get any solution for this?
Approve a new release 🙂
*Thread Reply:* Requesting a release? 3 +1s from committers will authorize. More info here: https://github.com/OpenLineage/OpenLineage/blob/main/GOVERNANCE.md
*Thread Reply:* Because the python client is broken as is today without a new release
*Thread Reply:* Thanks, all. The release is authorized and will be initiated by EOB next Tuesday, but in all likelihood well before then.
@channel
We released OpenLineage 0.28.0, including:
Added
• dbt: add Databricks compatibility #1829 @Ines70
Fixed
• Fix type-checked marker and packaging #1913 @gaborbernat
• Python client: add schemaURL to run event #1917 @gaborbernat
For the details, see:
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.28.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.27.2...0.28.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
@channel Meetup announcement: there’s another meetup happening soon! This one will be an evening event on 6/22 in New York at Collibra’s HQ. For details and to sign up, please join the meetup group: https://www.meetup.com/data-lineage-meetup/events/294065396/. Thanks to @Sheeri Cabral (Collibra) for cohosting and providing a space.
Hi, just curious, does openlineage have a log4j integration?
*Thread Reply:* Do you mean to just log events to logging backend?
*Thread Reply:* Hmm more like have a separate logging config for sending all the logs to a backend
*Thread Reply:* Not the events itself
*Thread Reply:* @Anirudh Shrinivason with Spark integration?
*Thread Reply:* It uses slf4j so you should be able to set up your log4j logger
*Thread Reply:* Yeah with the spark integration. Ahh I see. Okay sure thanks!
*Thread Reply:* ~Hi @Maciej Obuchowski May I know what the class path I should be using for setting up the log4j if I want to set it up for OL related logs? Is there some guide or runbook to setting up the log4j with OL? Thanks!~ Nvm lol found it! 🙂

Hello all, we are just starting to use Marquez as part of our POC. We are following the getting started guide at https://openlineage.io/getting-started/ to set the environment on an AWS Ec2 instance. When we are running ./docker/up.sh, it is not bringing up marquez-web container. Also, we are not able to access Admin UI at 5000 and 5001 ports.
Docker version: 24.0.2 Docker compose version: 2.18.1 OS: Ubuntu_20.04
Can someone please let me know what I am missing? Note: I had to modify docker-compose command in up.sh as per docker compose V2.
Also, we are seeing following log when our loadbalancer is checking for health:
WARN [2023-06-13 15:35:31,040] marquez.logging.LoggingMdcFilter: status: 404 172.30.1.206 - - [13/Jun/2023:15:35:42 +0000] "GET / HTTP/1.1" 200 535 "-" "ELB-HealthChecker/2.0" 1 172.30.1.206 - - [13/Jun/2023:15:35:42 +0000] "GET / HTTP/1.1" 404 43 "-" "ELB-HealthChecker/2.0" 2 WARN [2023-06-13 15:35:42,866] marquez.logging.LoggingMdcFilter: status: 404

*Thread Reply:* Hello, is anyone eho has recently installed latest version of marquez/open-lineage-spark using docker image available to help Vamshi and I or provide any pointers? Thank you
*Thread Reply:* if you're working on mac, you can have an issue related to port 5000. Instructions here https://github.com/MarquezProject/marquez#quickstart provides a workaround for that ./docker/up.sh --api-port 9000
*Thread Reply:* @Paweł Leszczyński, thank you, we were using ubuntu on an EC2 instance and each time we are running into different errors and are never able to access the application page, web server, the admin interface, we have run out of ideas of what else to try differently to get this setup up and running
*Thread Reply:* @Michael Robinson Can you please help us here?
*Thread Reply:* @Vamshi krishna I’m sorry you’re still blocked. Thanks for the information about your system. Would you please share some of the errors you are getting? More details would help us reproduce and diagnose.
*Thread Reply:* @Michael Robinson, thank you, vamshi and i will share the errors that we are running into shortly
*Thread Reply:* We are following https://openlineage.io/getting-started/ guide and trying to set up Marquez on a ubuntu ec2 instance. Following are versions of docker, docker compose and ubuntu
*Thread Reply:* since I am getting timeouts, I thought it might be an issue with proxy. So, I followed this doc: https://stackoverflow.com/questions/58841014/set-proxy-on-docker and added my outbound proxy and tried
*Thread Reply:* @Michael Robinson @Paweł Leszczyński Can you please see above steps and let us know what are we missing/doing wrong? I appreciate your help and time.
*Thread Reply:* The latest errors look to me like they’re being caused by postgres and might reflect a port conflict. Are you using the default port for the API (5000)? You might try using a different port. More info about this in the Marquez readme: https://github.com/MarquezProject/marquez/blob/0.35.0/README.md.
*Thread Reply:* Yes we are using default ports: APIPORT=5000 APIADMINPORT=5001 WEBPORT=3000 TAG=0.35.0
*Thread Reply:* We see these postgres permission issues only occasionally. Other times we only see db and api containers up but not the web
*Thread Reply:* I would try running ./docker/up.sh --api-port 9000 (see Pawel’s message above for more context.)
*Thread Reply:* Still no luck. Seeing same errors.
2023-06-23 14:53:23.971 GMT [1] LOG: could not open configuration file "/etc/postgresql/postgresql.conf": Permission denied
marquez-db | 2023-06-23 14:53:23.971 GMT [1] FATAL: configuration file "/etc/postgresql/postgresql.conf" contains errors
*Thread Reply:* ERROR [2023-06-23 14:53:42,269] org.apache.tomcat.jdbc.pool.ConnectionPool: Unable to create initial connections of pool.
marquez-api | ! java.net.UnknownHostException: postgres
marquez-api | ! at java.base/sun.nio.ch.NioSocketImpl.connect(NioSocketImpl.java:567)
marquez-api | ! at java.base/java.net.SocksSocketImpl.connect(SocksSocketImpl.java:327)
marquez-api | ! at java.base/java.net.Socket.connect(Socket.java:633)
marquez-api | ! at org.postgresql.core.PGStream.createSocket(PGStream.java:243)
marquez-api | ! at org.postgresql.core.PGStream.<init>(PGStream.java:98)
marquez-api | ! at org.postgresql.core.v3.ConnectionFactoryImpl.tryConnect(ConnectionFactoryImpl.java:132)
marquez-api | ! at org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:258)
marquez-api | ! ... 26 common frames omitted
marquez-api | ! Causing: org.postgresql.util.PSQLException: The connection attempt failed.
marquez-api | ! at org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:354)
marquez-api | ! at org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:54)
marquez-api | ! at org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:253)
marquez-api | ! at org.postgresql.Driver.makeConnection(Driver.java:434)
marquez-api | ! at org.postgresql.Driver.connect(Driver.java:291)
marquez-api | ! at org.apache.tomcat.jdbc.pool.PooledConnection.connectUsingDriver(PooledConnection.java:346)
marquez-api | ! at org.apache.tomcat.jdbc.pool.PooledConnection.connect(PooledConnection.java:227)
marquez-api | ! at org.apache.tomcat.jdbc.pool.ConnectionPool.createConnection(ConnectionPool.java:768)
marquez-api | ! at org.apache.tomcat.jdbc.pool.ConnectionPool.borrowConnection(ConnectionPool.java:696)
marquez-api | ! at org.apache.tomcat.jdbc.pool.ConnectionPool.init(ConnectionPool.java:495)
marquez-api | ! at org.apache.tomcat.jdbc.pool.ConnectionPool.<init>(ConnectionPool.java:153)
marquez-api | ! at org.apache.tomcat.jdbc.pool.DataSourceProxy.pCreatePool(DataSourceProxy.java:118)
marquez-api | ! at org.apache.tomcat.jdbc.pool.DataSourceProxy.createPool(DataSourceProxy.java:107)
marquez-api | ! at org.apache.tomcat.jdbc.pool.DataSourceProxy.getConnection(DataSourceProxy.java:131)
marquez-api | ! at org.flywaydb.core.internal.jdbc.JdbcUtils.openConnection(JdbcUtils.java:48)
marquez-api | ! at org.flywaydb.core.internal.jdbc.JdbcConnectionFactory.<init>(JdbcConnectionFactory.java:75)
marquez-api | ! at org.flywaydb.core.FlywayExecutor.execute(FlywayExecutor.java:147)
marquez-api | ! at <a href="http://org.flywaydb.core.Flyway.info">org.flywaydb.core.Flyway.info</a>(Flyway.java:190)
marquez-api | ! at marquez.db.DbMigration.hasPendingDbMigrations(DbMigration.java:73)
marquez-api | ! at marquez.db.DbMigration.migrateDbOrError(DbMigration.java:27)
marquez-api | ! at marquez.MarquezApp.run(MarquezApp.java:105)
marquez-api | ! at marquez.MarquezApp.run(MarquezApp.java:48)
marquez-api | ! at io.dropwizard.cli.EnvironmentCommand.run(EnvironmentCommand.java:67)
marquez-api | ! at io.dropwizard.cli.ConfiguredCommand.run(ConfiguredCommand.java:98)
marquez-api | ! at io.dropwizard.cli.Cli.run(Cli.java:78)
marquez-api | ! at io.dropwizard.Application.run(Application.java:94)
marquez-api | ! at marquez.MarquezApp.main(MarquezApp.java:60)
marquez-api | INFO [2023-06-23 14:53:42,274] marquez.MarquezApp: Stopping app...
*Thread Reply:* Why do you run docker up with sudo? some of your screenshots suggest docker is not able to access docker registry. The last error java.net.UnknownHostException: postgres may be just a result of container being down. Could you verify if all the containers are up and running and if not what's the error? Are you able to test this docker.up in your laptop or other environment?
*Thread Reply:* Docker commands require sudo and cannot run with other user. Postgres container is not coming up. It is failing with following errors:
2023-06-23 14:53:23.971 GMT [1] LOG: could not open configuration file "/etc/postgresql/postgresql.conf": Permission denied
marquez-db | 2023-06-23 14:53:23.971 GMT [1] FATAL: configuration file "/etc/postgresql/postgresql.conf" contains errors
*Thread Reply:* and what does docker ps -a say about postgres container? why did it fail?
*Thread Reply:* hmyy, no changes on our side have been done in postgresql.conf since August 2022. Did you apply any changes or have a clean clone of a repo?
*Thread Reply:* No we didn't make any changes
*Thread Reply:* you did write earlier Note: I had to modify docker-compose command in up.sh as per docker compose V2.
*Thread Reply:* Yes all I did was modified this line: docker-compose --log-level ERROR $compose_files up $ARGS to
docker compose $compose_files up $ARGS since docker compose v2 doesn't support --log-level flag
*Thread Reply:* Let me pull an older version and try
*Thread Reply:* Still no luck same exact errors. Tried on a different ubuntu instance. Still seeing same errors with postgres
Hi all, a general doubt. Would the column lineage associated with a job be present in both the start events and the complete events? Or could there be cases where the column lineage, and any output information is only present in one of the events, but not the other?
*Thread Reply:* > Or could there be cases where the column lineage, and any output information is only present in one of the events, but not the other? Yes. Generally events regarding single run are cumulative
*Thread Reply:* Ahh I see... Is it fair to assume that if I see column lineage in a start event, it's the full column lineage? Or could it be possible that half the lineage is in the start event, and half the lineage is in the complete event?
*Thread Reply:* Hi @Maciej Obuchowski just pinging in case you'd missed the above message. 🙇
*Thread Reply:* Actually, in this case this definitely should not happen. @Paweł Leszczyński am I right?
*Thread Reply:* @Maciej Obuchowski yes, you're

Hi All.. Is JDBC supported for openLineage and marquez for columnlineage? I did some POC using tables in postgresdb and I am able to see all events but for columnLineage Iam getting it as NULL. Not sure where I am missing.
*Thread Reply:* ~No, we do have an open issue for that: https://github.com/OpenLineage/OpenLineage/issues/1758~
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @nivethika R, I am sorry for misleading response, we've merged PR for that https://github.com/OpenLineage/OpenLineage/pull/1636. It does not support select ** but besides that, it should be operational.
Could you please try a query from our integration tests to verify if this is working for you or not: https://github.com/OpenLineage/OpenLineage/pull/1636/files#diff-137aa17091138b69681510e13e3b7d66aa9c9c7c81fe8fe13f09f0de76448dd5R46 ?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

We are trying to install the image on the private AKS cluster and we ended up in below error
kubectl : pod marquez/pgsql-postgresql-client terminated (StartError) At line:1 char:1
- kubectl run pgsql-postgresql-client --rm --tty -i --restart='Never' `
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
- CategoryInfo : NotSpecified: (pod marquez/pgs...ed (StartError):String) [], RemoteException
- FullyQualifiedErrorId : NativeCommandError
failed to create containerd task: failed to create shim task: OCI runtime create failed: container_linux.go:380: starting container process caused: exec: "PGPASSWORD=macondo": executable file not found in $PATH: unknown
We followed the below article to install Marquez in AKS (Azure). By the way, we pulled the images from docker pushed it to our acr. tried installing the postgresql via ACR and it failed with the error
https://github.com/MarquezProject/marquez/blob/main/docs/running-on-aws.md
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* Hi Nagendra, sorry you’re running into this error. We’re looking into it!
Hi, found this error in couple of the spark jobs: https://github.com/OpenLineage/OpenLineage/issues/1930 Would request your help to kindly help patch thanks!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hey @Anirudh Shrinivason, me and Paweł are at Berlin Buzzwords right now. Will definitely look at it later
*Thread Reply:* Oh nice! Thanks!

Hi Team, we are not able to generate lineage for aggregate functions while joining two tables. below is the query df2 = spark.sql("select th.ProductID as Pid, pd.Name as N, sum(th.quantity) as TotalQuantity, sum(th.ActualCost) as TotalCost from silveradventureworks.transactionhistory as th join productdescription_dim as pd on th.ProductID = pd.ProductID group by th.ProductID, pd.Name ")

*Thread Reply:* This is the event generated for above query.
this is event for view for which no lineage is being generated
Has anyone here successfully implemented the Amundsen OpenLineage extractor? I’m a little confused on the best way to output my lineage events to ndjson files in a scalable way as the docs seem to suggest. Currently I’m pushing all my lineage events to Marquez via REST API. I suppose I could change my transports to Kinesis and write the events to s3 but that comes with the cost of having to build some new way of getting the events to Marquez.
In any case, this seems like a problem someone must have solved before?
Edit: looking at the source code for this Amundsen extractor, it seems like it should be pretty straightforward to just implement our own extractor that can pull these records from the Marquez backend. Will give that a shot and see about getting that merged into Amundsen later.
*Thread Reply:* Hi John, glad to hear you figured out a path forward on this! Please let us know what you learn 🙂
Our New York meetup with Collibra is happening in just two days! https://openlineage.slack.com/archives/C01CK9T7HKR/p1686594956030059
Hello all, Do you know if we have th possibility of persisting column orders while creating lineage as it may be available in the table or data set from which it originates. Or, is there some way in which we can get the column order (id or something).
For example, if a dataset has columns xyz, abc, fgh, dec, I would like to know which column shows first in the dataset in the common data model. Please let me know. m
*Thread Reply:* Hi Harshini, I’ve alerted our resident Spark and column-lineage expert about this. Hope to have an answer for you soon.
*Thread Reply:* Thank you Michael, looking forward to it
*Thread Reply:* Hello @Harshini Devathi. An interesting topic which I have never thought about. The ordering of the fields, we get for Spark Apps, comes from Spark logical plans we extract information from and we do not apply any sorting on them. So, if Spark plan contains columns a , b, c we trust it's the order of columns for a dataset and don't want to check it on our own.
*Thread Reply:* btw. please let us know how do you obtain your lineage: within a Spark app or from some SQL's scheduled by Airflow?
*Thread Reply:* Hello @Paweł Leszczyński, thank you for the response. We do not need you to check the ordering specifically but I assume that the spark logical plan maintains the column order based on the input datasets. Can we retain that order by adding column id or some sequence number which helps to represent the lineage in the same order.
The lineage we are capturing using Spark openlineage connector, by posting custom lineage to Marquez through API calls, and also in process of leveraging SQL connector feature using Airflow.
*Thread Reply:* Hi @Harshini Devathi, are you asking about schema facet within a dataset? This should have an order from spark logical plans. Or, are you asking about columnLineage facet? Or Marquez API responses? It's not clear to me why do you need it. Each column, is identified by a dataset (dataset namespace + dataset name) and field name. You can, on your side, generate and column id based on that and order columns based on the id, but still I think I am missing some arguments behind doing so.
Attention all Bay-area data friends and Data+AI Summit attendees: our first San Francisco meetup is next Tuesday! https://www.meetup.com/meetup-group-bnfqymxe/events/293448130/

Last night in New York we held a meetup with Collibra at their lovely HQ in the Financial District! Many thanks to @Sheeri Cabral (Collibra) for inviting us. Over a bunch of tasty snacks (thanks for the idea @Harel Shein), we discussed: • the history and evolution of the spec, and trends in adoption • progress on the OpenLineage Provider in Airflow (AIP 53) • progress on “static” AKA design lineage support (expected soon in OpenLineage 1.0.0) • progress in the LFAI program • a proposal to add “jobless run” support for auditing use cases and similar edge cases • an idea to throw a hackathon for creating validation tests and example payloads (would you be interested in participating? let us know!) • and more. Many thanks to: • @Julien Le Dem for making the trip • Sheeri & Collibra for hosting • everyone for coming, including second-timer @Ernie Ostic and new member @Shirley Lu It was great meeting/catching up with everyone. Hope to see you and more new faces at the next one!
Our first San Francisco meetup is tomorrow at 5:30 PM at Astronomer’s offices in the Financial District. https://openlineage.slack.com/archives/C01CK9T7HKR/p1687383708927189
I can’t seem to get OL logging working with Spark. Any guidance please?
*Thread Reply:* Is it because the logLevel is set to WARN or ERROR?
*Thread Reply:* No, I set it to INFO, may be I need to add some jars?
*Thread Reply:* Hmm have you set the relevant spark configs?
*Thread Reply:* yep, I have http working. But not the console
spark.extraListeners=io.openlineage.spark.agent.OpenLineageSparkListener
spark.openlineage.transport.type=console
*Thread Reply:* Oh wait http works but not console...
*Thread Reply:* If you want to see the console events which are emitted, then need to set logLevel to DEBUG
*Thread Reply:* Is the openlienage jar installed and added to config?
*Thread Reply:* the only thing I see in the logs is this:
23/06/27 07:39:11 INFO SparkSQLExecutionContext: OpenLineage received Spark event that is configured to be skipped: SparkListenerJobEnd
*Thread Reply:* Hmm if an event is still emitted for this case, but logs not showing up then I'm not sure... Maybe someone with more knowledge on this can help
*Thread Reply:* sure, thanks for trying @Anirudh Shrinivason
*Thread Reply:* What job are you trying this on? If there's this message, then logging is working afaik
*Thread Reply:* Hi @Maciej Obuchowski Actually I also noticed a similar issue... For some spark pipelines, the log level is set to debug, but I'm not seeing any events being logged. I am however receiving these events in the backend. Have any of the logging been removed from some places?
*Thread Reply:* yep, exactly same thing here also @Maciej Obuchowski, I can get the events on http, but changing to console gets me nothing from ConsoleTransport.
@here A bunch of us are downstairs in the lobby at 8 California but no one is down here to let us up. Anyone here to help?
Hi guys, I noticed a few of the jobs getting OOMed while running with openlineage. Even increasing the number of executors and doubling the memory does not seem to fix it actually. This is observed especially when using the graphx libs. Is this a known issue? Just curious as to what the cause might be... The same jobs run fine once openlineage is disabled. Are there some rogue threads from the listener or any connections we aren't closing properly?
*Thread Reply:* Hi @Anirudh Shrinivason, could you disable serializing spark.logicalPlan to see if the behaviour is the same?
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark -> spark.openlineage.facets.disabled -> [spark_unknown;spark.logicalPlan]
*Thread Reply:* We do serialize logicalPlan because this is useful in many cases, but sometimes can lead to serializing things that shouldn't be serialized
*Thread Reply:* Ahh I see. Yeah okay let me try that
Hello all, I’m opening a vote to release OpenLineage 0.29.0, including:
• support for Spark 3.4
• support for Flink 1.17.1
• a fix in the Flink integration to enable dataset schema extraction for a KafkaSource when GenericRecord is used
• removal of the unused Golang proxy client (made redundant by the fluentd proxy)
• security vulnerability fixes, doc changes, test improvements, and more.
Three +1s from committers will authorize an immediate release.
*Thread Reply:* Thanks, all. The release is authorized.
@channel
We released OpenLineage 0.29.2, including:
Added
• Flink: support Flink version 1.17.1 #1947 @pawel-big-lebowski
• Spark: support Spark version 3.4 #1790 @pawel-big-lebowski
Removed
• Proxy: remove unused Golang client approach #1926 @mobuchowski
• Req: bump minimum supported Python version to 3.8 #1950 @mobuchowski
◦ Note: this removes support for Python 3.7, which is at EOL.
Plus test improvements, docs changes, bug fixes and more.
Thanks to all the contributors!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.29.2
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.28.0...0.29.2
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
@channel The latest issue of OpenLineage News is now available, featuring a recap of recent events, releases, and more. To get it directly in your inbox each month, sign up https://openlineage.us14.list-manage.com/track/click?u=fe7ef7a8dbb32933f30a10466&id=e598962936&e=ef0563a7f8|here.
@channel This month’s TSC meeting is next Thursday, 7/13, at a special time: 8 am PT. All are welcome! On the tentative agenda: • announcements • updates • recent releases • a new DataGalaxy integration • open discussion
Wow, I just got finished watching @Julien Le Dem and @Willy Lulciuc’s presentation of OpenLineage at databricks and it’s really fantastic! There isn’t a better 30 minutes of content on theory + practice than this, IMO. https://www.databricks.com/dataaisummit/session/cross-platform-data-lineage-openlineage/ (you can watch for free by making an account. I’m not affiliated with databricks…)

*Thread Reply:* thanks for watching and sharing! the recording is also on youtube 😉 https://www.youtube.com/watch?v=rO3BPqUtWrI

*Thread Reply:* Very much agree. I’ve even forwarded to a few people here and there, those who I think should learn about it.
*Thread Reply:* You’re both too kind :) Thank you for your support and being part of the community.
@channel If you registered for TSC meetings through AddEvent, first of all, thank you! Second of all, I’ve had to create a new event series there to enable the editing of individual events. When you have a moment, would you please register for next week’s meeting? Apologies for the inconvenience.


Hi community, we are interested in capturing time-travel usage for Iceberg Spark sql in column lineage. For instance, INSERT INTO schema.table select ** from schema.another_table version as of 'some_version' . Column lineage is currently missing the version, if used, which it’s actually quite relevant. I’ve gone through the open issues and didn’t see anything similar. Does it look like a valid use case scenario? We started going through the OL, iceberg and Spark code in trying to capture/expose it, but so far we haven’t been able to. If anyone can give a hint/idea/pointer, we are willing to give it try a contribute back with the code
*Thread Reply:* I think yes this is a great use case. @Paweł Leszczyński is more familiar with the spark integration code than I. I think in this case, we would add the datasetVersion facet with the underlying Iceberg version: https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/DatasetVersionDatasetFacet.json We extract this information in a few places: https://github.com/search?q=repo%3AOpenLineage%2FOpenLineage%20%20DatasetVersionDatasetFacet&type=code
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Yes, we do have datasetVersion which captures for output and input datasets their iceberg or delta version. Input versions are collected on START while output are collected on COMPLETE in case a job reads and writes to the same dataset. So, even though column-lineage facet is missing the version, it should be available within events related to a particular run.
If it is not, then perhaps the case here is the lack of support of as of syntax. As far as I remeber, we always get a current version of a dataset and this may be a missing part here.
*Thread Reply:* link to a method that gets dataset version for iceberg: https://github.com/OpenLineage/OpenLineage/blob/0.29.2/integration/spark/spark3/sr[…]lineage/spark3/agent/lifecycle/plan/catalog/IcebergHandler.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thank you @Julien Le Dem and @Paweł Leszczyński
Based on what I’ve seen so far, indeed it seems that only the current snapshot is tracked. When IcebergHandler.getDatasetVersion()
Initially I was expecting to be able to obtain the snapshotId from the SparkTable which comes within getDatasetVersion() but now I realize that OL is using an older version of Iceberg runtime, (0.12.1) which does not support time travel (introduced in 0.14.1).
The evidence is:
• Iceberg documentation for release 0.14.1: https://iceberg.apache.org/docs/0.14.0/spark-queries/#sql
• Iceberg release notes https://iceberg.apache.org/releases/#0140-release
• Comparing the source code, I see the SparkTable from 0.14.1 onward does have a snapshotId instance variable, while previous versions don’t
https://github.com/apache/iceberg/blob/0.14.x/spark/v3.0/spark/src/main/java/org/apache/iceberg/spark/source/SparkTable.java#L82
https://github.com/apache/iceberg/blob/0.12.x/spark3/src/main/java/org/apache/iceberg/spark/source/SparkTable.java#L78
I don’t see anyone complaining about the old version of Iceberg runtime being used and there is no open issue to upgrade so I’ll open the issue and please let me know if that seems reasonable as the immediate next step to take
*Thread Reply:* Thanks @Juan Manuel Cappi. openlineage-spark jar contains modules like spark3 , spark32 , spark33 and spark34 that is going to be merged soon (we do have a ready PR for that). spark34 will be compiled against latest iceberg version. Once this is done #1969 can be closed. For 1970, one would need to implement datasetBuilder within spark34 module and visits node within spark's logical plan that is responsible for as of and creates dataset for OpenLineage event other way than getting latest snapshot version.
*Thread Reply:* @Paweł Leszczyński I’ve see PR #1971 and I see a new spark34 project with the latest iceberg-spark dependency version, but other versions (spark33, spark32, etc) have not being upgraded in that PR. Since the change is small and does not break any tests, I’ve created PR #1976 for to fix #1969. That alone is unlocking some time travel lineage (i.e. dataset identifier now becomes schema.table.version or schema.table.snapshot_id). Hope it makes sense
*Thread Reply:* Hi @Juan Manuel Cappi, You're right and after discussion with you I realized we support some version of iceberg (for spark 3.3 it's still 0.14.0) but this is not the latest iceberg version matching spark version.
There's some tricky part here. Although we wan't our code to succeed with latest spark, we don't want it to fail in a nasty way (class not found exception) when a user is working with an old iceberg version. There are places in our code where we do check are iceberg classes on the classpath? We need to extend this to are iceberg classes on classpath is iceberg version above 0.14 or not For sure this is the case for merge into commands I am working on at the moment. Let's see if the other integration tests are affected in your PR

HI Team, I Seen that Kafka lineage is not coming properly in for Spark streaming, Are we working on this?
*Thread Reply:* what do you mean by that? there is a pyspark & kafka integration test that verifies event being sent when reading or writing to kafka topic: https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/tes[…]a/io/openlineage/spark/agent/SparkContainerIntegrationTest.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* We do have an old issue https://github.com/OpenLineage/OpenLineage/issues/372 to support more spark plans that are stream related. But, if you had an example of streaming that is not working for you, this would have been really helpful.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I have a pipeline Which reads from topic and send data to 3 HIVE tables and one postgres , Its not emitting any lineage for this pipeline
*Thread Reply:* just one task is getting created
Hi guys, I notice that with the below spark configs: ```from pyspark.sql import SparkSession import os
os.environ["TEST_VAR"] = "1"
spark = (SparkSession.builder.master('local') .appName('samplespark') .config('spark.jars.packages', 'io.openlineage:openlineagespark:0.29.2,io.delta:deltacore2.12:1.0.1') .config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener') .config('spark.openlineage.transport.type', 'console') .config('spark.sql.catalog.sparkcatalog', "org.apache.spark.sql.delta.catalog.DeltaCatalog") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("hive.metastore.schema.verification", False) .config("spark.sql.warehouse.dir","/tmp/") .config("hive.metastore.warehouse.dir","/tmp/") .config("javax.jdo.option.ConnectionURL","jdbc:derby:;databaseName=/tmp/metastoredb;create=true") .config("spark.openlineage.facets.customenvironmentvariables","[TESTVAR;]") .config("spark.openlineage.facets.disabled","[sparkunknown;spark.logicalPlan]") .config("spark.hadoop.fs.permissions.unmask-mode","000") .enableHiveSupport() .getOrCreate())``` The custom environment variables facet is not kicking in. However, when all the delta related spark configs are removed, it is working fine. Is this a known issue? Are there any workarounds for it? Thanks!
*Thread Reply:* Hi @Anirudh Shrinivason, I’m not familiar with Delta, but enabling debugging helped me a lot to understand what’s going when things fail silently. Just add at the end:
spark.sparkContext.setLogLevel("DEBUG")
*Thread Reply:* Yeah I checked on debug
*Thread Reply:* There are no errors
*Thread Reply:* Just that there is no environment-properties in the event that is being emitted
*Thread Reply:* Hi @Anirudh Shrinivason, what spark version is that? i see you delta version is pretty old. Anyway, the observation is weird and don't know how come delta interferes with environment facet builder. These are so disjoint features. Are you sure you create a new session (there is getOrCreate) ?

*Thread Reply:* @Paweł Leszczyński its because of this line : https://github.com/OpenLineage/OpenLineage/blob/0.29.2/integration/spark/app/src/m[…]nlineage/spark/agent/lifecycle/InternalEventHandlerFactory.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Assuming this is https://learn.microsoft.com/en-us/azure/databricks/delta/ ... delta .. which is azure datbricks. @Anirudh Shrinivason
*Thread Reply:* Hmm I wasn't using databricks
*Thread Reply:* @Paweł Leszczyński I'm using spark 3.1 btw
*Thread Reply:* @Anirudh Shrinivason This should resolve the issue https://github.com/OpenLineage/OpenLineage/pull/1973
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* PR description contains info on how come the observed behaviour was possible
*Thread Reply:* As always, thank you @Anirudh Shrinivason for providing clear information on how to reproduce the issue 🚀 :medal: 👍
*Thread Reply:* Ohh that is really great! Thankss so much for the help! 🙂
@channel A friendly reminder: this month’s TSC meeting — open to all — is tomorrow at 8 am PT. https://openlineage.slack.com/archives/C01CK9T7HKR/p1688665004736219
Hi Team How are you ? Is there any chance to use airflow to run queries against Access file? Sorry to bother with a question that is not directly related to openlineage ... but I am kind of stuck
*Thread Reply:* what do you mean by Access file?
*Thread Reply:* ... accdb file, Microsoft Access File: I am in a reverse engineering projet facing a spaghetti style development and would have loved to use, airflow and openlineage as a magic wand, to help me in this damn work
*Thread Reply:* oof.. I’d look into https://airflow.apache.org/docs/apache-airflow-providers-odbc/4.0.0/ but I really have no clue..
*Thread Reply:* Thank you Harel I started from that too ... but it became foggy after the initial step

Hi folks, having an issue ingesting the seed metadata when starting the docker container. The output shows "seed-marquez-with-metadata exited with code 0" but no information is visible in marquez What can be the issue?
*Thread Reply:* Did you check the namespace menu in the top right for a food_delivery namespace?
*Thread Reply:* I think that should be added to the quickstart guide
*Thread Reply:* Great idea, thank you
As discussed in the Monthly meeting, I have opened a PR to propose adding deletion to facets for static lineage metadata: https://github.com/OpenLineage/OpenLineage/pull/1975
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi, I'm using OL python client.
client.emit(
DatasetEvent(
_eventTime_=datetime.now().isoformat(),
_producer_=producer,
_schemaURL_="<https://openlineage.io/spec/1-0-5/OpenLineage.json#/definitions/DatasetEvent>",
_dataset_=Dataset(_namespace_=namespace, _name_=f"input-file"),
)
)
I want to send a dataset event once files been uploaded. But I received 422 from api/v1/lineage, saying that run and job must not be null. I don't have a job or run yet. How can I solve this?
*Thread Reply:* Hi @Steven, I assume you send your Openlineage events to Marquez. 422 http code is a response from backend and Marquez is still waiting for the PR https://github.com/MarquezProject/marquez/pull/2495 to be merged and released. This PR makes Marquez understand DatasetEvents. They won't be saved in Marquez database (this is to be implemented in future), but at least one will not experience error response code.
To sum up: what you do is correct. You are using a feature that is allowed on a client side but still not implemented on a backend.
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
@here Hi Team, I am trying to run a spark application with openLineage Spark :- 3.3.3 Openlineage :- 0.29.2 I am getting below error can you please me, what I could be doing wrong.
``` spark = (SparkSession .builder .config('spark.port.maxRetries', 100) .appName(app_name) .config("spark.openlineage.url","http://localhost/api/v1/namespaces/spark_integration/") .config("spark.extraListeners","io.openlineage.spark.agent.OpenLineageSparkListener") .getOrCreate())
23/07/14 18:04:01 ERROR Utils: uncaught error in thread spark-listener-group-shared, stopping SparkContext java.lang.UnsatisfiedLinkError: /private/var/folders/z6/pl8p30z11v50zf6pv51p259m0000gp/T/native-lib4983292552717270883/libopenlineagesqljava.dylib: dlopen(/private/var/folders/z6/pl8p30z11v50zf6pv51p259m0000gp/T/native-lib4983292552717270883/libopenlineagesqljava.dylib, 0x0001): tried: '/private/var/folders/z6/pl8p30z11v50zf6pv51p259m0000gp/T/native-lib4983292552717270883/libopenlineagesqljava.dylib' (mach-o file, but is an incompatible architecture (have 'x8664', need 'arm64')), '/System/Volumes/Preboot/Cryptexes/OS/private/var/folders/z6/pl8p30z11v50zf6pv51p259m0000gp/T/native-lib4983292552717270883/libopenlineagesqljava.dylib' (no such file), '/private/var/folders/z6/pl8p30z11v50zf6pv51p259m0000gp/T/native-lib4983292552717270883/libopenlineagesqljava.dylib' (mach-o file, but is an incompatible architecture (have 'x8664', need 'arm64')) at java.lang.ClassLoader$NativeLibrary.load(Native Method)```
*Thread Reply:* Hi @Harshit Soni, where are you deploying your spark? locally or not? is it on mac? Calling @Maciej Obuchowski to help with ibopenlineage_sql_java architecture compilation issue
*Thread Reply:* Currently, was testing on local.
*Thread Reply:* We have created a centralised utility for all data ingestion needs and want to see how lineage is created for same using Openlineage.
@channel If you missed this month’s TSC meeting, the recording is now available on our YouTube channel: https://youtu.be/2vD6-Uwr7ZE. A clip of Alexandre Bergere’s DataGalaxy integration demo is also available: https://youtu.be/l_HbEtpXphY.



Hey guys - trying to get a grip on the ecosystem regarding flink lineage 🙂 as far as my research has revealed, the openlineage project is the only one that supports flink lineage with an out of the box library that can be integrated in jobs. at least as far as i've seen the for other toolings such as datahub we'd have to write our custom hooks that implement their api. as for my question - is my current assumption correct that an integration into the openlineage project of for example datahub/openmetadata would also require support from datahub/openmetadata itself so that they can work with the openlineage spec? or would it somewhat work to write a mapper in between to support their spec? (more of an architectural decision i assume but would be interested in knowing what the openlinage's approach is regarding that)
*Thread Reply:* > or would it somewhat work to write a mapper in between to support their spec? I think yeah - maybe https://github.com/Natural-Intelligence/openLineage-openMetadata-transporter would work out of the box if I understand correctly?
*Thread Reply:* Tagging @Natalie Zeller in case you want to collaborate
*Thread Reply:* Hi, We've implemented a transporter that transmits lineage from OpenLineage to OpenMetadata, you can find the github project here. I've also published a blog post that explains this integration and how to use it. I'll be happy to help if you have any question
*Thread Reply:* very cool! thanks a lot for responding so quickly
🚀 We recently hit the 1000-member mark on here! Thank you for joining the movement to establish an open standard for data lineage across the data ecosystem! Tell your friends 🙂! 💯💯💯💯💯💯💯💯💯💯 https://bit.ly/lineageslack
Btw, just curious what exactly does the runId correspond to in the OL spark integration? Is it possible to obtain the spark application id from the event too?
*Thread Reply:* runId is an UUID assigned per spark action (compute trigger within a spark job). A single spark script can result in multiple runs then
*Thread Reply:* adding an extra facet with applicationId looks like a good idea to me: https://spark.apache.org/docs/latest/api/scala/org/apache/spark/SparkContext.html#applicationId:String
*Thread Reply:* Got it thanks!

Hi, I have an usecase to integrate queries run in Jupyter notebook using pandas integrate with OpenLineage to get the Lineage in Marquez. Did anyone implemented this before? please let me know. Thanks
*Thread Reply:* I think we don't have pandas support so far. So, if one uses pandas to read local files on disk, then perhaps Openlineage (OL) has little sense to do. There is an old pandas issues in our backlog (over 2 years old) -> https://github.com/OpenLineage/OpenLineage/issues/108
Surely one can use use python OL client to create manully events and send them to MQZ, which may be less convenient (https://github.com/OpenLineage/OpenLineage/tree/main/client/python)
Anyway, we would like to know what's you usecase? this would be super helpful in understanding why OL & pandas integration may be useful.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks Pawel for responding
Hi guys, when can we expect the next Openlineage release? Excited for MergeIntoCommand column lineage feature!
*Thread Reply:* Hi @Anirudh Shrinivason, I am still working on that. It's kind of complex because I want to refactor column level lineage so that it can work with multiple Spark versions and multiple delta jars as merge into implementation for delta differs for different delta releases. I thought it's ready, but this needs some extra work to be done in next days. I am excited about that too!
*Thread Reply:* Ahh I see... Got it! Is there a tentative timeline for when we can expect this? So sorry haha don't mean to rush you. Just curious to know thats all! 🙂
*Thread Reply:* Can we author a release sometime soon? Would like to use the CustomEnvironmentFacetBuilder for delta catalog!
*Thread Reply:* we're pretty close i think with merge into delta which is under review. waiting for it would be nice. anyway, we're 3 weeks after the last release.
*Thread Reply:* @Anirudh Shrinivason releases are available basically on-demand using our process in GOVERNANCE.md. I recommend watching 1958 and then making a request in #general once it’s been merged. But, as Paweł suggested, we have a scheduled release coming soon, anyway. Thanks for your interest in the fix!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Ahh I see. Got it. Thanks! @Michael Robinson @Paweł Leszczyński
*Thread Reply:* @Anirudh Shrinivason it's merged -> https://github.com/OpenLineage/OpenLineage/pull/1958
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Awesome thanks so much! @Paweł Leszczyński
Hi there, related to my question a few days ago about usage of time travel in iceberg, currently only the alias used (i.e. tag, branch) is captured as part of the dataset identifier for lineage. If the tag is removed, or even worse, if it’s removed and re-created with the same name pointing to a difference snapshotid, the lineage will be capturing an inaccurate history. So, ideally, we’d like to capture the actual snapshotid behind the named reference, as part of the lineage. Anyone else thinking this is a reasonable scenario? => more in 🧵
*Thread Reply:* One hacky approach would be to update the current dataset identifier to include the snapshot_id, so, for schema.table.tag we would have something like schema.table.tag-snapshot_id. The benefit is that it’s explicit and it doesn’t require a change in the OL schemas. The obvious downside (though not that serious in my opinion) is that impacts readability. Not sure though if there are other non-obvious side-effects.
Another alternative would be to add a dedicated property. For instance, the job > latestRun schema, the input/output dataset version objects could look like this:
"inputDatasetVersions": [
{
"datasetVersionId": {
"namespace": "<s3a://warehouse>",
"name": "schema.table.tag",
"snapshot_id": "7056736771450556218",
"version": "1c634e18-e357-347b-b758-4337ac352d6d"
},
"facets": {}
}
]
And column lineage could look like:
```"columnLineage": [
{
"name": "somefield",
"inputFields": [
{
"namespace": "s3a:warehouse",
"dataset": "schema.table.tag",
"snapshotid": "7056736771450556218",
"field": "some_field",
...
},
...
],
...```
*Thread Reply:* @Paweł Leszczyński what do you think?
*Thread Reply:* 1. How does snapshotId differ from version? Could one make OL version property to be a string concat of iceberg-snapshot-id.iceberg-version
- I don't think it's necessary (or don't understand why) to add snapshot-id within column-linegea. Each entry within inputFields of columnLineage is already available within
inputsof the OL event related to this run.
*Thread Reply:* Yes, I think follow the idea. The problem with that is the version is tied to the dataset name, i.e. my_namespace.table_A.tag_v1 which stays the same for the source dataset, which is the one being used with time travel.
Suppose the following sequence:
step 1 =>
tableA.tagv1 has snapshot id 123-abc
run job: table_A.tag_v1 -> job x -> table_B
the inputDatasetVersions > datasetVersionId > version for table_B points to an object which represents table_A.tag_v1 with snapshot id 123-abc correctly captured within facets > version > datasetVersion
step 2 =>
delete tag_v1, insert some data, create tag_v1 again
now table_A.tag_v1 has snapshot id 456-def
run job again: table_A.tag_v1 -> job x -> table_B
the inputDatasetVersions > datasetVersionId > version for table_B points to the same object which represents table_A.tag_v1 only now snapshot id has been replaced by 456-def within facets > version > datasetVersion which means I don’t have way to know which was the snapshot id used in the step 1
The “hack” I mentioned above though seems to solve the issue, since a new dataset is captured for each combination, so no information is overwritten/lost, i.e., the datasets referenced in inputDatasetVersions are now named:
table_A.tag_v1-123-abc
table_A.tag_v1-456-def
As a side effect, the column lineage also gets “fixed”, since the lineage for the step 1 and step 2 job runs, without the “hack” both referenced table_A.tag_v1 as the source of input field, though in each run the snapshot id was different. With the hack, one run references table_A.tag_v1-123-abc and the other one table_A.tag_v1-456-def
Hope it makes sense. If it helps, I can put together a few json files with the examples I’ve been using to experiment
*Thread Reply:* So, my understanding of the problem is that icberg version is not unique. So, if you have version 3, revert to version 2, and then write something again, one ends up again with version 3.
I would not like to mess with dataset names because on the backend sides like Marquez, dataset names being the same in different jobs and runs allow creating lineage graph. If dataset names are different, then there is no way to build lineage graph across multiple jobs.
Adding snapshot_id to datasetVersion is one option to go. My concern here is that this is so iceberg specific while we're aiming to have a general solution to dataset versioning.
Some other options are: send concat of version+snapshotId as a version or send only snapshot_id as a version. The second ain't that bad as actually snapashotId is something we're aiming to get as a version, isn't it?
Hi guys, I’d like to open a vote to release the next OpenLineage version! We'd really like to use the fixed CustomEnvironmentFacetBuilder for delta catalogs, and column lineage for Merge Into command in the spark integration! Thanks! 🙂
*Thread Reply:* Thanks, all. The release is authorized and will be initiated within two business days per our policy here.
*Thread Reply:* @Anirudh Shrinivason and others waiting on this release: the release process isn’t working as expected due to security improvements recently made to the website, ironically enough, which is the source for the spec. But we’re working on a fix and hope to complete the release soon.
*Thread Reply:* @Anirudh Shrinivason the release (0.30.1) is out now. Thanks for your patience 🙂
*Thread Reply:* Hi @Michael Robinson Thanks a lot!
*Thread Reply:* > I am running a job in Marquez with 180 rows of metadata
Do you mean that you have +100 rows of metadata in the jobs table for Marquez? Or that the job never finishes?
*Thread Reply:* If you post a sample of your events, it’d be helpful to troubleshoot your issue
*Thread Reply:* Sure Willy thanks for your response. The job is still running. This is the code I am running from jupyter notebook using Python client:
*Thread Reply:* as you can see my input and output datasets are just 1 row
*Thread Reply:* included column lineage but job keeps running so I don't know if it is working
Please ignore 'UPDATED AT' timestamp
@Paweł Leszczyński there is lot of interest in our organisation to implement Openlineage in several project and we might take the spark route so on that note a small question: Does open lineage works from extracting data from the Catalyst optimiser's Physical/Logical plans etc?
*Thread Reply:* spark integration is based on extracting lineage from optimized plans
*Thread Reply:* https://youtu.be/rO3BPqUtWrI?t=1326 i recommend whole presentation but in case you're just interested in Spark integration, there few mins that explain how this is achieved (link points to 22:06 min of video)
*Thread Reply:* Thanks Pawel for sharing. I will take a look. Have a nice weekend.

Hello everyone!
*Thread Reply:* Welcome, @Jens Pfau!

hello everyone! I am trying to follow your guide https://openlineage.io/docs/integrations/spark/quickstart_local and when i execute spark.createDataFrame([ {'a': 1, 'b': 2}, {'a': 3, 'b': 4} ]).write.mode("overwrite").saveAsTable("temp1")
i not getting the expected result
``23/07/23 12:35:20 INFO OpenLineageRunEventBuilder: Visiting query plan Optional[== Parsed Logical Plan ==
'CreateTabletemp1`, Overwrite
+- LogicalRDD [a#6L, b#7L], false
== Analyzed Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Optimized Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Physical Plan ==
Execute CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- **(1) Scan ExistingRDD[a#6L,b#7L]
] with input dataset builders [<function1>, <function1>, <function1>, <function1>, <function1>]
23/07/23 12:35:20 INFO OpenLineageRunEventBuilder: Visiting query plan Optional[== Parsed Logical Plan ==
'CreateTable temp1, Overwrite
+- LogicalRDD [a#6L, b#7L], false
== Analyzed Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Optimized Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Physical Plan ==
Execute CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- **(1) Scan ExistingRDD[a#6L,b#7L]
] with output dataset builders [<function1>, <function1>, <function1>, <function1>, <function1>, <function1>, <function1>]
23/07/23 12:35:20 INFO CreateDataSourceTableAsSelectCommandVisitor: Matched io.openlineage.spark.agent.lifecycle.plan.CreateDataSourceTableAsSelectCommandVisitor<org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand,io.openlineage.client.OpenLineage$OutputDataset> to logical plan CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
23/07/23 12:35:20 INFO CreateDataSourceTableAsSelectCommandVisitor: Matched io.openlineage.spark.agent.lifecycle.plan.CreateDataSourceTableAsSelectCommandVisitor<org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand,io.openlineage.client.OpenLineage$OutputDataset> to logical plan CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
23/07/23 12:35:20 ERROR EventEmitter: Could not emit lineage w/ exception
io.openlineage.client.OpenLineageClientException: io.openlineage.spark.shaded.org.apache.http.client.ClientProtocolException
at io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:105)
at io.openlineage.client.OpenLineageClient.emit(OpenLineageClient.java:34)
at io.openlineage.spark.agent.EventEmitter.emit(EventEmitter.java:71)
at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:77)
at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$sparkSQLExecStart$0(OpenLineageSparkListener.java:99)
at java.base/java.util.Optional.ifPresent(Optional.java:183)
at io.openlineage.spark.agent.OpenLineageSparkListener.sparkSQLExecStart(OpenLineageSparkListener.java:99)
at io.openlineage.spark.agent.OpenLineageSparkListener.onOtherEvent(OpenLineageSparkListener.java:90)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:100)
at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37)
at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117)
at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101)
at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105)
at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105)
at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1381)
at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
Caused by: io.openlineage.spark.shaded.org.apache.http.client.ClientProtocolException
at io.openlineage.spark.shaded.org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:187)
at io.openlineage.spark.shaded.org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83)
at io.openlineage.spark.shaded.org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:108)
at io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:100)
... 21 more
Caused by: io.openlineage.spark.shaded.org.apache.http.ProtocolException: Target host is not specified
at io.openlineage.spark.shaded.org.apache.http.impl.conn.DefaultRoutePlanner.determineRoute(DefaultRoutePlanner.java:71)
at io.openlineage.spark.shaded.org.apache.http.impl.client.InternalHttpClient.determineRoute(InternalHttpClient.java:125)
at io.openlineage.spark.shaded.org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:184)
... 24 more
23/07/23 12:35:20 INFO ParquetFileFormat: Using default output committer for Parquet: org.apache.parquet.hadoop.ParquetOutputCommitter
23/07/23 12:35:20 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
23/07/23 12:35:20 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
23/07/23 12:35:20 INFO SQLHadoopMapReduceCommitProtocol: Using user defined output committer class org.apache.parquet.hadoop.ParquetOutputCommitter
23/07/23 12:35:20 INFO FileOutputCommitter: File Output Committer Algorithm version is 1
23/07/23 12:35:20 INFO FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
23/07/23 12:35:20 INFO SQLHadoopMapReduceCommitProtocol: Using output committer class org.apache.parquet.hadoop.ParquetOutputCommitter
23/07/23 12:35:20 INFO CodeGenerator: Code generated in 120.989125 ms
23/07/23 12:35:21 INFO SparkContext: Starting job: saveAsTable at NativeMethodAccessorImpl.java:0
23/07/23 12:35:21 INFO DAGScheduler: Got job 0 (saveAsTable at NativeMethodAccessorImpl.java:0) with 1 output partitions
23/07/23 12:35:21 INFO DAGScheduler: Final stage: ResultStage 0 (saveAsTable at NativeMethodAccessorImpl.java:0)
23/07/23 12:35:21 INFO DAGScheduler: Parents of final stage: List()
23/07/23 12:35:21 INFO DAGScheduler: Missing parents: List()
23/07/23 12:35:21 INFO OpenLineageRunEventBuilder: Visiting query plan Optional[== Parsed Logical Plan ==
'CreateTable temp1, Overwrite
+- LogicalRDD [a#6L, b#7L], false
== Analyzed Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Optimized Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Physical Plan ==
Execute CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- **(1) Scan ExistingRDD[a#6L,b#7L]
] with input dataset builders [<function1>, <function1>, <function1>, <function1>, <function1>]
23/07/23 12:35:21 INFO OpenLineageRunEventBuilder: Visiting query plan Optional[== Parsed Logical Plan ==
'CreateTable temp1, Overwrite
+- LogicalRDD [a#6L, b#7L], false
== Analyzed Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Optimized Logical Plan ==
CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
== Physical Plan ==
Execute CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- **(1) Scan ExistingRDD[a#6L,b#7L]
] with output dataset builders [<function1>, <function1>, <function1>, <function1>, <function1>, <function1>, <function1>]
23/07/23 12:35:21 INFO CreateDataSourceTableAsSelectCommandVisitor: Matched io.openlineage.spark.agent.lifecycle.plan.CreateDataSourceTableAsSelectCommandVisitor<org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand,io.openlineage.client.OpenLineage$OutputDataset> to logical plan CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
23/07/23 12:35:21 INFO CreateDataSourceTableAsSelectCommandVisitor: Matched io.openlineage.spark.agent.lifecycle.plan.CreateDataSourceTableAsSelectCommandVisitor<org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand,io.openlineage.client.OpenLineage$OutputDataset> to logical plan CreateDataSourceTableAsSelectCommand temp1, Overwrite, [a, b]
+- LogicalRDD [a#6L, b#7L], false
23/07/23 12:35:21 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[10] at saveAsTable at NativeMethodAccessorImpl.java:0), which has no missing parents 23/07/23 12:35:21 ERROR EventEmitter: Could not emit lineage w/ exception io.openlineage.client.OpenLineageClientException: io.openlineage.spark.shaded.org.apache.http.client.ClientProtocolException at io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:105) at io.openlineage.client.OpenLineageClient.emit(OpenLineageClient.java:34) at io.openlineage.spark.agent.EventEmitter.emit(EventEmitter.java:71) at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:174) at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$onJobStart$9(OpenLineageSparkListener.java:153) at java.base/java.util.Optional.ifPresent(Optional.java:183) at io.openlineage.spark.agent.OpenLineageSparkListener.onJobStart(OpenLineageSparkListener.java:149) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:37) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1381) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96) Caused by: io.openlineage.spark.shaded.org.apache.http.client.ClientProtocolException at io.openlineage.spark.shaded.org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:187) at io.openlineage.spark.shaded.org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83) at io.openlineage.spark.shaded.org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:108) at io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:100) ... 20 more Caused by: io.openlineage.spark.shaded.org.apache.http.ProtocolException: Target host is not specified at io.openlineage.spark.shaded.org.apache.http.impl.conn.DefaultRoutePlanner.determineRoute(```
23/07/23 12:35:20 ERROR EventEmitter: Could not emit lineage w/ exception
io.openlineage.client.OpenLineageClientException: io.openlineage.spark.shaded.org.apache.http.client.ClientProtocolException
at io.openlineage.client.transports.HttpTransport.emit(HttpTransport.java:105)
at io.openlineage.client.OpenLineageClient.emit(OpenLineageClient.java:34)
at io.openlineage.spark.agent.EventEmitter.emit(EventEmitter.java:71)
at io.openlineage.spark.agent.lifecycle.SparkSQLExecutionContext.start(SparkSQLExecutionContext.java:77)
at io.openlineage.spark.agent.OpenLineageSparkListener.lambda$sparkSQLExecStart$0(OpenLineageSparkListener.java:99)
*Thread Reply:* That looks like your URL provided to OpenLineage is missing http:// or https:// in the front
*Thread Reply:* sorry how can i resolve this ? do i need to add this ? i just follow the guide step by step . You dont mention anywhere to add anything. You provide smth that
*Thread Reply:* really does not work out of the box
*Thread Reply:* anbd this is supposed to be a demo
*Thread Reply:* bumping e.g. to io.openlineage:openlineage_spark:0.29.2 seems to be fixing the issue
not sure why it stopped working for 0.12.0 but we’ll take a look and fix accordingly
*Thread Reply:* ...probably by bumping the version on this page 🙂
*Thread Reply:* thank you both for coming back to me , I bumped to 0.29 and i think that it now runs.Is this the expected output ?
23/07/24 08:43:55 INFO ConsoleTransport: {"eventTime":"2023_07_24T08:43:55.941Z","producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","schemaURL":"<https://openlineage.io/spec/2-0-0/OpenLineage.json#/$defs/RunEvent>","eventType":"COMPLETE","run":{"runId":"186c06c0_e79c_43cf_8bb7_08e1ab4c86a5","facets":{"spark.logicalPlan":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","_schemaURL":"<https://openlineage.io/spec/2-0-0/OpenLineage.json#/$defs/RunFacet>","plan":[{"class":"org.apache.spark.sql.execution.command.CreateDataSourceTableAsSelectCommand","num-children":1,"table":{"product-class":"org.apache.spark.sql.catalyst.catalog.CatalogTable","identifier":{"product-class":"org.apache.spark.sql.catalyst.TableIdentifier","table":"temp2","database":"default"},"tableType":{"product-class":"org.apache.spark.sql.catalyst.catalog.CatalogTableType","name":"MANAGED"},"storage":{"product_class":"org.apache.spark.sql.catalyst.catalog.CatalogStorageFormat","compressed":false,"properties":null},"schema":{"type":"struct","fields":[]},"provider":"parquet","partitionColumnNames":[],"owner":"","createTime":1690188235517,"lastAccessTime":-1,"createVersion":"","properties":null,"unsupportedFeatures":[],"tracksPartitionsInCatalog":false,"schemaPreservesCase":true,"ignoredProperties":null},"mode":null,"query":0,"outputColumnNames":"[a, b]"},{"class":"org.apache.spark.sql.execution.LogicalRDD","num_children":0,"output":[[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num-children":0,"name":"a","dataType":"long","nullable":true,"metadata":{},"exprId":{"product-class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":12,"jvmId":"173725f4_02c4_4174_9d18_3a61aa311d62"},"qualifier":[]}],[{"class":"org.apache.spark.sql.catalyst.expressions.AttributeReference","num_children":0,"name":"b","dataType":"long","nullable":true,"metadata":{},"exprId":{"product_class":"org.apache.spark.sql.catalyst.expressions.ExprId","id":13,"jvmId":"173725f4-02c4-4174-9d18-3a61aa311d62"},"qualifier":[]}]],"rdd":null,"outputPartitioning":{"product_class":"org.apache.spark.sql.catalyst.plans.physical.UnknownPartitioning","numPartitions":0},"outputOrdering":[],"isStreaming":false,"session":null}]},"spark_version":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","_schemaURL":"<https://openlineage.io/spec/2-0-0/OpenLineage.json#/$defs/RunFacet>","spark-version":"3.1.2","openlineage_spark_version":"0.29.2"}}},"job":{"namespace":"default","name":"sample_spark.execute_create_data_source_table_as_select_command","facets":{}},"inputs":[],"outputs":[{"namespace":"file","name":"/home/jovyan/spark-warehouse/temp2","facets":{"dataSource":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","_schemaURL":"<https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet>","name":"file","uri":"file"},"schema":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","_schemaURL":"<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>","fields":[{"name":"a","type":"long"},{"name":"b","type":"long"}]},"symlinks":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","_schemaURL":"<https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet>","identifiers":[{"namespace":"/home/jovyan/spark-warehouse","name":"default.temp2","type":"TABLE"}]},"lifecycleStateChange":{"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/integration/spark>","_schemaURL":"<https://openlineage.io/spec/facets/1-0-0/LifecycleStateChangeDatasetFacet.json#/$defs/LifecycleStateChangeDatasetFacet>","lifecycleStateChange":"CREATE"}},"outputFacets":{}}]}
? Also i then proceeded to run
docker run --network spark_default -p 3000:3000 -e MARQUEZ_HOST=marquez-api -e MARQUEZ_PORT=5000 --link marquez-api:marquez-api marquezproject/marquez-web:0.19.1
but the page is empty
*Thread Reply:* You'd need to set up spark.openlineage.transport.url to send OpenLineage events to Marquez
*Thread Reply:* where n how can i do this ?
*Thread Reply:* do i need to edit the conf ?
*Thread Reply:* yes, in the spark conf
*Thread Reply:* what this url should be ?
*Thread Reply:* http://localhost:3000/ ?
*Thread Reply:* That depends how you ran Marquez, but looking at your screenshot UI is at 3000, I guess API would be at 5000
*Thread Reply:* as that's default in Marquez docker-compose
*Thread Reply:* i cannot see spark conf
*Thread Reply:* is it in there or do i need to create it ?
*Thread Reply:* Is something like ```from pyspark.sql import SparkSession
spark = (SparkSession.builder.master('local') .appName('samplespark') .config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener') .config('spark.jars.packages', 'io.openlineage:openlineagespark:0.29.2') .config('spark.openlineage.transport.url', 'http://marquez:5000') .config('spark.openlineage.transport.type', 'http') .getOrCreate())``` not working?
*Thread Reply:* so i cannot see any details of the job

*Thread Reply:* yes i will tell you
*Thread Reply:* For the docker command that I used, I updated the marquez-web version to 0.40.0 and I also updated the Marquez_host which I am not sure if I have to or not. The UI is running but not showing anything docker run --network spark_default -p 3000:3000 -e MARQUEZ_HOST=localhost -e MARQUEZ_PORT=5000 --link marquez-api:marquez-api marquez/marquez-web:0.40.0
*Thread Reply:* is because you are running this command right
*Thread Reply:* yes thats it
*Thread Reply:* you need 0.40
*Thread Reply:* and there is a lot of stuff
*Thread Reply:* you need rto chwange
*Thread Reply:* in the Docker
*Thread Reply:* so the spark
*Thread Reply:* version
*Thread Reply:* the python
*Thread Reply:* version: "3.10" services: notebook: image: jupyter/pyspark-notebook:spark-3.4.1 ports: - "8888:8888" volumes: - ./docker/notebooks:/home/jovyan/notebooks - ./build:/home/jovyan/openlineage links: - "api:marquez" depends_on: - api
Marquez as an OpenLineage Client
api: image: marquezproject/marquez containername: marquez-api ports: - "5000:5000" - "5001:5001" volumes: - ./docker/wait-for-it.sh:/usr/src/app/wait-for-it.sh links: - "db:postgres" dependson: - db entrypoint: [ "./wait-for-it.sh", "db:5432", "--", "./entrypoint.sh" ]
db: image: postgres:12.1 containername: marquez-db ports: - "5432:5432" environment: - POSTGRESUSER=postgres - POSTGRESPASSWORD=password - MARQUEZDB=marquez - MARQUEZUSER=marquez - MARQUEZPASSWORD=marquez volumes: - ./docker/init-db.sh:/docker-entrypoint-initdb.d/init-db.sh # Enables SQL statement logging (see: https://www.postgresql.org/docs/12/runtime-config-logging.html#GUC-LOG-STATEMENT) # command: ["postgres", "-c", "log_statement=all"]

*Thread Reply:* this is hopw mine looks
*Thread Reply:* it is all tested and letest version
*Thread Reply:* postgres does not work beyond 12
*Thread Reply:* if you run this docker-compose up
*Thread Reply:* the notebooks
*Thread Reply:* are 10 faster
*Thread Reply:* and give no errors
*Thread Reply:* also you need to update other stuff
*Thread Reply:* such as
*Thread Reply:* dont run what is in the docs
*Thread Reply:* but run what is in github
*Thread Reply:* run in your notebooks what is in here
*Thread Reply:* ```from pyspark.sql import SparkSession
spark = (SparkSession.builder.master('local') .appName('samplespark') .config('spark.jars.packages', 'io.openlineage:openlineagespark:1.1.0') .config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener') .config('spark.openlineage.transport.url', 'http://{openlineage.client.host}/api/v1/namespaces/spark_integration/') .getOrCreate())```
*Thread Reply:* the dont update documentation
*Thread Reply:* it took me 4 weeks to get here
is this a known error ? does anyone know how to debug this ?
Hi,
Using Marquez. I tried to get the dataset version through two apis.
First:
http://host/api/v1/namespaces/{namespace}/datasets/{dataset}
It will include a currentVersion in the response.
Then:
http://host/api/v1/namespaces/{namespace}/datasets/{dataset}/versions/{currentVersion}
But the version used here refers to the "version" column in table dataset_versions. Not the primary key "uuid". Which leads to 404 not found.
I checked other apis but seemed that there are no other way to get the version through "currentVersion".
Any help?
*Thread Reply:* Like I want to change the facets of a specific dataset.
*Thread Reply:* @Willy Lulciuc do you have any idea? 🙂
*Thread Reply:* I solved this by adding a new job which outputs to the same dataset. This ended up in a newer dataset version.
*Thread Reply:* @Steven great to hear that you solved the issue! but there are some minor logical inconsistencies that we’d like to address with versioning (for both datasets and jobs) in Marquez. The tl;dr is the version column wasn’t meant to be used externally, but internally within Marquez. The issue is “minor” as it’s more of a pointer thing. We’ll be addressing soon. For some background, you can look at:
• https://github.com/MarquezProject/marquez/issues/2071
• https://github.com/MarquezProject/marquez/pull/2153
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
Hi, Are there any keys to set in marquez.yaml to skip db initialization and use existing db? I am deploying the marquez client on k8s client, which uses a cloud postgres. Every time I restart the marquez deployment I have to drop all those tables otherwise it will raise table already exists ERROR
*Thread Reply:* @Steven ahh very good point, it’s technically not “error” in the true sense, but annoying nonetheless. I think you’re referencing the init container in the Marquez helm chart? https://github.com/MarquezProject/marquez/blob/main/chart/templates/marquez/deployment.yaml#L37
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* hmm, actually what raises the error you’re referencing? the Maruez http server?
*Thread Reply:* > Every time I restart the marquez deployment I have to drop all those tables otherwise it will raise table already exists ERROR This shouldn’t be an error. I’m trying to understand the scenario in which this error is thrown (any info is helpful). We use flyway to manage our db schema, but you may have gotten in an odd state somehow
For Databricks notebooks, does the Spark listener work without any notebook changes? (I see that Azure Databricks -> purview needs no changes, but I’m not sure if that applies to anywhere….e.g. if I have an existing databricks notebook, and I add a spark listener, can I get column-level lineage? or do I need to change my notebook to use openlineage libraries, like I do with an arbitrary Python script?)
*Thread Reply:* Nope, one should modify the cluster as per doc <https://openlineage.io/docs/integrations/spark/quickstart_databricks> but no changes in notebook are required.
*Thread Reply:* Right, great, that’s exactly what I was hoping 😄
@channel
We released OpenLineage 0.30.1, including:
Added
• Flink: support Iceberg sinks #1960 @pawel-big-lebowski
• Spark: column-level lineage for merge into on delta tables #1958 @pawel-big-lebowski
• Spark: column-level lineage for merge into on Iceberg tables #1971 @pawel-big-lebowski
• Spark: add supprt for Iceberg REST catalog #1963 @juancappi
• Airflow: add possibility to force direct-execution based on environment variable #1934 @mobuchowski
• SQL: add support for Apple Silicon to openlineage-sql-java #1981 @davidjgoss
• Spec: add facet deletion #1975 @julienledem
• Client: add a file transport #1891 @alexandre bergere
Changed
• Airflow: do not run plugin if OpenLineage provider is installed #1999 @JDarDagran
• Python: rename config to config_class #1998 @mobuchowski
Plus test improvements, docs changes, bug fixes and more.
Thanks to all the contributors, including new contributors @davidjgoss, @alexandre bergere and @Juan Manuel Cappi!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/0.30.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.29.2...0.30.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

Hello everyone! I’m part of a team trying to integrate OpenLineage and Marquez with multiple tools in our ecosystem. Integration with Spark and Iceberg was fairly easy with the listener you guys developed. We are now trying to integrate with Ray and we are having some trouble there. I was wondering if anybody has tried any work in that direction, so we can chat and exchange ideas. Thank you!
*Thread Reply:* This is the first I’ve heard of someone trying to do this, but others have tried getting lineage from pandas. There isn’t support for this currently, but this thread contains a link to an issue that might be helpful: https://openlineage.slack.com/archives/C01CK9T7HKR/p1689850134978429?thread_ts=1689688067.729469&cid=C01CK9T7HKR.
 }
}
*Thread Reply:* Thank you for your response. We have implemented the “manual way” of emitting events with python OL client. We are now looking for a more automated way, so that updates to the scripts that run in Ray are minimal to none
*Thread Reply:* If you're actively using Ray, then you know way more about it than me, or probably any other OL contributor 🙂 I don't know how it works or is deployed, but I would recommend checking if there's robust way of being notified in the runtime about processing occuring there.
*Thread Reply:* Thank you for the tip. That’s the kind of details I’m looking for, but couldn’t find yet

Hi, does anyone have experience integrating OpenLineage and Marquez with Keboola? I am new to OpenLineage and struggling with the KBC component configuration.
*Thread Reply:* @Martin Fiser can you share any resources or pointers that might be helpful?
*Thread Reply:* Hi, apologies - vacation period has hit m. However here are the resources:
API endpoint: https://app.swaggerhub.com/apis-docs/keboola/job-queue-api/1.3.4#/Jobs/getJobOpenApiLineage|job-queue-api | 1.3.4 | keboola | SwaggerHub Dedicated component to push data into openlineage(Marquez instance): https://components.keboola.com/components/keboola.wr-openlineage|OpenLineage data destination | Keboola Developer Portal

Hi folks. I'm looking to find the complete spec in openapi format. For example, if I want to find the complete spec of 1.0.5 , where would I find that? I've looked here: https://openlineage.io/apidocs/openapi/ however when I download the spec, things are missing, specifically the facets. This makes it difficult to generate clients / backend interfaces from the (limited) openapi spec.

*Thread Reply:* +1, I could also really use this!
*Thread Reply:* Found a way: you download it as json in the above link (“Download OpenAPI specification”), then if you copy paste it to editor.swagger.io it asks f you want to convert to yaml :)
*Thread Reply:* Whilst that works, it isn't complete. The issue is that the "facets" are not resolved. Exploring the website repository (https://github.com/OpenLineage/website/tree/main/static/spec) shows that facets aren't published alongside the spec, beyond 1.0.1 - which means its hard to know which revisions of the facets belong to which version of the spec.
*Thread Reply:* Good point! Would be good if we could clarify how to get the full spec, in that case
*Thread Reply:* Granted. If the spec follows backwards compatible evolution rules, then this shouldn't be a problem, i.e., new fields must be optional, you can not remove existing fields, you can not modify existing fields, etc.
*Thread Reply:* We don't have facets with newer version than 1.1.0
*Thread Reply:* @Damien Hawes we've moved to merge docs and website repos here: https://github.com/OpenLineage/docs
*Thread Reply:* > Would be good if we could clarify how to get the full spec, in that case Is using https://github.com/OpenLineage/OpenLineage/tree/main/spec not enough? We have separate files with facets definition to be able to evolve them separetely from main spec
*Thread Reply:* @Maciej Obuchowski - thanks for your input. I understand the desire to want to evolve the facets independently from the main spec, yet I keep running into a mental wall.
If I say, 'My application is compatible with OpenLineage 1.0.5' - what does that mean exactly? Does it mean that I am at least compatible with the base definition of RunEvent and its nested components, but not facets?
That's what I'm finding difficult to wrap my head around. Right now, I can not define (for my own sake and the sake of my org) what 'OpenLineage 1.0.5' means.
When I read the Marquez source code, I see that they state they implement 1.0.5, but again, it isn't clear what that completely entails.
I hope I am making sense.
*Thread Reply:* If I approach this from a conventional software engineering standpoint, where I provide a library to my consumers. The library has a version associated with it, and that version encompasses all the objects located within that particular library. If I release a new version of my library, it implies that some form of evolution has happened. Whether it is a bug fix, a documentation change, or evolving the API of my objects it means something has changed and the new version is there to indicate that.
*Thread Reply:* Yes - it means you can read and understand base spec. Facets are completely optional - reading them might provide you additional information, but you as a event consumer need to define what you do with them. Basically, the needs can be very different between consumers, spec should not define behavior of a consumer.
*Thread Reply:* OK. Thanks for the clarification. That clears things up for me.
This month’s issue of OpenLineage News was just sent out. Please
Hello, I request OpenLineage release, especially for two things: • Snowflake/HTTP/Airflow bugfix: https://github.com/OpenLineage/OpenLineage/pull/2025 • Spec: removing refs from core: https://github.com/OpenLineage/OpenLineage/pull/1997 Three approvals from committers will authorize release. @Michael Robinson
*Thread Reply:* Thanks, @Maciej Obuchowski
*Thread Reply:* Thanks, all. The release is authorized and will be initiated within two business days.
@channel
We released OpenLineage 1.0.0, featuring static lineage capability!
Added:
• Airflow: convert lineage from legacy File definition #2006 @Maciej Obuchowski
Removed:
• Spec: remove facet ref from core #1997 @JDarDagran
Changed
• Airflow: change log level to DEBUG when extractor isn’t found #2012 @kaxil
• Airflow: make sure we cannot fail in thread despite direct execution #2010 @Maciej Obuchowski
Plus test improvements, docs changes, bug fixes and more.
*See prior releases for additional changes related to static lineage.
Thanks to all the contributors, including new contributors @kaxil and @Mars Lan!
*Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.0.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/0.30.1...1.0.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

hi folks! so happy to see that static lineage is making its way through OL. one question: is the OpenAPI spec up to date? https://openlineage.io/apidocs/openapi/ IIUC, proposal 1837 says that JobEvent and DatasetEvent can be emitted independently from RunEvents now, but it's not clear how this affected the spec.
I see the Python client https://pypi.org/project/openlineage-python/1.0.0/ includes these changes already, so I assume I can go ahead and use it already? (I'm also keeping tabs on https://github.com/MarquezProject/marquez/issues/2544)
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* I think the apidocs are not up to date 🙂
*Thread Reply:* https://openlineage.io/spec/2-0-2/OpenLineage.json has the newest spec
*Thread Reply:* thanks for the pointer @Maciej Obuchowski
*Thread Reply:* Also working on updating the apidocs
*Thread Reply:* The API docs are now up to date @Juan Luis Cano Rodríguez! Thank you for raising this issue.
@channel If you can, please join us in San Francisco for a meetup at Astronomer on August 30th at 5:30 PM PT. On the agenda: a presentation by special guest @John Lukenoff plus updates on the Airflow Provider, static lineage, and more. Food will be provided, and all are welcome. Please https://www.meetup.com/meetup-group-bnfqymxe/events/295195280/?utmmedium=referral&utmcampaign=share-btnsavedeventssharemodal&utmsource=link|RSVP to let us know you’re coming.


Hey, I hope this is the right channel for this kind of question - I’m running a tests to integrate Airflow (2.4.3) with Marquez (Openlineage 0.30.1). Currently, I’m testing the postgres operator and for some reason queries like “Copy” and “Unload” are being sent as events, but doesn’t appear in the graph. Any idea how to solve it?
You can see attached
- The graph of an airflow DAG with all the tasks beside the copy and unload.
- The graph with the unload task that isn’t connected to the other flow.
*Thread Reply:* I think our underlying SQL parser does not hancle the Postgres versions of those queries
*Thread Reply:* Can you post the (anonymized?) queries?
*Thread Reply:* for example
copy bi.marquez_test_2 from '******' iam_role '**********' delimiter as '^' gzi
*Thread Reply:* @Zahi Fail iam_role suggests you want redshift version of this supported, not Postgres one right?
*Thread Reply:* @Maciej Obuchowski hey, actually I tried both Postgres and Redshift to S3 operators. Both of them sent a new event through OL to Marquez, and still wasn’t part of the entire flow.

Hey team! 👋
We were exploring open-lineage and had a couple of questions:
- Does open-lineage support presto-sql?
- Do we have any docs/benchmarks on query coverage (inner joins, subqueries, etc) & source/sink coverage (spark.read from JDBC, Files etc) for spark-sql?
- Can someone point to the code where we currently parse the input/output facets from the spark integration (like sql queries / transformations) and if it's extendable?
*Thread Reply:* Hey @Athitya Kumar,
- For parsing SQL queries, we're using sqlparser-rs (https://github.com/sqlparser-rs/sqlparser-rs) which already has great coverage of sql syntax and supports different dialects. it's open source project and we already did contribute to it for snowflake dialect.
- We don't have such a benchmark, but if you like, you could contribute and help us providing such. We do support joins, subqueries, iceberg and delta tables, jdbc for Spark and much more. Everything we do support, is covered in our tests.
- Not sure if got it properly. Marquez is our reference backend implementation which parses all the facets and stores them in relational db in a relational manner (facets, jobs, datasets and runs in separate tables).
*Thread Reply:* For (3), I was referring to where we call the sqlparser-rs in our spark-openlineage event listener / integration; and how customising/improving them would look like
*Thread Reply:* sqlparser-rs is a rust libary and we bundle it within iface-java (https://github.com/OpenLineage/OpenLineage/blob/main/integration/sql/iface-java/src/main/java/io/openlineage/sql/SqlMeta.java). It's capable of extracting input/output datasets, column lineage information from SQL
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* and this is Spark code that extracts it from JdbcRelation -> https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/[…]ge/spark/agent/lifecycle/plan/handlers/JdbcRelationHandler.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I think 3 question relates generally to Spark SQL handling, rather than handling JDBC connections inside Spark, right?
*Thread Reply:* Yup, both actually. Related to getting the JDBC connection info in the input/output facet, as well as spark-sql queries we do on that JDBC connection
*Thread Reply:* For Spark SQL - it's translated to Spark's internal query LogicalPlan. We take that plan, and process it's nodes. From root node we can take output dataset, from leaf nodes we can take input datasets, and inside internal nodes we track columns to extract column-level lineage. We express those (table-level) operations by implementing classes like QueryPlanVisitor
You can extend that, for example for additional types of nodes that we don't support by implementing your own QueryPlanVisitor, and then implementing OpenLineageEventHandlerFactory and packaging this into a .jar deployed alongside OpenLineage jar - this would be loaded by us using Java's ServiceLoader .
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Maciej Obuchowski @Paweł Leszczyński - Thanks for your responses! I had a follow-up query regarding the sqlparser-rs that's used internally by open-lineage: we see that these are the SQL dialects supported by sqlparser-rs here doesn't include spark-sql / presto-sql dialects which means they'd fallback to generic dialect:
"--ansi" => Box::new(AnsiDialect {}),
"--bigquery" => Box::new(BigQueryDialect {}),
"--postgres" => Box::new(PostgreSqlDialect {}),
"--ms" => Box::new(MsSqlDialect {}),
"--mysql" => Box::new(MySqlDialect {}),
"--snowflake" => Box::new(SnowflakeDialect {}),
"--hive" => Box::new(HiveDialect {}),
"--redshift" => Box::new(RedshiftSqlDialect {}),
"--clickhouse" => Box::new(ClickHouseDialect {}),
"--duckdb" => Box::new(DuckDbDialect {}),
"--generic" | "" => Box::new(GenericDialect {}),
Any idea on how much coverage generic dialect provides for spark-sql / how different they are etc?
<a href="https://github.com/sqlparser-rs/sqlparser-rs">sqlparser-rs/sqlparser-rs</a>
*Thread Reply:* spark-sql integration is based on spark LogicalPlan's tree. Extracting input/output datasets from tree nodes which is more detailed than sql parsing
*Thread Reply:* I think presto/trino dialect is very standard - there shouldn't be any problems with regular queries
*Thread Reply:* @Paweł Leszczyński - Got it, and would you be able to point me to where within the openlineage-spark integration do we:
- provide the Spark Logical Plan / query to sqlparser-rs
- get the output of sqlparser-rs (parsed query AST) & stitch back the inputs/outputs in the open-lineage events?
*Thread Reply:* For example, we'd like to understand which dialectname of sqlparser-rs would be used in which scenario by open-lineage and what're the interactions b/w open-lineage & sqlparser-rs
*Thread Reply:* @Paweł Leszczyński - Incase you missed the above messages ^
*Thread Reply:* Sqlparser-rs is used within Spark integration only for spark jdbc queries (queries to external databases). That's the only scenario. For spark.sql(...) , instead of SQL parsing, we rely on a logical plan of a job and extract information from it. For jdbc queries, that user sqlparser-rs, dialect is extracted from url:
https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/shared/src/main/java/io/openlineage/spark/agent/util/JdbcUtils.java#L69
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hi.. Is column lineage available for spark version 2.4.0?
*Thread Reply:* No, it's not.
*Thread Reply:* Is it only available for spark version 3+?

Hi, Will really appreciate if I can learn how community have been able to harness spark integration. In our testing where a spark application writes to S3 multiple times (different location), OL generates the same job name for all writes (namepsacename.executeinsertintohadoopfsrelation_command ) rendering the OL graph final output less helpful. Say for example if I have series of transformation/writes 5 times , in Lineage graph we are just seeing last 1. There is an open bug and hopefully will be resolved soon.
Curious how much is adoption of OL spark integration in presence of that bug, as generating same name for a job makes it less usable for anything other than trivial one output application.
Example from 2 write application EXPECTED : first produce weather dataset and the subsequent produce weather40. (generated/mocked using 2 spark app). (1st image) ACTUAL OL : weather40. see only last one. (2nd image)
Will really appreciate community guidance as in how successful they have been in utilizing spark integration (vanilla not Databricks) . Thank you
Expected. vs Actual.
@channel This month’s TSC meeting is this Thursday, August 10th at 10:00 a.m. PT. On the tentative agenda: • announcements • recent releases • Airflow provider progress update • OpenLineage 1.0 overview • open discussion • more (TBA) More info and the meeting link can be found on the website. All are welcome! Also, feel free to reply or DM me with discussion topics, agenda items, etc.

I can’t see output when saveAsTable 100+ columns in spark. Any help or ideas for issue? Really thanks.
*Thread Reply:* Does this work with similar jobs, but with small amount of columns?
*Thread Reply:* thanks for reply @Maciej Obuchowski yes it works for small amount of columns but not work in big amount of columns
*Thread Reply:* one more question: how much data the jobs approximately process and how long does the execution take?
*Thread Reply:* ah… it’s like 20 min ~ 30 min various data size is like 2000,0000 rows with columns 100 ~ 1000
*Thread Reply:* that's interesting. we could prepare integration test for that. 100 cols shouldn't make a difference
*Thread Reply:* honestly sorry for typo its 1000 columns
*Thread Reply:* i check it works good for small numbers of columns
*Thread Reply:* if it's 1000, then maybe we're over event size - event is too large and backend can't accept that
*Thread Reply:* maybe debug logs could tell us something
*Thread Reply:* i’ll do spark.sparkContext.setLogLevel("DEBUG") ing
*Thread Reply:* are there any errors in the logs? perhaps pivoting uses contains nodes in SparkPlan that we don't support yet
*Thread Reply:* did you check pivoting that results in less columns?
*Thread Reply:* @추호관 would also be good to disable logicalPlan facet:
spark.openlineage.facets.disabled: [spark_unknown;spark.logicalPlan]
in spark conf
*Thread Reply:* got it can’t we do in python config
.config("spark.dynamicAllocation.enabled", "true") \
.config("spark.dynamicAllocation.initialExecutors", "5") \
.config("spark.openlineage.facets.disabled", [spark_unknown;spark.logicalPlan]
*Thread Reply:* .config("spark.dynamicAllocation.enabled", "true") \
.config("spark.dynamicAllocation.initialExecutors", "5") \
.config("spark.openlineage.facets.disabled", "[spark_unknown;spark.logicalPlan]"
*Thread Reply:* ah… there are no errors nor debug level issue successfully Registered listener ìo.openlineage.spark.agent.OpenLineageSparkListener
*Thread Reply:* maybe df.groupBy(some column).pivot(some_column).agg(**agg_cols) is not supported
*Thread Reply:* oh.. interesting spark.openlineage.facets.disabled this option gives me output when eventType is START “eventType”: “START” “outputs”: [ … columns …. ]
*Thread Reply:* Yes
"spark.openlineage.facets.disabled", "[spark_unknown;spark.logicalPlan]" <- this option gives output when eventType is START but not give output bunches of columns when that config is not set
*Thread Reply:* this option prevents logicalPlan being serialized and sent as a part of Openlineage event which included in one of the facets
*Thread Reply:* possibly, serializing logicalPlans, in case of pivots, leads to size of the events that are not acceptable
*Thread Reply:* Ah… so you mean pivot makes serializing logical plan not availble for generating event because of size. and disable logical plan with not serializing make availabe to generate event cuz not serialiize logical plan made by pivot
Can we overcome this
*Thread Reply:* we've seen such issues for some plans some time ago
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* by excluding some properties from plan to be serialized
*Thread Reply:* here https://github.com/OpenLineage/OpenLineage/blob/c3a5211f919c01870a7f79f48588177a9b[…]io/openlineage/spark/agent/lifecycle/LogicalPlanSerializer.java we exclude certain classes
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* AH…. excluded properties cause ignore logical plan’s of pivointing
*Thread Reply:* you can start with writing a failing test here -> https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/tes[…]/openlineage/spark/agent/lifecycle/SparkReadWriteIntegTest.java
then you can try to debug logical plan trying to find out what should be excluded from it when it's being serialized. Even, if you find this difficult, a failing integration test is super helpful to let others help you in that.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* okay i would look into and maybe pr thanks
*Thread Reply:* Can I ask if there are any suspicious properties?
*Thread Reply:* sure
*Thread Reply:* Thanks I would also try to find the property too
Hi guys, I've a generic sql-parsing doubt... what would be the recommended way (if any) to check for sql similarity? I understand that most sql parsers parse the query into an AST, but are there any well known ways to measure semantic similarities between 2 or more ASTs? Just curious lol... Any ideas appreciated! Thanks!

*Thread Reply:* Hi @Anirudh Shrinivason, I think I would take a look on this https://sqlglot.com/sqlglot/diff.html
*Thread Reply:* Hey @Guy Biecher Yeah I was looking at this... but it seems to calculate similarity from a more textual context, as opposed to a more semantic one...
eg: SELECT ** FROM TABLE_1 and SELECT col1,col2,col3 FROM TABLE_1 could be the same semantic query, but sqlglot would give diffs in the ast because its textual...
*Thread Reply:* I totally get you. In such cases without the metadata of the TABLE_1, it's impossible what I would do I would replace all ** before you use the diff function.
*Thread Reply:* Yeah I was thinking about the same... But the more nested and complex your queries get, the harder it'll become to accurately pre-process before running the ast diff too... But yeah that's probably the approach I'd be taking haha... Happy to discuss and learn if there are better ways to doing this

dear all, I have some novice questions. I put them in separate messages for clarity. 1st Question: I understand from the examples in the documentation that the main lineage events are RunEvent's, which can contain link to Run ID, Job ID, Dataset ID (I see they are RunEvent because they have EventType, correct?). However, the main openlineage json object contains also JobEvent and DatasetEvent. When are JobEvent and DatasetEvent supposed to be used in the workflow? Do you have relevant examples? thanks!
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hey @Luigi Scorzato! You can read about these 2 event types in this blog post: https://openlineage.io/blog/static-lineage
*Thread Reply:* we’ll work on getting the documentation improved to clarify the expected use cases for each event type. this is a relatively new addition to the spec.
*Thread Reply:* this sounds relevant for my 3rd question, doesn't it? But I do not see scheduling information among the use cases, am I wrong?
*Thread Reply:* you’re not wrong, these 2 events were not designed for runtime lineage, but rather “static” lineage that gets emitted after the fact
2nd Question. I see that the input dataset appears in the RunEvent with EventType=START, the output dataset appears in the RunEvent with EventType=COMPLETE only, the RunEvent with EventType=RUNNING has no dataset attached. This makes sense for ETL jobs, but for streaming (e.g. Flink), the run could run very long and never terminate with a COMPLETE. On the other hand, emitting all the info about the output dataset in every RUNNING event would be far too verbose. What is the recommended set up in this case? TLDR: what is the recommended configuration of the frequency and data model of the lineage events for streaming systems like Flink?
*Thread Reply:* great question! did you get a chance to look at the current Flink integration?
*Thread Reply:* to be honest, I only quickly went through this and I did not identfy what I needed. Can you please point me to the relevant section?
*Thread Reply:* here’s an example START event for Flink: https://github.com/OpenLineage/OpenLineage/blob/main/integration/flink/src/test/resources/events/expected_kafka.json
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* or a checkpoint (RUNNING) event: https://github.com/OpenLineage/OpenLineage/blob/main/integration/flink/src/test/resources/events/expected_kafka_checkpoints.json
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* generally speaking, you can see the execution contexts that invoke generation of OL events here: https://github.com/OpenLineage/OpenLineage/blob/main/integration/flink/src/main/ja[…]/openlineage/flink/visitor/lifecycle/FlinkExecutionContext.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* thank you! So, if I understand correctly, the key is that even eventType=START, admits an output datasets. Correct? What determines how often are the eventType=RUNNING emitted?
*Thread Reply:* now I see, RUNNING events are emitted on onJobCheckpoint
3rd Question: I am looking for information about the time when the next run should start, in case of scheduled jobs. I see that the Run Facet has a Nominal Time Facet, but -- if I understand correctly -- it refers to the current run, so it is always emitted after the fact. Is the Nominal Start Time of the next run available somewhere? If not, where do you recommend to add it as a custom field? In principle, it belongs to the Job object, but would that maybe cause an undesirable fast change in the Job object?
*Thread Reply:* For Airflow, this is part of the AirflowRunFacet, here: https://github.com/OpenLineage/OpenLineage/blob/81372ca2bc2afecab369eab4a54cc6380dda49d0/integration/airflow/facets/AirflowRunFacet.json#L100
For other orchestrators / schedulers, that would depend..

Hi Team, Question regarding Databricks OpenLineage init script, is the path /mnt/driver-daemon/jars common to all the clusters? or its unique to each cluster? https://github.com/OpenLineage/OpenLineage/blob/81372ca2bc2afecab369eab4a54cc6380d[…]da49d0/integration/spark/databricks/open-lineage-init-script.sh
*Thread Reply:* I might be wrong, but I believe it's unique for each cluster - the common part is dbfs\.
*Thread Reply:* dbfs is mounted to a databricks workspace which can run multiple clusters. so i think, it's common.
Worth mentioning: init-scripts located in dbfs are becoming deprecated next month and we plan moving them into workspaces.
*Thread Reply:* yes, the init scripts are moved at workspace level.
Hi @Paweł Leszczyński Will really aprecaite if you please let me know once this PR is good to go. Will love to test in our environment : https://github.com/OpenLineage/OpenLineage/pull/2036. Thank you for all your help.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* great to hear. I still need some time as there are few corner cases. For example: what should be the behaviour when alter table rename is called 😉 But sure, you can test it if you like. ci is failing on integration tests but ./gradlew clean build with unit tests are fine.
*Thread Reply:* @GitHubOpenLineageIssues Feel invited to join todays community and advocate for the importance of this issue. Such discussions are extremely helpful in prioritising backlog the right way.

Hi Team, I'm doing a POC with open lineage to extract column lineage of Spark. I'm using it on databricks notebook. I'm facing a issue where I,m trying to get the column lineage in a join involving external tables on s3. The lineage that is being extracted is returning on base path of the table ie on the s3 file path and not on the corresponding tables. Is there a way to extract/map columns of output to the columns of base tables instead of storage location.
*Thread Reply:* Query:
INSERT INTO test.merchant_md
(Select
m.`id`,
m.name,
m.activated,
m.parent_id,
md.contact_name,
md.contact_email
FROM
test.merchants_0 m
LEFT JOIN merchant_details md ON m.id = md.merchant_id
WHERE
m.created_date > '2023-08-01')
*Thread Reply:* "columnLineage":{
"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.30.1/integration/spark>",
"_schemaURL":"<https://openlineage.io/spec/facets/1-0-1/ColumnLineageDatasetFacet.json#/$defs/ColumnLineageDatasetFacet>",
"fields":{
"merchant_id":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchants",
"field":"id"
}
]
},
"merchant_name":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchants",
"field":"name"
}
]
},
"activated":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchants",
"field":"activated"
}
]
},
"parent_id":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchants",
"field":"parent_id"
}
]
},
"contact_name":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchant_details",
"field":"contact_name"
}
]
},
"contact_email":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchant_details",
"field":"contact_email"
}
]
}
}
},
"symlinks":{
"_producer":"<https://github.com/OpenLineage/OpenLineage/tree/0.30.1/integration/spark>",
"_schemaURL":"<https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet>",
"identifiers":[
{
"namespace":"/warehouse/test.db",
"name":"test.merchant_md",
"type":"TABLE"
}
*Thread Reply:* "contact_name":{
"inputFields":[
{
"namespace":"<s3a://datalake>",
"name":"/test/merchant_details",
"field":"contact_name"
}
]
}
This is returning mapping from the s3 location on which the table is created.
Hey, I’m running Spark application (spark version 3.4) with OL integration. I changed spark to use “debug” level, and I see the OL events with the below message: “Emitting lineage completed successfully:”
With all the above, I can’t see the event in Marquez.
Attaching the OL configurations. When changing the OL-spark version to 0.6.+, I do see event created in Marquez with only “Start” status (attached below).
The OL-spark version is matching the Spark version? Is there a known issues with the Spark / OL versions ?
*Thread Reply:* > OL-spark version to 0.6.+ This OL version is ancient. You can try with 1.0.0
I think you're hitting this issue which duplicates jobs: https://github.com/OpenLineage/OpenLineage/issues/1943
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* I haven’t mentioned that I tried multiple OL versions - 1.0.0 / 0.30.1 / 0.6.+ … None of them worked for me. @Maciej Obuchowski
*Thread Reply:* @Zahi Fail understood. Can you provide sample job that reproduces this behavior, and possibly some logs?
*Thread Reply:* If you can, it might be better to create issue at github and communicate there.
*Thread Reply:* Before creating an issue in GIT, I wanted to check if my issue only related to versions compatibility..
This is the sample of my test: ```from pyspark.sql import SparkSession from pyspark.sql.functions import col
spark = SparkSession.builder\ .config('spark.jars.packages', 'io.openlineage:openlineage_spark:1.0.0') \ .config('spark.extraListeners', 'io.openlineage.spark.agent.OpenLineageSparkListener') \ .config('spark.openlineage.host', 'http://localhost:9000') \ .config('spark.openlineage.namespace', 'default') \ .getOrCreate()
spark.sparkContext.setLogLevel("DEBUG")
csv_file = location.csv
df = spark.read.format("csv").option("header","true").option("sep","^").load(csv_file)
df = df.select("campaignid","revenue").groupby("campaignid").sum("revenue").show()``` Part of the logs with the OL configurations and the processed event
*Thread Reply:* try spark.openlineage.transport.url instead of spark.openlineage.host
*Thread Reply:* and possibly link the doc where you've seen spark.openlineage.host 🙂
*Thread Reply:* https://openlineage.io/blog/openlineage-spark/
*Thread Reply:* changing to “spark.openlineage.transport.url” didn’t make any change
*Thread Reply:* do you see the ConsoleTransport log? it suggests Spark integration did not register that you want to send events to Marquez
*Thread Reply:* let's try adding spark.openlineage.transport.type to http
*Thread Reply:* Cool 🙂 however it should not require it if you provide spark.openlineage.transport.url - I'll create issue for debugging that.
@channel This month’s TSC meeting is tomorrow! All are welcome. https://openlineage.slack.com/archives/C01CK9T7HKR/p1691422200847979
While using the spark integration, we're unable to see the query in the job facet for any spark-submit - is this a known issue/limitation, and can someone point to the code where this is currently extracted / can be enhanced?
*Thread Reply:* Let me first rephrase my understanding of the question assume a user runs spark.sql('INSERT INTO ...'). Are we able to include sql queryINSERT INTO ...within SQL facet?
We once had a look at it and found it difficult. Given an SQL, spark immediately translates it to a logical plan (which our integration is based on) and we didn't find any place where we could inject our code and get access to sql being run.
*Thread Reply:* Got it. So for spark.sql() - there's no interaction with sqlparser-rs and we directly try stitching the input/output & column lineage from the spark logical plan. Would something like this fall under the spark.jdbc() route or the spark.sql() route (say, if the df is collected / written somewhere)?
val df = spark.read.format("jdbc")
.option("url", url)
.option("user", user)
.option("password", password)
.option("fetchsize", fetchsize)
.option("driver", driver)
*Thread Reply:* @Athitya Kumar I understand your issue. From my side, there's one problem with this - potentially there can be multiple queries for one spark job. You can imagine something like joining results of two queries - possible to separate systems - and then one SqlJobFacet would be misleading. This needs more thorough spec discussion
Hi Team, has anyone experience with integrating OpenLineage with the SAP ecosystem? And with Salesforce/MuleSoft?
Hi,
Are there any ways to save list of string directly in the dataset facets? Such as the myfacets field in this dict
"facets": {
"metadata_facet": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/0.29.2/client/python>",
"_schemaURL": "<https://sth/schemas/facets.json#/definitions/SomeFacet>",
"myfacets": ["a", "b", "c"]
}
}
*Thread Reply:* I'm using python OpenLineage package and extend the BaseFacet class
*Thread Reply:* for custom facets, as long as it's valid json - go for it
*Thread Reply:* However I tried to insert a list of string. And I tried to get the dataset, the returned valued of that list field is empty.
*Thread Reply:* @attr.s
class MyFacet(BaseFacet):
columns: list[str] = attr.ib()
Here's my python code.
*Thread Reply:* How did you emit, serialized the event, and where did you look when you said you tried to get the dataset?
*Thread Reply:* I use the python openlineage client to emit the RunEvent.
openlineage_client.emit(
RunEvent(
eventType=RunState.COMPLETE,
eventTime=datetime.now().isoformat(),
run=run,
job=job,
producer=PRODUCER,
outputs=outputs,
)
)
And use marquez to visualize the get data result
*Thread Reply:* Yah, list of objects is working, but list of string is not.😩
*Thread Reply:* I think the problem is related to the openlineage package openlineage.client.serde.py. The function Serde.to_json()
*Thread Reply:* Yah, the value in list will end up False in this code and be filtered out
isinstance(_x_, dict)
😳
*Thread Reply:* wow, that's right 😬
*Thread Reply:* want to create PR fixing that?
*Thread Reply:* Sure! May do this later tomorrow.
*Thread Reply:* I created the pr at https://github.com/OpenLineage/OpenLineage/pull/2044 But the ci on integration-test-integration-spark FAILED
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Steven sorry for that - some tests require credentials that are not present on the forked versions of CI. It will work once I push it to origin. Anyway Spark tests failing aren't blocker for this Python PR
*Thread Reply:* I would only ask to add some tests for that case with facets containing list of string
*Thread Reply:* ah we had other CI problem, go version was too old in one of the jobs - neverthless I won't judge your PR on stuff failing outside your PR anyway 🙂
*Thread Reply:* LOL🤣 I've added some tests and made a force push

*Thread Reply:* @GitHubOpenLineageIssues I am trying to contribute to Integration tests which is listed here as good first issue the CONTRIBUTING.md mentions that i can trigger CI for integration tests from forked branch. using this tool. but i am unable to do so, is there a way to trigger CI from forked brach or do i have to get permission from someone to run the CI?
i am getting this error when i run this command sudo git-push-fork-to-upstream-branch upstream savannavalgi:hacktober
> Username for '<https://github.com>': savannavalgi
> Password for '<https://savannavalgi@github.com>':
> remote: Permission to OpenLineage/OpenLineage.git denied to savannavalgi.
> fatal: unable to access '<https://github.com/OpenLineage/OpenLineage.git/>': The requested URL returned error: 403
i have tried to configure ssh key
also tried to trigger CI from another brach,
and tried all of this after fetching the latest upstream
cc: @Athitya Kumar @Maciej Obuchowski @Steven
*Thread Reply:* what PR is the probem related to? I can run git-push-fork-to-upstream-branch for you
*Thread Reply:* @Paweł Leszczyński thanks for approving my PR - ( link )
I will make the changes needed for the new integration test case for drop table (good first issue) , in another PR, I would need your help to run the integration tests again, thank you
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Paweł Leszczyński opened a PR ( link ) for integration test for drop table can you please help run the integration test
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* sure, some of our tests require access to S3/BigQuery secret keys, so will not work automatically from the fork, and require action on our side. working on that
*Thread Reply:* thanks @Paweł Leszczyński let me know if i can help in any way
*Thread Reply:* @Paweł Leszczyński any action item on my side?
*Thread Reply:* @Paweł Leszczyński can you please take a look at this ? 🙂
*Thread Reply:* Hi @savan, were you able to run integration tests locally on your side? It seems the generated OL event is missing schema facet
"outputs" : [ {
"namespace" : "file",
"name" : "/tmp/drop_test/drop_table_test",
"facets" : {
"dataSource" : {
"_producer" : "<https://github.com/OpenLineage/OpenLineage/tree/1.5.0-SNAPSHOT/integration/spark>",
"_schemaURL" : "<https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet>",
"name" : "file",
"uri" : "file"
},
"symlinks" : {
"_producer" : "<https://github.com/OpenLineage/OpenLineage/tree/1.5.0-SNAPSHOT/integration/spark>",
"_schemaURL" : "<https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet>",
"identifiers" : [ {
"namespace" : "/tmp/drop_test",
"name" : "default.drop_table_test",
"type" : "TABLE"
} ]
},
"lifecycleStateChange" : {
"_producer" : "<https://github.com/OpenLineage/OpenLineage/tree/1.5.0-SNAPSHOT/integration/spark>",
"_schemaURL" : "<https://openlineage.io/spec/facets/1-0-0/LifecycleStateChangeDatasetFacet.json#/$defs/LifecycleStateChangeDatasetFacet>",
"lifecycleStateChange" : "DROP"
}
},
"outputFacets" : { }
} ]
which shouldn't be such a big problem I believe. This event intends to notify table is dropped which is still ok I believe without schema.
*Thread Reply:* @Paweł Leszczyński i am unable to run integration tests locally, as you mentioned it requires S3/BigQuery secret keys and wont work from a forked branch
*Thread Reply:* you can run this particular test you modify, don't need to run all of them
*Thread Reply:* can you please share any doc which will help me do that. i did go through the readme doc, i was stuck at > you dont have permission to perform this action
*Thread Reply:* ./gradlew :app:integrationTest --tests io.openlineage.spark.agent.SparkIcebergIntegrationTest.testDropTable
*Thread Reply:* this should run the thing you modify
*Thread Reply:* i am getting this error while building the project. tried a lot of things, any pointers or leads will be helpful? i am using apple m1 max chip computer. thanks > ------ Running smoke test ------ > Exception in thread “main” java.lang.UnsatisfiedLinkError: /private/var/folders/zz/zyxvpxvq6csfxvnn0000000000000/T/native-lib4719585175993676348/libopenlineagesqljava.dylib: dlopen(/private/var/folders/zz/zyxvpxvq6csfxvnn0000000000000/T/native-lib4719585175993676348/libopenlineagesqljava.dylib, 0x0001): tried: ‘/private/var/folders/zz/zyxvpxvq6csfxvnn0000000000000/T/native-lib4719585175993676348/libopenlineagesqljava.dylib’ (mach-o file, but is an incompatible architecture (have ‘arm64’, need ‘x8664’)), ‘/System/Volumes/Preboot/Cryptexes/OS/private/var/folders/zz/zyxvpxvq6csfxvnn0000000000000/T/native-lib4719585175993676348/libopenlineagesqljava.dylib’ (no such file), ‘/private/var/folders/zz/zyxvpxvq6csfxvnn0000000000000/T/native-lib4719585175993676348/libopenlineagesqljava.dylib’ (mach-o file, but is an incompatible architecture (have ‘arm64’, need ‘x86_64’)) > at java.base/java.lang.ClassLoader$NativeLibrary.load0(Native Method)
*Thread Reply:* the build passes with out the smoke tests. but the command you gave is throwing below error
(base) snavalgi@macos-PD7LVVY6MQ spark % ./gradlew -q :app:integrationTest --tests io.openlineage.spark.agent.SparkIcebergIntegrationTest.testDropTable
FAILURE: Build failed with an exception.
** Where: Build file ‘/Users/snavalgi/Documents/GitHub/OpenLineage/integration/spark/app/build.gradle’ line: 256
** What went wrong: A problem occurred evaluating project ‘:app’.
Could not resolve all files for configuration ‘:app:spark2’. Could not resolve io.openlineage:openlineagejava:1.9.0-SNAPSHOT. Required by: project :app > project :shared Could not resolve io.openlineage:openlineagejava:1.9.0-SNAPSHOT. Unable to load Maven meta-data from https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-java/1.9.0-SNAPSHOT/maven-metadata.xml. org.xml.sax.SAXParseException; lineNumber: 1; columnNumber: 10; DOCTYPE is disallowed when the feature “http://apache.org/xml/features/disallow-doctype-decl” set to true. Could not resolve io.openlineage:openlineagesqljava:1.9.0-SNAPSHOT. Required by: project :app > project :shared Could not resolve io.openlineage:openlineagesqljava:1.9.0-SNAPSHOT. Unable to load Maven meta-data from https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-sql-java/1.9.0-SNAPSHOT/maven-metadata.xml. org.xml.sax.SAXParseException; lineNumber: 1; columnNumber: 10; DOCTYPE is disallowed when the feature “http://apache.org/xml/features/disallow-doctype-decl” set to true.
** Try:
Run with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights. Get more help at https://help.gradle.org.
BUILD FAILED in 10s
*Thread Reply:* updated the correct error message
*Thread Reply:* @savan you need to build openlineage-java and openlineage-sql-java libraries as described here: https://github.com/OpenLineage/OpenLineage/blob/73b4a3bcd84239e7baedd22b5294624623d6f3ad/integration/spark/README.md#preparation
*Thread Reply:* @Maciej Obuchowski thanks for the response. the issue was with java-8 architecture i had installed.
i am able to compile, build and run the integration test now , with java 11 ( of appropriate arch)
*Thread Reply:* was able running some(createtable) integration tests successfully. but now the marquez-api container is repeated crashing. any pointers?
marquez-api | [Too many errors, abort] marquez-api | qemu: uncaught target signal 6 (Aborted) - core dumped marquez-api | /usr/src/app/entrypoint.sh: line 19: 44 Aborted java ${JAVAOPTS} -jar marquez-**.jar server ${MARQUEZCONFIG} marquez-api exited with code 134
*Thread Reply:* the marquez-api docker image has this warning
AMD64, image may have poor performance or fail, if run via emulation
*Thread Reply:* @Willy Lulciuc I think publishing arm64 image of Marquez would be a good idea
*Thread Reply:* Yeah, supporting multi-architectural docker builds makes sense. Here’s an article outlining an approach https://www.padok.fr/en/blog/multi-architectures-docker-iot#architectures. @Maciej Obuchowski what’s is what you’re suggesting here?
*Thread Reply:* @Maciej Obuchowski @Paweł Leszczyński i have verified the integration test for dropTestTable on my local. it is working fine. ✅✅✅✅✅ can you please trigger the CI for this PR? and expedite the review and merge process https://github.com/OpenLineage/OpenLineage/pull/2214
*Thread Reply:* the test is still failin in CI -> https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/9488/workflows/f669d751-aa18-4735-a51f-7d647415fee8/jobs/181187
io.openlineage.spark.agent.SparkContainerIntegrationTest testDropTable() FAILED (31.2s)
*Thread Reply:* i have made a minor change . can you please trigger the CI again @Paweł Leszczyński
*Thread Reply:* the test is again passing on my local with latest code. but i notice the below error in the previous CI failure.
the previous CI build was failing because
the actual START event for droptable in the CI had empty input and output.
> "eventType" : "START",
> "inputs" : [ ],
> "outputs" : [ ]
but on my local ,
the START event for droptable has output populated as below.
> {
> "eventType": "START",
> "job": {
> "namespace": "testDropTable"
> },
> "inputs": [],
> "outputs": [
> {
> "namespace": "file",
> "name": "/tmp/drop_test/drop_table_test",
> "facets": {
> "dataSource": {
> "name": "file",
> "uri": "file"
> },
> "symlinks": {
> "identifiers": [
> {
> "namespace": "file:/tmp/drop_test",
> "name": "default.drop_table_test",
> "type": "TABLE"
> }
> ]
> },
> "lifecycleStateChange": {
> "lifecycleStateChange": "DROP"
> }
> }
> }
> ]
> }
>
*Thread Reply:* Please note that CI runs tests against several Spark versions. This can be configured with
-Pspark.version=3.4.2
It's possible that your test passing for some versions while still failing for other ones.
*Thread Reply:* if CI is verifying against many spark version, does that mean, some spark version have empty output:[] and some have populated output:[] for the same START event of a droptable ?
if so then how do we specify different START events respectively for those versions of spark? is that possible?
*Thread Reply:* For complete event the assertion with empty inputs and outputs verifies only if an complete event was emitted. It would make sense for start to verify if this contains information about the deleted dataset. If it is missing for a single spark version, we should first try to understand why is this happening and if there is any workaround for this.
*Thread Reply:* yes makes sense. can you please approve to run CI for integration test again?
I really wanted to check if this build passes.
*Thread Reply:* and for the spark version for which we are getting empty output[] in START event for droptable should i open a new ticket on openlineage and report the issue?
*Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski can you please approve this CI to run integration tests? https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/9497/workflows/4a20dc95-d5d1-4ad7-967c-edb6e2538820
*Thread Reply:* @Paweł Leszczyński only 2 spark version are sending empty input and output for both START and COMPLETE event
• 3.4.2 • 3.5.0 i can look into the above , if you guide me a bit on how to ? should i open a new ticket for it? please suggest how to proceed?
*Thread Reply:* this integration test case lead to finding of the above bug for spark 3.4.2 and 3.5.0 will that be a blocker to merge this test case? @Paweł Leszczyński @Maciej Obuchowski
*Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski any direction on the above blocker will be helpful.
*Thread Reply:* @Paweł Leszczyński @Maciej Obuchowski we were able to debug the issue and found issues in logical plan received from sparkCore and have open a issue on spark jira for tracking it https://issues.apache.org/jira/browse/SPARK-48390
have opened a issue on openlineage github as well https://github.com/OpenLineage/OpenLineage/issues/2716
cc: @Mayur Madnani
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Yeah - looks like they moved to using different LogicalPlan - DropTable instead of DropTableCommand - but the identifier field should not be empty
*Thread Reply:* the code that handles DropTable does not look buggy https://github.com/OpenLineage/OpenLineage/blob/a391c53e3374479ed5bf2c3e3ad519b53f[…]o/openlineage/spark3/agent/lifecycle/plan/DropTableVisitor.java
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hi @Maciej Obuchowski@Paweł Leszczyński,
I hope this message finds you well. I recently noticed that my contributions to PR [#2745] were not attributed to me. Here is the PR i had open for the integration test cases after a lot of work. - PR [#2214] and as result of the over integration tests i wrote, i was able to figure the exact issue that was present - issue Over the past six months, I have invested significant time and effort into this work, and I believe it would be fair to recognize my contributions.
Would it be possible to amend the commit to include me as a co-author? Here’s the line that can be added to the commit message:
Coauthoredby: savan navalgi <savan.navalgi@gmail.com>
Thank you for your assistance.
Best regards, savan navalgi
*Thread Reply:* Hi @savan, your investigation on determining affected spark versions and providing clear logs to nail the problem, was really helpful. I am not sure if amending to commit on main branch can be applied. What if I created a separate PR with a changelog entry mentioning the fix applied and you as co-author? What this work for you?
*Thread Reply:* @Paweł Leszczyński yes that will also work. thank you very much.
*Thread Reply:* @Paweł Leszczyński
I have an internal demo tomorrow where I plan to present my open source contributions. Would it be possible to create the separate PR with the changelog entry by then? This would greatly help me in showcasing my work.
Thank you very much for your assistance.
*Thread Reply:* sure, https://github.com/OpenLineage/OpenLineage/pull/2759
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* thank you :gratitudethankyou:
Hey folks! 👋
Had a query/observation regarding columnLineage inferred in spark integration - opened this issue for the same. Basically, when we do something like this in our spark-sql:
SELECT t1.c1, t1.c2, t1.c3, t2.c4 FROM t1 LEFT JOIN t2 ON t1.c1 = t2.c1 AND t1.c2 = t2.c2
The expected column lineage for output table t3 is:
t3.c1 -> Comes from both t1.c1 & t2.c1 (SELECT + JOIN clause)
t3.c2 -> Comes from both t1.c2 & t2.c2 (SELECT + JOIN clause)
t3.c3 -> Comes from t1.c3
t3.c4 -> Comes from t2.c4
However, actual column lineage for output table t3 is:
t3.c1 -> Comes from t1.c1 (Only based on SELECT clause)
t3.c2 -> Comes from t1.c1 (Only based on SELECT clause)
t3.c3 -> Comes from t1.c3
t3.c4 -> Comes from t2.c4
Is this a known issue/behaviour?
*Thread Reply:* Hmm... this is kinda "logical" difference - is column level lineage taken from actual "physical" operations - like in this case, we always take from t1 - or from "logical" where t2 is used only for predicate, yet we still want to indicate it as a source?
*Thread Reply:* I think your interpretation is more useful
*Thread Reply:* @Maciej Obuchowski - Yup, especially for use-cases where we wanna depend on column lineage for impact analysis, I think we should be considering even predicates. For example, if t2.c1 / t2.c2 gets corrupted or dropped, the query would be impacted - which means that we should be including even predicates (t2.c1 / t2.c2) in the column lineage imo
But is there any technical limitation if we wanna implement this / make an OSS contribution for this (like logical predicate columns not being part of the spark logical plan object that we get in the PlanVisitor or something like that)?
*Thread Reply:* It's probably a bit of work, but can't think it's impossible on parser side - @Paweł Leszczyński will know better about spark collection
*Thread Reply:* This is a case where it would be nice to have an alternate indication (perhaps in the Column lineage facet?) for this type of "suggested" lineage. As noted, this is especially important for impact analysis purposes. We (and I believe others do the same or similar) call that "indirect" lineage at Manta.
*Thread Reply:* Something like additional flag in inputFields, right?
*Thread Reply:* Yes, this would require some extension to the spec. What do you mean spark-sql : spark.sql() with some spark query or SQL in spark JDBC?
*Thread Reply:* Sorry, missed your question @Paweł Leszczyński. By spark-sql, I'm referring to the former: spark.sql() with some spark query
*Thread Reply:* cc @Jens Pfau - you may be also interested in extending column level lineage facet.
*Thread Reply:* Hi, is there a github issue for this feature? Seems like a really cool and exciting functionality to have!
*Thread Reply:* @Anirudh Shrinivason - Are you referring to this issue: https://github.com/OpenLineage/OpenLineage/issues/2048?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Hey team 👋
Is there a way we can feed the logical plan directly to check the open-lineage events being built, without actually running a spark-job with open-lineage configs? Basically interested to see if we can mock a dry-run of a spark job w/ open-lineage by mimicking the logical plan 😄
cc @Shubh
*Thread Reply:* Not really I think - the integration does not rely purely on the logical plan
*Thread Reply:* At least, not in all cases. For some maybe
*Thread Reply:* We're using pretty similar approach in our column level lineage tests where we run some spark commands, register custom listener https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/tes[…]eage/spark/agent/util/LastQueryExecutionSparkEventListener.java which catches the logical plan. Further we run our tests on the captured logical plan.
The difference here, between what you're asking about, is that we still have an access to the same spark session.
In many cases, our integration uses active Spark session to fetch some dataset details. This happens pretty often (like fetch dataset location) and cannot be taken just from a Logical Plan.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Paweł Leszczyński - We're mainly interested to see the inputs/outputs (mainly column schema and column lineage) for different logical plans. Is that something that could be done in a static manner without running spark jobs in your opinion?
For example, I know that we can statically create logical plans
*Thread Reply:* The more we talk the more I am wondering what is the purpose of doing so? Do you want to test openlineage coverage or is there any production scenario where you would like to apply this?
*Thread Reply:* @Paweł Leszczyński - This is for testing openlineage coverage so that we can be more confident on what're the happy path scenarios and what're the scenarios where it may not work / work partially etc
*Thread Reply:* If this is for testing, then you're also capable of mocking some SparkSession/catalog methods when Openlineage integration tries to access them. If you want to reuse LogicalPlans from your prod environment, you will encounter logicalplan serialization issues. On the other hand, if you generate logical plans from some example Spark jobs, then the same can be easier achieved in a way the integration tests are run with mockserver.
Hi Team,
Spark & Databricks related question: Starting 1st September Databricks is going to block running init_scripts located in dbfs and this is the way our integration works (https://www.databricks.com/blog/securing-databricks-cluster-init-scripts).
We have two ways of mitigating this in our docs and quickstart: (1) move initscripts to workspace (2) move initscripts to S3
None of them is perfect. (1) requires creating init_script file manually through databricks UI and copy/paste its content. I couldn't find the way to load it programatically. (2) requires quickstart user to have s3 bucket access.
Would love to hear your opinion on this. Perhaps there's some better way to do that. Thanks. `

*Thread Reply:* We're uploading the init scripts to s3 via tf. But yeah ig there are some access permissions that the user needs to have

*Thread Reply:* Hello I am new here and I am asking why do you need an init script ? If it's a spark integration we can just specify --package=io.openlineage...
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/databricks/open-lineage-init-script.sh -> I think the issue was in having openlineage-jar installed immediately on the classpath bcz it's required when OpenLineageSparkListener is instantiated. It didn't work without it.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Yes it happens if you use --jars s3://.../...openlineage-spark-VERSION.jar parameter. (I made a ticket for this issue in Databricks support)
But if you use --package io.openlineage... (the package will be downloaded from maven) it works fine.
*Thread Reply:* I think they don't use the right class loader.
*Thread Reply:* To make sure: are you able to run Openlineage & Spark on Databricks Runtime without init_scripts?
I was doing this a second ago and this ended up with Caused by: java.lang.ClassNotFoundException: io.openlineage.spark.agent.OpenLineageSparkListener not found in com.databricks.backend.daemon.driver.ClassLoaders$LibraryClassLoader@1609ed55

Hello, I just downloaded Marquez and I'm trying to send a sample request but I'm getting a 403 (forbidden). Any idea how to find the authentication details?
*Thread Reply:* Ok, nevermind. I figured it out. The port 5000 is reserved in MACOS so I had to start on port 9000 instead.
Hi, I noticed that while capturing lineage for merge into commands, some of the tables/columns are unaccounted for the lineage. Example: ```fdummyfunnelstg = spark.sql("""WITH dummyfunnel AS ( SELECT ** FROM fdummyfunnelone WHERE dateid BETWEEN {startdateid} AND {enddateid}
UNION ALL
SELECT **
FROM f_dummy_funnel_two
WHERE date_id BETWEEN {start_date_id} AND {end_date_id}
UNION ALL
SELECT **
FROM f_dummy_funnel_three
WHERE date_id BETWEEN {start_date_id} AND {end_date_id}
UNION ALL
SELECT **
FROM f_dummy_funnel_four
WHERE date_id BETWEEN {start_date_id} AND {end_date_id}
UNION ALL
SELECT **
FROM f_dummy_funnel_five
WHERE date_id BETWEEN {start_date_id} AND {end_date_id}
)
SELECT DISTINCT
dummy_funnel.customer_id,
dummy_funnel.product,
dummy_funnel.date_id,
dummy_funnel.country_id,
dummy_funnel.city_id,
dummy_funnel.dummy_type_id,
dummy_funnel.num_attempts,
dummy_funnel.num_transactions,
dummy_funnel.gross_merchandise_value,
dummy_funnel.sub_category_id,
dummy_funnel.is_dummy_flag
FROM dummy_funnel
INNER JOIN d_dummy_identity as dummy_identity
ON dummy_identity.id = dummy_funnel.customer_id
WHERE
date_id BETWEEN {start_date_id} AND {end_date_id}""")
spark.sql(f"""
MERGE INTO {tablename}
USING fdummyfunnelstg
ON
fdummyfunnelstg.customerid = {tablename}.customerid
AND fdummyfunnelstg.product = {tablename}.product
AND fdummyfunnelstg.dateid = {tablename}.dateid
AND fdummyfunnelstg.countryid = {tablename}.countryid
AND fdummyfunnelstg.cityid = {tablename}.cityid
AND fdummyfunnelstg.dummytypeid = {tablename}.dummytypeid
AND fdummyfunnelstg.subcategoryid = {tablename}.subcategoryid
AND fdummyfunnelstg.isdummyflag = {tablename}.isdummyflag
WHEN MATCHED THEN
UPDATE SET
{tablename}.numattempts = fdummyfunnelstg.numattempts
, {tablename}.numtransactions = fdummyfunnelstg.numtransactions
, {tablename}.grossmerchandisevalue = fdummyfunnelstg.grossmerchandisevalue
WHEN NOT MATCHED
THEN INSERT (
customerid,
product,
dateid,
countryid,
cityid,
dummytypeid,
numattempts,
numtransactions,
grossmerchandisevalue,
subcategoryid,
isdummyflag
)
VALUES (
fdummyfunnelstg.customerid,
fdummyfunnelstg.product,
fdummyfunnelstg.dateid,
fdummyfunnelstg.countryid,
fdummyfunnelstg.cityid,
fdummyfunnelstg.dummytypeid,
fdummyfunnelstg.numattempts,
fdummyfunnelstg.numtransactions,
fdummyfunnelstg.grossmerchandisevalue,
fdummyfunnelstg.subcategoryid,
fdummyfunnelstg.isdummyflag
)
""")``
In cases like this, I notice that the full lineage is not actually captured... I'd expect to see this having 5 upstreams:dummyfunnelone, dummyfunneltwo, dummyfunnelthree, dummyfunnelfour, dummyfunnel_five` , but I notice only 1-2 upstreams for this case...
Would like to learn more about why this might happen, and whether this is expected behaviour or not. Thanks!
*Thread Reply:* Would be useful to see generated event or any logs
*Thread Reply:* @Anirudh Shrinivason what if there is just one union instead of four? What if there are just two columns selected instead of 10? What if inner join is skipped? Does merge into matter?
The smaller SQL to reproduce the problem, the easier it is to find the root cause. Most of the issues are reproducible with just few lines of code.
*Thread Reply:* Yup let me try to identify the cause from my end. Give me some time haha. I'll reach out again once there is more clarity on the occurence
Hello,
The OpenLineage Databricks integration is not working properly in our side which due to filtering adaptive_spark_plan
Please find the issue link.
https://github.com/OpenLineage/OpenLineage/issues/2058
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* thanks @Abdallah for the thoughtful issue that you submitted! was wondering if you’d consider opening up a PR? would love to help you as a contributor is that’s something you are interested in.
*Thread Reply:* I deleted the line that has that filter.
*Thread Reply:* But running
./gradlew --no-daemon databricksIntegrationTest -x test -Pspark.version=3.4.0 -PdatabricksHost=$DATABRICKS_HOST -PdatabricksToken=$DATABRICKS_TOKEN
*Thread Reply:* gives me
A problem occurred evaluating project ':app'.
> Could not resolve all files for configuration ':app:spark33'.
> Could not resolve io.openlineage:openlineage_java:1.1.0-SNAPSHOT.
Required by:
project :app > project :shared
> Could not resolve io.openlineage:openlineage_java:1.1.0-SNAPSHOT.
> Unable to load Maven meta-data from <https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-java/1.1.0-SNAPSHOT/maven-metadata.xml>.
> org.xml.sax.SAXParseException; lineNumber: 1; columnNumber: 326; The reference to entity "display" must end with the ';' delimiter.
> Could not resolve io.openlineage:openlineage_sql_java:1.1.0-SNAPSHOT.
Required by:
project :app > project :shared
> Could not resolve io.openlineage:openlineage_sql_java:1.1.0-SNAPSHOT.
> Unable to load Maven meta-data from <https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-sql-java/1.1.0-SNAPSHOT/maven-metadata.xml>.
> org.xml.sax.SAXParseException; lineNumber: 1; columnNumber: 326; The reference to entity "display" must end with the ';' delimiter.
*Thread Reply:* And I am trying to understand what should I do.
*Thread Reply:* but having
A problem occurred evaluating project ':app'.
> Could not resolve all files for configuration ':app:spark33'.
> Could not resolve io.openlineage:openlineage_java:1.1.0-SNAPSHOT.
Required by:
project :app > project :shared
> Could not resolve io.openlineage:openlineage_java:1.1.0-SNAPSHOT.
> Unable to load Maven meta-data from <https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-java/1.1.0-SNAPSHOT/maven-metadata.xml>.
> org.xml.sax.SAXParseException; lineNumber: 1; columnNumber: 326; The reference to entity "display" must end with the ';' delimiter.
> Could not resolve io.openlineage:openlineage_sql_java:1.1.0-SNAPSHOT.
Required by:
project :app > project :shared
> Could not resolve io.openlineage:openlineage_sql_java:1.1.0-SNAPSHOT.
> Unable to load Maven meta-data from <https://astronomer.jfrog.io/artifactory/maven-public-libs-snapshot/io/openlineage/openlineage-sql-java/1.1.0-SNAPSHOT/maven-metadata.xml>.
> org.xml.sax.SAXParseException; lineNumber: 1; columnNumber: 326; The reference to entity "display" must end with the ';' delimiter.
*Thread Reply:* Please do ./gradlew publishToMavenLocal in client/java directory
*Thread Reply:* And I had somme issues that -PdatabricksHost doesn't work with System.getProperty("databricksHost") So I changed to -DdatabricksHost with System.getenv("databricksHost")
*Thread Reply:* Then I had some issue that the path dbfs:/databricks/openlineage/ doesn't exist, I, then, created the folder /dbfs/databricks/openlineage/
*Thread Reply:* And now I am investigating this issue :
java.lang.NullPointerException
at io.openlineage.spark.agent.DatabricksUtils.uploadOpenlineageJar(DatabricksUtils.java:226)
at io.openlineage.spark.agent.DatabricksUtils.init(DatabricksUtils.java:66)
at io.openlineage.spark.agent.DatabricksIntegrationTest.setup(DatabricksIntegrationTest.java:54)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at ...
worker.org.gradle.process.internal.worker.GradleWorkerMain.main(GradleWorkerMain.java:74)
Suppressed: com.databricks.sdk.core.DatabricksError: Missing required field: cluster_id
at app//com.databricks.sdk.core.error.ApiErrors.readErrorFromResponse(ApiErrors.java:48)
at app//com.databricks.sdk.core.error.ApiErrors.checkForRetry(ApiErrors.java:22)
at app//com.databricks.sdk.core.ApiClient.executeInner(ApiClient.java:236)
at app//com.databricks.sdk.core.ApiClient.getResponse(ApiClient.java:197)
at app//com.databricks.sdk.core.ApiClient.execute(ApiClient.java:187)
at app//com.databricks.sdk.core.ApiClient.POST(ApiClient.java:149)
at app//com.databricks.sdk.service.compute.ClustersImpl.delete(ClustersImpl.java:31)
at app//com.databricks.sdk.service.compute.ClustersAPI.delete(ClustersAPI.java:191)
at app//com.databricks.sdk.service.compute.ClustersAPI.delete(ClustersAPI.java:180)
at app//io.openlineage.spark.agent.DatabricksUtils.shutdown(DatabricksUtils.java:96)
at app//io.openlineage.spark.agent.DatabricksIntegrationTest.shutdown(DatabricksIntegrationTest.java:65)
at
...
*Thread Reply:* Suppressed: com.databricks.sdk.core.DatabricksError: Missing required field: cluster_id
*Thread Reply:* at io.openlineage.spark.agent.DatabricksUtils.uploadOpenlineageJar(DatabricksUtils.java:226)
*Thread Reply:* I did this !echo "xxx" > /dbfs/databricks/openlineage/openlineage-spark-V.jar
*Thread Reply:* To create some fake file that can be deleted in uploadOpenlineageJar function.
*Thread Reply:* Because if there is no file, this part fails
StreamSupport.stream(
workspace.dbfs().list("dbfs:/databricks/openlineage/").spliterator(), false)
.filter(f -> f.getPath().contains("openlineage-spark"))
.filter(f -> f.getPath().endsWith(".jar"))
.forEach(f -> workspace.dbfs().delete(f.getPath()));
*Thread Reply:* does this work after
!echo "xxx" > /dbfs/databricks/openlineage/openlineage-spark-V.jar
?
*Thread Reply:* I am now having another error in the driver
23/08/22 22:56:26 ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Exception when registering SparkListener
at org.apache.spark.SparkContext.setupAndStartListenerBus(SparkContext.scala:3121)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:835)
at com.databricks.backend.daemon.driver.DatabricksILoop$.$anonfun$initializeSharedDriverContext$1(DatabricksILoop.scala:362)
...
at com.databricks.DatabricksMain.main(DatabricksMain.scala:146)
at com.databricks.backend.daemon.driver.DriverDaemon.main(DriverDaemon.scala)
Caused by: java.lang.ClassNotFoundException: io.openlineage.spark.agent.OpenLineageSparkListener not found in com.databricks.backend.daemon.driver.ClassLoaders$LibraryClassLoader@298cfe89
at com.databricks.backend.daemon.driver.ClassLoaders$MultiReplClassLoader.loadClass(ClassLoaders.scala:115)
at java.lang.ClassLoader.loadClass(ClassLoader.java:352)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:263)
*Thread Reply:* due to the findAny 😕
private static void uploadOpenlineageJar(WorkspaceClient workspace) {
Path jarFile =
Files.list(Paths.get("../build/libs/"))
.filter(p -> p.getFileName().toString().startsWith("openlineage-spark-"))
.filter(p -> p.getFileName().toString().endsWith("jar"))
.findAny()
.orElseThrow(() -> new RuntimeException("openlineage-spark jar not found"));
*Thread Reply:* The PR 😄 https://github.com/OpenLineage/OpenLineage/pull/2061
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* thanks for the pr 🙂
*Thread Reply:* code formatting checks complain now
*Thread Reply:* for the JAR issues, do you also want to create PR as you've fixed the issue on your end?
*Thread Reply:* @Abdallah you're using newer version of Java than 8, right?
*Thread Reply:* AFAIK googleJavaFormat behaves differently between Java versions
*Thread Reply:* Okay I will switch back to another java version
*Thread Reply:* terra@MacBook-Pro-M3 spark % java -version
java version "1.8.0_381"
Java(TM) SE Runtime Environment (build 1.8.0_381-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.381-b09, mixed mode)
*Thread Reply:* Can you tell me which java version should I use ?
*Thread Reply:* Hello, I have
@mobuchowski ERROR: Missing environment variable {i}
Can you please check what does it come from ?
*Thread Reply:* ```Hello, I have
@mobuchowski ERROR: Missing environment variable {i} Can you please check what does it come from ? (edited) ``` Yup, for now I have to manually make our CI account pick your changes up if you make PR from fork. Just did that
*Thread Reply:* running here now: https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/7881/workflows/90793f46-796a-4f59-9de3-5d58cbcbf162
*Thread Reply:* @Abdallah merged 🙂
@channel
Meetup notice: on Monday, 9/18, at 5:00 pm ET OpenLineage will be gathering in Toronto at Airflow Summit. Coming to the summit? Based in or near Toronto? Please join us to discuss topics such as:
• recent developments in the project including the addition of static lineage support and the OpenLineage Airflow Provider,
• the project’s history and architecture,
• opportunities to contribute,
• resources for getting started,
• + more.
Please visit


i saw OpenLineage was built into Airflow recently as a provider but the documentation seems really light (https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/guides/user.html), is the documentation from openlineage the correct way I should proceed?
https://openlineage.io/docs/integrations/airflow/usage
*Thread Reply:* openlineage-airflow is the package maintained in the OpenLineage project and to be used for versions of Airflow before 2.7. You could use it with 2.7 as well but you’d be staying on the “old” integration. apache-airflow-providers-openlineage is the new package, maintained in the Airflow project that can be used starting Airflow 2.7 and is the recommended package moving forward. It is compatible with the configuration of the old package described in that usage page. CC: @Maciej Obuchowski @Jakub Dardziński It looks like this page needs improvement.

*Thread Reply:* Yeah, I'll fix that
*Thread Reply:* https://github.com/apache/airflow/pull/33610
fyi
<a href="https://github.com/apache/airflow">apache/airflow</a>
do I label certain raw data sources as a dataset, for example SFTP/FTP sites, 0365 emails, etc? I extract that data into a bucket for the client in a "folder" called "raw" which I know will be an OL Dataset. Would this GCS folder (after extracting the data with Airflow) be the first Dataset OL is aware of?
<gcs://client-bucket/source-system-lob/raw>
I then process that data into partitioned parquet datasets which would also be OL Datasets:
<gcs://client-bucket/source-system-lob/staging>
<gcs://client-bucket/source-system-lob/analytics>
*Thread Reply:* that really depends on the use case IMHO if you consider a whole directory/folder as a dataset (meaning that each file inside folds into a larger whole) you should label dataset as directory
you might as well have directory with each file being something different - in this case it would be best to set each file separately as dataset
*Thread Reply:* there was also SymlinksDatasetFacet introduced to store alternative dataset names, might be useful: https://github.com/OpenLineage/OpenLineage/pull/936
*Thread Reply:* cool, yeah in general each file is just a snapshot of data from a client (for example, daily dump). the parquet datasets are normally partitioned and might have small fragments and I definitely picture it as more of a table than individual files
*Thread Reply:* Agree with Jakub here - with object storage, people use different patterns, but usually some directory layer vs file is the valid abstraction level, especially if your pattern is adding files with new data inside
*Thread Reply:* I tested a dataset for each raw file versus the folder and the folder looks much cleaner (not sure if I can collapse individual datasets/files into a group?)
from 2022, this particular source had 6 raw schema changes (client controlled, no warning). what should I do to make that as obvious as possible if I track the dataset at a folder level?
*Thread Reply:* I was thinking that I could name the dataset based on the schema_version (identified by the raw column names), so in this example I would have 6 OL datasets feeding into one "staging" dataset
*Thread Reply:* not sure what the best practice would be in this scenario though
• also saw the docs reference URI = gs://{bucket name}{path} and I wondered if the path would include the filename, or if it was just the base path like I showed above

Has anyone managed to get the OL Airflow integration to work on AWS MWAA? We've tried pretty much every trick but still ended up with the following error:
Broken plugin: [openlineage.airflow.plugin] No module named 'openlineage.airflow'; 'openlineage' is not a package
*Thread Reply:* Which version are you trying to use?
*Thread Reply:* Both OL and MWAA/Airflow 🙂
*Thread Reply:* 'openlineage' is not a package
suggests that something went wrong with import process, for example cycle in import path
*Thread Reply:* MWAA: 2.6.3 OL: 1.0.0
I can see from the log that OL has been successfully installed to the webserver:
Successfully installed openlineage-airflow-1.0.0 openlineage-integration-common-1.0.0 openlineage-python-1.0.0 openlineage-sql-1.0.0
This is the full stacktrace:
```Traceback (most recent call last):
File "/usr/local/airflow/.local/lib/python3.10/site-packages/airflow/pluginsmanager.py", line 229, in loadentrypointplugins pluginclass = entrypoint.load() File "/usr/local/airflow/.local/lib/python3.10/site-packages/importlibmetadata/init.py", line 209, in load module = importmodule(match.group('module')) File "/usr/lib/python3.10/importlib/init.py", line 126, in importmodule return bootstrap.gcdimport(name[level:], package, level) File "<frozen importlib.bootstrap>", line 1050, in gcdimport File "<frozen importlib.bootstrap>", line 1027, in _findandload File "<frozen importlib.bootstrap>", line 992, in findandloadunlocked File "<frozen importlib.bootstrap>", line 241, in _callwithframesremoved File "<frozen importlib.bootstrap>", line 1050, in _gcdimport File "<frozen importlib.bootstrap>", line 1027, in _findandload File "<frozen importlib.bootstrap>", line 1001, in findandloadunlocked ModuleNotFoundError: No module named 'openlineage.airflow'; 'openlineage' is not a package```
*Thread Reply:* It’s taking long to update MWAA environment but I tested 2.6.3 version with the followingrequirements.txt:
openlineage-airflow
and
openlineage-airflow==1.0.0
is there any step that might lead to some unexpected results?
*Thread Reply:* Yeah, it takes forever to update MWAA even for a simple change. If you open either the webserver log (in CloudWatch) or the AirFlow UI, you should see the above error message.
*Thread Reply:* The thing is that I don’t see any error messages. I wrote simple DAG to test too: ```from future import annotations
from datetime import datetime
from airflow.models import DAG
try: from airflow.operators.empty import EmptyOperator except ModuleNotFoundError: from airflow.operators.dummy import DummyOperator as EmptyOperator # type: ignore
from openlineage.airflow.adapter import OpenLineageAdapter from openlineage.client.client import OpenLineageClient
from airflow.operators.python import PythonOperator
DAGID = "exampleol"
def callable(): client = OpenLineageClient() adapter = OpenLineageAdapter() print(client, adapter)
with DAG( dagid=DAGID, startdate=datetime(2021, 1, 1), schedule="@once", catchup=False, ) as dag: begin = EmptyOperator(taskid="begin")
test = PythonOperator(task_id='print_client', python_callable=callable)```
and it gives expected results as well
*Thread Reply:* Oh how interesting. I did have a plugin that sets the endpoint & key via env var. Let me try to disable that to see if it fixes the issue. Will report back after 30 mins, or however long it takes to update MWAA 😉
*Thread Reply:* ohh, I see you probably followed this guide: https://aws.amazon.com/blogs/big-data/automate-data-lineage-on-amazon-mwaa-with-openlineage/?
*Thread Reply:* Actually no. I'm not aware of this guide. I assume it's outdated already?
*Thread Reply:* tbh I don’t know
*Thread Reply:* Actually while we're on that topic, what's the recommended way to pass the URL & API Key in MWAA?
*Thread Reply:* I think it's still a plugin that sets env vars
*Thread Reply:* Yeah based on the page you shared, secret manager + plugin seems like the way to go.
*Thread Reply:* Alas after disabling the plugin and restarting the cluster, I'm still getting the same error. Do you mind to share a screenshot of your cluster's settings so I can compare?
*Thread Reply:* Are you maybe importing some top level OpenLineage code anywhere? This error is most likely circular import
*Thread Reply:* Let me try removing all the dags to see if it helps.
*Thread Reply:* @Maciej Obuchowski you were correct! It was indeed the DAGs. The errors are gone after removing all the dags. Now just need to figure what caused the circular import since I didn't import OL directly in DAG.
*Thread Reply:* Could this be the issue?
from airflow.lineage.entities import File, Table
How could I declare lineage manually if I can't import these classes?
*Thread Reply:* @Mars Lan (Metaphor) I'll look in more details next week, as I'm in transit now
*Thread Reply:* but if you could narrow down a problem to single dag that I or @Jakub Dardziński could reproduce, ideally locally, it would help a lot
*Thread Reply:* Thanks. I think I understand how this works much better now. Found a few useful BQ example dags. Will give them a try and report back.

Hi All, I want to capture, source and target table details as lineage information with openlineage for Amazon Redshift. Please let me know, if anyone has done it
*Thread Reply:* are you using Airflow to connect to Redshift?
*Thread Reply:* Hi @Jakub Dardziński, Thank you for your reply. No, we are not using Airflow. We are using load/Unload cmd with Pyspark and also Pandas with JDBC connection
*Thread Reply:* @Paweł Leszczyński might know answer if Spark<->OL integration works with Redshift. Eventually JDBC is supported with sqlparser
for Pandas I think there wasn’t too much work done
*Thread Reply:* @Nitin If you're using jdbc within Spark, the lineage should be obtained via sqlparser-rs library https://github.com/sqlparser-rs/sqlparser-rs. In case it's not, please try to provide some minimal SQL code (or pyspark) which leads to uncaught lineage.
*Thread Reply:* Hi @Jakub Dardziński / @Paweł Leszczyński, thank you for taking out time to reply on my query. We need to capture only load and unload query lineage which we are running using Spark.
If you have any sample implementation for reference, it will be indeed helpful
*Thread Reply:* I think we don't support load yet on our side: https://github.com/OpenLineage/OpenLineage/blob/main/integration/sql/impl/src/visitor.rs#L8
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Yeah! any way you can think of, we can accommodate it specially load and unload statement. Also, we would like to capture, lineage information where our endpoints are Sagemaker and Redis
*Thread Reply:* @Paweł Leszczyński can we use this code base integration/common/openlineage/common/provider/redshift_data.py for redshift lineage capture
*Thread Reply:* it still expects input and output tables that are usually retrieved from sqlparser
*Thread Reply:* for Sagemaker there is an Airflow integration written, might be an example possibly https://github.com/OpenLineage/OpenLineage/blob/main/integration/airflow/openlineage/airflow/extractors/sagemaker_extractors.py
Approve a new release please 🙂 • Fix spark integration filtering Databricks events.
*Thread Reply:* Thank you for requesting a release @Abdallah. Three +1s from committers will authorize.
*Thread Reply:* Thanks, all. The release is authorized and will be initiated within 2 business days.
Hey folks! Do we have clear step-by-step documentation on how we can leverage the ServiceLoader based approach for injecting specific OpenLineage customisations for tweaking the transport type with defaults / tweaking column level lineage etc?
*Thread Reply:* For custom transport, you have to provide implementation of interface https://github.com/OpenLineage/OpenLineage/blob/4a1a5c3bf9767467b71ca0e1b6d820ba9e[…]ain/java/io/openlineage/client/transports/TransportBuilder.java and point to it in META_INF file
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* But if I understand correctly, if you want to change behavior rather than extend, the correct way may be to either contribute it to repo - if that behavior is useful to anyone, or fork the repo
*Thread Reply:* @Maciej Obuchowski - Can you elaborate more on the "point to it in META_INF file"? Let's say we have the custom transport type built in a standalone jar by extending transport builder - what're the exact next steps to use this custom transport in the standalone jar when doing spark-submit?
*Thread Reply:* @Athitya Kumar your jar needs to have META-INF/services/io.openlineage.client.transports.TransportBuilder with fully qualified class names of your custom TransportBuilders there - like openlineage-spark has
io.openlineage.client.transports.HttpTransportBuilder
io.openlineage.client.transports.KafkaTransportBuilder
io.openlineage.client.transports.ConsoleTransportBuilder
io.openlineage.client.transports.FileTransportBuilder
io.openlineage.client.transports.KinesisTransportBuilder
*Thread Reply:* @Maciej Obuchowski - I think this change may be required for consumers to leverage custom transports, can you check & verify this GH comment? https://github.com/OpenLineage/OpenLineage/issues/2007#issuecomment-1690350630
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Probably, I will look at more details next week @Athitya Kumar as I'm in transit
@channel
We released OpenLineage 1.1.0, including:
Additions:
• Flink: create Openlineage configuration based on Flink configuration #2033 @pawel-big-lebowski
• Java: add Javadocs to the Java client #2004 @julienledem
• Spark: append output dataset name to a job name #2036 @pawel-big-lebowski
• Spark: support Spark 3.4.1 #2057 @pawel-big-lebowski
Fixes:
• Flink: fix a bug when getting schema for KafkaSink #2042 @pentium3
• Spark: fix ignored event adaptive_spark_plan in Databricks #2061 @algorithmy1
Plus additional bug fixes, doc changes and more.
Thanks to all the contributors, especially new contributors @pentium3 and @Abdallah!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.1.0
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.0.0...1.1.0
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
@channel
Friendly reminder: our next in-person meetup is next Wednesday, August 30th in San Francisco at Astronomer’s offices in the Financial District. You can sign up and find the details on the
hi Openlineage team , we would like to join one of your meetups(me and @Madhav Kakumani nad @Phil Rolph and we're wondering if you are hosting any meetups after the 18/9 ? We are trying to join this but air - tickets are quite expensive
*Thread Reply:* there will certainly be more meetups, don’t worry about that!
*Thread Reply:* where are you located? perhaps we can try to organize a meetup closer to where you are.
*Thread Reply:* Thanks a lot for the response, we are in London. We'd be glad to help you organise a meetup and also meet in person!
*Thread Reply:* This is awesome, thanks @George Polychronopoulos. I’ll start a channel and invite you
hi folks, I'm looking into exporting static metadata, and found that DatasetEvent requires a eventTime, which in my mind doesn't make sense for static events. I'm setting it to None and the Python client seems to work, but wanted to ask if I'm missing something.
*Thread Reply:* Although you emit DatasetEvent, you still emit an event and eventTime is a valid marker.
*Thread Reply:* so, should I use the current time at the moment of emitting it and that's it?
*Thread Reply:* yes, that should be it
and something else: I understand that Marquez does not yet support the 2.0 spec, hence it's incompatible with static metadata right? I tried to emit a list of DatasetEvent s and got HTTPError: 422 Client Error: Unprocessable Entity for url: <http://localhost:3000/api/v1/lineage> (I'm using a FileTransport for now)
*Thread Reply:* marquez is not capable of reflecting DatasetEvents in DB but it should respond with Unsupported event type
*Thread Reply:* and return 200 instead of 201 created
*Thread Reply:* I'll have a deeper look then, probably I'm doing something wrong. thanks @Paweł Leszczyński

Hi folks. I have some pure golang jobs from which I need to emit OL events to Marquez. Is the right way to go about this to generate a Golang client from the Marquez OpenAPI spec and use that client from my go jobs?
*Thread Reply:* I'd rather generate them from OL spec (compliant with JSON Schema)
*Thread Reply:* I'll look into this. I take you to mean that I would use the OL spec which is available as a set of JSON schemas to create the data object and then HTTP POST it using vanilla Golang. Is that correct? Thank you for your help!
*Thread Reply:* Correct! You’re also very welcome to contribute Golang client (currently we have Python & Java clients) if you manage to send events using golang 🙂
@channel
The agenda for the
- Intros
- Evolution of spec presentation/discussion (project background/history)
- State of the community
- Spark/Column lineage update
- Airflow Provider update
- Roadmap Discussion
- Action items review/next steps
New on the OpenLineage blog: a close look at the new OpenLineage Airflow Provider, including: • the critical improvements it brings to the integration • the high-level design • implementation details • an example operator • planned enhancements • a list of supported operators • more. The post, by @Maciej Obuchowski, @Julien Le Dem and myself is live now on the OpenLineage blog.
Hello, I'm currently in the process of following the instructions outlined in the provided getting started guide at https://openlineage.io/getting-started/. However, I've encountered a problem while attempting to complete *Step 1* of the guide. Unfortunately, I'm encountering an internal server error at this stage. I did manage to successfully run Marquez, but it appears that there might be an issue that needs to be addressed. I have attached screen shots.
*Thread Reply:* is 5000 port taken by any other application? or ./docker/up.sh has some errors in logs?
*Thread Reply:* I think Marquez is running on WSL while you're trying to connect from host computer?
hi folks, for now I'm producing .jsonl (or .ndjson ) files with one event per line, do you know if there's any way to validate those? would standard JSON Schema tools work?
*Thread Reply:* reply by @Julian LaNeve: yes 🙂💯
for namespaces, if my data is moving between sources (SFTP -> GCS -> Azure Blob (synapse connects to parquet datasets) then should my namespace be based on the client I am working with? my current namespace has been
*Thread Reply:* > then should my namespace be based on the client I am working with? I think each of those sources should be a different namespace?
*Thread Reply:* got it, yeah I was kind of picturing as one namespace for the client (we handle many clients but they are completely distinct entities). I was able to get it to work with multiple namespaces like you suggested and Marquez was able to plot everything correctly in the visualization
*Thread Reply:* I noticed some of my Dataset facets make more sense as Run facets, for example, the name of the specific file I processed and how many rows of data / size of the data for that schedule. that won't impact the Run facets Airflow provides right? I can still have the schedule information + my custom run facets?
*Thread Reply:* Yes, unless you name it the same as one of the Airflow facets 🙂
Hi, Will really appreciate if someone can guide me or provide me any pointer - if they have been able to implement authentication/authorization for access to Marquez. Have not seen much info around it. Any pointers greatly appreciated. Thanks in advance.
*Thread Reply:* I’ve seen people do this through the ingress controller in Kubernetes. Unfortunately I don’t have documentation besides k8s specific ones you would find for the ingress controller you’re using. You’d redirect any unauthenticated request to your identity provider
@channel Friendly reminder: there’s a meetup tonight at Astronomer’s offices in SF!
*Thread Reply:* I’ll be there and looking forward to see @John Lukenoff ‘s presentation

Can anyone let 3 people stuck downstairs into the 7th floor?

hello,everyone,i can run openLineage spark code in my notebook with python,but when use my idea to execute scala code like this: import org.apache.spark.internal.Logging import org.apache.spark.sql.SparkSession import io.openlineage.client.OpenLineageClientUtils.loadOpenLineageYaml import org.apache.spark.scheduler.{SparkListener, SparkListenerApplicationEnd, SparkListenerApplicationStart} import sun.java2d.marlin.MarlinUtils.logInfo object Test { def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("test")
.config("spark.jars.packages","io.openlineage:openlineage_spark:0.12.0")
.config("spark.extraListeners","io.openlineage.spark.agent.OpenLineageSparkListener")
.config("spark.openlineage.transport.type","console")
.getOrCreate()
spark.sparkContext.setLogLevel("INFO")
//spark.sparkContext.addSparkListener(new MySparkAppListener)
import spark.implicits._
val input = Seq((1, "zs", 2020), (2, "ls", 2023)).toDF("id", "name", "year")
input.select("id", "name").orderBy("id").show()
}
}
there is something wrong: Exception in thread "spark-listener-group-shared" java.lang.NoSuchMethodError: io.openlineage.client.OpenLineageClientUtils.loadOpenLineageYaml(Ljava/io/InputStream;)Lio/openlineage/client/OpenLineageYaml; at io.openlineage.spark.agent.ArgumentParser.extractOpenlineageConfFromSparkConf(ArgumentParser.java:114) at io.openlineage.spark.agent.ArgumentParser.parse(ArgumentParser.java:78) at io.openlineage.spark.agent.OpenLineageSparkListener.initializeContextFactoryIfNotInitialized(OpenLineageSparkListener.java:277) at io.openlineage.spark.agent.OpenLineageSparkListener.onApplicationStart(OpenLineageSparkListener.java:267) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent(SparkListenerBus.scala:55) at org.apache.spark.scheduler.SparkListenerBus.doPostEvent$(SparkListenerBus.scala:28) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.scheduler.AsyncEventQueue.doPostEvent(AsyncEventQueue.scala:37) at org.apache.spark.util.ListenerBus.postToAll(ListenerBus.scala:117) at org.apache.spark.util.ListenerBus.postToAll$(ListenerBus.scala:101) at org.apache.spark.scheduler.AsyncEventQueue.super$postToAll(AsyncEventQueue.scala:105) at org.apache.spark.scheduler.AsyncEventQueue.$anonfun$dispatch$1(AsyncEventQueue.scala:105) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.scheduler.AsyncEventQueue.org$apache$spark$scheduler$AsyncEventQueue$$dispatch(AsyncEventQueue.scala:100) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.$anonfun$run$1(AsyncEventQueue.scala:96) at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1446) at org.apache.spark.scheduler.AsyncEventQueue$$anon$2.run(AsyncEventQueue.scala:96)
i want to know how can i set idea scala environment correctly
*Thread Reply:* io.openlineage:openlineage_spark:0.12.0 -> could you repeat the steps with newer version?
ok,it`s my first use thie lineage tool. first,I added dependences in my pom.xml like this: <dependency> <groupId>io.openlineage</groupId> <artifactId>openlineage-java</artifactId> <version>0.12.0</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>2.7</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.7</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> <version>2.7</version> </dependency> <dependency> <groupId>io.openlineage</groupId> <artifactId>openlineage-spark</artifactId> <version>0.30.1</version> </dependency>
my spark version is 3.3.1 and the version can not change
second, in file Openlineage/intergration/spark I enter command : docker-compose up and follow the steps in this doc: https://openlineage.io/docs/integrations/spark/quickstart_local there is no erro when i use notebook to execute pyspark for openlineage and I could get json message. but after I enter "docker-compose up" ,I want to use my Idea tool to execute scala code like above,the erro happend like above. It seems that I does not configure the environment correctly. so how can i fix the problem .
*Thread Reply:* please use latest io.openlineage:openlineage_spark:1.1.0 instead. openlineage-java is already contained in the jar, no need to add it on your own.
Will the August meeting be put up at https://wiki.lfaidata.foundation/display/OpenLineage/Monthly+TSC+meeting soon? (usually it’s up in a few days 🙂
*Thread Reply:* @Michael Robinson
*Thread Reply:* The recording is on the youtube channel here. I’ll update the wiki ASAP

It sounds like there have been a few announcements at Google Next: https://cloud.google.com/data-catalog/docs/how-to/open-lineage https://cloud.google.com/dataproc/docs/guides/lineage
*Thread Reply:* https://www.youtube.com/watch?v=zvCdrNJsxBo&t=2260s

@channel The latest issue of OpenLineage News is out now! Please subscribe to get it directly in your inbox each month.
Hi guys, I'd like to capture the spark.databricks.clusterUsageTags.clusterAllTags property from databricks. However, the value of this is a list of keys, and therefore cannot be supported by custom environment facet builder.
I was thinking that capturing this property might be useful for most databricks workloads, and whether it might make sense to auto-capture it along with other databricks variables, similar to how we capture mount points for the databricks jobs.
Does this sound okay? If so, then I can help to contribute this functionality
*Thread Reply:* Sounds good to me
*Thread Reply:* Added this here: https://github.com/OpenLineage/OpenLineage/pull/2099
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
Also, another small clarification is that when using MergeIntoCommand, I'm receiving the lineage events on the backend, but I cannot seem to find any logging of the payload when I enable debug mode in openlineage. I remember there was a similar issue reported by another user in the past. May I check if it might be possible to help with this? It's making debugging quite hard for these cases. Thanks!
*Thread Reply:* I think it only depends on log4j configuration
*Thread Reply:* ```# Set everything to be logged to the console log4j.rootCategory=INFO, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
set the log level for the openlineage spark library
log4j.logger.io.openlineage.spark=DEBUG``
this is what we have inlog4j.properties` in test environment and it works
*Thread Reply:* Hmm... I can see the logs for the other commands, like createViewCommand etc. I just cannot see it for any of the delta runs
*Thread Reply:* that's interesting. So, logging is done here: https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/app/src/main/java/io/openlineage/spark/agent/EventEmitter.java#L63 and this code is unaware of delta.
The possible problem could be filtering delta events (which we do bcz of delta being noisy)
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Recently, we've closed that https://github.com/OpenLineage/OpenLineage/issues/1982 which prevents generating events for `
createOrReplaceTempView
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* and this is the code change: https://github.com/OpenLineage/OpenLineage/pull/1987/files
*Thread Reply:* Hmm I'm a little confused here. I thought we are only filtering out events for certain specific commands, like show table etc. because its noisy right? Some important commands like MergeInto or SaveIntoDataSource used to be logged before, but I notice now that its not being logged anymore... I'm using 0.23.0 openlineage version.
*Thread Reply:* yes, we do. it's just sometimes when doing a filter, we can remove too much. but SaveIntoDataSource and MergeInto should be fine, as we do check them within the tests
it looks like my dynamic task mapping in Airflow has the same run ID in marquez, so even if I am processing 100 files, there is only one version of the data. is there a way to have a separate version of each dynamic task so I can track the filename etc?
*Thread Reply:* map_index should be indeed included when calculating run ID (it’s deterministic in Airflow integration)
what version of Airflow are you using btw?
*Thread Reply:* 2.7.0
I do see this error log in all of my dynamic tasks which might explain it:
[2023-09-05, 00:31:57 UTC] {manager.py:200} ERROR - Extractor returns non-valid metadata: None
[2023-09-05, 00:31:57 UTC] {utils.py:401} ERROR - cannot import name 'get_operator_class' from 'airflow.providers.openlineage.utils' (/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/utils/__init__.py)
Traceback (most recent call last):
File "/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/utils/utils.py", line 399, in wrapper
return f(**args, ****kwargs)
^^^^^^^^^^^^^^^^^^
File "/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/plugins/listener.py", line 93, in on_running
****get_custom_facets(task_instance),
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/utils/utils.py", line 148, in get_custom_facets
custom_facets["airflow_mappedTask"] = AirflowMappedTaskRunFacet.from_task_instance(task_instance)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/plugins/facets.py", line 36, in from_task_instance
from airflow.providers.openlineage.utils import get_operator_class
ImportError: cannot import name 'get_operator_class' from 'airflow.providers.openlineage.utils' (/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/utils/__init__.py)
*Thread Reply:* I only have a few custom operators with the on_complete facet so I think this is a built in one - it runs before my task custom logs for example
*Thread Reply:* and any time I messed up my custom facet, the error would be at the bottom of the logs. this is on top, probably an on_start facet?
*Thread Reply:* seems like some circular import
*Thread Reply:* I just tested it manually, it’s a bug in OL provider. let me fix that
*Thread Reply:* cool, thanks. I am glad it is just a bug, I was afraid dynamic tasks were not supported for a minute there
*Thread Reply:* how do the provider updates work? they can be released in between Airflow releases and issues for them are raised on the main Airflow repo?
*Thread Reply:* generally speaking anything related to OL-Airflow should be placed to Airflow repo, important changes/bug fixes would be implemented in OL repo as well
*Thread Reply:* is there a way for me to install the openlineage provider based on the commit you made to fix the circular imports?
i was going to try to install from Airflow main branch but didnt want to mess anything up
*Thread Reply:* I saw it was merged to airflow main but it is not in 2.7.1 and there is no 1.0.3 provider version yet, so I wondered if I could manually install it for the time being
*Thread Reply:* https://github.com/apache/airflow/blob/main/BREEZE.rst#preparing-provider-packages building the provider package on your own could be best idea probably? that depends on how you manage your Airflow instance
*Thread Reply:* there's 1.1.0rc1 btw
*Thread Reply:* perfect, thanks. I got started with breeze but then stopped haha
*Thread Reply:* The dynamic task mapping error is gone, I did run into this:
File "/home/airflow/.local/lib/python3.11/site-packages/airflow/providers/openlineage/extractors/base.py", line 70, in disabledoperators operator.strip() for operator in conf.get("openlineage", "disabledfor_operators").split(";") ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/airflow/.local/lib/python3.11/site-packages/airflow/configuration.py", line 1065, in get raise AirflowConfigException(f"section/key [{section}/{key}] not found in config")
I am redeploying now with that option added to my config. I guess it did not use the default which should be ""
*Thread Reply:* added "disabledforoperators" to my openlineage config and it worked (using Airflow helm chart - not sure if that means there is an error because the value I provided should just be the default value, not sure why I needed to explicitly specify it)
openlineage: disabledforoperators: "" ...
this is so much better and makes a lot more sense. most of my tasks are dynamic so I was missing a lot of metadata before the fix, thanks!
Hello Everyone,
I've been diving into the Marquez codebase and found a performance bottleneck in JobDao.java for the query related to namespaceName=MyNameSpace limit=10 and 12s with limit=25. I managed to optimize it using CTEs, and the execution times dropped dramatically to 300ms (for limit=100) and under 100ms (for limit=25 ) on the same cluster.
Issue link : https://github.com/MarquezProject/marquez/issues/2608
I believe there's even more room for optimization, especially if we adjust the job_facets_view to include the namespace_name column.
Would the team be open to a PR where I share the optimized query and discuss potential further refinements? I believe these changes could significantly enhance the Marquez web UI experience.
PR link : https://github.com/MarquezProject/marquez/pull/2609
Looking forward to your feedback.
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
<a href="https://github.com/MarquezProject/marquez">MarquezProject/marquez</a>
*Thread Reply:* @Willy Lulciuc wdyt?
Has there been any conversation on the extensibility of facets/concepts? E.g.: • how does one extends the list of run states https://openlineage.io/docs/spec/run-cycle to add a paused/resumed state? • how does one extend https://openlineage.io/docs/spec/facets/run-facets/nominal_time to add a created at field?
*Thread Reply:* Hello Bernat,
The primary mechanism to extend the model is through facets. You can either: • create new standard facets in the spec: https://github.com/OpenLineage/OpenLineage/tree/main/spec/facets • create custom facets defined somewhere else with a prefix in their name: https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md#custom-facet-naming • Update existing facets with a backward compatible change (example: adding an optional field). The core spec can also be modified. Here is an example of adding a state That being said I think more granular states like pause/resume are probably better suited in a run facet. There was an issue opened for that particular one a while ago: https://github.com/OpenLineage/OpenLineage/issues/9 maybe that particular discussion can continue there.
For the nominal time facet, You could open an issue describing the use case and on community agreement follow up with a PR on the facet itself: https://github.com/OpenLineage/OpenLineage/blob/main/spec/facets/NominalTimeRunFacet.json (adding an optional field is backwards compatible)
*Thread Reply:* I see, so in general one is best copying a standard facet and maintain it under a different name. That way can be made mandatory 🙂 and one does not need to be blocked for a long time until there's a community agreement 🤔
*Thread Reply:* Yes, The goal of custom facets is to allow you to experiment and extend the spec however you want without having to wait for approval. If the custom facet is very specific to a third party project/product then it makes sense for it to stay a custom facet. If it is more generic then it makes sense to add it to the core facets as part of the spec. Hopefully community agreement can be achieved relatively quickly. Unless someone is strongly against something, it can be added without too much red tape. Typically with support in at least one of the integrations to validate the model.
@channel This month’s TSC meeting is next Thursday the 14th at 10am PT. On the tentative agenda: • announcements • recent releases • demo: Spark integration tests in Databricks runtime • open discussion • more (TBA) More info and the meeting link can be found on the website. All are welcome! Also, feel free to reply or DM me with discussion topics, agenda items, etc.
@channel The first Toronto OpenLineage Meetup, featuring a presentation by recent adopter Metaphor, is just one week away. On the agenda:
- Evolution of spec presentation/discussion (project background/history)
- State of the community
- Integrating OpenLineage with Metaphor (by special guests Ye & Ivan)
- Spark/Column lineage update
- Airflow Provider update
- Roadmap Discussion Find more details and RSVP https://www.meetup.com/openlineage/events/295488014/?utmmedium=referral&utmcampaign=share-btnsavedeventssharemodal&utmsource=link|here.
I’m seeing some odd behavior with my http transport when upgrading airflow/openlineage-airflow from 2.3.2 -> 2.6.3 and 0.24.0 -> 0.28.0. Previously I had a config like this that let me provide my own auth tokens. However, after upgrading I’m getting a 401 from the endpoint and further debugging seems to reveal that we’re not using the token provided in my TokenProvider. Does anyone know if something changed between these versions that could be causing this? (more details in 🧵 )
transport:
type: http
url: <https://my.fake-marquez-endpoint.com>
auth:
type: some.fully.qualified.classpath
*Thread Reply:* If I log this line I can tell the TokenProvider is the class instance I would expect: https://github.com/OpenLineage/OpenLineage/blob/45d94fb73b5488d34b8ca544b58317382ceb3980/client/python/openlineage/client/transport/http.py#L55
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* However, if I log the token_provider here I get the origin TokenProvider: https://github.com/OpenLineage/OpenLineage/blob/45d94fb73b5488d34b8ca544b58317382ceb3980/client/python/openlineage/client/transport/http.py#L154
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Ah I think I see the issue. Looks like this was introduced here, we are instantiating with the base token provider here when we should be using the subclass: https://github.com/OpenLineage/OpenLineage/pull/1869/files#diff-2f8ea6f9a22b5567de8ab56c6a63da8e7adf40cb436ee5e7e6b16e70a82afe05R57
*Thread Reply:* Opened a PR for this here: https://github.com/OpenLineage/OpenLineage/pull/2100
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
This particular code in docker-compose exits with code 1 because it is unable to find wait-for-it.sh, file in the container. I have checked the mounting path from the local machine, It is correct and the path on the container for Marquez is also correct i.e. /usr/src/app but it is unable to mount the wait-for-it.sh. Does anyone know why is this? This code exists in the open lineage repository as well https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/docker-compose.yml
# Marquez as an OpenLineage Client
api:
image: marquezproject/marquez
container_name: marquez-api
ports:
- "5000:5000"
- "5001:5001"
volumes:
- ./docker/wait-for-it.sh:/usr/src/app/wait-for-it.sh
links:
- "db:postgres"
depends_on:
- db
entrypoint: [ "./wait-for-it.sh", "db:5432", "--", "./entrypoint.sh" ]
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* no permissions?

I am trying to run Google Cloud Composer where i have added the openlineage-airflow pypi packagae as a dependency and have added the env OPENLINEAGEEXTRACTORS to point to my custom extractor. I have added a folder by name dependencies and inside that i have placed my extractor file, and the path given to OPENLINEAGEEXTRACTORS is dependencies.<filename>.<extractorclass_name>…still it fails with the exception saying No module named ‘dependencies’. Can anyone kindly help me out on correcting my mistake
*Thread Reply:* Hey @Guntaka Jeevan Paul, can you share some details on which versions of airflow and openlineage you’re using?
*Thread Reply:* airflow ---> 2.5.3, openlinegae-airflow ---> 1.1.0
*Thread Reply:* ```import traceback import uuid from typing import List, Optional
from openlineage.airflow.extractors.base import BaseExtractor, TaskMetadata from openlineage.airflow.utils import getjobname
class BigQueryInsertJobExtractor(BaseExtractor): def init(self, operator): super().init(operator)
@classmethod
def get_operator_classnames(cls) -> List[str]:
return ['BigQueryInsertJobOperator']
def extract(self) -> Optional[TaskMetadata]:
return None
def extract_on_complete(self, task_instance) -> Optional[TaskMetadata]:
self.log.debug(f"JEEVAN ---> extract_on_complete({task_instance})")
random_uuid = str(uuid.uuid4())
self.log.debug(f"JEEVAN ---> Randomly Generated UUID --> {random_uuid}")
self.operator.job_id = random_uuid
return TaskMetadata(
name=get_job_name(task=self.operator)
)```
*Thread Reply:* this is the custom extractor code that im trying with
*Thread Reply:* thanks @Guntaka Jeevan Paul, will try to take a deeper look tomorrow
*Thread Reply:* No module named 'dependencies'.
This sounds like general Python problem
*Thread Reply:* https://stackoverflow.com/questions/69991553/how-to-import-custom-modules-in-cloud-composer
*Thread Reply:* basically, if you're able to import the file from your dag code, OL should be able too
*Thread Reply:* The Problem is in the GCS Composer there is a component called Triggerer, which they say is used for deferrable operators…i have logged into that pod and i could see that the GCS Bucket is not mounted on this, but i am unable to understand why is the initialisation happening inside the triggerer pod
*Thread Reply:* > The Problem is in the GCS Composer there is a component called Triggerer, which they say is used for deferrable operators…i have logged into that pod and i could see that the GCS Bucket is not mounted on this, but i am unable to understand why is the initialisation happening inside the triggerer pod OL integration is not running on triggerer, only on worker and scheduler pods
*Thread Reply:* As you can see in this screenshot i am seeing the logs of the triggerer and it says clearly unable to import plugin openlineage
*Thread Reply:* I see. There are few possible things to do here - composer could mount the user files, Airflow could not start plugins on triggerer, or we could detect we're on triggerer and not import anything there. However, does it impact OL or Airflow operation in other way than this log?
*Thread Reply:* Probably we'd have to do something if that really bothers you as there won't be further changes to Airflow 2.5
*Thread Reply:* The Problem is it is actually not registering this custom extractor written by me, henceforth i am just receiving the DefaultExtractor things and my piece of extractor code is not even getting triggered
*Thread Reply:* any suggestions to try @Maciej Obuchowski
*Thread Reply:* Could you share worker logs?
*Thread Reply:* and check if module is importable from your dag code?
*Thread Reply:* these are the worker pod logs…where there is no log of openlineageplugin
*Thread Reply:* https://openlineage.slack.com/archives/C01CK9T7HKR/p1694608076879469?thread_ts=1694545905.974339&cid=C01CK9T7HKR --> sure will check now on this one
 }
}
*Thread Reply:* {
"textPayload": "Traceback (most recent call last): File \"/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/utils.py\", line 427, in import_from_string module = importlib.import_module(module_path) File \"/opt/python3.8/lib/python3.8/importlib/__init__.py\", line 127, in import_module return _bootstrap._gcd_import(name[level:], package, level) File \"<frozen importlib._bootstrap>\", line 1014, in _gcd_import File \"<frozen importlib._bootstrap>\", line 991, in _find_and_load File \"<frozen importlib._bootstrap>\", line 961, in _find_and_load_unlocked File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed File \"<frozen importlib._bootstrap>\", line 1014, in _gcd_import File \"<frozen importlib._bootstrap>\", line 991, in _find_and_load File \"<frozen importlib._bootstrap>\", line 961, in _find_and_load_unlocked File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed File \"<frozen importlib._bootstrap>\", line 1014, in _gcd_import File \"<frozen importlib._bootstrap>\", line 991, in _find_and_load File \"<frozen importlib._bootstrap>\", line 973, in _find_and_load_unlockedModuleNotFoundError: No module named 'airflow.gcs'",
"insertId": "pt2eu6fl9z5vw",
"resource": {
"type": "cloud_composer_environment",
"labels": {
"environment_name": "openlineage",
"location": "us-west1",
"project_id": "acceldata-acm"
}
},
"timestamp": "2023-09-13T06:20:44.131577764Z",
"severity": "ERROR",
"labels": {
"worker_id": "airflow-worker-xttt8"
},
"logName": "projects/acceldata-acm/logs/airflow-worker",
"receiveTimestamp": "2023-09-13T06:20:48.847319607Z"
},
it doesn't see No module named 'airflow.gcs' that is part of your extractor path airflow.gcs.dags.big_query_insert_job_extractor.BigQueryInsertJobExtractor
however, is it necessary? I generally see people using imports directly from dags folder
*Thread Reply:* yeah it would be expected to have this in triggerer where it's not mounted, but will it behave the same for worker where it's mounted?
*Thread Reply:* maybe ___init___.py is missing for top-level dag path?
*Thread Reply:* https://openlineage.slack.com/archives/C01CK9T7HKR/p1694609229577469?thread_ts=1694545905.974339&cid=C01CK9T7HKR --> you mean to make the dags folder as well like a module by adding the init.py?
*Thread Reply:* yes, I would put whole custom code directly in dags folder, to make sure import paths are the problem
*Thread Reply:* and would be nice if you could set
AIRFLOW__LOGGING__LOGGING_LEVEL="DEBUG"
*Thread Reply:* ```Starting the process, got command: triggerer Initializing airflow.cfg. airflow.cfg initialization is done. [2023-09-13T13:11:46.620+0000] {settings.py:267} DEBUG - Setting up DB connection pool (PID 8) [2023-09-13T13:11:46.622+0000] {settings.py:372} DEBUG - settings.prepareengineargs(): Using pool settings. poolsize=5, maxoverflow=10, poolrecycle=570, pid=8 [2023-09-13T13:11:46.742+0000] {cliactionloggers.py:39} DEBUG - Adding <function defaultactionlog at 0x7ff39ca1d3a0> to pre execution callback [2023-09-13T13:11:47.638+0000] {cliactionloggers.py:65} DEBUG - Calling callbacks: [<function defaultactionlog at 0x7ff39ca1d3a0>] _ |( ) _/ /_ _ _ /| |_ / / /_ _ / _ _ | /| / / _ | / _ / _ _/ _ / / // /_ |/ |/ / // |// // // // _/_/|/ [2023-09-13T13:11:50.527+0000] {pluginsmanager.py:300} DEBUG - Loading plugins [2023-09-13T13:11:50.580+0000] {pluginsmanager.py:244} DEBUG - Loading plugins from directory: /home/airflow/gcs/plugins [2023-09-13T13:11:50.581+0000] {pluginsmanager.py:224} DEBUG - Loading plugins from entrypoints [2023-09-13T13:11:50.587+0000] {pluginsmanager.py:227} DEBUG - Importing entrypoint plugin OpenLineagePlugin [2023-09-13T13:11:50.740+0000] {utils.py:430} WARNING - No module named 'boto3' [2023-09-13T13:11:50.743+0000] {utils.py:430} WARNING - No module named 'botocore' [2023-09-13T13:11:50.833+0000] {utils.py:430} WARNING - No module named 'airflow.providers.sftp' [2023-09-13T13:11:51.144+0000] {utils.py:430} WARNING - No module named 'bigqueryinsertjobextractor' [2023-09-13T13:11:51.145+0000] {pluginsmanager.py:237} ERROR - Failed to import plugin OpenLineagePlugin Traceback (most recent call last): File "/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/utils.py", line 427, in importfromstring module = importlib.importmodule(modulepath) File "/opt/python3.8/lib/python3.8/importlib/init.py", line 127, in importmodule return bootstrap.gcdimport(name[level:], package, level) File "<frozen importlib.bootstrap>", line 1014, in gcdimport File "<frozen importlib.bootstrap>", line 991, in _findandload File "<frozen importlib.bootstrap>", line 973, in findandloadunlocked ModuleNotFoundError: No module named 'bigqueryinsertjobextractor'
The above exception was the direct cause of the following exception:
Traceback (most recent call last): File "/opt/python3.8/lib/python3.8/site-packages/airflow/pluginsmanager.py", line 229, in loadentrypointplugins pluginclass = entrypoint.load() File "/opt/python3.8/lib/python3.8/site-packages/setuptools/vendor/importlibmetadata/init.py", line 194, in load module = importmodule(match.group('module')) File "/opt/python3.8/lib/python3.8/importlib/init.py", line 127, in importmodule return _bootstrap.gcdimport(name[level:], package, level) File "<frozen importlib.bootstrap>", line 1014, in gcdimport File "<frozen importlib.bootstrap>", line 991, in _findandload File "<frozen importlib.bootstrap>", line 975, in findandloadunlocked File "<frozen importlib.bootstrap>", line 671, in _loadunlocked File "<frozen importlib.bootstrapexternal>", line 843, in execmodule File "<frozen importlib.bootstrap>", line 219, in callwithframesremoved File "/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/plugin.py", line 32, in <module> from openlineage.airflow import listener File "/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/listener.py", line 75, in <module> extractormanager = ExtractorManager() File "/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/extractors/manager.py", line 16, in init self.tasktoextractor = Extractors() File "/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/extractors/extractors.py", line 122, in init extractor = importfromstring(extractor.strip()) File "/opt/python3.8/lib/python3.8/site-packages/openlineage/airflow/utils.py", line 431, in importfromstring raise ImportError(f"Failed to import {path}") from e ImportError: Failed to import bigqueryinsertjobextractor.BigQueryInsertJobExtractor [2023-09-13T13:11:51.235+0000] {pluginsmanager.py:227} DEBUG - Importing entrypoint plugin composermenuplugin [2023-09-13T13:11:51.719+0000] {pluginsmanager.py:316} DEBUG - Loading 1 plugin(s) took 1.14 seconds [2023-09-13T13:11:51.733+0000] {triggererjob.py:101} INFO - Starting the triggerer [2023-09-13T13:11:51.734+0000] {selectorevents.py:59} DEBUG - Using selector: EpollSelector [2023-09-13T13:11:56.118+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:01.359+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:06.665+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:11.880+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:17.098+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:22.323+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:27.597+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:32.826+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:38.049+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:43.275+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:48.509+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:53.867+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:12:59.087+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:04.300+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:09.539+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:14.785+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:20.007+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:25.274+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:30.510+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:35.729+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:40.960+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:46.444+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:51.751+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:13:57.084+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:02.310+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:07.535+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:12.754+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:17.967+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:23.185+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:28.406+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:33.661+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:38.883+0000] {basejob.py:240} DEBUG - [heartbeat] [2023-09-13T13:14:44.247+0000] {base_job.py:240} DEBUG - [heartbeat]```
*Thread Reply:* still the same error in the triggerer pod
*Thread Reply:* > still the same error in the triggerer pod it won't change, we're not trying to fix the triggerer import but worker, and should look only at worker pod at this point
*Thread Reply:* ```extractor for <class 'airflow.providers.google.cloud.operators.bigquery.BigQueryInsertJobOperator'> is <class 'bigqueryinsertjobextractor.BigQueryInsertJobExtractor'
Using extractor BigQueryInsertJobExtractor tasktype=BigQueryInsertJobOperator airflowdagid=dataanalyticsdag taskid=joinbqdatasets.bqjoinholidaysweatherdata2021 airflowrunid=manual_2023-09-13T13:24:08.946947+00:00
fatal: not a git repository (or any parent up to mount point /home/airflow) Stopping at filesystem boundary (GITDISCOVERYACROSSFILESYSTEM not set). fatal: not a git repository (or any parent up to mount point /home/airflow) Stopping at filesystem boundary (GITDISCOVERYACROSSFILESYSTEM not set).```
*Thread Reply:* able to see these logs in the worker pod…so what you said is right that it is able to get the extractor but i get the below error immediately where it says not a git repository
*Thread Reply:* seems like we are almost there nearby…am i missing something obvious
*Thread Reply:* > fatal: not a git repository (or any parent up to mount point /home/airflow)
> Stopping at filesystem boundary (GIT_DISCOVERY_ACROSS_FILESYSTEM not set).
> fatal: not a git repository (or any parent up to mount point /home/airflow)
> Stopping at filesystem boundary (GIT_DISCOVERY_ACROSS_FILESYSTEM not set).
hm, this could be the actual bug?
*Thread Reply:* that’s casual log in composer
*Thread Reply:* extractor for <class 'airflow.providers.google.cloud.operators.bigquery.BigQueryInsertJobOperator'> is <class 'big_query_insert_job_extractor.BigQueryInsertJobExtractor'
that’s actually class from your custom module, right?
*Thread Reply:* I have this extractor detected as expected
*Thread Reply:* seens as <class 'dependencies.bq.BigQueryInsertJobExtractor'>
*Thread Reply:* no __init__.py in base dags folder
*Thread Reply:* I also checked that triggerer pod indeed has no gcsfuse set up, tbh no idea why, maybe some kind of optimization the only effect is that when loading plugins in triggerer it throws some errors in logs, we don’t do anything at the moment there
*Thread Reply:* okk…got it @Jakub Dardziński…so the init at the top level of dags is as well not reqd, got it. Just one more doubt, there is a requirement where i want to change the operators property in the extractor inside the extract function, will that be taken into account and the operator’s execute be called with the property that i have populated in my extractor?
*Thread Reply:* for example i want to add a custom jobid to the BigQueryInsertJobOperator, so wheneerv someone uses the BigQueryInsertJobOperator operator i want to intercept that and add this jobid property to the operator…will that work?
*Thread Reply:* I’m not sure if using OL for such thing is best choice. Wouldn’t it be better to subclass the operator?
*Thread Reply:* but the answer is: it dependes on the airflow version, in 2.3+ I’m pretty sure the changed property stays in execute method
*Thread Reply:* yeah ideally that is how we should have done this but the problem is our client is having around 1000+ Dag’s in different google cloud projects, which are owned by multiple teams…so they are not willing to change anything in their dag. Thankfully they are using airflow 2.4.3
*Thread Reply:* task_policy might be better tool for that: https://airflow.apache.org/docs/apache-airflow/2.6.0/administration-and-deployment/cluster-policies.html
*Thread Reply:* btw I double-checked - execute method is in different process so this would not change task’s attribute there
*Thread Reply:* @Jakub Dardziński any idea how can we achieve this one. ---> https://openlineage.slack.com/archives/C01CK9T7HKR/p1694849427228709
 }
}
@here has anyone succeded in getting a custom extractor to work in GCP Cloud Composer or AWS MWAA, seems like there is no way
*Thread Reply:* I'm getting quite close with MWAA. See https://openlineage.slack.com/archives/C01CK9T7HKR/p1692743745585879.
 }
}

I am exploring Spark - OpenLineage integration (using the latest PySpark and OL versions). I tested a simple pipeline which:
• Reads JSON data into PySpark DataFrame
• Apply data transformations
• Write transformed data to MySQL database
Observed that we receive 4 events (2 START and 2 COMPLETE) for the same job name. The events are almost identical with a small diff in the facets. All the events share the same runId, and we don't get any parentRunId.
Team, can you please confirm if this behaviour is expected? Seems to be different from the Airflow integration where we relate jobs to Parent Jobs.
*Thread Reply:* The Spark integration requires that two parameters are passed to it, namely:
spark.openlineage.parentJobName
spark.openlineage.parentRunId
You can find the list of parameters here:
https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/README.md
*Thread Reply:* As for double accounting of events - that's a bit harder to diagnose.
*Thread Reply:* Can you share the the job and events? Also @Paweł Leszczyński
*Thread Reply:* Hi @Suraj Gupta,
Thanks for providing such a detailed description of the problem.
It is not expected behaviour, it's an issue. The events correspond to the same logical plan which for some reason lead to sending two OL events. Is it reproducible aka. does it occur each time? If yes, we please feel free to raise an issue for that.
We have added in recent months several tests to verify amount of OL events being generated but we haven't tested it that way with JDBC. BTW. will the same happen if you write your data df_transformed to a file (like parquet file) ?
*Thread Reply:* Thanks @Paweł Leszczyński, will confirm about writing to file and get back.
*Thread Reply:* And yes, the issue is reproducible. Will raise an issue for this.
*Thread Reply:* even if you write onto a file?
*Thread Reply:* Yes, even when I write to a parquet file.
*Thread Reply:* ok. i think i was able to reproduce it locally with https://github.com/OpenLineage/OpenLineage/pull/2103/files
*Thread Reply:* Opened an issue: https://github.com/OpenLineage/OpenLineage/issues/2104
*Thread Reply:* @Paweł Leszczyński I see that the PR is work in progress. Any rough estimate on when we can expect this fix to be released?
*Thread Reply:* @Suraj Gupta put a comment within your issue. it's a bug we need to solve but I cannot bring any estimates today.
*Thread Reply:* Thanks for update @Paweł Leszczyński, also please look into this comment. It might related and I'm not sure if expected behaviour.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
@channel This month’s TSC meeting, open to all, is tomorrow: https://openlineage.slack.com/archives/C01CK9T7HKR/p1694113940400549
Context:
We use Spark with YARN, running on Hadoop 2.x (I can't remember the exact minor version) with Hive support.
Problem:
I'm noticed that CreateDataSourceAsSelectCommand objects are always transformed to an OutputDataset with a namespace value set to file - which is curious, because the inputs always have a (correct) namespace of hdfs://<name-node> - is this a known issue? A flaw with Apache Spark? A bug in the resolution logic?
For reference:
```public class CreateDataSourceTableCommandVisitor extends QueryPlanVisitor<CreateDataSourceTableCommand, OpenLineage.OutputDataset> {
public CreateDataSourceTableCommandVisitor(OpenLineageContext context) { super(context); }
@Override public List<OpenLineage.OutputDataset> apply(LogicalPlan x) { CreateDataSourceTableCommand command = (CreateDataSourceTableCommand) x; CatalogTable catalogTable = command.table();
return Collections.singletonList(
outputDataset()
.getDataset(
PathUtils.fromCatalogTable(catalogTable),
catalogTable.schema(),
OpenLineage.LifecycleStateChangeDatasetFacet.LifecycleStateChange.CREATE));
}
}``
Running this:cat events.log | jq '{eventTime: .eventTime, eventType: .eventType, runId: .run.runId, jobNamespace: .job.namespace, jobName: .job.name, outputs: .outputs[] | {namespace: .namespace, name: .name}, inputs: .inputs[] | {namespace: .namespace, name: .name}}'`
This is an output:
{
"eventTime": "2023-09-13T16:01:27.059Z",
"eventType": "START",
"runId": "bbbb5763-3615-46c0-95ca-1fc398c91d5d",
"jobNamespace": "spark.cluster-1",
"jobName": "ol_hadoop_test.execute_create_data_source_table_as_select_command.dhawes_db_ol_test_hadoop_tgt",
"outputs": {
"namespace": "file",
"name": "/user/hive/warehouse/dhawes.db/ol_test_hadoop_tgt"
},
"inputs": {
"namespace": "<hdfs://nn1>",
"name": "/user/hive/warehouse/dhawes.db/ol_test_hadoop_src"
}
}
*Thread Reply:* Seems like an issue on our side. Do you know how the source is read? What LogicalPlan leaf is used to read src? Would love to find how is this done differently
*Thread Reply:* Hmm, I'll have to do explain plan to see what exactly it is.
However my sample job uses spark.sql("SELECT ** FROM dhawes.ol_test_hadoop_src")
which itself is created using
spark.sql("SELECT 1 AS id").write.format("orc").mode("overwrite").saveAsTable("dhawes.ol_test_hadoop_src")
*Thread Reply:* ``>>> spark.sql("SELECT ** FROM dhawes.ol_test_hadoop_src").explain(True)
== Parsed Logical Plan ==
'Project [**]
+- 'UnresolvedRelationdhawes.oltesthadoop_src`
== Analyzed Logical Plan ==
id: int
Project [id#3]
+- SubqueryAlias dhawes.ol_test_hadoop_src
+- Relation[id#3] orc
== Optimized Logical Plan == Relation[id#3] orc
== Physical Plan ==
**(1) FileScan orc dhawes.oltesthadoop_src[id#3] Batched: true, Format: ORC, Location: InMemoryFileIndex[

Hey everyone, Any chance we could have a openlineage-integration-common 1.1.1 release with the following changes..? • https://github.com/OpenLineage/OpenLineage/pull/2106 • https://github.com/OpenLineage/OpenLineage/pull/2108
*Thread Reply:* Specially the first PR is affecting users of the astronomer-cosmos library: https://github.com/astronomer/astronomer-cosmos/issues/533
*Thread Reply:* Thanks @tati for requesting your first OpenLineage release! Three +1s from committers will authorize
*Thread Reply:* The release is authorized and will be initiated within two business days.
*Thread Reply:* Thanks a lot, @Michael Robinson!
Per discussion in the OpenLineage sync today here is a very early strawman proposal for an OpenLineage registry that producers and consumers could be registered in. Feedback or alternate proposals welcome https://docs.google.com/document/d/1zIxKST59q3I6ws896M4GkUn7IsueLw8ejct5E-TR0vY/edit Once this is sufficiently fleshed out, I’ll create an actual proposal on github
*Thread Reply:* I have cleaned up the registry proposal.
https://docs.google.com/document/d/1zIxKST59q3I6ws896M4GkUn7IsueLw8ejct5E-TR0vY/edit
In particular:
• I clarified that option 2 is preferred at this point.
• I moved discussion notes to the bottom. they will go away at some point
• Once it is stable, I’ll create a proposal with the preferred option.
• we need a good proposal for the core facets prefix. My suggestion is to move core facets to core in the registry. The drawback is prefix would be inconsistent.
*Thread Reply:* I have created a ticket to make this easier to find. Once I get more feedback I’ll turn it into a md file in the repo: https://docs.google.com/document/d/1zIxKST59q3I6ws896M4GkUn7IsueLw8ejct5E-TR0vY/edit#heading=h.enpbmvu7n8gu https://github.com/OpenLineage/OpenLineage/issues/2161
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
@channel Friendly reminder: the next OpenLineage meetup, our first in Toronto, is happening this coming Monday at 5 PM ET https://openlineage.slack.com/archives/C01CK9T7HKR/p1694441261486759
@here we have dataproc operator getting called from a dag which submits a spark job, we wanted to maintain that continuity of parent job in the spark job so according to the documentation we can acheive that by using a macro called lineagerunid that requires task and taskinstance as the parameters. The problem we are facing is that our client’s have 1000's of dags, so asking them to change this everywhere it is used is not feasible, so we thought of using the taskpolicy feature in the airflow…but the problem is that taskpolicy gives you access to only the task/operator, but we don’t have the access to the task instance..that is required as a parameter to the lineagerun_id function. Can anyone kindly help us on how should we go about this one
t1 = DataProcPySparkOperator(
task_id=job_name,
<b>#required</b> pyspark configuration,
job_name=job_name,
dataproc_pyspark_properties={
'spark.driver.extraJavaOptions':
f"-javaagent:{jar}={os.environ.get('OPENLINEAGE_URL')}/api/v1/namespaces/{os.getenv('OPENLINEAGE_NAMESPACE', 'default')}/jobs/{job_name}/runs/{{{{macros.OpenLineagePlugin.lineage_run_id(task, task_instance)}}}}?api_key={os.environ.get('OPENLINEAGE_API_KEY')}"
dag=dag)
*Thread Reply:* you don't need actual task instance to do that. you only should set additional argument as jinja template, same as above
*Thread Reply:* task_instance in this case is just part of string which is evaluated when jinja render happens
*Thread Reply:* ohh…then we could use the same example as above inside the task_policy to intercept the Operator and add the openlineage specific additions properties?
*Thread Reply:* correct, just remember not to override all properties, just add ol specific
*Thread Reply:* yeah sure…thank you so much @Jakub Dardziński, will try this out and keep you posted
*Thread Reply:* We want to automate setting those options at some point inside the operator itself
@here is there a way by which we could add custom headers to openlineage client in airflow, i see that provision is there for spark integration via these properties spark.openlineage.transport.headers.xyz --> abcdef
*Thread Reply:* there’s no out-of-the-box possibility to do that yet, you’re very welcome to create an issue in GitHub and maybe contribute as well! 🙂
It doesn't seem like there's a way to override the OL endpoint from the default (/api/v1/lineage) in Airflow? I tried setting the OPENLINEAGE_ENDPOINT environment to no avail. Based on this statement, it seems that only OPENLINEAGE_URL was used to construct HttpConfig ?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* That’s correct. For now there’s no way to configure the endpoint via env var. You can do that by using config file
*Thread Reply:* How do you do that in Airflow? Any particular reason for excluding endpoint override via env var? Happy to create a PR to fix that.
*Thread Reply:* historical I guess? go for the PR, of course 🚀
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/2151
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hi! I'm in need of help with wrapping my head around OpenLineage. My team have the goal of collecting metadata from the Airflow operators GreatExpectationsOperator, PythonOperator, MsSqlOperator and BashOperator (for dbt). Where can I see the sourcecode for what is collected for each operator, and is there support for these in the new provider apache-airflow-providers-openlineage? I am super confused and feel lost in the docs. 🤯 We are using MSSQL/ODBC to connect to our db, and this data does not seem to appear as datasets in Marquez, do I need to configure this? If so, HOW and WHERE? 🥲
Happy for any help, big or small! 🙏
*Thread Reply:* there’s no actual single source of what integrations are currently implemented in openlineage Airflow provider. That’s something we should work on so it’s more visible
*Thread Reply:* answering this quickly - GE & MS SQL are not currently implemented yet in the provider
*Thread Reply:* but I also invite you to contribute if you’re interested! 🙂

Hi I need help in extracting OpenLineage for PostgresOperator in json format. any suggestions or comments would be greatly appreciated
*Thread Reply:* If you're using Airflow 2.7, take a look at https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/guides/user.html
*Thread Reply:* If you use one of the lower versions, take a look here https://openlineage.io/docs/integrations/airflow/usage
*Thread Reply:* Maciej, Thanks for sharing the link https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/guides/user.html this should address the issue
congrats folks 🥳 https://lfaidata.foundation/blog/2023/09/20/lf-ai-data-foundation-announces-graduation-of-openlineage-project
@channel
We released OpenLineage 1.2.2!
Added
• Spark: publish the ProcessingEngineRunFacet as part of the normal operation of the OpenLineageSparkEventListener #2089 @d-m-h
• Spark: capture and emit spark.databricks.clusterUsageTags.clusterAllTags variable from databricks environment #2099 @Anirudh181001
Fixed
• Common: support parsing dbt_project.yml without target-path #2106 @tatiana
• Proxy: fix Proxy chart #2091 @harels
• Python: fix serde filtering #2044 @xli-1026
• Python: use non-deprecated apiKey if loading it from env variables @2029 @mobuchowski
• Spark: Improve RDDs on S3 integration. #2039 @pawel-big-lebowski
• Flink: prevent sending running events after job completes #2075 @pawel-big-lebowski
• Spark & Flink: Unify dataset naming from URI objects #2083 @pawel-big-lebowski
• Spark: Databricks improvements #2076 @pawel-big-lebowski
Removed
• SQL: remove sqlparser dependency from iface-java and iface-py #2090 @JDarDagran
Thanks to all the contributors, including new contributors @tati, @xli-1026, and @d-m-h!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.2.2
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.1.0...1.2.2
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/

*Thread Reply:* Hi @Michael Robinson Thank you! I love the job that you’ve done. If you have a few seconds, please hint at how I can push lineage gathered from Airflow and Spark jobs into DataHub for visualization? I didn’t find any solutions or official support neither at Openlineage nor at DataHub, but I still want to continue using Openlineage
*Thread Reply:* Hi Yevhenii, thank you for using OpenLineage. The DataHub integration is new to us, but perhaps the experts on Spark and Airflow know more. @Paweł Leszczyński @Maciej Obuchowski @Jakub Dardziński
*Thread Reply:* @Yevhenii Soboliev at Airflow Summit, Shirshanka Das from DataHub mentioned this as upcoming feature.
Hi, we're using Custom Operators in airflow(2.5) and are planning to expose lineage via default extractors: https://openlineage.io/docs/integrations/airflow/default-extractors/ Question: Now if we upgrade our Airflow version to 2.7 in the future, would our code be backward compatible? Since OpenLineage has now moved inside airflow and I think there is no concept of extractors in the latest version.
*Thread Reply:* Also, do we have any docs on how OL works with the latest airflow version? Few questions: • How is it replacing the concept of custom extractors and Manually Annotated Lineage in the latest version? • Do we have any examples of setting up the integration to emit input/output datasets for non supported Operators like PythonOperator?
*Thread Reply:* > Question: Now if we upgrade our Airflow version to 2.7 in the future, would our code be backward compatible?
It will be compatible, “default extractors” is generally the same concept as we’re using in the 2.7 integration.
One thing that might be good to update is import paths, from openlineage.airflow to airflow.providers.openlineage but should work both ways
> • Do we have any code samples/docs of setting up the integration to emit input/output datasets for non supported Operators like PythonOperator? Our experience with that is currently lacking - this means, it works like in bare airflow, if you annotate your PythonOperator tasks with old Airflow lineage like in this doc.
We want to make this experience better - by doing few things • instrumenting hooks, then collecting lineage from them • integration with AIP-48 datasets • allowing to emit lineage collected inside Airflow task by other means, by providing core Airflow API for that All those things require changing core Airflow in a couple of ways: • tracking which hooks were used during PythonOperator execution • just being able to emit datasets (airflow inlets/outlets) from inside of a task - they are now a static thing, so if you try that it does not work • providing better API for emitting that lineage, preferably based on OpenLineage itself rather than us having to convert that later. As this requires core Airflow changes, it won’t be live until Airflow 2.8 at the earliest.
thanks to @Maciej Obuchowski for this response

I am using this accelerator that leverages OpenLineage on Databricks to publish lineage info to Purview, but it's using a rather old version of OpenLineage aka 0.18, anybody has tried it on a newer version of OpenLineage? I am facing some issues with the inputs and outputs for the same object is having different json https://github.com/microsoft/Purview-ADB-Lineage-Solution-Accelerator/
I installed 1.2.2 on Databricks, followed the below init script: https://github.com/OpenLineage/OpenLineage/blob/main/integration/spark/databricks/open-lineage-init-script.sh
my cluster config looks like this:
spark.openlineage.version v1 spark.openlineage.namespace adb-5445974573286168.8#default spark.openlineage.endpoint v1/lineage spark.openlineage.url.param.code 8kZl0bo2TJfnbpFxBv-R2v7xBDj-PgWMol3yUm5iP1vaAzFu9kIZGg== spark.openlineage.url https://f77b-50-35-69-138.ngrok-free.app
But it is not calling the API, it works fine with 0.18 version
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* this issue is resolved, solution can be found here: https://openlineage.slack.com/archives/C01CK9T7HKR/p1691592987038929
 }
}
*Thread Reply:* We were all out at Airflow Summit last week, so apologies for the delayed response. Glad you were able to resolve the issue!

@here I'm presently addressing a particular scenario that pertains to Openlineage authentication, specifically involving the use of an access key and secret.
I've implemented a custom token provider called AccessKeySecretKeyTokenProvider, which extends the TokenProvider class. This token provider communicates with another service, obtaining a token and an expiration time based on the provided access key, secret, and client ID.
My goal is to retain this token in a cache prior to its expiration, thereby eliminating the need for network calls to the third-party service. Is it possible without relying on an external caching system.
*Thread Reply:* Hey @Sangeeta Mishra, I’m not sure that I fully understand your question here. What do you mean by OpenLineage authentication? What are you using to generate OL events? What’s your OL receiving backend?
*Thread Reply:* Hey @Harel Shein, I wanted to clarify the previous message. I apologize for any confusion. When I mentioned "OpenLineage authentication," I was actually referring to the authentication process for the OpenLineage backend, specifically using HTTP transport. This involves using my custom token provider, which utilizes access keys and secrets for authentication. The OL backend is http based backend . I hope this clears things up!
*Thread Reply:* We are trying to leverage our own backend here.
*Thread Reply:* I see.. I’m not sure the OpenLineage community could help here. Which webserver framework are you using?
*Thread Reply:* Our backend authentication operates based on either a pair of keys or a single bearer token, with a limited time of expiry. Hence, wanted to cache this information inside the token provider.
*Thread Reply:* I see, I would ask this question here https://ktor.io/support/

*Thread Reply:* @Sangeeta Mishra which openlineage client are you using: java or python?
*Thread Reply:* @Paweł Leszczyński I am using python client
I'm using the Spark OpenLineage integration. In the outputStatistics output dataset facet we receive rowCount and size.
The Job performs a SQL insert into a MySQL table and I'm receiving the size as 0.
{
"outputStatistics":
{
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.1.0/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/OutputStatisticsOutputDatasetFacet.json#/$defs/OutputStatisticsOutputDatasetFacet>",
"rowCount": 1,
"size": 0
}
}
I'm not sure what the size means here. Does this mean number of bytes inserted/updated?
Also, do we have any documentation for Spark specific Job and Run facets?
*Thread Reply:* I am not sure it's stated in the doc. Here's the list of spark facets schemas: https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark/shared/facets/spark/v1
@here In Airflow Integration we send across a lineage Event for Dag start and complete, but that is not the case with spark integration…we don’t receive any event for the application start and complete in spark…is this expected behaviour or am i missing something?
*Thread Reply:* For spark we do send start and complete for each spark action being run (single operation that causes spark processing being run). However, it is difficult for us to know if we're dealing with the last action within spark job or a spark script.
*Thread Reply:* I think we need to look deeper into that as there is reoccuring need to capture such information
*Thread Reply:* and spark listener event has methods like onApplicationStart and onApplicationEnd
*Thread Reply:* We are using the SparkListener, which has a function called OnApplicationStart which gets called whenever a spark application starts, so i was thinking why cant we send one at start and simlarly at end as well
*Thread Reply:* additionally, we would like to have a concept of a parent run for a spark job which aggregates all actions run within a single spark job context
*Thread Reply:* yeah exactly. the way that it works with airflow integration
*Thread Reply:* we do have an issue for that https://github.com/OpenLineage/OpenLineage/issues/2105
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* what you can is: come to our monthly Openlineage open meetings and raise that issue and convince the community about its importance
*Thread Reply:* yeah sure would love to do that…how can i join them, will that be posted here in this slack channel?
*Thread Reply:* Hi, you can see the schedule and RSVP here: https://openlineage.io/community
Meetup recap: Toronto Meetup @ Airflow Summit, September 18, 2023 It was great to see so many members of our community at this event! I counted 32 total attendees, with all but a handful being first-timers. Topics included: • Presentation on the history, architecture and roadmap of the project by @Julien Le Dem and @Harel Shein • Discussion of OpenLineage support in Marquez by @Willy Lulciuc • Presentation by Ye Liu and Ivan Perepelitca from Metaphor, the social platform for data, about their integration • Presentation by @Paweł Leszczyński about the Spark integration • Presentation by @Maciej Obuchowski about the Apache Airflow Provider Thanks to all the presenters and attendees with a shout out to @Harel Shein for the help with organizing and day-of logistics, @Jakub Dardziński for the help with set up/clean up, and @Sheeri Cabral (Collibra) for the crucial assist with the signup sheet. This was our first meetup in Toronto, and we learned some valuable lessons about planning events in new cities — the first and foremost being to ask for a pic of the building! 🙂 But it seemed like folks were undeterred, and the space itself lived up to expectations. For a recording and clips from the meetup, head over to our YouTube channel. Upcoming events: • October 5th in San Francisco: Marquez Meetup @ Astronomer (sign up https://www.meetup.com/meetup-group-bnfqymxe/events/295444209/?utmmedium=referral&utmcampaign=share-btnsavedeventssharemodal&utmsource=link|here) • November: Warsaw meetup (details, date TBA) • January: London meetup (details, date TBA) Are you interested in hosting or co-hosting an OpenLineage or Marquez meetup? DM me!


Hi folks, am I correct in my observations that the Spark integration does not generate inputs and outputs for Kafka-to-Kafka pipelines?
EDIT: Removed the crazy wall of text. Relevant GitHub issue is here.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* responded within the issue

Hello community First time poster - bear with me :)
I am looking to make a minor PR on the airflow integration (fixing github #2130), and the code change is easy enough, but I fail to install the python environment. I have tried the simple ones
OpenLineage/integration/airflow > pip install -e .
or
OpenLineage/integration/airflow > pip install -r dev-requirements.txt
but they both fail on
ERROR: No matching distribution found for openlineage-sql==1.3.0
(which I think is an unreleased version in the git project)
How would I go about to install the requirements?
//Erik
PS. Sorry for posting this in general if there is a specific integration or contribution channel - I didnt find a better channel
*Thread Reply:* Hi @Erik Alfthan, the channel is totally OK. I am not airflow integration expert, but what it looks to me, you're missing openlineage-sql library, which is a rust library used to extract lineage from sql queries. This is how we do that in circle ci: https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/8080/workflows/aba53369-836c-48f5-a2dd-51bc0740a31c/jobs/140113
and subproject page with build instructions: https://github.com/OpenLineage/OpenLineage/tree/main/integration/sql
*Thread Reply:* Ok, so I go and "manually" build the internal dependency so that it becomes available in the pip cache?
I was hoping for something more automagical, but that should work
*Thread Reply:* I think so. @Jakub Dardziński am I right?
*Thread Reply:* https://openlineage.io/docs/development/developing/python/setup there’s a guide how to setup the dev environment
> Typically, you first need to build openlineage-sql locally (see README). After each release you have to repeat this step in order to bump local version of the package.
This might be somewhat exposed more in GitHub repository README as well
*Thread Reply:* It didnt find the wheel in the cache, but if I used the line in the sql/README.md
pip install openlineage-sql --no-index --find-links ../target/wheels --force-reinstall
It is installed and thus skipped/passed when pip later checks if it needs to be installed.
Now I have a second issue because it is expecting me to have mysqlclient-2.2.0 which seems to need a binary
Command 'pkg-config --exists mysqlclient' returned non-zero exit status 127
and
Command 'pkg-config --exists mariadb' returned non-zero exit status 127
I am on Ubuntu 22.04 in WSL2. Should I go to apt and grab me a mysql client?
*Thread Reply:* > It didnt find the wheel in the cache, but if I used the line in the sql/README.md
> pip install openlineage-sql --no-index --find-links ../target/wheels --force-reinstall
> It is installed and thus skipped/passed when pip later checks if it needs to be installed.
That’s actually expected. You should build new wheel locally and then install it.
> Now I have a second issue because it is expecting me to have mysqlclient-2.2.0 which seems to need a binary
> Command 'pkg-config --exists mysqlclient' returned non-zero exit status 127
> and
> Command 'pkg-config --exists mariadb' returned non-zero exit status 127
> I am on Ubuntu 22.04 in WSL2. Should I go to apt and grab me a mysql client?
We’ve left some system specific configuration, e.g. mysqlclient, to users as it’s a bit aside from OpenLineage and more of general development task.
probably
sudo apt-get install python3-dev default-libmysqlclient-dev build-essential
should work
*Thread Reply:* I just realized that I should probably skip setting up my wsl and just run the tests in the docker setup you prepared
*Thread Reply:* You could do that as well but if you want to test your changes vs many Airflow versions that wouldn’t be possible I think (run them with tox btw)
*Thread Reply:* This is starting to feel like a rabbit hole 😞
When I run tox, I get a lot of build errors • client needs to be built • sql needs to be built to a different target than its readme says • a lot of builds fail on cython_sources
*Thread Reply:* would you like to share some exact log lines? I’ve never seen such errors, they probably are system specific
*Thread Reply:* Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [62 lines of output]
/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/config/setupcfg.py:293: _DeprecatedConfig: Deprecated config insetup.cfg`
!!`
`****************************************************************************************************************************************************************`
`The license_file parameter is deprecated, use license_files instead.`
`By 2023-Oct-30, you need to update your project and remove deprecated calls`
`or your builds will no longer be supported.`
`See <https://setuptools.pypa.io/en/latest/userguide/declarative_config.html> for details.`
`****************************************************************************************************************************************************************`
`!!`
`parsed = self.parsers.get(option_name, lambda x: x)(value)`
`running egg_info`
`writing lib3/PyYAML.egg-info/PKG-INFO`
`writing dependency_links to lib3/PyYAML.egg-info/dependency_links.txt`
`writing top-level names to lib3/PyYAML.egg-info/top_level.txt`
`Traceback (most recent call last):`
`File "/home/obr_erikal/projects/OpenLineage/integration/airflow/.tox/py3-airflow-2.1.4/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 353, in <module>`
`main()`
`File "/home/obr_erikal/projects/OpenLineage/integration/airflow/.tox/py3-airflow-2.1.4/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 335, in main`
`json_out['return_val'] = hook(****hook_input['kwargs'])`
`File "/home/obr_erikal/projects/OpenLineage/integration/airflow/.tox/py3-airflow-2.1.4/lib/python3.10/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 118, in get_requires_for_build_wheel`
`return hook(config_settings)`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 355, in get_requires_for_build_wheel`
`return self._get_build_requires(config_settings, requirements=['wheel'])`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 325, in _get_build_requires`
`self.run_setup()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/build_meta.py", line 341, in run_setup`
`exec(code, locals())`
`File "<string>", line 271, in <module>`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/__init__.py", line 103, in setup`
`return distutils.core.setup(****attrs)`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/core.py", line 185, in setup`
`return run_commands(dist)`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/core.py", line 201, in run_commands`
`dist.run_commands()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/dist.py", line 969, in run_commands`
`self.run_command(cmd)`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/dist.py", line 989, in run_command`
`super().run_command(command)`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/dist.py", line 988, in run_command`
`cmd_obj.run()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/command/egg_info.py", line 318, in run`
`self.find_sources()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/command/egg_info.py", line 326, in find_sources`
`mm.run()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/command/egg_info.py", line 548, in run`
`self.add_defaults()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/command/egg_info.py", line 586, in add_defaults`
`sdist.add_defaults(self)`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/command/sdist.py", line 113, in add_defaults`
`super().add_defaults()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/command/sdist.py", line 251, in add_defaults`
`self._add_defaults_ext()`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/command/sdist.py", line 336, in _add_defaults_ext`
`self.filelist.extend(build_ext.get_source_files())`
`File "<string>", line 201, in get_source_files`
`File "/tmp/pip-build-env-q1pay0xo/overlay/lib/python3.10/site-packages/setuptools/_distutils/cmd.py", line 107, in __getattr__`
`raise AttributeError(attr)`
`AttributeError: cython_sources`
`[end of output]`
note: This error originates from a subprocess, and is likely not a problem with pip.
py3-airflow-2.1.4: exit 1 (7.85 seconds) /home/obr_erikal/projects/OpenLineage/integration/airflow> python -m pip install --find-links target/wheels/ --find-links ../sql/iface-py/target/wheels --use-deprecated=legacy-resolver --constraint=<https://raw.githubusercontent.com/apache/airflow/constraints-2.1.4/constraints-3.8.txt> apache-airflow==2.1.4 'mypy>=0.9.6' pytest pytest-mock -r dev-requirements.txt pid=368621
py3-airflow-2.1.4: FAIL ✖ in 7.92 seconds
*Thread Reply:* Then, for the actual error in my PR: Evidently you are not using isort, so what linter/fixer should I use for imports?
*Thread Reply:* for the error - I think there’s a mistake in the docs. Could you please run maturin build --out target/wheels as a temp solution?
*Thread Reply:* we’re using ruff , tox runs it as one of commands
*Thread Reply:* Not in the airflow folder?
OpenLineage/integration/airflow$ maturin build --out target/wheels
💥 maturin failed
Caused by: pyproject.toml at /home/obr_erikal/projects/OpenLineage/integration/airflow/pyproject.toml is invalid
Caused by: TOML parse error at line 1, column 1
|
1 | [tool.ruff]
| ^
missing fieldbuild-system``
*Thread Reply:* I meant change here https://github.com/OpenLineage/OpenLineage/blob/main/integration/sql/README.md
so
cd iface-py
python -m pip install maturin
maturin build --out ../target/wheels
becomes
cd iface-py
python -m pip install maturin
maturin build --out target/wheels
tox runs
install_command = python -m pip install {opts} --find-links target/wheels/ \
--find-links ../sql/iface-py/target/wheels
but it should be
install_command = python -m pip install {opts} --find-links target/wheels/ \
--find-links ../sql/target/wheels
actually and I’m posting PR to fix that
*Thread Reply:* yes, that part I actually worked out myself, but the cython_sources error I fail to understand cause. I have python3-dev installed on WSL Ubuntu with python version 3.10.12 in a virtualenv. Anything in that that could cause issues?
*Thread Reply:* looks like it has something to do with latest release of Cython?
pip install "Cython<3" maybe solves the issue?
*Thread Reply:* I didnt have any cython before the install. Also no change. Could it be some update to setuptools itself? seems like the depreciation notice and the error is coming from inside setuptools
*Thread Reply:* (I.e. I tried the pip install "Cython<3" command without any change in the output )
*Thread Reply:* Applying ruff lint on the converter.py file fixed the issue on the PR though so unless you have any feedback on the change itself, I will set it up on my own computer later instead (right now doing changes on behalf of a client on the clients computer)
If the issue persists on my own computer, I'll dig a bit further
*Thread Reply:* It’s a bit hard for me to find the root cause as I cannot reproduce this locally and CI works fine as well
*Thread Reply:* Yeah, I am thinking that if I run into the same problem "at home", I might find it worthwhile to understand the issue. Right now, the client only wants the fix.
*Thread Reply:* Is there an official release cycle?
or more specific, given that the PRs are approved, how soon can they reach openlineage-dbt and apache-airflow-providers-openlineage ?
*Thread Reply:* we need to differentiate some things:
- OpenLineage repository: a. dbt integration - this is the only place where it is maintained b. Airflow integration - here we only keep backwards compatibility but generally speaking starting from Airflow 2.7+ we would like to do all the job in Airflow repo as OL Airflow provider
- Airflow repository - there’s only Airflow Openlineage provider compatible (and works best) with Airflow 2.7+
we have control over releases (obviously) in OL repo - it’s monthly cycle so beginning next week that should happen. There’s also a possibility to ask for ad-hoc release in #general slack channel and with approvals of committers the new version is also released
For Airflow providers - the cycle is monthly as well
*Thread Reply:* it’s a bit complex for this split but needed temporarily
*Thread Reply:* oh, I did the fix in the wrong place! The client is on airflow 2.7 and is using the provider. Is it syncing?
*Thread Reply:* it’s not, two separate places a~nd we haven’t even added the whole thing with converting old lineage objects to OL specific~
editing, that’s not true
*Thread Reply:* the code’s here: https://github.com/apache/airflow/blob/main/airflow/providers/openlineage/extractors/manager.py#L154
<a href="https://github.com/apache/airflow">apache/airflow</a>
*Thread Reply:* sorry I did not mention this earlier. we definitely need to add some guidance how to proceed with contributions to OL and Airflow OL provider
*Thread Reply:* anyway, the dbt fix is the blocking issue, so if that parts comes next week, there is no real urgency in getting the columns. It is a nice to have for our ingest parquet files.
*Thread Reply:* may I ask if you use some custom operator / python operator there?
*Thread Reply:* yeah, taskflow with inlets/outlets
*Thread Reply:* so we extract from sources and use pyarrow to create parquet files in storage that an mssql-server can use as external tables
*Thread Reply:* awesome 👍 we have plans to integrate more with Python operator as well but not earlier than in Airflow 2.8
*Thread Reply:* I guess writing a generic extractor for the python operator is quite hard, but if you could support some inlet/outlet type for tabular fileformat / their python libraries like pyarrow or maybe even pandas and document it, I think a lot of people would understand how to use them
Are you located in the Brussels area or within commutable distance? Interested in attending a meetup between October 16-20? If so, please DM @Sheeri Cabral (Collibra) or myself. TIA
@channel Hello all, I’d like to open a vote to release OpenLineage 1.3.0, including: • support for Spark 3.5 in the Spark integration • scheme preservation bug fix in the Spark integration • find-links path in tox bug in the Airflow integration fix • more graceful logging when no OL provider is installed in the Airflow integration • columns as schema facet for airflow.lineage.Table addition • SQLSERVER to supported dbt profile types addition Three +1s from committers will authorize. Thanks in advance.
*Thread Reply:* Thanks all. The release is authorized and will be initiated within 2 business days.
*Thread Reply:* looking forward to that, I am seeing inconsistent results in Databricks for Spark 3.4+, sometimes there's no inputs / outputs, hope that is fixed?
*Thread Reply:* @Jason Yip if it isn’t fixed for you, would love it if you could open up an issue that will allow us to reproduce and fix
*Thread Reply:* @Harel Shein the issue still exists -> Spark 3.4 and above, including 3.5, saveAsTable and create table won't have inputs and outputs in Databricks
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/2124
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* and of course this issue still exists
*Thread Reply:* thanks for posting, we’ll continue looking into this.. if you find any clues that might help, please let us know.
*Thread Reply:* is there any instructions on how to hook up a debugger to OL?
*Thread Reply:* @Paweł Leszczyński has been working on adding a debug facet, but more suggestions are more than welcome!
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/pull/2147
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* @Paweł Leszczyński do you have a build for the PR? Appreciated!
*Thread Reply:* we’ll ask for a release once it’s reviewed and merged
@channel The September issue of OpenLineage News is here! This issue covers the big news about OpenLineage coming out of Airflow Summit, progress on the Airflow Provider, highlights from our meetup in Toronto, and much more. To get the newsletter directly in your inbox each month, sign up here.
Hi folks - I'm wondering if its just me, but does io.openlineage:openlineage_sql_java:1.2.2 ship with the arm64.dylib binary? When i try and run code that uses the Java package on an Apple M1, the binary isn't found, The workaround is to checkout 1.2.2 and then build and publish it locally.
*Thread Reply:* Not sure if I follow your question. Whenever OL is released, there is a script new-version.sh - https://github.com/OpenLineage/OpenLineage/blob/main/new-version.sh being run and modify the codebase.
So, If you pull the code, it contains OL version that has not been released yet and in case of dependencies, one need to build them on their own.
For example, here https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#preparation Preparation section describes how to build openlineage-java and openlineage-sql in order to build openlineage-spark.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Hmm. Let's elaborate my use case a bit.
We run Apache Hive on-premise. Hive provides query execution hooks for pre-query, post-query, and I think failed query.
Any way, as part of the hook, you're given the query string.
So I, naturally, tried to pass the query string into OpenLineageSql.parse(Collections.singletonList(hookContext.getQueryPlan().getQueryStr()), "hive") in order to test this out.
I was using openlineage-sql-java:1.2.2 at that time, and no matter what query string I gave it, nothing was returned.
I then stepped through the code and noticed that it was looking for the arm64 lib, and I noticed that that package (downloaded from maven central) lacked that particular native binary.
*Thread Reply:* I hope that helps.
*Thread Reply:* I get in now. In Circle CI we do have 3 build steps:
- build-integration-sql-x86
- build-integration-sql-arm
- build-integration-sql-macos
but no mac m1. I think at that time circle CI did not have a proper resource class in free plan. Additionally, @Maciej Obuchowski would prefer to migrate this to github actions as he claims this can be achieved there in a cleaner way (https://github.com/OpenLineage/OpenLineage/issues/1624).
Feel free to create an issue for this. Others would be able to upvote it in case they have similar experience.
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* It doesn't have the free resource class still 😞 We're blocked on that unfortunately. Other solution would be to migrate to GH actions, where most of our solution could be replaced by something like that https://github.com/PyO3/maturin-action
@channel
We released OpenLineage 1.3.1!
Added:
• Airflow: add some basic stats to the Airflow integration #1845 @harels
• Airflow: add columns as schema facet for airflow.lineage.Table (if defined) #2138 @erikalfthan
• DBT: add SQLSERVER to supported dbt profile types #2136 @erikalfthan
• Spark: support for latest 3.5 #2118 @pawel-big-lebowski
Fixed:
• Airflow: fix find-links path in tox #2139 @JDarDagran
• Airflow: add more graceful logging when no OpenLineage provider installed #2141 @JDarDagran
• Spark: fix bug in PathUtils’ prepareDatasetIdentifierFromDefaultTablePath (CatalogTable) to correctly preserve scheme from CatalogTable’s location #2142 @d-m-h
Thanks to all the contributors, including new contributor @Erik Alfthan!
Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.3.1
Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md
Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.2.2...1.3.1
Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage
PyPI: https://pypi.org/project/openlineage-python/
*Thread Reply:* Any chance we can do a 1.3.2 soonish to include https://github.com/OpenLineage/OpenLineage/pull/2151 instead of waiting for the next monthly release?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>

Hey everyone - does anyone have a good mechanism for alerting on issues with open lineage? For example, maybe alerting when an event times out - perhaps to prometheus or some other kind of generic endpoint? Not sure the best approach here (if the meta inf extension would be able to achieve it)
*Thread Reply:* That's a great usecase for OpenLineage. Unfortunately, we don't have any doc or recomendation on that.
I would try using FluentD proxy we have (https://github.com/OpenLineage/OpenLineage/tree/main/proxy/fluentd) to copy event stream (alerting is just one of usecases for lineage events) and write fluentd plugin to send it asynchronously further to alerting service like PagerDuty.
It looks cool to me but I never had enough time to test this approach.
@channel This month’s TSC meeting is next Thursday the 12th at 10am PT. On the tentative agenda: • announcements • recent releases • Airflow Summit recap • tutorial: migrating to the Airflow Provider • discussion topic: observability for OpenLineage/Marquez • open discussion • more (TBA) More info and the meeting link can be found on the website. All are welcome! Do you have a discussion topic, use case or integration you’d like to demo? DM me to be added to the agenda.
The Marquez meetup in San Francisco is happening right now! https://www.meetup.com/meetup-group-bnfqymxe/events/295444209/?utmmedium=referral&utmcampaign=share-btnsavedeventssharemodal&utmsource=link|https://www.meetup.com/meetup-group-bnfqymxe/events/295444209/?utmmedium=referral&utmcampaign=share-btnsavedeventssharemodal&utmsource=link
@Michael Robinson can we cut a new release to include this change? • https://github.com/OpenLineage/OpenLineage/pull/2151
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Thanks for requesting a release, @Mars Lan (Metaphor). It has been approved and will be initiated within 2 business days of next Monday.
@here I am trying out the openlineage integration of spark on databricks. There is no event getting emitted from Openlineage, I see logs saying OpenLineage Event Skipped. I am attaching the Notebook that i am trying to run and the cluster logs. Kindly can someone help me on this
*Thread Reply:* from my experience, it will only work on Spark 3.3.x or below, aka Runtime 12.2 or below. Anything above the events will show up once in a blue moon
*Thread Reply:* ohh, thanks for the information @Jason Yip, I am trying out with 13.3 Databricks Version and Spark 3.4.1, will try using a below version as you suggested. Any issue tracking this bug @Jason Yip
*Thread Reply:* https://github.com/OpenLineage/OpenLineage/issues/2124
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* tried with databricks 12.2 --> spark 3.3.2, still the same behaviour no event getting emitted
*Thread Reply:* you can do 11.3, its the most stable one I know
*Thread Reply:* sure, let me try that out
*Thread Reply:* still the same problem…the jar that i am using is the latest openlineage-spark-1.3.1.jar, do you think that can be the problem
*Thread Reply:* tried with openlineage-spark-1.2.2.jar, still the same issue, seems like they are skipping some events
*Thread Reply:* Probably not all events will be captured, I have only tested create tables and jobs
*Thread Reply:* Hi @Guntaka Jeevan Paul, how did you configure openlineage and what is your job doing?
We do have a bunch of integration tests on Databricks platform available here and they're passing on databricks runtime 13.0.x-scala2.12.
Could you also try running code same as our test does (this one)? If you run it and see OL events, this will make us sure your config is OK and we can continue further debug.
Looking at your spark script: could you save your dataset and see if you still don't see any events?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("dbfs:/FileStore/babynames.csv")
babynames.createOrReplaceTempView("babynames_table")
years = spark.sql("select distinct(Year) from babynames_table").rdd.map(lambda row : row[0]).collect()
years.sort()
dbutils.widgets.dropdown("year", "2014", [str(x) for x in years])
display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
*Thread Reply:* this is the script that i am running @Paweł Leszczyński…kindly let me know if i’m doing any mistake. I have added the init script at the cluster level and from the logs i could see that openlineage is configured as i see a log statement
*Thread Reply:* there's nothing wrong in that script. It's just we decided to limit amount of OL events for jobs that don't write their data anywhere and just do collect operation
*Thread Reply:* this is also a potential reason why can't you see any events
*Thread Reply:* ohh…okk, will try out the test script that you have mentioned above. Kindly correct me if my understanding is correct, so if there are a few transformatiosna nd finally writing somewhere that is where the OL events are expected to be emitted?
*Thread Reply:* yes. main purpose of the lineage is to track dependencies between the datasets, when a job reads from dataset A and writes to dataset B. In case of databricks notebook, that do show or collect and print some query result on the screen, there may be no reason to track it in the sense of lineage.
@channel We released OpenLineage 1.4.1! Additions: • Client: allow setting client’s endpoint via environment variable 2151 @Mars Lan (Metaphor) • Flink: expand Iceberg source types 2149 @Peter Huang • Spark: add debug facet 2147 @Paweł Leszczyński • Spark: enable Nessie REST catalog 2165 @julwin Thanks to all the contributors, especially new contributors @Peter Huang and @julwin! Release: https://github.com/OpenLineage/OpenLineage/releases/tag/1.4.1 Changelog: https://github.com/OpenLineage/OpenLineage/blob/main/CHANGELOG.md Commit history: https://github.com/OpenLineage/OpenLineage/compare/1.3.1...1.4.1 Maven: https://oss.sonatype.org/#nexus-search;quick~openlineage PyPI: https://pypi.org/project/openlineage-python/
Hello. I am getting started with OL and Marquez with dbt. I am using dbt-ol. The namespace of the dataset showing up in Marquez is not the namespace I provide using OPENLINEAGENAMESPACE. It happens to be the same as the source in Marquez which is the snowflake account uri. It's obviously picking up the other env variable OPENLINEAGEURL so i am pretty sure its not the environment. Is this expected?
*Thread Reply:* Hi Drew, thank you for using OpenLineage! I don’t know the details of your use case, but I believe this is expected, yes. In general, the dataset namespace is different. Jobs are namespaced separately from datasets, which are namespaced by their containing datasources. This is the case so datasets have the same name regardless of the job writing to them, as datasets are sometimes shared by jobs in different namespaces.
Any idea why "environment-properties" is gone in Spark 3.4+ in StartEvent?
example:
{"environment_properties":{"spark.databricks.clusterUsageTags.clusterName":"<a href="mailto:jason.yip@tredence.com">jason.yip@tredence.com</a>'s Cluster","spark.databricks.job.runId":"","spark.databricks.job.type":"","spark.databricks.clusterUsageTags.azureSubscriptionId":"a4f54399_8db8_4849_adcc_a42aed1fb97f","spark.databricks.notebook.path":"/Repos/jason.yip@tredence.com/segmentation/01_Data Prep","spark.databricks.clusterUsageTags.clusterOwnerOrgId":"4679476628690204","MountPoints":[{"MountPoint":"/databricks-datasets","Source":"databricks_datasets"},{"MountPoint":"/Volumes","Source":"UnityCatalogVolumes"},{"MountPoint":"/databricks/mlflow-tracking","Source":"databricks/mlflow-tracking"},{"MountPoint":"/databricks-results","Source":"databricks_results"},{"MountPoint":"/databricks/mlflow-registry","Source":"databricks/mlflow-registry"},{"MountPoint":"/Volume","Source":"DbfsReserved"},{"MountPoint":"/volumes","Source":"DbfsReserved"},{"MountPoint":"/","Source":"DatabricksRoot"},{"MountPoint":"/volume","Source":"DbfsReserved"}],"User":"<a href="mailto:jason.yip@tredence.com">jason.yip@tredence.com</a>","UserId":"4768657035718622","OrgId":"4679476628690204"}}
*Thread Reply:* Is this related to any OL version? In OL 1.2.2. we've added extra variable spark.databricks.clusterUsageTags.clusterAllTags to be captured, but this should not break things.
I think we're facing some issues on recent databricks runtime versions. Here is an issue for this: https://github.com/OpenLineage/OpenLineage/issues/2131
Is the problem you describe specific to some databricks runtime versions?
<a href="https://github.com/OpenLineage/OpenLineage">OpenLineage/OpenLineage</a>
*Thread Reply:* Btw I don't understand the code flow entirely, if we are talking about a different classpath only, I see there's Unity Catalog handler in the code and it says it works the same as Delta, but I am not seeing it subclassing Delta. I suppose it will work the same.
I am happy to jump on a call to show you if needed
*Thread Reply:* @Paweł Leszczyński do you think in Spark 3.4+ only one event would happen?
/** * We get exact copies of OL events for org.apache.spark.scheduler.SparkListenerJobStart and * org.apache.spark.sql.execution.ui.SparkListenerSQLExecutionStart. The same happens for end * events. * * @return */ private boolean isOnJobStartOrEnd(SparkListenerEvent event) { return event instanceof SparkListenerJobStart || event instanceof SparkListenerJobEnd; }
@here i am trying out the databricks spark integration and in one of the events i am getting a openlineage event where the output dataset is having a facet called symlinks , the statement that generated this event is this sql
CREATE TABLE IF NOT EXISTS covid_research.covid_data
USING CSV
LOCATION '<abfss://oltptestdata@jeevanacceldata.dfs.core.windows.net/testdata/johns-hopkins-covid-19-daily-dashboard-cases-by-states.csv>'
OPTIONS (header "true", inferSchema "true");
Can someone kindly let me know what this symlinks facet is. i tried seeing the spec but did not get it completely
*Thread Reply:* I use it to get the table with database name
*Thread Reply:* so can i think it like if there is a synlink, then that table is kind of a reference to the original dataset
@here When i am running this sql as part of a databricks notebook, i am recieving an OL event where i see only an output dataset and there is no input dataset or a symlink facet inside the dataset to map it to the underlying azure storage object. Can anyone kindly help on this
spark.sql(f"CREATE TABLE IF NOT EXISTS covid_research.uscoviddata USING delta LOCATION '<abfss://oltptestdata@jeevanacceldata.dfs.core.windows.net/testdata/modified-delta>'")
{
"eventTime": "2023-10-11T10:47:36.296Z",
"producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"schemaURL": "<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunEvent>",
"eventType": "COMPLETE",
"run": {
"runId": "d0f40be9-b921-4c84-ac9f-f14a86c29ff7",
"facets": {
"spark.logicalPlan": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet>",
"plan": [
{
"class": "org.apache.spark.sql.catalyst.plans.logical.CreateTable",
"num-children": 1,
"name": 0,
"tableSchema": [],
"partitioning": [],
"tableSpec": null,
"ignoreIfExists": true
},
{
"class": "org.apache.spark.sql.catalyst.analysis.ResolvedIdentifier",
"num-children": 0,
"catalog": null,
"identifier": null
}
]
},
"spark_version": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/2-0-2/OpenLineage.json#/$defs/RunFacet>",
"spark-version": "3.3.0",
"openlineage-spark-version": "1.2.2"
},
"processing_engine": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-1-0/ProcessingEngineRunFacet.json#/$defs/ProcessingEngineRunFacet>",
"version": "3.3.0",
"name": "spark",
"openlineageAdapterVersion": "1.2.2"
}
}
},
"job": {
"namespace": "default",
"name": "adb-3942203504488904.4.azuredatabricks.net.create_table.covid_research_db_uscoviddata",
"facets": {}
},
"inputs": [],
"outputs": [
{
"namespace": "dbfs",
"name": "/user/hive/warehouse/covid_research.db/uscoviddata",
"facets": {
"dataSource": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/DatasourceDatasetFacet.json#/$defs/DatasourceDatasetFacet>",
"name": "dbfs",
"uri": "dbfs"
},
"schema": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/SchemaDatasetFacet.json#/$defs/SchemaDatasetFacet>",
"fields": []
},
"storage": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/StorageDatasetFacet.json#/$defs/StorageDatasetFacet>",
"storageLayer": "unity",
"fileFormat": "parquet"
},
"symlinks": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet>",
"identifiers": [
{
"namespace": "/user/hive/warehouse/covid_research.db",
"name": "covid_research.uscoviddata",
"type": "TABLE"
}
]
},
"lifecycleStateChange": {
"_producer": "<https://github.com/OpenLineage/OpenLineage/tree/1.2.2/integration/spark>",
"_schemaURL": "<https://openlineage.io/spec/facets/1-0-0/LifecycleStateChangeDatasetFacet.json#/$defs/LifecycleStateChangeDatasetFacet>",
"lifecycleStateChange": "CREATE"
}
},
"outputFacets": {}
}
]
}
*Thread Reply:* Hey Guntaka - can I ask you a favour? Can you please stop using @here or @channel - please keep in mind, you're pinging over 1000 people when you use that mention. Its incredibly distracting to have Slack notify me of a message that isn't pertinent to me.
*Thread Reply:* sure noted @Damien Hawes
Hi @there, I am trying to make API call to get column-lineage information could you please let me know the url construct to retrieve the same? As per the API documentation I am passing the following url to GET column-lineage: http://localhost:5000/api/v1/column-lineage but getting error code:400. Thanks
*Thread Reply:* Make sure to provide a dataset field nodeId as a query param in your request. If you’ve seeded Marquez with test metadata, you can use:
curl -XGET "<http://localhost:5002/api/v1/column-lineage?nodeId=datasetField%3Afood_delivery%3Apublic.delivery_7_days%3Acustomer_email>"
You can view the API docs for column lineage here!
*Thread Reply:* Thanks Willy. The documentation says 'name space' so i constructed API Like this: 'http://marquez-web:3000/api/v1/column-lineage/nodeId=datasetField:file:/home/jovyan/Downloads/event_attribute.csv:eventType' but it is still not working 😞
*Thread Reply:* nodeId is constructed like this: datasetField:<namespace>:<dataset>:<field name>
@channel Friendly reminder: this month’s TSC meeting, open to all, is tomorrow at 10 am PT: https://openlineage.slack.com/archives/C01CK9T7HKR/p1696531454431629
*Thread Reply:* Newly added discussion topics: • a proposal to add a Registry of Consumers and Producers • a dbt issue to add OpenLineage Dataset names to the Manifest • a proposal to add Dataset support in Spark LogicalPlan Nodes • a proposal to institute a certification process for new integrations
This might be a dumb question, I guess I need to setup local Spark in order for the Spark tests to run successfully?
*Thread Reply:* just follow these instructions: https://github.com/OpenLineage/OpenLineage/tree/main/integration/spark#build
*Thread Reply:* when trying to install openlineage-java in local via this command --> cd ../../client/java/ && ./gradlew publishToMavenLocal, i am receiving this error ```> Task :signMavenJavaPublication FAILED
FAILURE: Build failed with an exception.
** What went wrong: Execution failed for task ':signMavenJavaPublication'. > Cannot perform signing task ':signMavenJavaPublication' because it has no configured signatory```
*Thread Reply:* which java are you using? what is your operation system (is it windows?)?
*Thread Reply:* yes it is Windows, i downloaded java 8 but I can try to build it with Linux subsystem or Mac
*Thread Reply:* ** Where: Build file '/mnt/c/Users/jason/Downloads/github/OpenLineage/integration/spark/build.gradle' line: 9
** What went wrong: An exception occurred applying plugin request [id: 'com.adarshr.test-logger', version: '3.2.0'] > Failed to apply plugin [id 'com.adarshr.test-logger'] > Could not generate a proxy class for class com.adarshr.gradle.testlogger.TestLoggerExtension.
** Try:
*Thread Reply:* we don't have any restrictions for windows builds, however it is something we don't test regularly. 2h ago we did have a successful build on circle CI https://app.circleci.com/pipelines/github/OpenLineage/OpenLineage/8271/workflows/0ec521ae-cd21-444a-bfec-554d101770ea
*Thread Reply:* ... 111 more Caused by: java.lang.ClassNotFoundException: org.gradle.api.provider.HasMultipleValues ... 117 more
*Thread Reply:* @Paweł Leszczyński now I am doing gradlew instead of gradle on windows coz Linux one doesn't work. The doc didn't mention about setting up Spark / Hadoop and that's my original question -- do I need to setup local Spark? Now it's throwing an error on Hadoop: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
*Thread Reply:* Got it working with Mac, couldn't get it working with Windows / Linux subsystem
*Thread Reply:* Now getting class not found despite build and test succeeded
*Thread Reply:* I uploaded the wrong jar.. there are so many jars, only the jar in the spark folder works, not subfolder
Hi team, I am running the following pyspark code in a cell: ```print("SELECTING 100 RECORDS FROM METADATA TABLE") df = spark.sql("""select ** from







 }
}












 }
}














 }
}

































 }
}


 }
}









 }
}

 }
}
















 }
}



































 }
}








 }
}























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}